引言:算力碎片化下的"AI 落地"困局
作为一名经历过无数次现场交付的架构师,我深知在企业级 AI 视觉项目中,"算力异构" 是最大的拦路虎。客户现场可能既有老旧的 x86 服务器,又有为了降本增效新采购的国产 ARM 架构边缘盒子(NPU);算法模型可能是基于 PyTorch 训练的,也可能是适配特定芯片的 RKNN 或 ONNX 格式。
如果每次部署都要针对不同的硬件重写驱动层代码,那"减少 95% 开发成本"就是一句空话。
今天,我们将深入剖析 YiheCode Server 的底层架构。这套系统之所以能被称为"企业级视频中台",核心在于它通过微服务解耦 与容器化部署 ,完美解决了 GPU(云端)与 NPU(边缘端)的混合调度难题,实现了真正意义上的"一次开发,随处运行"。
一、 分层架构设计:计算与控制的彻底解耦
YiheCode Server 的架构设计严格遵循了控制平面与数据平面分离的原则。这种设计不仅是为了美观,更是为了解决 X86 与 ARM 指令集不兼容的根本矛盾。
1.1 核心架构拓扑
系统被拆解为三个核心层级,通过标准的 HTTP/WebSocket 进行通信:
- Web 控制层 (Java/Vue):业务逻辑中枢,负责用户交互、任务编排、告警存储。通常部署在 X86 服务器或云端。
- 流媒体网关层 (ZLM):负责视频流的拉取、转码、分发。支持 Docker 部署,适应各种环境。
- 边缘计算层 (Edge SDK):算法推理核心,直接运行在 NPU/GPU 边缘盒子上,负责实时抓拍与 AI 计算。
这种架构使得上层业务代码(Java)完全不需要关心底层是海思芯片还是瑞芯微芯片,只需通过接口下发任务即可。
1.2 异构计算的调度逻辑
平台通过**"算法商城"**实现了模型与硬件的动态绑定。在配置文件中,系统会根据硬件信息自动匹配对应的推理引擎(Inference Engine)。
yaml
# 伪代码:边缘节点配置示例 (edge-config.yml)
device:
hardware_type: "RK3588" # 识别硬件类型 ARM64
npu_brand: "Rockchip" # NPU品牌
compute_mode: "Edge" # 计算模式:边缘/云端
algorithm_engine:
- name: "Helmet_Detect" # 算法名称
model_format: "RKNN" # 根据硬件自动选择 RKNN (针对ARM) 或 ONNX (针对x86)
input_size: [640, 640]
confidence_threshold: 0.6二、 技术实现:如何打通 X86 与 ARM 的"任督二脉"
2.1 容器化与跨平台部署
为了适应不同的硬件环境,平台提供了Docker 和 Docker-Compose 的部署方案。无论是 X86 的物理机,还是 ARM 架构的边缘服务器,只需执行相同的 docker-compose up 命令,即可完成环境依赖的拉取和启动。
- X86 环境:运行 MySQL, Redis, Web 服务,利用 CUDA 进行高密度计算(可选)。
- ARM 环境:部署边缘计算 Agent,利用 NPU 进行低功耗推理。
2.2 统一的通信协议栈
为了解决不同网络环境下的通信问题,系统设计了Socket + HTTP 双通道心跳机制:
- 指令通道 (HTTP/WebSocket):用于下发配置、算法包更新、控制指令。
- 数据通道 (HTTP Form):边缘节点将告警抓拍的图片和结构化数据回传至中心服务器。
告警回传接口示例:
java
// 边缘节点向中心服务器上报告警的伪代码
public class AlarmUploader {
public void upload(AlarmEntity entity) {
// 1. 图片压缩与编码
byte[] imageBytes = ImageUtils.compress(entity.getSnapshot());
// 2. 构建 Form-Data 请求
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
body.add("cameraId", entity.getCameraId());
body.add("algorithm", entity.getAlgorithmType());
body.add("image", new ByteArrayResource(imageBytes));
// 3. 发送至中心服务器 (无论中心是x86还是arm,协议一致)
ResponseEntity<String> response = restTemplate.postForEntity(
"http://center-server/api/v1/alarm/receive",
body,
String.class
);
}
}三、 硬件适配与性能优化
结合文档中的"边缘平台"设计,我们可以看到平台对硬件资源的精细化管理:
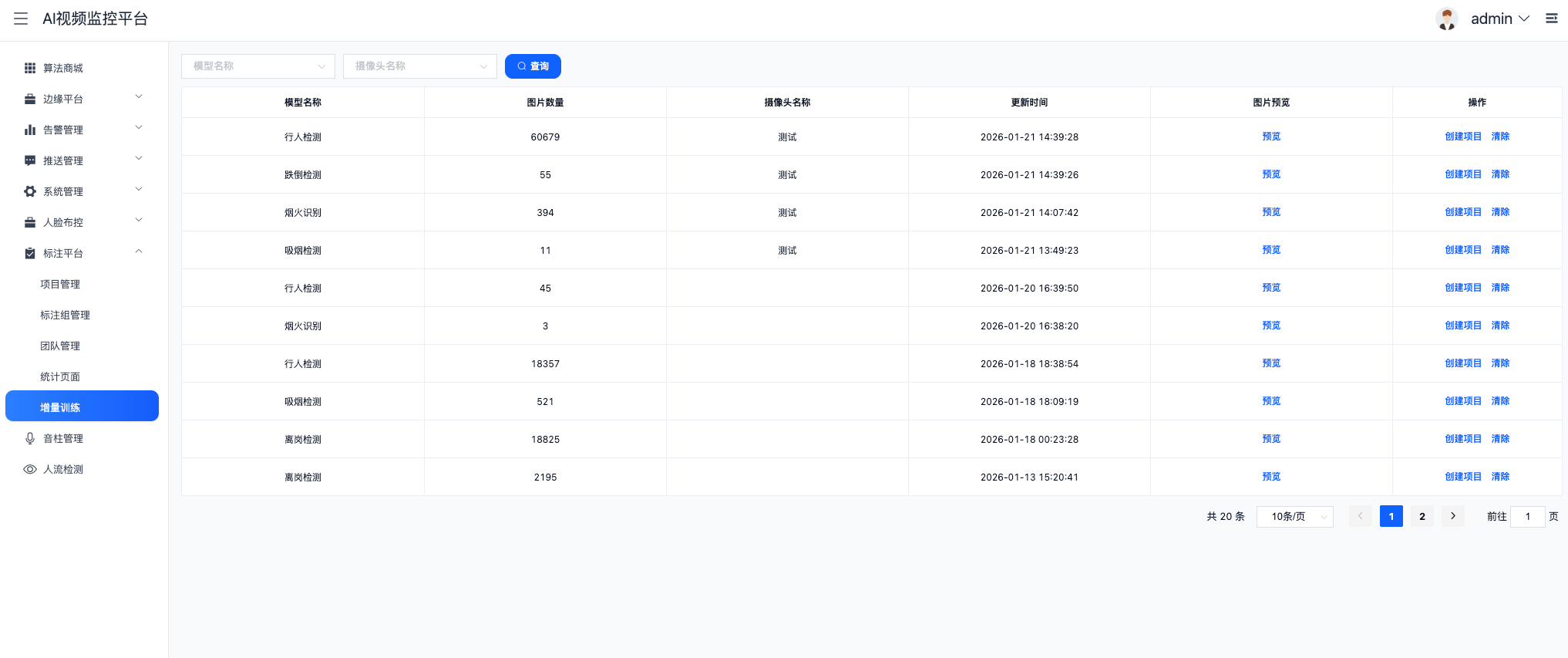
| 硬件维度 | 管理策略 | 技术价值 |
|---|---|---|
| 芯片类型 | 自动识别 1684X, RK3588, GPU 等 | 无需人工干预,自动加载对应驱动库 |
| 算力调度 | 支持云端 (GPU) 与边缘端 (NPU) 混合部署 | 敏感数据本地处理,非敏感数据云端分析 |
| 资源监控 | 实时显示 CPU/内存/硬盘使用率 | 防止过载,保障 7x24 小时稳定运行 |
| 算法分发 | 支持版本升级与降级 | 解决了边缘设备固件更新难的问题 |
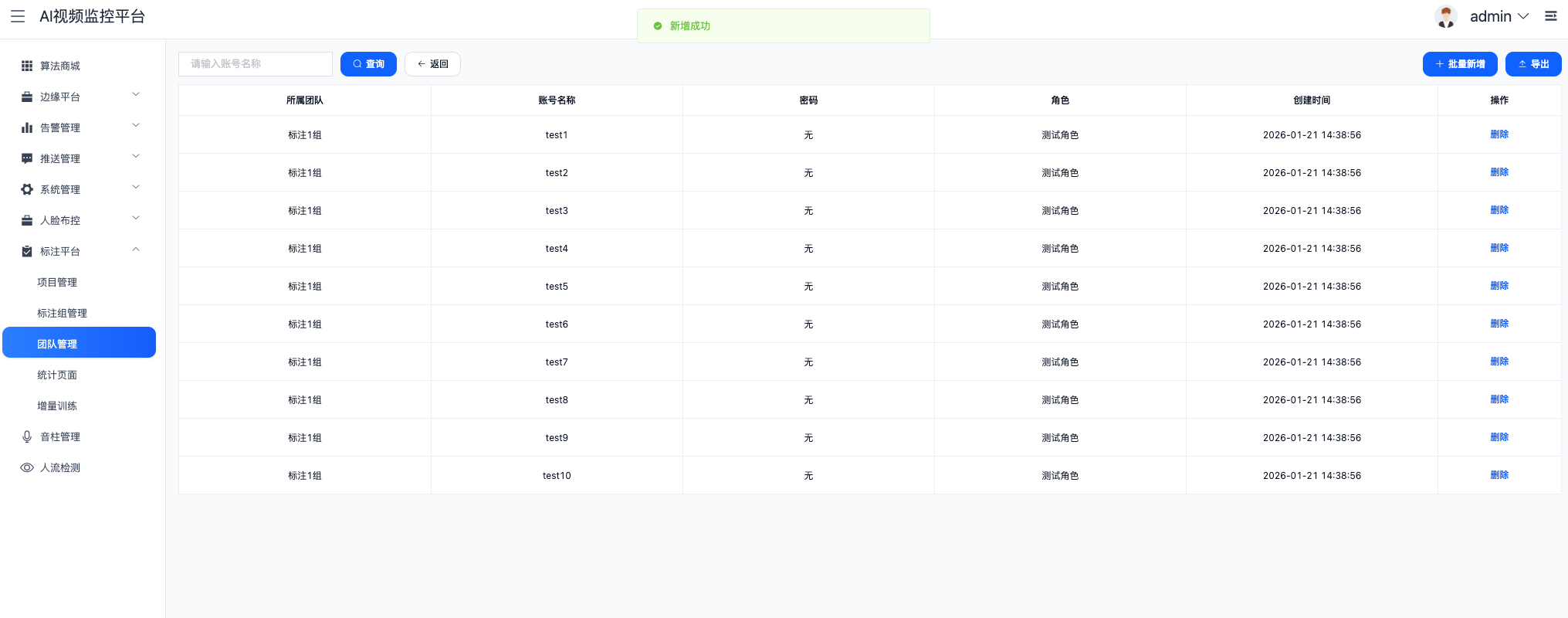
四、 总结
YiheCode Server 的架构精髓在于**"中间件化"。它没有试图用一套二进制代码跑在所有机器上,而是通过标准的 视频流 (RTSP/GB28181)** 和数据流 (HTTP API) ,将散落在各处的异构算力编织成一张网。
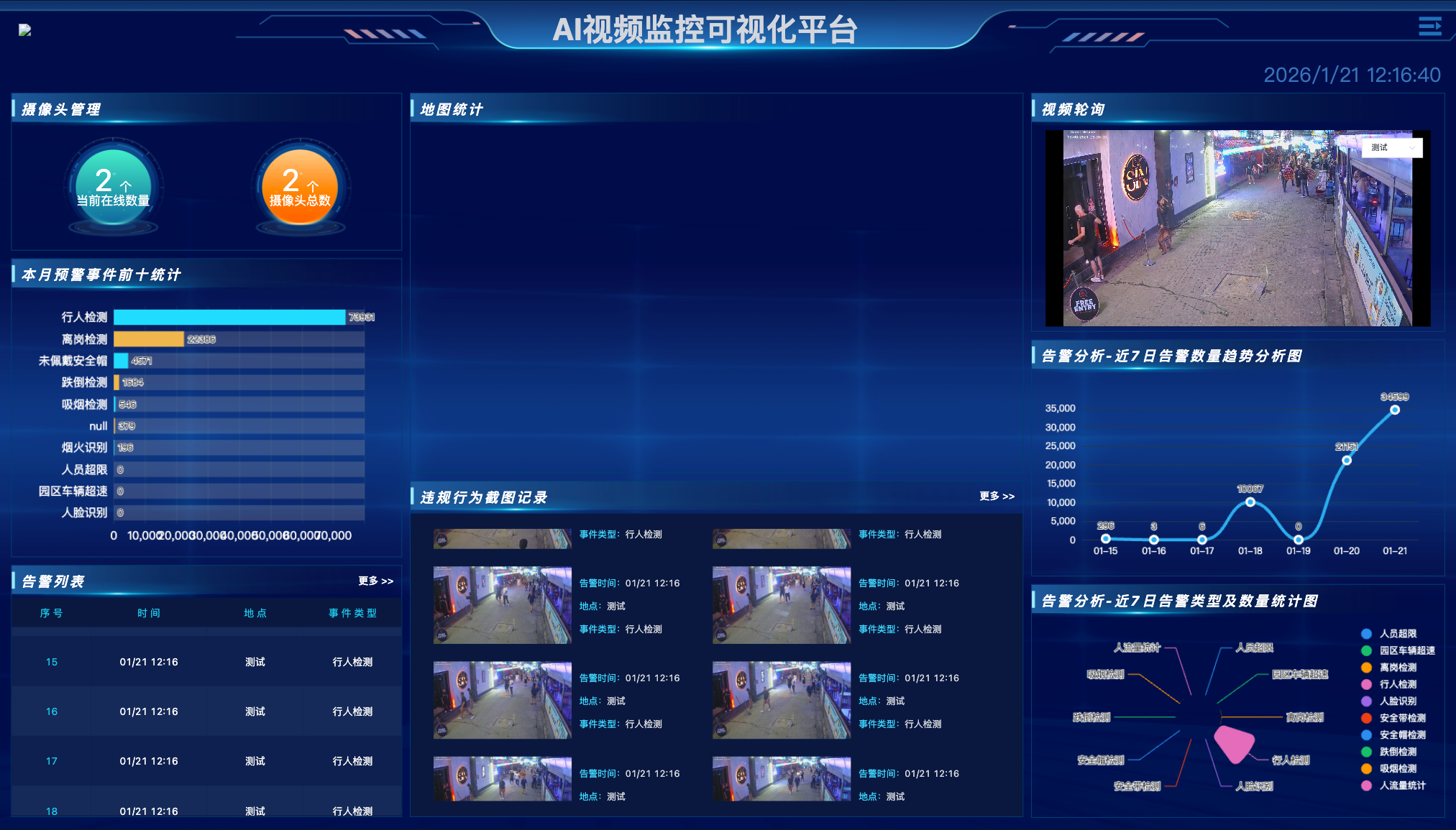
对于技术决策者来说,这意味着:
- 利旧与扩容并存:旧的 X86 服务器可以做存储和管理,新的 ARM 盒子做计算,互不干扰。
- 开发成本归零:无需招聘昂贵的嵌入式底层开发人员,Java 后端即可完成全链路配置。
🚀 演示环境与部署指南
如果您正在寻找一套能够真正落地、支持私有化部署的 AI 视频管理方案,请参考以下信息进行体验:
- 开源地址 :Gitee - YiheCode Server
架构师建议 :
在进行异构部署时,请务必关注边缘节点的网络带宽。建议将高码率视频流的解码和推理直接放在 ARM 边缘端,仅将抓拍图片和结构化数据回传中心,以节省带宽成本。