Vibe Coding 的热度还没过,Prompt Engineering 的课还在卖,Context Engineering 的墨迹还没干,现在又来了一个 Harness Engineering?
AI 圈造新词的速度,快赶上模型迭代了。过去一年光「XX Engineering」就冒出来四五个,让人眼花缭乱。
但当我读完 OpenAI 和 Anthropic 的原文后,我的反应变了。不是「哇好新」,而是:等等,这不就是我过去半年一直在干的事吗?
我写 CLAUDE.md,告诉 AI 我是谁、什么规则必须遵守;我配 hooks,在 agent 关键节点注入检查;我建知识库,给 AI 准备决策需要的上下文。做了半年,从来没觉得这些事需要一个统一的名字。
直到 OpenAI 发了篇博文说这叫 Harness Engineering。Mitchell Hashimoto(HashiCorp 联合创始人)也这么叫,Martin Fowler 写了长文分析。行,那就叫 Harness Engineering。
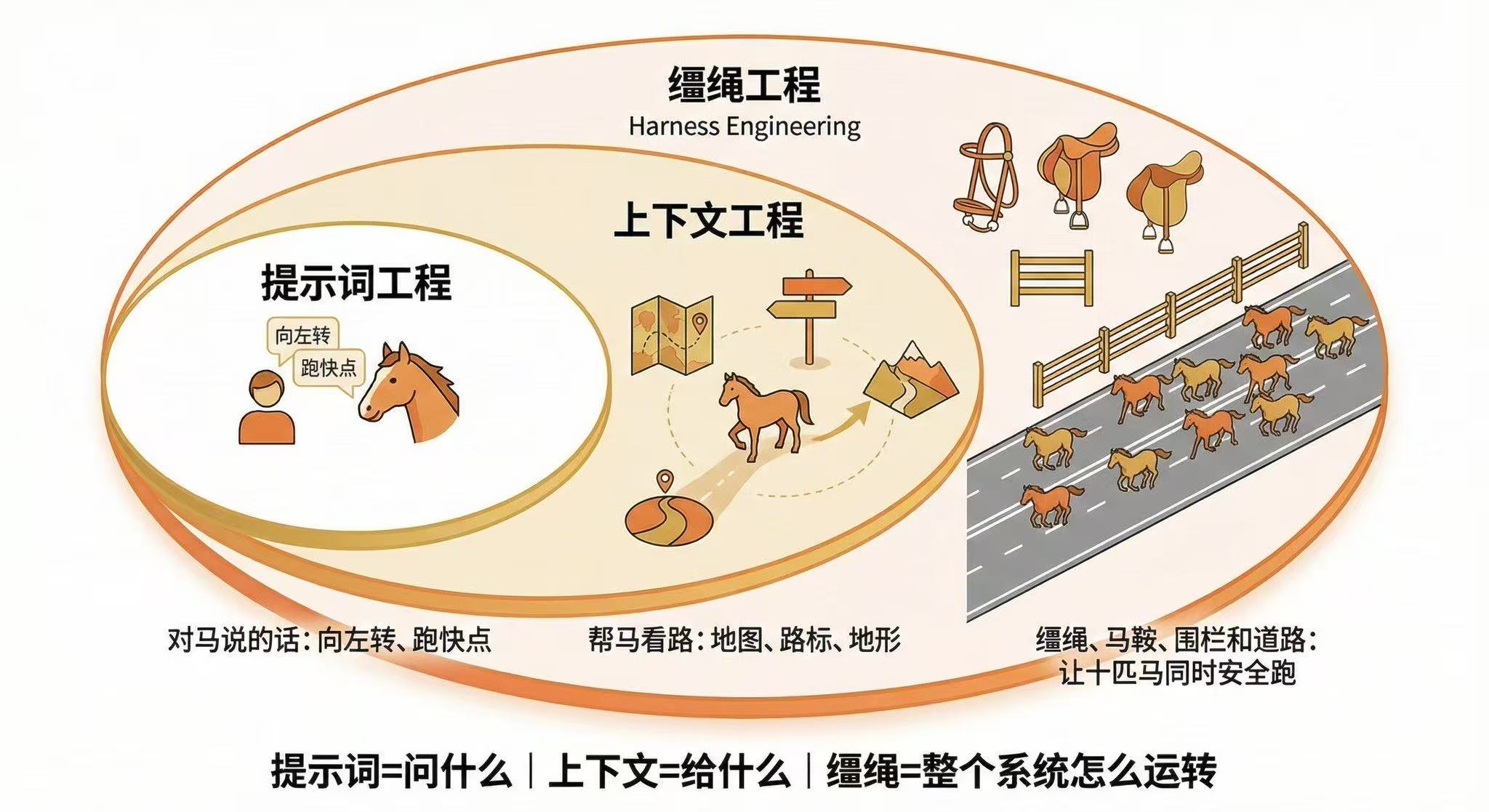
Harness 这个词,英文原意是马具、缰绳。不是马本身,是套在马身上让它能拉车、能被引导的那整套东西。没有它,马就是一匹乱跑的野马,力气再大也白搭。
🧩 三层关系:从"喊话"到"造轨"
为了理清这三者的关系,我们可以用一个非常直观的比喻:
- Prompt Engineering(提示工程):是你对马说的话。比如"向左转"、"跑快点"。
- Context Engineering(上下文工程):是帮马看路的一切。比如地图、路标、地形信息。
- Harness Engineering(驾驭工程) :是缰绳、马鞍、围栏和道路本身。它是让十匹马同时安全跑起来的系统。
Prompt 管你问什么,Context 管你给模型看什么,而 Harness 管整个东西怎么运转。Context 只是 Harness 的一部分,Harness 还多管了约束、反馈和质量检查。
🚀 震撼的数据:模型可能已经不是瓶颈了
先说一个最硬的数据。LangChain 的 coding agent 在 Terminal Bench 2.0 上,成绩从 52.8% 涨到了 66.5%,排名从 Top 30 跳到 Top 5。
重点是:模型完全没换。他们只改了三样东西:系统提示词、工具配置、中间件钩子。同一个模型,换了套"缰绳",成绩天差地别。这说明,瓶颈可能不再是模型本身,而是你给它搭了个什么样的环境。
再看 OpenAI 自己的实验。Codex 团队仅用 3 名工程师(后来扩到 7 个),在 5 个月内,利用 Codex 智能体从零构建了一个拥有 100 万行代码 的完整 Beta 产品,且全程没有一行代码是由人类手写的。
期间合并了约 1500 个 PR,每个工程师每天推进约 3.5 个 PR,估算速度是传统方式的 10 倍。

🛡️ Harness 到底包含什么?
既然 Harness Engineering 这么重要,那它具体包含哪些内容?Martin Fowler 将其拆解为三块:
- 上下文工程:给模型一张地图,而不是一本 1000 页的说明书。维护一个持续更新的代码库知识库,加上 agent 能实时看到的系统状态。上下文是稀缺资源,塞太多反而挤占干活的空间。
- 架构约束:不光靠 AI 自己检查,还有代码检查器(Linter)和结构测试在旁边盯着。这是硬规则,不遵守就编译不过。
- 垃圾回收:专门有个 agent 周期性运行,不写代码不做功能,就干一件事:找文档里的矛盾和架构违规。就像一个专职找茬的 AI。
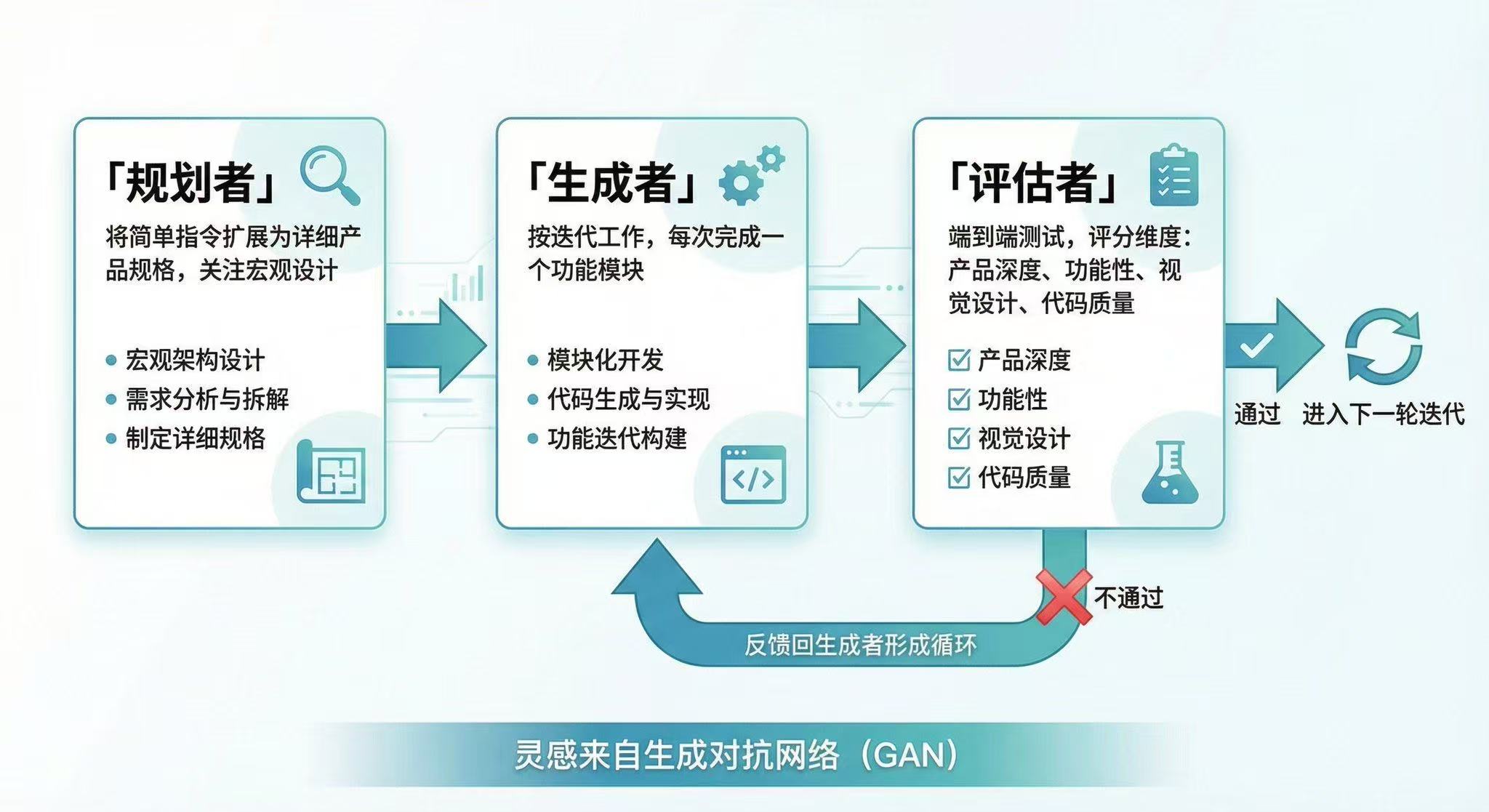
Anthropic 则走了另一条路,他们搞了个三 agent 架构:规划者负责扩展规格,生成者负责迭代开发,评估者负责跑端到端测试。灵感来自生成对抗网络(GAN),训练一个专门的评估者让它一直挑刺,比让生成者自己检查自己管用得多。
🤔 一个被忽视的隐忧:代码质量与可维护性
这些数字很炸,但有个问题很少人聊:这 100 万行代码的质量怎么样?
速度快了 10 倍,不代表产出好了 10 倍。每人每天 3.5 个 PR,谁在做代码审查?六个月后需要改需求的时候,这 100 万行好改吗?
AI 写的代码和人写的代码有个关键区别:人写代码时会无意识地留下结构线索,方便将来的自己理解。AI 不会。 它只解决眼前的任务,不考虑六个月后维护这段代码的人会不会骂娘。
所以,Harness 不只是让 AI 写得快,还得让 AI 写得能维护。OpenAI 的实验证明了速度,但长期成本还是个问号。
💡 如何开始你的 Harness Engineering?
如果你想开始尝试,三条建议就够:
- 给地图,不给说明书 :
CLAUDE.md应该像地图:项目结构、文件关系、关键约束。不要把每步都写死。AI 需要方向感,不需要僵化步骤。 - 每次犯错加一条规则:从空文件开始,agent 犯一个错就加一条。三个月后那个文件就是你的 Harness。它高度定制,因为全是你场景里真实出过的问题。
- 让 AI 查 AI:借鉴 Anthropic 的 Evaluator 思路。别让 AI 自己查自己。最简单的做法:写完后开一个新对话,把结果贴进去:"找出所有问题"。你会惊讶第二个 AI 能发现多少第一个漏掉的。
🧠 最后的思考:经验工程的未来
在实际的开发过程中遵循一些基本准则:
1、把"隐形知识"显性化(Context Engineering),将项目结构、技术栈约束、动态维护要求和项目写在一起,针对项目或AI 工具会集成Agent/MCP/Rule/Skills等作为AI调用和识别处理的Tools 改进围栏规则。
2、项目基础框架配置约束好,项目本身的Linter静态检查/自动化测试脚本/构建脚本以及Pre-commit hook 或 CI 流程 都需要统一配置。
3、建立"自我纠错"的闭环(Feedback Loops)。人作为观察者和审查者,不断补充有效信息,让 AI 能读取日志。当代码报错时,不要只给它看错误代码,把错误堆栈(Stack Trace)和相关日志喂给它,让 AI 能够运行测试用例或端到端测试。如果测试失败,AI 自动分析原因并重试。