一、复杂场景下,LLA嵌入应用的问题
使用过⼀些原⽣大模型的⼈可能会发现⼀些问题,尽管⼤模型的在某些方⾯表现振奋人心,例如将其 当作搜索引擎去使用,LLM⽣成的答案可能要比其他搜索引擎查到的答案更符合你的预期,但要是在 复杂的场景下使用,如将LLM嵌⼊应用程序时却遭遇了全新难题,这里简单介绍6种主要问题
1.幻觉问题
举几个例子:
用户提问:"请介绍一下《三体》的作者刘慈欣的其他作品。"
幻觉回答:"刘慈欣除了《三体》三部曲外,还著有《流浪地球》《乡村教师》,以及著名的科幻小说《你一生的故事》。(注:《你一生的故事》是美国华裔作家特德·姜的作品,也是电影《降临》的原著)"
分析:模型将另一位优秀科幻作家的代表作错误地归属给了刘慈欣。因为这两者常被一起讨论(都是科幻、都有改编电影),模型在概率关联上产生了混淆。
当模型不确定答案时,有时会虚构一个前置条件来让回答显得合理。
用户提问:"你能告诉我,我昨天在会议上具体说了什么吗?"
幻觉回答:"虽然我没有实时记录功能,但根据我的系统分析,您在昨天的会议上主要讨论了关于Q4预算的调整方案......"
分析:模型根本不可能知道用户昨天在会议上说了什么(除非是真正的具备记忆功能的智能体)。它没有诚实地表示"我不知道"或"我没有该信息",而是编造了一个听起来合理的会议内容。
2.统一提示词
开发团队需要为"疾病诊断"、"药物咨询"、"急救建议"等不同功能编写提示词
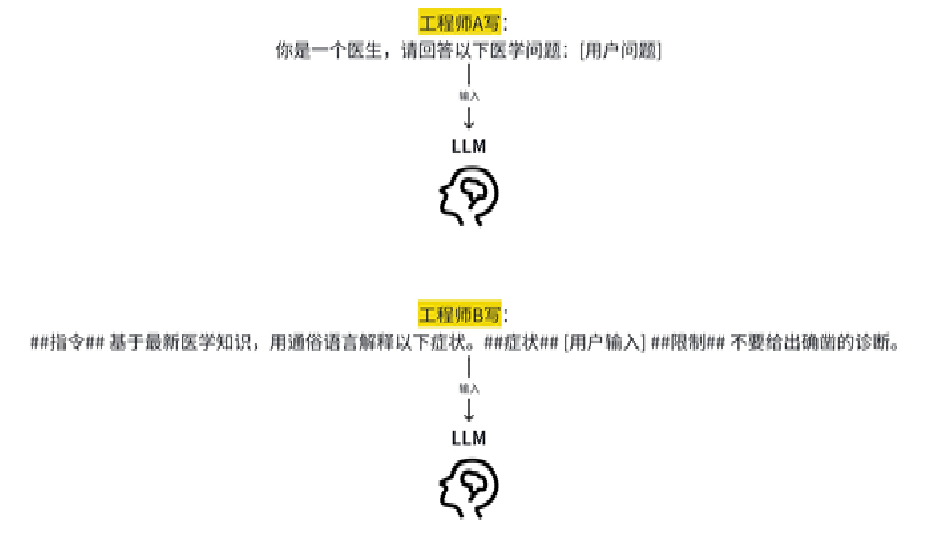
提示词的质量和风格直接决定输出结果的准确性和安全性。没有统⼀的规范会导致应用行为不可预测、难以调试,且无法规模化地优化效果
3.切换模型问题
项目开始时使用GPT-3.5Turbo进行原型开发,成本较低。后期为了提升准确性,希望切换到更强⼤的GPT-5或开源模型如Llama3
会发现切换成本极高,这意味着⼀旦选定⼀个模型,整个应⽤程序的代码就与该模型的API强耦合。切换模型⼏乎等于重写所有与LLM交互的代码,严重阻碍了技术选型的灵活性
4.非结构化输出难以与程序接口交互
举个例子:以用户输入自身疾病为例
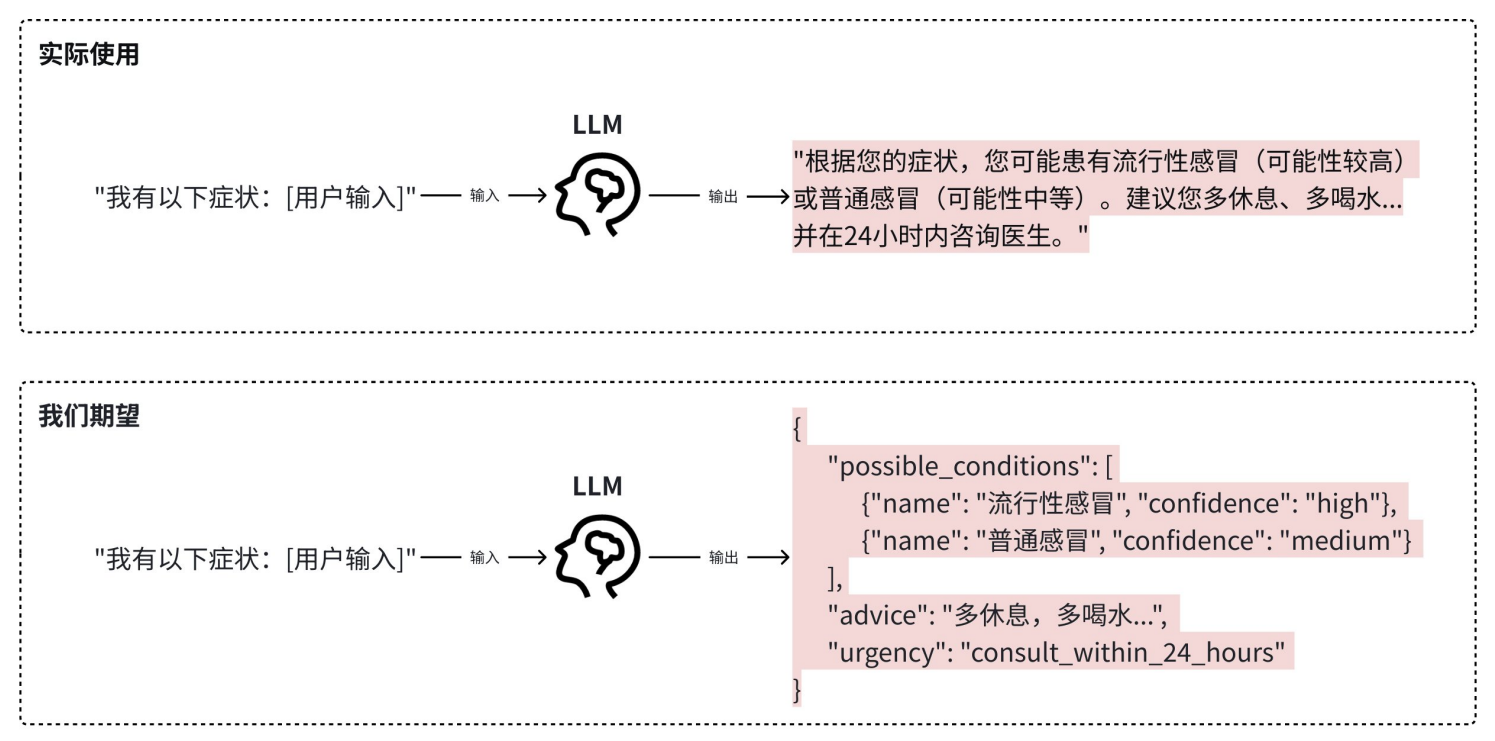
程序无法直接解析这段自然语⾔文本来提取"疾病名称"和"可信度"。必须编写复杂且脆弱的正则表达式或再用⼀个模型来解析第⼀个模型的输出,极大增加了复杂度和出错概率
5.大模型训练是有截至日期的
这个很好理解,比如GPT-5的截至日期是2024.9.30
6.针对非常专业的知识,只能做参考
二、Langchain的解决思路
1.针对幻觉问题:根据用户的问题,使用RAG 技术在内部知识库进行检索,通过语义的形式(嵌入模型),会得到一些"参考答案",然后把问题和答案一起发给大模型。还有一种方法是Agent(智能体)
2.针对提示词:设计严谨、规范的提示词
3.针对模型切换:使用LLMAPI抽象层(如LangChain),这些中间件统⼀了不同模型的接,让开 发者通过配置而非修改代码来切换模型
4.LangChain可以要求大模型返回一些特定的结构化数据(依旧需求)。
5.LangChain有一些搜索引擎,可以实时搜索网页
6.若建立一个专业知识的库,LangChain也可以调用
三、LangChain的技术特点
LangChain框架的设计精髓在于以链式(Chain)的⽅式整合多个组件,从而构建出功能丰富的⼤语言模型应用。链式表示LangChain允许将多个步骤或多个组件串联起来,无需各个组件各自完成其能力,而是⼀次性执行这个"链"上的所有流程
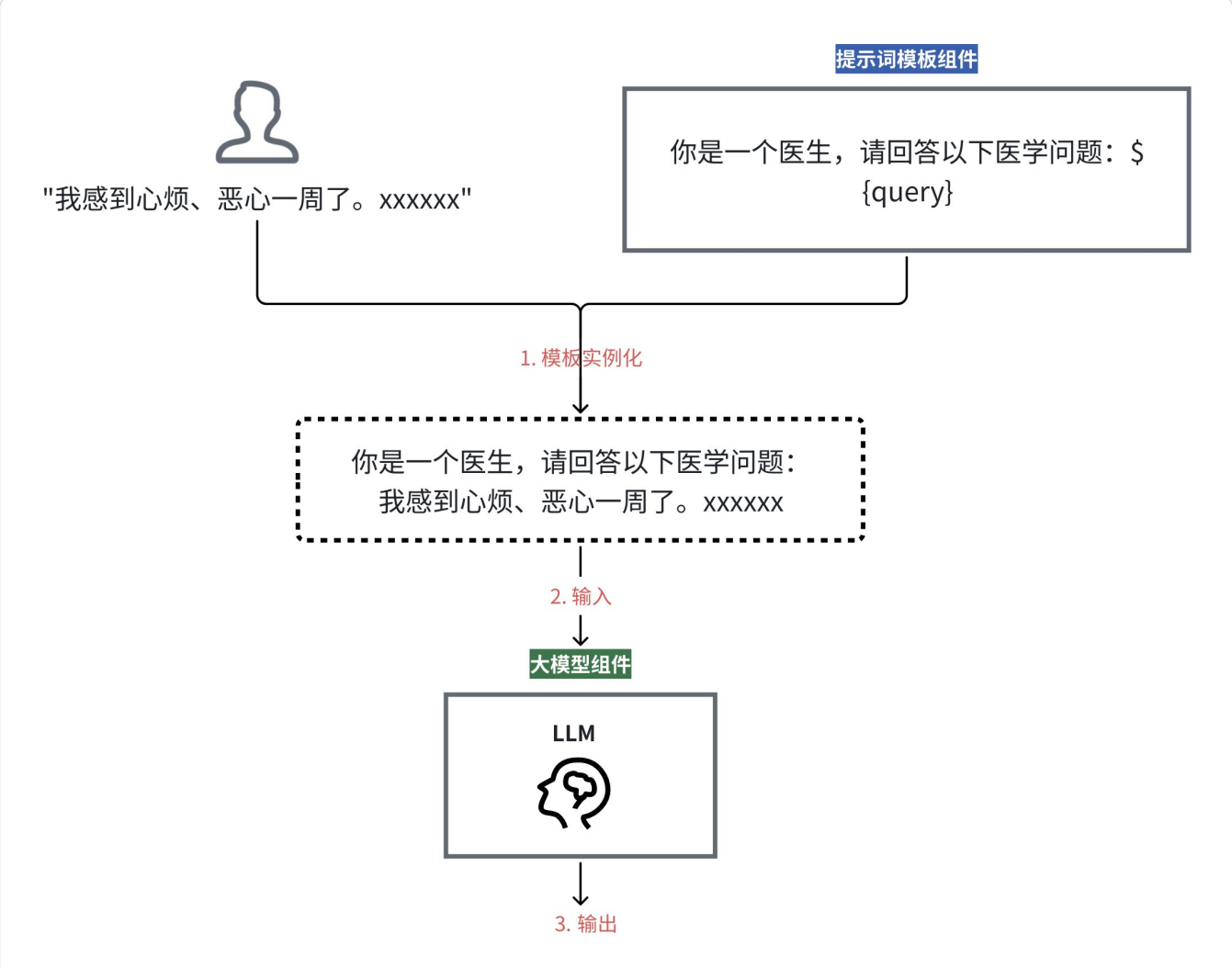
转换成:
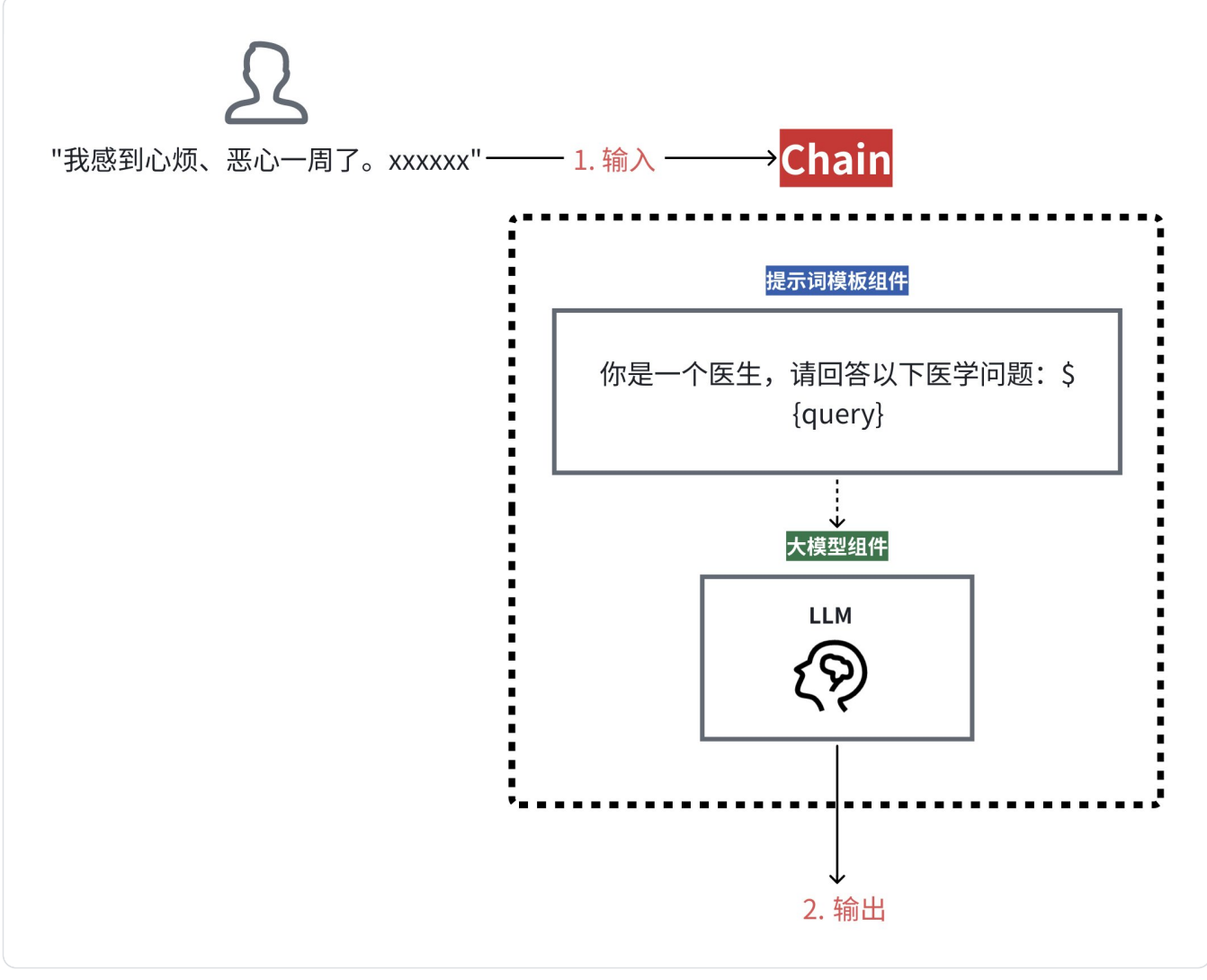
本文只是简介,后面会对LangChain进行详细介绍