内容参考于:图灵AI大模型全栈
LangChain提供了多个类型的文本切分器:常用RecursiveCharacterTextSplitter(递归分割)、MarkdownHeaderTextSplitter(按照Markdown文档分割)

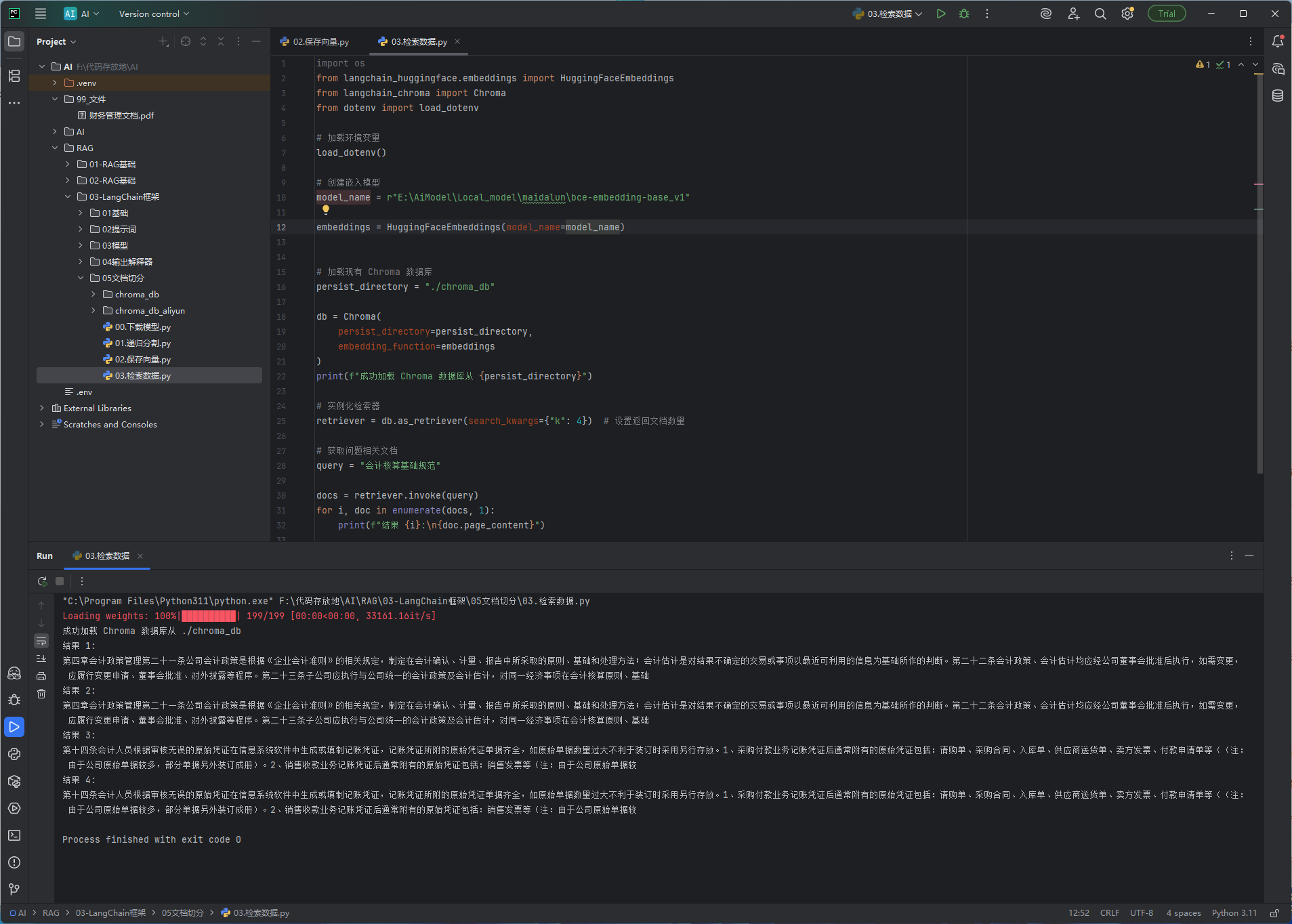
递归分割
效果图:
python# 导入LangChain的PDF文档加载器,用于读取本地PDF文件 from langchain_community.document_loaders import PyPDFLoader # 导入递归字符文本分割器,用于将长文本切割成固定大小的文本块(RAG知识库必备) from langchain_text_splitters import RecursiveCharacterTextSplitter # 初始化PDF加载器,传入本地PDF文件的绝对路径(Windows路径加r防止转义) loader = PyPDFLoader(r"F:\代码存放地\AI\99_文件\财务管理文档.pdf") # 加载PDF并**自动分页**解析 # load_and_split() = 加载文档 + 基础分页,返回按PDF页面拆分的文档列表 pages = loader.load_and_split() # print(f"第0页:\n{pages[0].page_content}") # print(pages) # 初始化【递归字符文本分割器】,自定义分块规则 text_splitter = RecursiveCharacterTextSplitter( chunk_size=200, # 每个文本块的最大长度(字符数) chunk_overlap=100, # 文本块之间的重叠字符数(防止语义断裂) length_function=len, # 长度计算函数:使用Python内置len()计算字符长度 ) # 核心步骤:遍历所有PDF页面,清洗文本(去除换行、空格),并进行文本分块 # 1. for page in pages:遍历PDF所有页面 # 2. page.page_content.replace:清洗文本,去掉换行符、空格 # 3. text_splitter.create_documents:将清洗后的长文本切割成指定大小的文档块 paragraphs = text_splitter.create_documents([page.page_content.replace('\n', '').replace(' ', '') for page in pages if pages]) # print(paragraphs) # 遍历所有切割后的文本块,打印内容和每个块的字符长度 for para in paragraphs: print(para.page_content) # 打印分隔线 + 当前文本块的长度 print('-------', len(para.page_content))
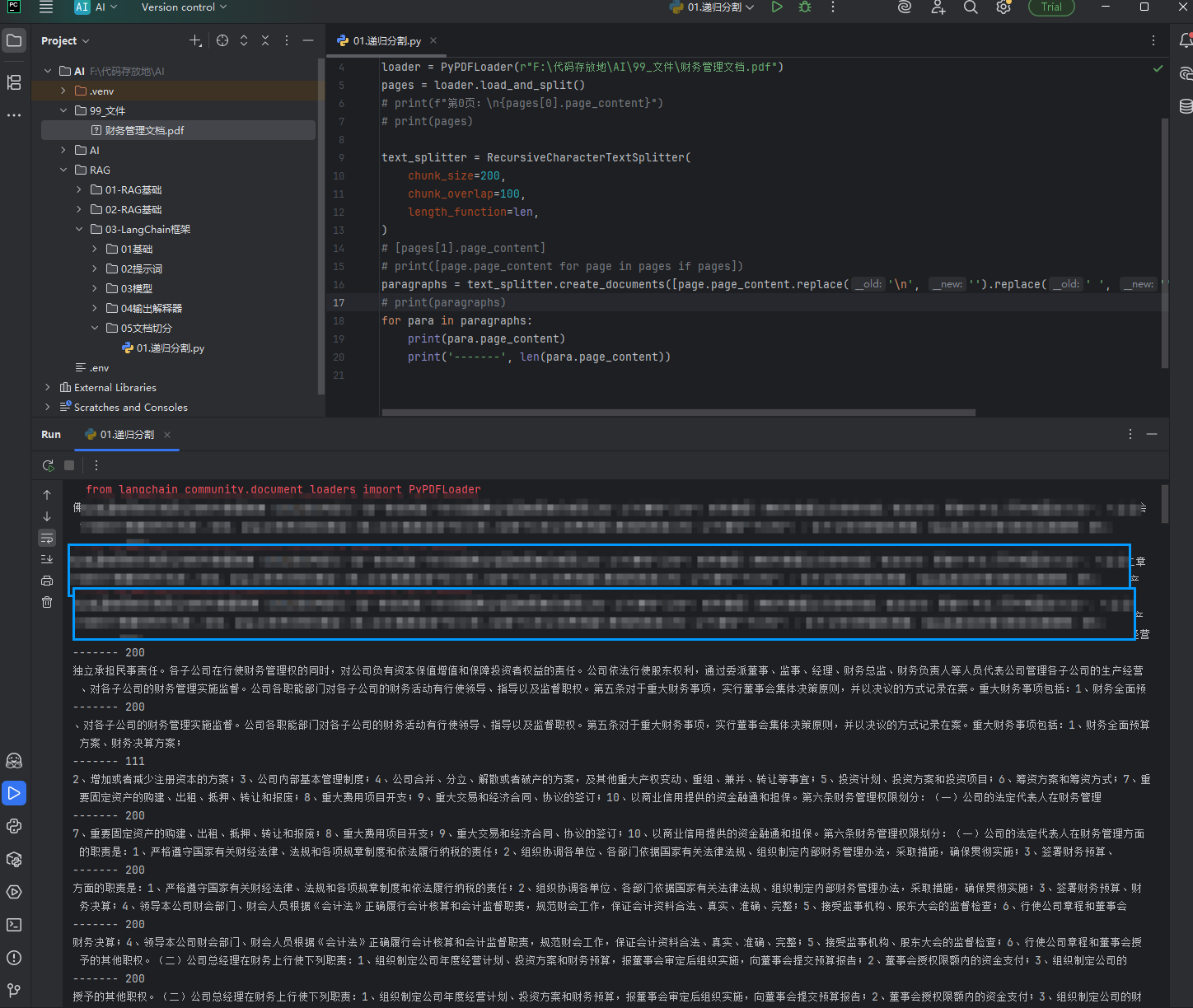
保存到向量
如下图:
之前我们需要自己写保存数据库的代码,现在不需要了,只需要一行代码就可以保存和查询,langChain都给我们做好了
pythonimport os from langchain_huggingface.embeddings import HuggingFaceEmbeddings from langchain_chroma import Chroma from langchain_community.document_loaders import PyPDFLoader from langchain_text_splitters import RecursiveCharacterTextSplitter from dotenv import load_dotenv load_dotenv() # 读取文件 loader = PyPDFLoader(r"F:\代码存放地\AI\99_文件\财务管理文档.pdf") pages = loader.load_and_split() text_splitter = RecursiveCharacterTextSplitter( chunk_size=200, chunk_overlap=100, length_function=len, add_start_index=True, ) # 将数据进行切割成块 paragraphs = text_splitter.create_documents([page.page_content.replace('\n', '').replace(' ', '') for page in pages if pages]) # print(paragraphs) # 创建嵌入模型 model_name = r'E:\AiModel\Local_model\maidalun\bce-embedding-base_v1' embeddings = HuggingFaceEmbeddings(model_name=model_name) # 创建chroma数据库,并将文本数据个向量化的数据存入 db = Chroma.from_documents(paragraphs, embeddings, persist_directory="chroma_db") # 一行代码搞定 # db = Chroma(persist_directory="chroma_db", embedding_function=embeddings) # 在数据库中进行搜索 query = "会计核算基础规范" docs = db.similarity_search(query) # 一行代码搞定 for doc in docs: print(f"{doc}\n-------\n")
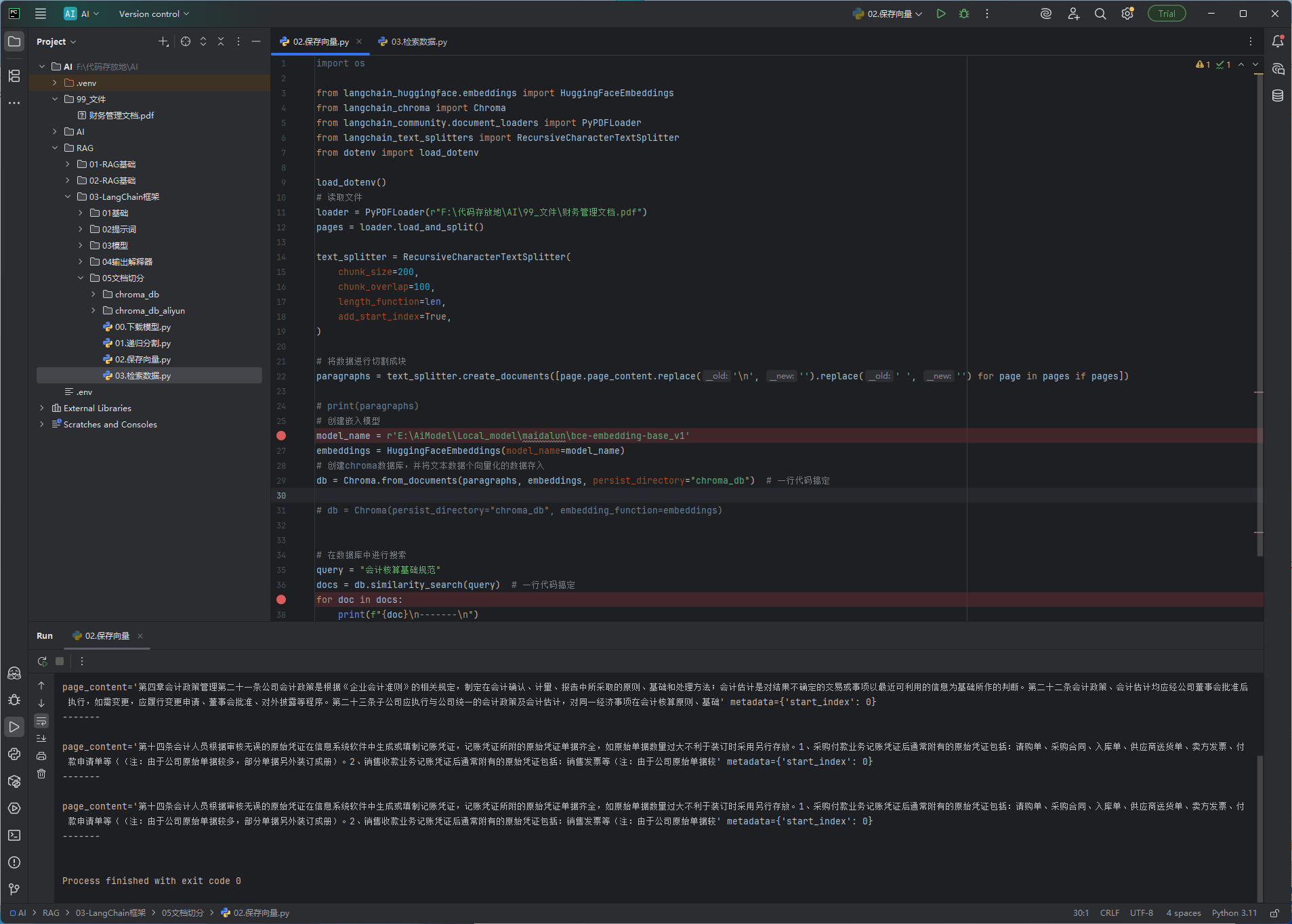
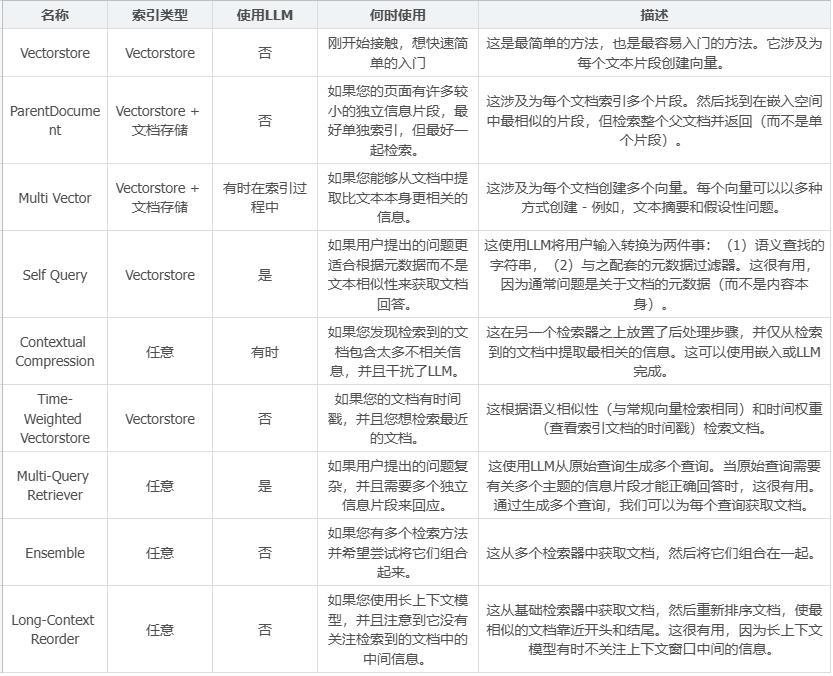
Retrievers检索器
检索器它比之前向量数据库的方式多了些功能:如下图
效果图:
注意执行下发的代码,要确保之前执行了上方的Chroma.from_documents创建了数据库文件
pythonimport os from langchain_huggingface.embeddings import HuggingFaceEmbeddings from langchain_chroma import Chroma from dotenv import load_dotenv # 加载环境变量(通用配置,本示例未使用API密钥) load_dotenv() # ====================== 向量模型配置 ====================== # 本地开源向量模型路径(百度BCE向量模型) model_name = r"E:\AiModel\Local_model\maidalun\bce-embedding-base_v1" # 初始化向量嵌入模型:将文本转为计算机可识别的数字向量 embeddings = HuggingFaceEmbeddings(model_name=model_name) # ====================== Chroma向量库加载 ====================== # 向量数据库本地存储路径 persist_directory = "./chroma_db" # 加载已存在的Chroma向量库(必须和入库时使用同一个向量模型) db = Chroma( persist_directory=persist_directory, embedding_function=embeddings ) print(f"成功加载 Chroma 数据库从 {persist_directory}") # ====================== 🚀 LangChain 全检索器详解(注释版+代码示例) ====================== # 一、【基础检索器】Chroma原生支持,最简单常用 # 1. 【默认】余弦相似度检索器 # 作用:按向量相似度从高到低返回结果,通用场景首选 # 参数:k=返回结果数量 retriever = db.as_retriever(search_kwargs={"k": 4}) # 2. 相似度阈值检索器 # 作用:只返回相似度超过指定阈值的结果,过滤低相关内容 # 代码:retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"k":4,"score_threshold":0.7}) # 3. MMR最大边际相关性检索器 # 作用:平衡相关性+多样性,避免结果重复 # 代码:retriever = db.as_retriever(search_type="mmr", search_kwargs={"k":4,"fetch_k":10}) # 二、【增强检索器】LangChain封装,解决复杂检索问题(注释内附完整代码示例) # 4. 多查询检索器(MultiQueryRetriever) # 作用:自动生成多个相似问题检索,提升召回率 # 【代码示例】 # from langchain.retrievers.multi_query import MultiQueryRetriever # from langchain_openai import ChatOpenAI # llm = ChatOpenAI(base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus") # retriever = MultiQueryRetriever.from_llm(retriever=db.as_retriever(k=4), llm=llm) # 5. 上下文压缩检索器(ContextualCompressionRetriever) # 作用:检索后压缩文本,只保留和问题相关的核心内容 # 【代码示例】 # from langchain.retrievers import ContextualCompressionRetriever # from langchain.retrievers.document_compressors import LLMChainExtractor # from langchain_openai import ChatOpenAI # llm = ChatOpenAI(base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-plus") # compressor = LLMChainExtractor.from_llm(llm) # retriever = ContextualCompressionRetriever(base_retriever=db.as_retriever(k=4), compressor=compressor) # 6. 集成检索器(EnsembleRetriever) # 作用:融合向量检索+关键词检索,兼顾语义与精准度 # 【代码示例】 # from langchain.retrievers import EnsembleRetriever # from langchain.retrievers.bm25 import BM25Retriever # bm25_retriever = BM25Retriever.from_documents(db.get()['documents']) # similarity_retriever = db.as_retriever(k=4) # retriever = EnsembleRetriever(retrievers=[bm25_retriever, similarity_retriever], weights=[0.5, 0.5]) # 7. 父文档检索器(ParentDocumentRetriever) # 作用:检索小块文本,返回完整父文档,保证语义完整 # 【代码示例】 # from langchain.retrievers import ParentDocumentRetriever # from langchain_text_splitters import RecursiveCharacterTextSplitter # child_splitter = RecursiveCharacterTextSplitter(chunk_size=200) # retriever = ParentDocumentRetriever(vectorstore=db, child_splitter=child_splitter) # 三、【高级检索器】带过滤/自定义逻辑 # 8. 元数据过滤检索器 # 作用:根据文档元数据(页码、文件、标签)精准过滤 # 代码:retriever = db.as_retriever(search_kwargs={"k":4,"filter":{"page":0}}) # ====================== 当前使用:基础相似度检索器 ====================== # 实例化检索器:返回相似度最高的4条结果 retriever = db.as_retriever(search_kwargs={"k": 4}) # ====================== 执行检索 ====================== # 定义查询问题 query = "会计核算基础规范" # 调用检索器,匹配向量库中最相关的文档 docs = retriever.invoke(query) # 遍历打印检索结果(编号+文本内容) for i, doc in enumerate(docs, 1): print(f"结果 {i}:\n{doc.page_content}")