目录
[1.0 简介](#1.0 简介)
[1.0 消息](#1.0 消息)
[2.0 提示词模板](#2.0 提示词模板)
[(3)使用LangChain Hub的提示词模板](#(3)使用LangChain Hub的提示词模板)
[3.0 少样本提示](#3.0 少样本提示)
[(1) 概念](#(1) 概念)
[4.0 输出解析器](#4.0 输出解析器)
[5.0 文档加载器](#5.0 文档加载器)
[(3) Document文档类](#(3) Document文档类)
[6.0 文本分割器](#6.0 文本分割器)
[7.0 文本向量](#7.0 文本向量)
[8.0 检索器](#8.0 检索器)
四、使用LangSmith跟踪LLM应用
1.0 简介
(1)引入
使用LangChain构建的许多应用程序,可能会包含多个步骤和多次的LLM调用
随着这些应用程序变的越来越复杂,作为开发者,我们能够检查链或代理内部到底发生了什么变得至关重要。最好的方法是使用LangSmith。 官网:LangSmith
LangSmith 与框架⽆关,它可以与 langchain 和 langgraph ⼀起使⽤,也可以不使⽤。LangSmith 是 ⼀个⽤于帮助我们构建⽣产级 LLM 应⽤程序的平台,它将密切监控和评估我们的应⽤。
五大核心能力:追踪 评估 监控 管理 标注
(2)环境搭建与快速开始
申请LangSmith API Key 点击Settings 就会跳转到"API Keys"设置⻚⾯,若没有跳转,可以在左侧 tab 栏中找到进⼊。 顺便看看LangSmith长啥样

创建完成后保存好你的key 配置两个环境变量
python
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY="你的 LangSmith API Key"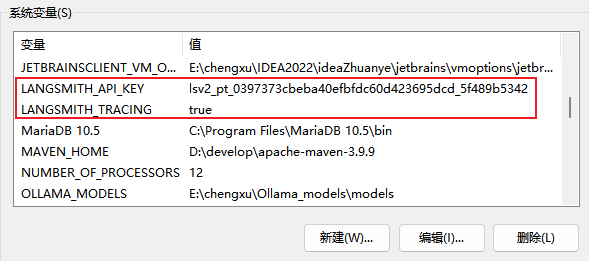
配置完成后 Python SDK安装:
LangSmith的Python SDK是独立包 不依赖LangChain 如果你同时使用LangChain,需要额外安装
下面的安装命令涵盖了本指南所有示例的依赖,建议在虚拟环境中安装,避免版本冲突:
python
# npm 项目
npm install langsmith
# 如果同时使用 LangChain.js
npm install langchain @langchain/openai @langchain/core
# yarn 项目
yarn add langsmith
# pnpm 项目
pnpm add langsmith安装完成后,在TypeScript项目中可以直接导入,SDK自带完整的类型定义,无需额外安装@types/langsmith
在项目根目录创建 .env 文件来管理这些变量
python
# .env 文件示例(不要提交到 Git!)
LANGCHAIN_TRACING_V2=true
LANGCHAIN_API_KEY=ls__your_actual_api_key_here
LANGCHAIN_PROJECT=my-first-langsmith-project
OPENAI_API_KEY=sk-your_openai_key_here记得将 .env 加入 .gitignore,防止 Key 泄露
python
#在 .gitignore 中添加
echo ".env" >> .gitignore
echo ".env.local" >> .gitignore
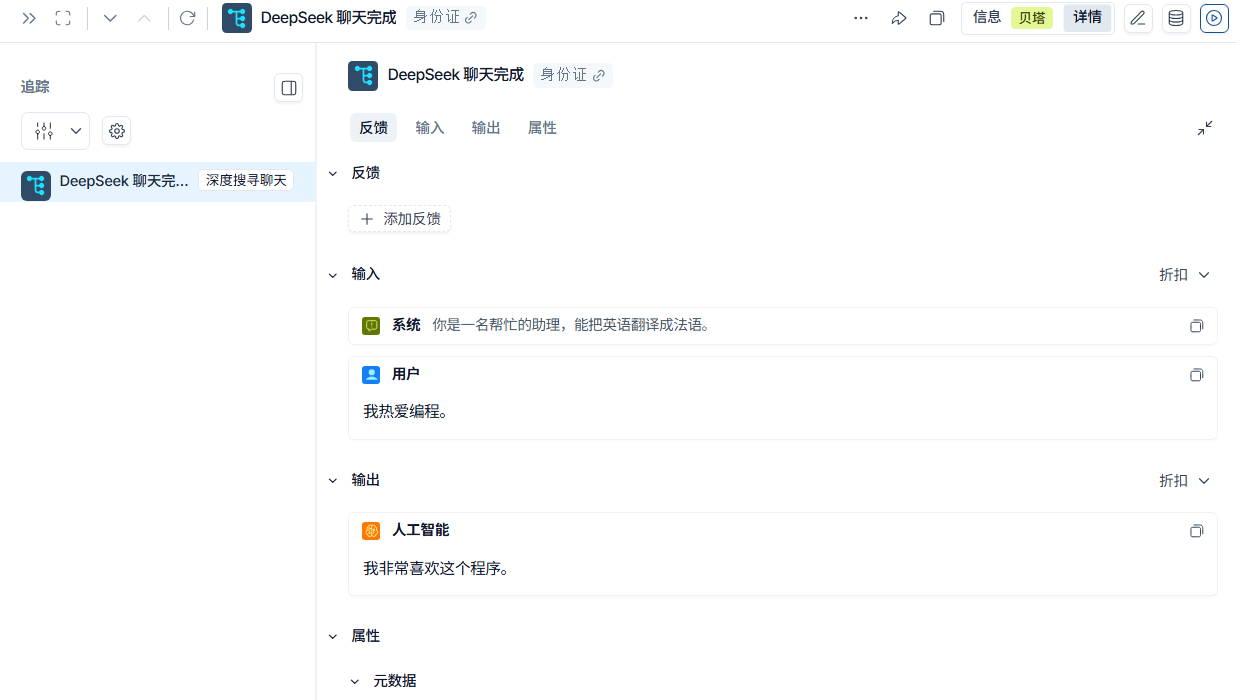
(3)效果展示
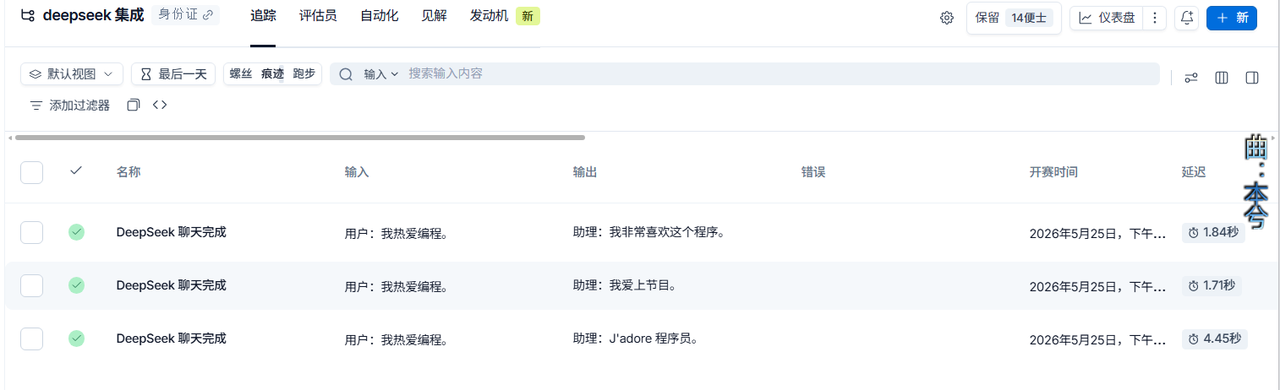
跟踪会以瀑布流形式展⽰调⽤的完整步骤,以及每个步骤的详细信息和耗时。
让我们能够检查内部到底发⽣了什么 //不过我这里的例子有点简单
五、核心组件
前置说明:从这⼀⼩节开始,我们将会学习⼤量的概念、术语,及其具体⽤法和对应的接⼝⽅法。
为了让整个交互流程更规范、更⾼效,LangChain 定义了⼀系列的组件使我们与⼤模型的交互更规范。
因此在学习过程中,有⼏点要提前强调:
-
理解每个组件的作⽤和适⽤场景是最重要的,不需要死记硬背接⼝和参数;
-
因为课程中会逐步教⼤家如何查阅官⽅⽂档,掌握⾃主查询的⽅法才是关键;
-
但前期我们仍会详细讲解常⽤接⼝和参数,随着内容深⼊,将更侧重核⼼功能与查询思路的培养。
重要的内容我们都会覆盖到,⼤家可以放⼼。
1.0 消息
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出 以及可能与对话关联的任何其他熵下文或元数据。
(1)LLM消息结构
每条消息都有⼀个⻆⾊和内容,以及因 LLM 的不同⽽不同的附加元数据。
• 消息⻆⾊ (Role):⽤来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。
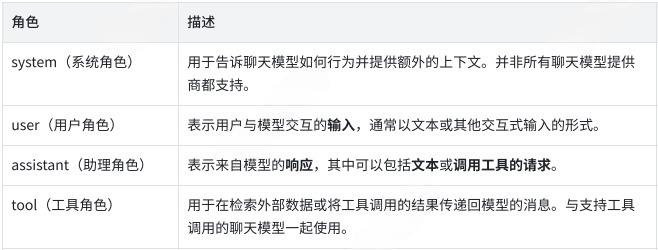
• 消息内容 (Content):表⽰多模态数据 (例如,图像、⾳频、视频)的消息⽂本或字典列表的内容。内容的具体格式可能因底层不同的 LLM ⽽异。⽬前,⼤多数模型都⽀持⽂本作为主要内容类型,对多模态数据的⽀持仍然有限。
• 消息其他元数据 (Additional metadata)
(2)LangChain消息
LangChain 提供了⼀种统⼀的消息格式,可以跨聊天模型使⽤,允许⽤⼾使⽤不同的聊天模型,⽽⽆需担⼼每个模型提供商使⽤的消息格式的具体细节。
这些模型提供商不同,但对于其输⼊和输出,统⼀使⽤ LangChain 的消息格式。LangChain 消息格式
主要分为五种,分别是:

这⼏个消息类型,我们已经全部⻅过!它们都是 LangChain BaseMessage 的⼦类,全部是作为
LangChain 聊天模型的输⼊和输出!!
BaseMessage抽象消息类:
class langchain_core.messages.base.BaseMessage 是作为 LangChain 聊天模型的输⼊和输出
参数如下:
• content :消息的字符串内容。
• additional_kwargs :与消息关联的其他有效负载数据。对于来⾃ AI 的消息,可能包括模
型提供程序编码的⼯具调⽤。
• response_metadata :响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
• type :消息的类型。必须是消息类型唯⼀的字符串。此字段的⽬的是在对消息进⾏反序列化时
⽅便地识别消息类型。
• name :消息名称,为消息提供⼀个⼈类可读的名称。该字段的使⽤是可选的,是否使⽤它取决
于模型实现。
• id :消息的可选唯⼀标识符。理想情况下,这应该由创建消息的提供者/模型提供。
//下面是辅助理解
-
去重:在链式调用或消息重试时,通过
id避免同一回复被重复处理。 -
日志追踪:将
id记录到日志,当多条消息内容相同时仍能区分。 -
持久化:用
id作为数据库主键,天然支持幂等存储。
内置方法:
pretty_print() **→**None :打印消息的漂亮表⽰。
pretty_repr(html: bool = False) **→**str :获得消息的漂亮表⽰。
◦ 请求:是否将消息格式化为 HTML。如果为 True,则消息将使⽤ HTML 标记进⾏格式化。默 认值为 False。
◦ 响应:这是消息的漂亮表⽰。 text() **→**str :获取消息的⽂本内容。
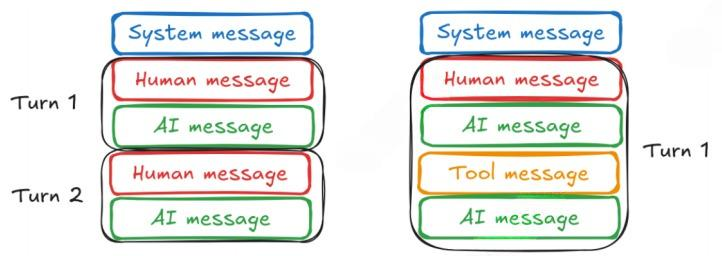
对话模式:
大多数对话都以设置对话上下文的系统消息开始。接下来是包含⽤⼾输⼊的⽤⼾消息,然后是包含模型响应的助⼿消息。
(3)缓存历史消息
多轮对话
虽然很方便,但⽬前我们的系统还不⽀持此功能
只要将历史消息,重新发送给聊天模型,那么就可以实现多轮对话的功能。
内存 缓存
对于历史消息的管理就显得尤为重要。
在 LangChain ⽼版本中,可以使⽤ RunnableWithMessageHistory 消息历史类来包装另⼀个 Runnable 并为其管理聊天消息历史记录。它将跟踪模型的输⼊和输出,并将其存储在某个数据存储中。未来的交互将加载这些消息,并将其作为输⼊的⼀部分传递给链。
python
store = {}
# 接受一个 session_id 并返回一个消息历史对象。
# 这个 session_id 用于区分不同的对话,并应作为配置的一部分在调用新链时传入
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
# InMemoryChatMessageHistory() 将消息存储在内存列表中。
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装model,管理聊天消息历史记录
with_message_history = RunnableWithMessageHistory(model, get_session_history)
config = {"configurable": {"session_id": "1"}}
with_message_history.invoke(
[HumanMessage(content="Hi! I'm Bob")],
config=config,
).pretty_print()
with_message_history.invoke(
[HumanMessage(content="What's my name?")],
config=config,
).pretty_print()
结果是:
================================== Ai Message
==================================
Hi Bob! How can I assist you today?
================================== Ai Message
==================================
Your name is Bob! How can I help you today?
记忆功能已经实现!从 LangChain 的 v0.3 版本开始,官⽅建议 LangChain ⽤⼾不要使⽤RunnableWithMessageHistory ,⽽是利⽤ LangGraph 持久性 来完成(⻅ LangGraph 章节)。
(4)管理历史消息
前置概念
上下文窗口:
上下⽂窗⼝可以理解为模型的"短期⼯作记忆区",即 LLM 在⼀次处理请求时,所能查看和处理的最⼤ Token 数量,它包含了:
• ⽤⼾的输⼊
• ⼤模型的输出
• 有时还包括系统指令(SystemMessage)和对话历史。
Token:在⾃然语⾔处理(NLP)中,Token 是⽂本的基本单位。它不是完全等同于⼀个单词或⼀个汉字,⽽
是⼀个更细粒度的划分。
为什么⽤ Token?计算机⽆法直接理解⽂字,它需要将⽂本转换为数字(向量)。Tokenization(令
牌化)就是这个转换过程的第⼀步,将句⼦分解成模型可以理解和处理的碎⽚。
• 对于英⽂: 1个Token ~= 4个字符或0.75个单词
• 对于中⽂: 1个汉字 ~= 1.5-2个Tokens
好看的图片分享给你:

消息裁剪:
• 输⼊ = 系统消息 + 对话历史 + 最新⽤⼾问题
• 对于模型来说,并不真正"记忆",⽽是每次都将完整的上下⽂重新输⼊。
如果有累积了很⻓的消息历史记录,则需要管理传递给模型的消息的⻓度。 trim_messages 可⽤于将聊天历史记录的⼤⼩减⼩为指定的令牌计数或指定的消息计数。
例:接下来让我们对消息进⾏裁剪,我们只希望将来输⼊时,最多输⼊ 65 tokens,超出的需要按照⼀定的"规则"进⾏裁剪。
python
# 使用 trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=65, # 修剪消息的最大令牌数,根据你想要的谈话长度来调整
strategy="last", # 修剪策略:
# "last"(默认):保留最后的消息。
# "first":保留最早的消息。
token_counter=model, # 传入一个函数或一个语言模型(因为语言模型有消息令牌计数方法)
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model
print(chain.invoke(messages))
可以看⻅,此时我们的输⼊ message 已经被修剪了。被修剪了哪些消息呢?来看下:
trimmer = trim_messages(
...
)
# 打印经过裁剪器裁剪后的结果
print(trimmer.invoke(messages))
从结果来看,确实是按照我们给定的裁剪"规则"来完成的。修剪聊天记录后,⽣成的聊天记录(输
⼊)应该有效,需遵循对话模式原则:基于消息数的修剪:
除了基于 token 的修剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这
种情况下, max_tokens 将控制最⼤消息数。
python
# 使用 trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=11, # 最大消息数
strategy="last", # 修剪策略:
# "last"(默认):保留最后的消息。可获取消息列表中的最后一个 max_tokens
# "first":保留最早的消息。
token_counter=len, # 根据消息数裁剪
include_system=True, # 如果想始终保留初始系统消息,可以指定
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)消息过滤:
在更复杂的场景下,我们可能会使⽤消息列表来跟踪状态,例如我们可能只想将这个完整消息列表的 ⼦集传递模型调⽤,⽽不是所有的历史记录。
filter_messages ⽅法则可以轻松地按类型、ID 或名称过滤 message
python
下⾯演⽰相关过滤⽰例,⾸先准备消息列表:
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, filter_messages
# 历史消息记录
messages = [
SystemMessage("你是一个聊天助手", id="1"),
HumanMessage("示例输入", id="2"),
AIMessage("示例输出", id="3"),
HumanMessage("真实输入", id="4"),
AIMessage("真实输出", id="5"),
]
按照类型+ID进行筛选:
print(filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"]))
# 结果如下:
# [
# HumanMessage(content='示例输入', additional_kwargs={}, response_metadata={}, name='example_user', id='2'),
# HumanMessage(content='真实输入', additional_kwargs={}, response_metadata={}, name='bob', id='4'),
# AIMessage(content='真实输出', additional_kwargs={}, response_metadata={}, name='alice', id='5')
# ]消息合并:
若我们的消息列表存在连续某种类型相同的消息,但实际上某些模型不⽀持传递相同类型的连续消息。因此对于这种情况,我们可以使⽤ merge_message_runs ⽅法轻松合并相同类型的连续消息。
python
# 历史消息记录
messages = [
SystemMessage("你是一个聊天助手。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使用 LangChain?"),
HumanMessage("为什么要使用 LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage("不过别担心,它不会"分散"你的注意力!"),
HumanMessage("选择LangChain还是LangGraph?"),
]
merged = merge_message_runs(messages)
# 打印合并后的每个消息
print("\n".join([repr(x) for x in merged]))
合并结果
SystemMessage(content='你是⼀个聊天助⼿。\n你总是以笑话回应。', additional_kwargs=
{}, response_metadata={})
HumanMessage(content='为什么要使⽤ LangChain?\n为什么要使⽤ LangGraph?',
additional_kwargs={}, response_metadata={})
AIMessage(content='因为当你试图让你的代码更有条理时,LangGraph 会让你感到"节点"是个好
主意!\n不过别担⼼,它不会"分散"你的注意⼒!', additional_kwargs={},
response_metadata={})
HumanMessage(content='选择LangChain还是LangGraph?', additional_kwargs={},
response_metadata={})
原来是7条 现在变成5条了
调用大模型:
## ⽅式⼀:
merged = merge_message_runs(messages)
model.invoke(messages).pretty_print()
## ⽅式⼆:
merger = merge_message_runs()
chain = merger | model
chain.invoke(messages).pretty_print()
打印结果:
================================== Ai Message
==================================
这就像选择汉堡还是热狗!如果你想要⼀个多层次的体验,选择LangChain;如果你想要⼀个清晰的链
接,LangGraph就像是你的"⽀架"!让你的代码加个"料"!
最终模型根据合并后的对话历史(系统消息要求以笑话回应)
对"选择 LangChain 还是 LangGraph"给出了一个幽默的比喻答案。2.0 提示词模板
(1)简介
提⽰词模板(Prompt Template)是 LangChain 的核⼼抽象之⼀,它被⼴泛应⽤于构建⼤语⾔模型
(LLM)应⽤的各个环节。 简单来说,只要是需要动态、批量、或有结构地向⼤语⾔模型【发送请求】的地⽅,⼏乎都会⽤到提⽰词模板。
在LangChain中,我们可以定义一个模板,定义好之后,可以使用该模板
由此可得:提⽰词模板就是⼀个可复⽤的提⽰词蓝图,它允许我们动态地⽣成提⽰词,⽽不是每次都⼿动编写完整的提⽰词。它类似于编程中的字符串格式化功能。你创建⼀个带有"占位符"的模板,然后在运⾏时,用具体的值(变量)填充这些占位符,从⽽⽣成⼀个最终发送给 LLM 的完整提⽰词。
提⽰词模板解决了以下⼏个核⼼问题:
-
可复⽤性: 只需定义⼀个模板,就可以⽤于⽆数个类似的查询。
-
关注点分离: 将提⽰词的结构和逻辑(⼯程)与具体的内容和数据分离开。提⽰⼯程师可以专注于优化模板,⽽应⽤程序则负责提供变量值。
-
⼀致性: 确保发送给LLM的提⽰词结构统⼀,这有助于获得更稳定、可预测的输出结果。
-
可维护性: 如果需要修改提⽰词的⻛格或结构,只需修改⼀个模板⽂件,⽽不⽤在代码的⽆数个地⽅进⾏修改
(2)用法
字符串模板:
LangChain 提供了 PromptTemplate 类来轻松实现这⼀功能。 PromptTemplate 实现了标准的Runnable 接⼝
python
from langchain_core.prompts import PromptTemplate
# 1. 定义模板
prompt_template = PromptTemplate.from_template("Translate the following into {language}")
# 2. 实例化模板
print(prompt_template.invoke({"language": "Chinese"}))
输出结果:
text='Translate the following into Chinese'
class langchain_core.prompts.prompt.PromptTemplate 类
参数:template 提示模板 input_variables:需要其值作为输入的变量的名称列表
内置方法:form_template()从模板定义提示模板 方法返回了一个PromptTemplate实例聊天消息模板:
ChatPromptTemplate 模板:专为 LangChain 聊天模型设计。可以⽅便地构建包含
SystemMessage 、 HumanMessage 、 AIMessage 的消息模板
python
from langchain_core.prompts import ChatPromptTemplate
# 1. 设置模板
prompt_template = ChatPromptTemplate(
[
("system", "Translate the following into {language}."),
("user", "{text}")
]
)
# 2. 实例化模板,获取消息实例
messagesValue = prompt_template.invoke(
{
"language": "Chinese",
"text": "what is your name?"
}
)
messages = messagesValue.to_messages()
print(messages)
结果是:
[
SystemMessage(content='Translate the following into Chinese.', additional_kwargs={}, response_metadata={}),
HumanMessage(content='what is your name?', additional_kwargs={}, response_metadata={})
]
这段代码就是在教我们怎么用模板来批量生产标准格式的聊天信息现在 我们可以将该结果发送给任何一个LLM来获取答案
python
# 3. 输出解析
parser = StrOutputParser()
chain = model | parser
print(chain.invoke(messages))
结果是:
你的名字是什么?由于ChatPromptTemplate同样也实现了标准的Runnable接口,因此我们还可以通过链来完成调用。
python
# 3. 定义链
chain = prompt_template | model | parser
for token in chain.stream(
{
"language": "English",
"text": "你好,我叫斯蒂芬,很高兴认识你"
}
):
print(token, end="|")
结果是:
|Hello|,| my| name| is| Stephen|,| nice| to| meet| you|.||消息占位符
在上⾯的 ChatPromptTemplate 中,我们看到了如何格式化两条消息,每条消息都是⼀个字符串。但如果我们希望将消息插⼊特定位置怎么办?使⽤ MessagesPlaceholder
python
("system", "你是⼀个聊天助⼿"),
MessagesPlaceholder("msgs") # 消息占位符
messages_to_pass = [
HumanMessage(content="中国首都是哪里?"),
AIMessage(content="中国首都是北京。"),
HumanMessage(content="那法国呢?")
]
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
print(formatted_prompt)(3)使用LangChain Hub的提示词模板
LangChain Hub 是⼀个⽤于上传、浏览、拉取和管理提⽰词(prompts)的地⽅。
随着 LLM 的发展,提⽰变得越来越重要。LangChain 正在打造⼀个与像 GitHub 这样的传统平台,GitHub⻓期以来⼀直是共享和协作代码的⾸选平台。于是推出了 LangChain Hub 平台。
LangChain Hub 创建⼀个分享和发现 Prompt 的平台,使得开发者可以更容易地发现新⽤例和精炼提⽰。 这⼀举措使提⽰⼯程师更容易合作,重复使⽤现有的提⽰,并对其进⾏微调以实现特定的结果,从⽽加速对话代理和其他基于语⾔的应⽤程序的开发和部署。早期的时候 LangChain Hub 有Prompt、Chain、Agent,现在只有Prompt。 LangChain Hub 官⽹地址:Hub - LangSmith。通过登录到 Hub 来探索所有现有提⽰词。
⽬前收藏最⾼的提⽰词模板是: hardkothari/prompt-maker 。我们就以它为⽰例,演⽰⼀下如何使⽤ LangChain Hub 上的提⽰。
Prompt Maker 模板是⼀个【提⽰⽣成器】 ,它可以⾃动化优化提⽰的过程,从⽽提⾼语⾔模型在
各种应⽤中的质量和效果。
要想使⽤该能⼒,需要先申请并配置 LangSmith 环境变量: LANGSMITH_API_KEY="你的
LangSmith API Key" 。接着,需要从 hub 拉取相应的提⽰,并使⽤,代码如下:
python
from langchain_openai import ChatOpenAI
from langsmith import Client
# 从 hub 拉取 "hardkothari/prompt-maker" 提示词模板
client = Client()
prompt = client.pull_prompt("hardkothari/prompt-maker", include_model=True)
# 定义模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义链
chain = prompt | model
# 循环交互
while True:
task = input("\n你的任务是什么?(输入 quit 退出聊天)\n")
if task == 'quit':
break
lazy_prompt = input("\n你当前的提示是什么?(输入 quit 退出聊天)\n")
if lazy_prompt == 'quit':
break
print("\nResponse:")
chain.invoke({
'lazy_prompt': lazy_prompt,
'task': task
}).pretty_print()通过使⽤这个模板,可以⼤ 减少⼿动调整提⽰所需的⼯作量,从⽽节省时间和资源。Prompt Maker通过分析初始提⽰的结构和内容,然后应⽤⼀组预定规则或算法来优化提⽰,以提⾼响应质量、清晰度和相关性。这在提⽰的质量对模型的输出有很⼤影响的场景中特别有⽤,⽐如客⼾服务机器⼈、对话代理或数据分析任务。
//这段代码相当于请了一个 提示词专家 你给它说"我想做什么任务"和'我大概想怎么问"。它就会帮你写出一段非常详细,规范,好用的提示词,让你可以直接拿去问别的大模型。
结果看一看:
python
写一个快排代码你当前的提示是什么?(输入 quit 退出聊天)开发专家,需中文回复Response:================================== Ai Message==================================As a coding expert specialized in algorithms and data structures, please writea detailed implementation of the Quick Sort algorithm in Python.
Instructions:
Your code should be well-structured, with clear comments explaining each stepof the algorithm. Additionally, include an example of how to use the functionto sort a list of integers and print the sorted result.
Context:
The implementation should focus on efficiency and clarity, ideally spanning nomore than 20 lines of code. Ensure that the prompt is in Chinese, andstructure your response to be easily understandable for readers with a basicknowledge of programming.Example:翻译一下中文体会一下
python
中文翻译:
作为一名专精于算法和数据结构的编码专家,请用 Python 编写一个详细的快速排序算法实现。
指令要求:
你的代码应该结构良好,并附有清晰的注释,解释算法的每一步。此外,请包含一个示例,展示如何使用该函数对整数列表进行排序,并打印排序后的结果。
背景说明:
实现应注重效率和清晰度,理想情况下代码行数不超过 20 行。请确保提示词使用中文,并且你的回答结构要让具备基础编程知识的读者容易理解。
示例格式:
def quick_sort(arr):
# 快速排序函数实现
...
return sorted_arr
# 使用示例
unsorted_list = [34, 7, 23, 32, 5, 62]
print(quick_sort(unsorted_list))
请提供完整的代码以及任何有助于理解快速排序算法的附加说明。谢谢!3.0 少样本提示
(1) 概念
少样本提⽰是⼀种通过向 LLM 提供少量具体⽰例或样本,来教会它如何执⾏某项特定任务的技术。提
⾼模型性能的最有效⽅法之⼀是给出⼀个【模型⽰例】指导⼤模型你想做什么、怎么做。
这能解决什么问题?LLM 虽然知识渊博,但有时我们需要它以⾮常特定的格式、⻛格或逻辑来回答问题。提供正确的⽰例可以减少模型"胡说⼋道"或犯低级错误的概率,将其输出约束在你提供的范例范围内。
(2)实现少样本提示
实现少样本提⽰的第⼀步也是最重要的⼀步是提出⼀个好的⽰例数据集。
好的示例应该在运行时相关、清晰、信息丰富,并提供模型不知道信息。如果我们给出的例子,就能很好的提示大模型。
如何让⼤模型看懂这份⽰例呢?之前我们说过聊天模型读的是聊天消息。因此,接下来我们需要将⽰例集实例化成聊天模型可以读懂的聊天消息。对于 LangChain 就需要创建⼀个FewShotChatMessagePromptTemplate 对象来实例化⽰例集。FewShotChatMessagePromptTemplate 是⼀个提⽰词模板,专⻔⽤来将⽰例集实例化为聊天消息。
python
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt, # ChatPromptTemplate,⽤于格式化单个⽰例
examples=examples, # 样本⽰例
)FewShotChatMessagePromptTemplate 也实现了标准的Runnable接口
(3)使用案例
案例一:推理推导
python
我们希望输⼊:
《教⽗》和《星球⼤战》的导演来⾃同⼀个国家吗?
让聊天模型可以先分析再得出结论,⽽不是直接得出结论。分析过程需要展⽰出来:
创建字符串模板
创建示例集
examples = [
{
"question": "李⽩和杜甫,谁更⻓寿?",
"answer": """
是否需要后续问题:是的。
后续问题:李⽩享年多少岁?
中间答案:李⽩享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李⽩
"""
},
接下来我们需要格式化完整的样本提示
此时可以创建⼀个 FewShotPromptTemplate 对象来初
始化少样本提⽰模板。其接收少量⽰例和少量⽰例的格式化程序。
from langchain_core.prompts import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt, # PromptTemplate,⽤于格式化单个⽰例
suffix="Question: {input}", # 放在⽰例之后的提⽰模板字符串。
input_variables=["input"], # 变量的名称列表,这些变量的值需要作为提⽰词的输⼊。
)
print(
prompt.invoke({"input": "《教⽗》和《星球⼤战》的导演来⾃同⼀个国家吗?"}).to_string()
)
结果是: //看一看这个惊艳的成果吧
================================== Ai Message
==================================
是否需要后续问题:是的。
后续问题:《教⽗》的导演是谁?
中间答案:《教⽗》的导演是弗朗西斯·福特·科波拉。
后续问题:弗朗西斯·福特·科波拉来⾃哪⾥?
中间答案:弗朗西斯·福特·科波拉来⾃美国。
后续问题:《星球⼤战》的导演是谁?
中间答案:《星球⼤战》的导演是乔治·卢卡斯。
后续问题:乔治·卢卡斯来⾃哪⾥?
中间答案:乔治·卢卡斯也来⾃美国。
所以最终答案是:是案例二: 使用示例数据增强LangChain信息提取能力
在我们学习【结构化输出】⼩节时,其中有⼀个使⽤场景是使⽤结构化输出进⾏信息提取。当时说明可以结合少样本提⽰来实现。于是在这⾥,我们来实现⼀个基于 LangChain 的结构化信息提取系统,专⻔从⽂本中提取⼈物相关信息。
python
例如我们希望,对于输⼊以下⽂本:
"篮球场上,⾝⾼两⽶的中锋王伟默契地将球传给⼀⽶七的后卫挚友李明,完成⼀记绝杀。这对⽼友
⽤⼗年配合弥补了⾝⾼的差距。"
代码会提取出结构化数据,如下所⽰:
people=[
Person(name="王伟", height_in_meters="2", skin_color=None, hair_color=None),
Person(name="李明", height_in_meters="1.7", skin_color=None, hair_color=None)
]
第一步:定义结构化返回对象
第二步:定义两个关键示例,每个示例包含文本 和 希望输出
第三步:定义提示词模板
第四步:构造请求的消息列表
第五步:测试(4)示例选择器
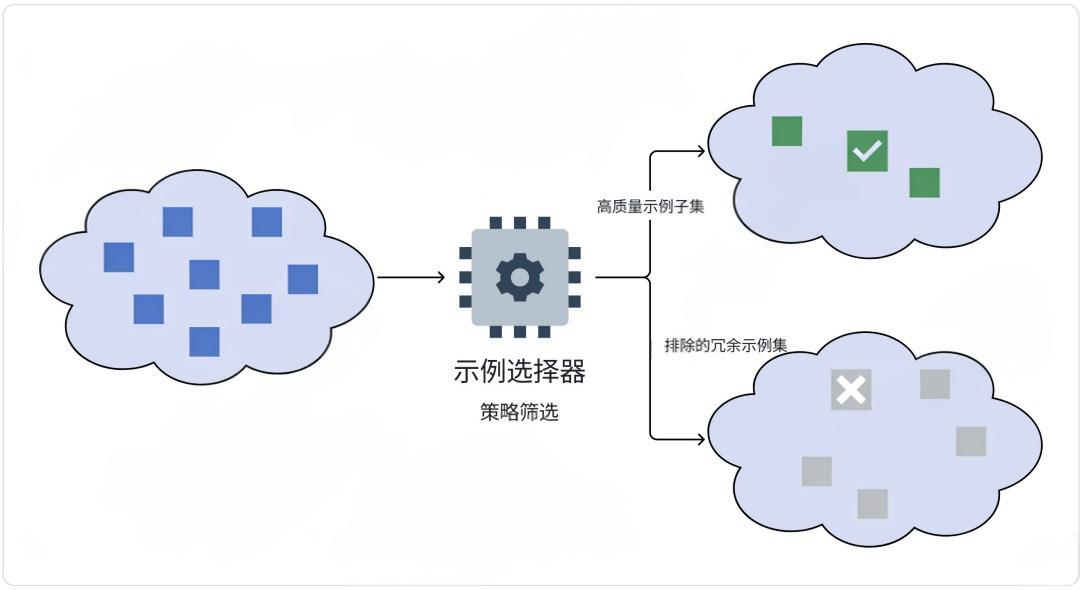
⼀旦我们有了⽰例数据集,就需要考虑提⽰中应该有多少个⽰例。
关键的权衡是,更多的⽰例通常会
提⾼性能,但更⼤的提⽰会增加成本和延迟。超过某个阈值,太多⽰例可能会开始混淆模型。
找到正确数量的⽰例在很⼤程度上取决于模型、任务、⽰例的质量以及成本和延迟限制。有趣的是,模型越好,它需要精准的⽰例就越少。但其实,最佳的⽅法是使⽤不同数量的⽰例进⾏⼀些实验。
若此时我们有【⼤量】的⽰例数据集。对于⼤模型来说,就没必要全部使⽤与参考。我们需要有⼀种⽅法可以根据给定的输⼊,从数据集中选择⽰例。
选择策略:
Length:根据特定长度内可以容纳的数量选择示例
Similarity:使用输入和示例之间的 语义相似性 来决定选择哪些示例
MMR:使用输入和示例之间的 最大边际相关性来决定选择哪些示例
Ngram:使用输入和示例之间的 NLP里的相似性衡量问题
按长度选择示例 Length:
实现按⻓度选择⽰例的⽰例选择器是:
class langchain_core.example_selectors.length_based.LengthBasedExampleSelector 类,其参数如下:
• example_prompt :PromptTemplate,⽤于格式化⽰例的提⽰模板。
• examples :模板所需的⽰例列表。
• max_length :提⽰的最⼤⻓度,超过该⻓度将剪切⽰例。
• get_text_length :测量提⽰⻓度的⽅法。默认为字数统计。
内置⽅法:
add_example(example: dictstr, str) :将新⽰例添加到列表中。
◦ 输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
select_examples(input_variables: dictstr, str) **→**listdict :根据输⼊⻓度选择要使⽤的⽰例。
◦ 输⼊:⼀个字典,其中键作为输⼊变量,值作为其值。
◦ 输出:要包含在提⽰中的⽰例列表。
python
核心代码:
# ⻓度⽰例选择器
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
# 格式化⽰例的最⼤⻓度。
# ⻓度由下⾯的get_text_length函数测量。
max_length=25,
# ⽤于获取字符串⻓度的函数,⽤于确定包含哪些⽰例。
# 如果没有指定,它是作为默认值提供的。
# 该函数返回⼀个整数,表⽰字符串中由换⾏符或空格分隔的"单词"数量
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
#用于示例化示例的模板
dynamic_prompt = FewShotPromptTemplate(
# 提供了⼀个ExampleSelector⽽不是examples。
example_selector=example_selector按语义相似性选择⽰例(Similarity)
什么是语义相似?它是衡量⽂本在【含义上】的接近程度。例如下述两段⽂本:
text1 = "我喜欢猫"
text2 = "我讨厌狗"
这两段⽂本表⾯相似度低,但语义上都是表达对动物的态度。
再例如:
text1 = "苹果很甜"
text2 = "苹果市值创新⾼"
"苹果"可以指⽔果或公司,语义相似可以解决⼀词多义问题,因此这两段⽂本语义上不相似。
LangChain 能根据输⼊和⽰例之间的语义相似性来决定选择哪些⽰例,它通过查找与输⼊具有最⼤余 弦相似性的嵌⼊⽰例来实现这⼀点
按最大边际相关性选择示例 (MMR)
【最⼤边际相关性】就像团队经理(MMR算法)要组建⼀个团队。⽬标是选出⼀组"精华"结果,
⽽不是⼀个单⼀结果
• MMR 使⽤场景:
◦ 推荐系统:推荐与⽤⼾兴趣相关但⼜不同类型的物品,避免"信息茧房"。
◦ ⽂档摘要:从⻓⽂档中选择能代表主旨⼜包含不同信息的句⼦,避免摘要内容重复。
◦ RAG (检索增强⽣成):在从知识库检索完⼀堆相关⽂档后,使⽤ MMR 进⾏去重和多样化筛选,
再交给LLM⽣成答案,能有效提升答案质量和减少幻觉。
MaxMarginalRelevanceExampleSelector 类中方法:
from_examples() :根据⽰例集⽣成 MMR ⽰例选择器
add_example(example: dictstr, str) :将新⽰例添加到列表中
select_examples(input_variables: dictstr, str) **→**listdict :根据输⼊选择要使⽤的⽰例
通过ngram重叠选择示例 (Ngram)
什么是【ngram】?ngram 指⼀个⽂本序列中连续的 n 个词(word) 或字符(character)
什么是【ngram 重叠】?通过计算它们之间共同拥有的 ngram 数量来一种衡量两段⽂本相似度的方法。
例如下述两段⽂本:text1 = "苹果⼿机很好⽤" (分词后:苹果 ⼿机 很 好⽤)text2 = "这款⼿机很好⽤" (分词后:这款 ⼿机 很 好⽤ )这两段⽂本单词重复度很⾼,连续三个词的相同的情况也存在,因此 ngram 重叠⾼。
再看个例⼦:text1 = "苹果⼿机很好⽤" (分词后:苹果 ⼿机 很 好⽤)text2 = "iPhone ⾮常不错" (分词后: iPhone ⾮常 不错 )这两段⽂本在含义上⾮常相似,但它们的 ngram 重叠度为 0。
因此,传统 ngram 重叠是⼀种表⾯形式的匹配。它只关⼼词是否完全⼀样,但对于同义词却⽆法处理。
什么是【语义 ngram 重叠】?不再⽐较词本⾝,⽽是⽐较词背后的语义向量(Embedding)。也就
是说,它不是看两个词 苹果 和 iPhone 的字⾯是否相同,⽽是计算它们在语义空间中的向量是
否相似。如果相似度超过某个阈值,就认为它们"重叠"了。
使用场景:语义 ngram 重叠常⽤于需要更精准语义评估的场景,例如剽窃检测 , 能够发现那些改换了词汇但保留了核⼼思想的"智能"剽窃。
4.0 输出解析器
(1)简介
负责获取模型的输出,并将输出转换为更结构化的格式。当使⽤ LLM ⽣成结构化数据或规范化聊天模
型和 LLM 的输出时,这很有⽤。
⼤型语⾔模型(LLM)的输出本质上是⾮结构化的⽂本。但在构建应⽤程序时,我们通常希望得到结构化的、机器可读的数据,这样可以将其转换为更适合下游任务的格式。
输出解析器的作⽤就是架起这座桥梁:它们将 LLM 的⾮结构化⽂本输出转换为结构化格式。这使得与
LLM 的交互从"模糊的⽂本对话"变成了"精确的数据 API 调⽤",是构建可靠、⾼效 LLM 应⽤不可
或缺的组件。
(2)解析文本输出
其实对于使⽤ StrOutputParser 输出解析器输出⽂本,我们已经使⽤过多次了。对于StrOutputParser ,它也实现了标准的 Runnable 接⼝。若是不使⽤输出解析器,⽽是直接得到聊天模型返回的 AIMessage,⽂本内容则需要从消息中的content 字段获取。
(3)解析结构化对象输出
要输出结构化对象,需要⽤到的输出解析器是 PydanticOutputParser
(4)解析JSON输出
要输出 JSON 格式,需要⽤到的输出解析器是 JsonOutputParser 。
class langchain_core.output_parsers.json.JsonOutputParser 类 //关于这个类的参数可以自己在网上搜索
除了上⾯讲的⽂本、对象、JSON解析器,其实 LangChain 官⽅还提供了更多类型的解析器,如:
• XML 解析器: XMLOutputParser
• Yaml 解析器: YamlOutputParser
• CSV 解析器: CommaSeparatedListOutputParser
• 枚举解析器: EnumOutputParser
• ⽇期解析器: DatetimeOutputParser 等等,更多类型参
langchain_core | LangChain Reference
除此之外,LangChain 还⽀持我们⾃定义输出解析器,以将模型输出结构化为⾃定义格式,详细情况参考
LangChain overview - Docs by LangChain
5.0 文档加载器
(1)RAG介绍
//这部分知识在springAI里面提到过 那篇文章重点讲解
(2)RAG流程
RAG 的流程分为【离线数据处理】和【在线检索】两个过程。
上⾯提到,RAG 知识库可以是本地⽂档、公司内部⽂档等⼀些私有化数据。但这些私有数据或⽂档实际上并不能很好地被直接进⾏检索访问。因此需要将这些私有化数据构建成可以被检索的知识库,这就是离线数据处理要⼲的事情。经过离线数据后,知识则会按照某种格式以及排列⽅式存储在知识库中,等待被使⽤。
⽽在线检索则是我们依赖知识库查询,通过⼤模型⽣成结果的过程。
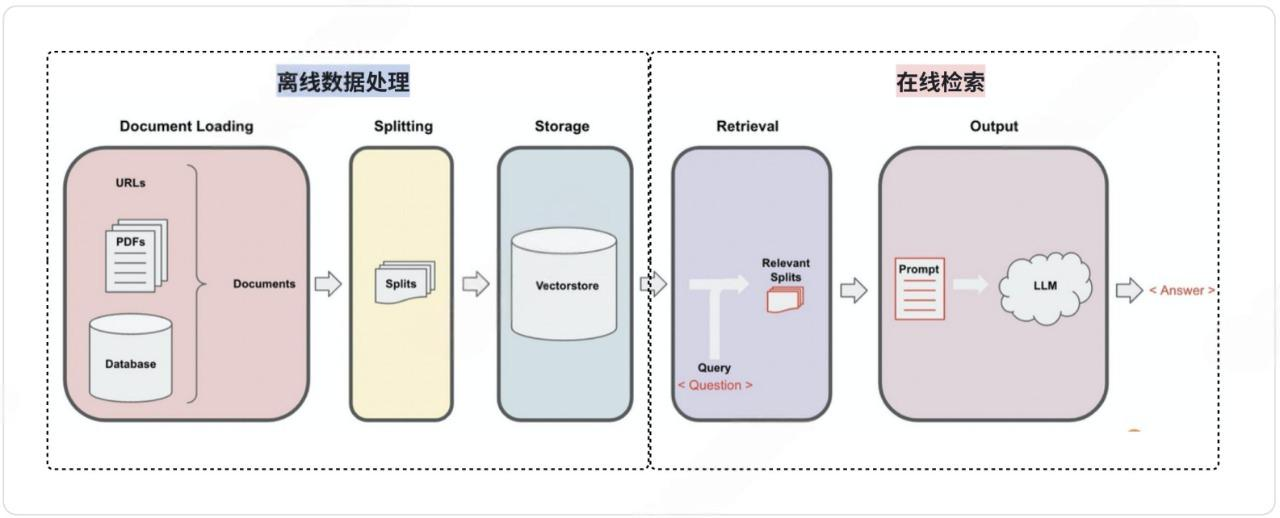
文档加载 文本分割 存储 检索 输出
RAG示例流程:定义聊天模型 定义嵌入模型 配置Redis客户端 定义Redis向量存储 生成检索器 定义提示词模板 将文档转换为字符串 定义链 循环输入问题
(3) Document文档类
LangChain ⽂档加载器可以将各种数据源加载成⼀系列的⽂档对象 Document 。 class langchain_core.documents.base.Document ⽤于存储⼀段⽂本和相关元数据的类,我们可以直接定LangChain ⽂档列表。
python
from langchain_core.documents import Document
documents = [
# 单个Document对象通常表⽰较⼤⽂档的⼀个块
Document(
# 内容字符串
page_content="狗是很好的伴侣,以忠诚和友好⽽闻名。",
# 元数据字典
# 元数据属性可以捕获有关⽂档源、与其他⽂档的关系以及其他信息的信息。
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独⽴的宠物,经常享受⾃⼰的空间。",
metadata={"source": "mammal-pets-doc"},
),
]
这段代码创建了两个"文档块",每个块包含一段文字(page_content)和一张小标签(metadata)
方便以后检索或分类。
metadata={"source": "mammal-pets-doc"}{"source": "mammal-pets-doc"}
意思是这段话的来源是"哺乳动物宠物文档"
方便以后你知道它是从哪个大文档里切出来的。(4)加载PDF文档
将本地的 PDF ⽂档加载到 LangChain 中,其实就是将 PDF ⽂档转换为⼀个个 Document 对象。这时
就需要我们使⽤ PyPDFLoader ⽂档加载器完成这⼀功能。
class langchain_community.document_loaders.pdf.PyPDFLoader 类,有以下关键函数:
• init() 初始化函数,⼊参 file_path ,表⽰要加载的 PDF ⽂件的路径。
• load() → listDocument :将数据加载到⽂档对象中。返回⽂档对象列表
python
from langchain_community.document_loaders import PyPDFLoader
file_path = "../Docs/PDF/脚⼿架级微服务租房平台Q&A.pdf"
loader = PyPDFLoader(file_path)
# 将 PDF ⽂件的每⼀⻚转换为⼀个独⽴的 Document 对象,并存储在列表 docs 中。
docs = loader.load()(5)加载Markdonwn文件
将本地的 Markdown ⽂档加载到 LangChain 中,需要我们使⽤UnstructuredMarkdownLoader ⽂档加载器完成这⼀功能。
class langchain_community.document_loaders.markdown.UnstructuredMarkdownLoader类
需要依赖 Unstructured 包。因此在使⽤前我们需要先安装它:
python
pip install "unstructured[md]" nltk对于 LangChain 来说,能加载的⽂档类型远不⽌这些,它还能加载⽹⻚、⼀些云提供商⽂件、社交媒
体平台⽂档等,更多⽂档加载器:LangChain Python integrations - Docs by LangChain
6.0 文本分割器
(1)概念
⽂档拆分通常是将⼤⽂本分解为更⼩的、易于管理的块。这对于索引数据并将其传递到模型中都很有⽤。因为,⼤块更难搜索并且不适合模型的有限上下⽂窗⼝。拆分可以提⾼搜索结果的粒度,从⽽可以更精确地将查询与相关⽂档部分进⾏匹配。
LangChain 的⽂本分割器便能将⼤型⽂档分解为更⼩的块。
(2)根据文档长度与文档语义拆分
我们可以直接根据⽂档的⻓度拆分⽂档,是最简单且有效的⽅法。可确保每个块不超过指定的⼤⼩限制。对于⻓度拆分,其实也分为两种: 基于字符⻓度拆分 和 基于Token⻓度拆分 。
python
基于字符串长度拆分:
# ⽂本分割器
text_splitter = CharacterTextSplitter(
separator="\n\n", # 选择分隔符:它有⼀个默认的分隔符优先级列表,通常是:["\n\n", "\n", " ", ""]。它会按顺序尝试这些分隔符
chunk_size=100, # 设定⽬标:⽬标块⼤⼩
chunk_overlap=20, # 设定⽬标:块之间的重叠⼤⼩
length_function=len, # 使⽤测量⻓度的函数
is_separator_regex=False, # 分隔符是正则表达式吗
)
在这⾥要说明,这是⼀个在使⽤
LangChain 的⽂本分割器时⾮常常⻅的问题。看到这个信息,不要担⼼,这不是错误,⽽是预期的⾏
为。原因是为了保持语义的完整性!当⽂本分割器⽤尽所有指定的分隔符都⽆法将⼀段⽂本分割到你的⽬标⼤⼩ chunk_size 以下时
它会选择保留整个⽂本块,⽽不是强⾏将其截断为⽆意义的⽚段
因此我们会看到这个提⽰信息。因此我们可以看到,被分割出来的段落,基本上都是语义完整的⼀段话。
那么分割逻辑到底是什么,可以⽀持保持语义完整性?
尝试分割 如果仍然有单个单词或字符串的⻓度超过了 100 ,分割器就陷⼊了两难境地
//选额的是: 保留这个完整的、超⻓的字符串作为⼀个块,并记录⼀条信息告知⽤⼾。
python
基于Tokent拆分:
之前我们讲过,LLM ⼤模型实际上并不是直接接收字符串,⽽是需要先做 token 切分编码。这⾥我们
可以借助 【 tiktoken 分词器】来进⾏ token 的切分编码。
我们可以使⽤根据 cl100k_base 编码⽅式的 tiktoken 分词器来拆分⽂档
在LangChain中,我们可以使⽤ CharacterTextSplitter 分割器
的 .from_tikt ken_encoder() ⽅法来定义根据 tiktoken 分词器拆分⽂本的分割器
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 分割⽂档
texts = text_splitter.split_documents(data)
同样,为了保持语义的完整性,⽂本分割器⽆法将⼀段⽂本分割到你的⽬标⼤⼩ chunk_size 以
下,它会选择保留整个⽂本块。
python
硬性约定长度拆分
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=100,
chunk_overlap=0,
)
但这样,其实是剥夺了⼀些保证语义完整性的能⼒,可以看到某些含义相似的内容,被强制分开。
若要将词组放在⼀起,可以覆盖分隔符列表以包含其他标点符号
例如中⽂的逗号 , 、句号 。 或其他中⽂符号
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
"。",
",",
"",
],
)
这样在分割的时候将递归用separators来尝试分割文本
python
特殊文档结构拆分
若对于代码等特殊⽂本,可以尝试使⽤ Language 提供的不同的分割器
(如PythonCodeTextSplitter 、 HTMLHeaderTextSplitter 等)效果会更好,它会理解代码的
语法结构。
https://reference.langchain.com/python/langchain-text-splitters#pythoncodetextsplitter
https://reference.langchain.com/python/langchain-text-splitters
这⾥了解下常⻅的拆分原则即可:
• Markdown:根据标头拆分(例如,#、##、###)
• HTML:使⽤标签拆分
• JSON: 按对象或数组元素拆分
• Code 代码 :按函数、类或逻辑块拆分7.0 文本向量
(1)嵌入与嵌入模型
嵌入的核心思想就是将人类世界的符号转换为计算机能够理解的数值形式。
并且要求这种转换能保留符号的语义和关系,可以想象成一个翻译的过程,把人类语言翻译成计算机的数学语言。
我们之前⼀直⽤的⼤语⾔模型是⽣成式模型。它理解输⼊并⽣成新的⽂本(回答问题、写⽂章)。它内部实际上也使⽤嵌⼊技术来理解输⼊,但最终⽬标是"创造"。
嵌⼊模型(Embedding Models)是表⽰型模型。它的⽬标不是⽣成⽂本,⽽是为输⼊的⽂本创建
⼀个最佳的、富含语义的数值表⽰(向量)。
向量:本质上是一个数字列表(一维数组) 对于向量来说,有两个关键概念需要了解一下 向量维度 向量空间
向量维度:嵌入结果得到的列表 长度是固定的 ,称为向量的维度 维度越高,通常能捕捉到更细微的语义信息,但是也需要更多的计算和存储资源。
向量空间:在这个空间里,每个点(即每个向量)都能代表一个概念。例如在嵌入模型中,⼀个点可以代表⼀个
单词、⼀句话、⼀张图⽚、⼀个⽤⼾、⼀部电影等。 我们可以用数学来度量语义。
应用场景:
语义搜索 //一种红色的水果 苹果
增强检索生成:当前大语言模型应用的核心模式
推荐系统:将用户和物品都转换为向量 进行喜好推荐
异常检测:正常的数据向量通常会聚集在一起,如果一个新数据的向量远离大多数向量的聚集区 可能就是一 个异常点。
(2)Embedding嵌入模型类
在 LangChain 中,有很多的嵌⼊模型提供⽅,使⽤不同的模型提供⽅,需要安装为其各⾃包,例如:
• OpenAI: pip install -U langchain-openai
• Ollama: pip install -U langchain-ollama
• Google Gemini: pip install -U langchain-google-genai
• 更多⻅这⾥ LangChain Python integrations - Docs by LangChain
定义嵌入模型:
官方文档:OpenAIEmbeddings引入方式: | langchain_openai | LangChain Reference
引入方式:
python
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", # 是 OpenAI 2024年发布的最新嵌⼊模型,⽣成3072维的⾼质量向量
)在LangChain框架中基础Embedding类
langchain_core | LangChain Reference
它设计了两个官方文档
嵌入文档列表:
embed_documents 的语义是 "索引"。它的⽬的是预处理⼤量⽂本,为它们创建向量表⽰,以便后续被搜索。这⼀般是⼀个离线、批量处理的过程。
python
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 嵌⼊⽂档列表,⽣成向量列表 嵌入单个查询:
embed_query 的语义是 "搜索"。它的⽬的是在⽤⼾发起请求时,实时地将⼀个问题或指令转换为向量,⽤于在已索引的⽂档向量中进⾏检索。这是⼀个在线、实时、按需处理的过程
python
# 嵌⼊单个查询
query_vector = embeddings.embed_query("项⽬中遇到了哪些挑战?如何解决?")
print(f"向量维度:{len(query_vector)}")
print(f"向量前五个数值为:{query_vector[:5]}")(3)向量存储
向量数据库向量存储的核⼼任务是解决⼀个传统数据库(如MySQL)不擅⻓的问题:基于内容的相似性搜索(Similarity Search),⽽不是基于精确匹配的查询。
如何⾼效地存储和管理这些向量?
向量数据库则提供了专⻔⽤于⾼效存储、管理和检索⾼维向量的能⼒。
其核⼼就是 "⾼效地组织和检索这些数据"。
专门的索引:这是向量数据库的灵魂。它们不会使⽤暴⼒搜索,⽽是会预先为所有向量构建⼀种特殊的索引结构。 常⻅的⽅法有近似最近邻(ANN)搜索:为了追求极致的速度,它愿意牺牲⼀点点精度。它不会保证找到绝对最相似的向量(即最近邻),但能以极⾼的概率找到⾮常相似的向量。通过聚类、分层、压缩等算法技术,将搜索范围从"整个数据库"缩⼩到"⼏个最可能的候选集"。
向量相似度计算优化:向量数据库底层使⽤⾼度优化的库来进⾏向量运算。如 FAISS 向量数据库,它是 Facebook AI 研究院开发的⼀种⾼效的相似性搜索和聚类的库。它能够快速处理⼤规模数据,并且⽀持在⾼维空间中进⾏相似性搜索。
LangChain支持的向量数据库:LangChain Python integrations - Docs by LangChain
内存存储:我们使用LangChain的InMemoryVectorStore来实现向量的内存存储
langchain_core | LangChain Reference
初始化:
LangChain 中的⼤多数向量在初始化向量存储时接受嵌⼊模型作为参数
python
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 内存存储初始化
vector_store = InMemoryVectorStore(embedding=embeddings)添加文档:
我们可以使⽤ add_documents ⽅法,向内存存储中去添加⽂档。要注意的是,该⽅法会为添加的 ⽂档编排索引,索引列表随着该⽅法返回
python
# 添加⽂档
ids = vector_store.add_documents(documents=documents)获取文档:
使⽤ get_by_ids ⽅法,通过索引列表获取对应的⽂档列表
python
doc_3 = vector_store.get_by_ids(ids[:3])
print(f"{[doc.page_content for doc in doc_3]}")删除文档:
使⽤ delete ⽅法,删除传⼊索引列表对应的⽂档列表;若不传⼊索引列表,则认为全量删除
python
vector_store.delete(ids=ids[:3])向量搜索:
相似性算法:欧式距离 余弦度相似度
根据获取相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返回。
这可以使用similarity_search 方法来实现
说明: InMemoryVectorStore 是根据【余弦相似度】来捕捉语义的
python
search_docs = vector_store.similarity(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)元数据过滤:
虽然向量数据库实现了搜索算法,来有效地搜索所有嵌⼊的⽂档以找到最相似的⽂档。但现实场景中,我们还希望通过先根据元数据进⾏过滤,来帮助缩⼩搜索范围
python
def _filter_function(doc: Document) -> bool:
return doc.metadata.get("source") == "hahaha"
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter=_filter_function
)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)
这次,我们给搜索方法加入了filter参数 它接收一个bool值,表示我们可以根据条件选择是否过滤某些文档
因此我们定义了一个_filter_function过滤函数,可以根据文档元数据先过滤出文档,再去进行搜索(4)Redis向量存储
Redis 还提供了诸如搜索和查询功能等额外能⼒,允许⽤⼾在 Redis 内创建⼆级索引结构。这使得 Redis 能够以缓存的速度充当向量数据库。
理解RedisSearch:
高性能 搜索 与 全文索引 引擎模块
它基于Redis构建,使用户能够直接在Redis数据库中执行复杂的搜索和分词查询,无需额外引入外部搜索引擎
RediSearch 特别适⽤于轻量级、响应速度要求较⾼的分词搜索场景
理解Index:
Index(索引)是 RediSearch 模块⾥的概念,⽤于定义⼀个查询⽬录。 Index 是⼀个独⽴的数据结构,它建⽴在多个 Redis Keys (Hash 类型)之上,这专⻔为了极速执⾏⽂本搜索、过滤和聚合而设计。它本⾝不存储数据,⽽是存储了指向其他 Redis Keys 的指针,和这些 Keys 中特定字段的索引信息。
理解IndexFields:
Index Fields(索引字段) 是创建索引时,明确指定的那些需要被索引的字段。它们定义了索引的"结构"或"蓝图",告诉 RediSearch:"请针对这些字段的内容,以其特定的⽅式为我构建快速搜索的能⼒。"
理解metadata schema:
schema我们讲过,就是描述数据结构的声明格式
Metadata schema则用来描述元数据结构的声明 这里的元数据是指我们将来要嵌入文档的元数据 因为对于文档元数据来说 它在存入Redis后,就被定义成了索引字段
对于文档元数据来说,里面存放的就是一些文档属性,如source表示文档来源,我们可以手动加入其他元数据,这需要设置每个字段的声明:name表示字段名 type表示字段类型
python
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
]环境设置:
启动Redis服务端:使用Docker 启动 Redis实例
python
docker run -d -p 6379:6379 -it redis:latest
使⽤ docker ps 查看是否启动成功安装Redis客户端包,以便将来定义客户端 以及运行搜索和查询命令
python
pip install redis在 LangChain 中想要使⽤ Redis 向量库,需要安装 langchain-redis 包
python
pip install -qU langchain-redis定义 Redis 连接 URL,客⼾端连接 Redis 时需要使⽤
python
Redis 连接 URL 的基本结构是:
[protocol]://[auth]@[host]:[port]/[database]
这部分根据⾃⼰Redis服务情况⽽定。例如: "redis://localhost:6379"测试连接:
python
import redis
redis_url = "redis://localhost:6379"
# 定义Redis客⼾端
redis_client = redis.from_url(redis_url)
# Ping
print(redis_client.ping())
若输出True 则表示连接测试成功基本操作:
python
初始化
LangChain 中使⽤ RedisVectorStore 初始化 Redis 向量存储。由于 Redis 需要相关配置,如连
接 URL 等,因此 LangChain 提供了 RedisConfig 配置类供我们使⽤。
# 配置 Redis 客⼾端
redis_url = "redis://192.168.100.238:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)
我们可以根据 Index Name 查询其下的所有的 Index Fields
这需要安装 redisvl ( pip install -U redisvl ),使⽤ rvl 命令⾏⼯具来检查索引
rvl index info -i qa --host 192.168.100.238 --port 6379添加文档:
python
我们可以使⽤ add_documents ⽅法,向向量库中去添加⽂档。这次我们可以给被分割的⽂档添加相
关的元数据。
# 为⽂档添加元数据
for i, doc in enumerate(documents, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)获取文档:
python
使⽤ get_by_ids ⽅法,通过索引列表获取对应的⽂档列表
ids = [":01K4Q0A3DSQVZBRFKJD5MS25HJ", ":01K4Q0A3DSQVZBRFKJD5MS25HK",
":01K4Q0A3DSQVZBRFKJD5MS25HM"]
doc_3 = vector_store.get_by_ids(ids)
print(f"{[doc.page_content for doc in doc_3]}")删除文档:
python
使⽤ delete ⽅法,删除传⼊索引列表对应的⽂档列表
vector_store.delete([":01K4Q0A3DSQVZBRFKJD5MS25HJ"])
# 删除指定内容
vector_store.index.drop_keys(["qa::01K4Q0A3DSQVZBRFKJD5MS25HJ"])
# 全量删除,删除索引
vector_store.index.delete(drop=True)向量搜索:
python
相似性搜索
想要获取根据相似性搜索的结果,即嵌⼊单个查询,并查找相似的⽂档,并将它们作为⽂档列表返回。
这可以使⽤ similarity_search ⽅法来实现
search_docs = vector_store.similarity_search(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)
• 根据向量搜索⽅法: similarity_search_by_vector
• 根据查询搜索⽅法,并返回相似分值: similarity_search_with_score
• 根据向量搜索⽅法,并返回相似分值: similarity_search_with_score_by_vector
元数据过滤
对于上述列举的⽅法,在他们搜索之前,都可以根据元数据先进⾏过滤。对于 RedisVectorStore
来说,需要使⽤ Redis 过滤表达式进⾏筛选。
filter=filter_condition最大边际相关性搜索:
是一种重新排序算法 它使用语义相似性作为基础工具 从一个候选集中挑选出一组既能代表查询主题又彼此多样化的结果
• 【语义相似性】就像⾯试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打⼀个分数。
• 【最⼤边际相关性】就像团队经理(MMR算法)要组建⼀个团队。⽬标是选出⼀组"精华"结果,
⽽不是⼀个单⼀结果。
使用场景:
• 推荐系统:推荐与⽤⼾兴趣相关但⼜不同类型的物品,避免"信息茧房"。
• ⽂档摘要:从⻓⽂档中选择能代表主旨⼜包含不同信息的句⼦,避免摘要内容重复。
• RAG (检索增强⽣成):在从知识库检索完⼀堆相关⽂档后,使⽤ MMR 进⾏去重和多样化筛选,再
交给LLM⽣成答案,能有效提升答案质量和减少幻觉。
(4)Pinecone向量存储
Pinecone 是为机器学习应⽤量⾝打造的⽣产级向量数据库服务,适⽤于⾼维向量数据的⾼效存储、索
引与查询。它屏蔽了基础设施管理,提供⽆缝扩展、实时数据写⼊和强⼤安全保障,让开发者和数据
科学家能够以极低运维成本,快速构建⾼效的相似度搜索、推荐系统和 AI 应⽤。
Pinecone 是⼀个全托管的向量数据库平台,即负责所有后端维护、扩展、更新和监控,让⽤⼾专注于
应⽤开发,⽆需担⼼数据库管理。
Pinecone 地址:The vector database to build knowledgeable AI | Pinecone
环境设置:
首次使用需注册新用户 选择个人免费版
继续创建账户相关信息,或者直接右上角skip跳过
注册成功会生成一个默认的API Key 注意保存好你的key 也可以创建新的key
设置 PINECONE_API_KEY ,将 Key 添加进环境变量
更新包:
python
pip install -qU pinecone langchain-pinecone基本操作:
初始化
LangChain 中使⽤ PineconeVectorStore 类初始化 Pinecone 向量库。我们需要:
-
使⽤索引来初始化 PineconeVectorStore 。
如果我们是第一次创建索引 在Pinecone控制台 则可以看见被创建的索引 The vector database to build knowledgeable AI | Pinecone
添加文档:
python
我们可以使⽤ add_documents ⽅法,向向量库中去添加⽂档。
ids = vector_store.add_documents(documents=documents)删除文档:
python
# 全量删除
vector_store.delete(delete_all=True)
# 删除指定id的⽂档列表
delete_ids = []
vector_store.delete(ids=delete_ids)向量搜索:
想要获取根据相似性搜索的结果,即嵌⼊单个查询,并查找相似的⽂档,并将它们作为⽂档列表返回。这可以使⽤ similarity_search ⽅法来实现
python
for doc in search_docs:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")8.0 检索器
(1)简介
检索系统是⼀个为了满⾜⽤⼾信息需求,从⼤规模、⾮结构化的数据集合中,⾃动、⾼效地查找、排序并返回相关信息的计算机系统。
核心任务:在正确的时间 以正确的方式 将正确的信息传递给正确的人 //最常见的例子就是 搜索引擎
随着大语言模型的流行,检索系统已经成为人工智能应用的重要组成部分 ,且存在多种
关系数据库:结构化数据存储的基本类型 关系数据库擅长维护数据完整性、支持复杂查询以及处理不同数据实体之间的关系。
词法搜索索引:
许多搜索引擎基于将查询中的单词与每个⽂档中的单词进⾏匹配,这种⽅法称为词法检索。即⼀个单词经常出现在⽤⼾的查询和特定⽂档中,那么这个⽂档可能是⼀个很好的匹配。这通常使⽤【倒排索引】实现。
向量数据库:
向量存储不使⽤字频,⽽是使⽤【嵌⼊模型】将⽂档转换为⾼维向量表⽰。这允许使⽤余弦相似度等数学运算对嵌⼊向量进⾏有效的相似性搜索。
检索器:
检索器是检索系统中的一个核心组件,它接收来自用户接口的查询,检索出包含查询关键词的候选文档集合。
LangChain的检索器接口非常简单: 输入:查询字符串 输出:文档列表
例如,使用关系数据库的检索系统 检索器可以将问题转换为SQL语句 并执行查询 最后将查询结果响应用户
(2)使用向量数据库作为检索器
基本使用:
向量存储是索引和检索⾮结构化数据的⼀种强⼤⽽有效的⽅法。可以通过调⽤向量数据库的
as_retriever ⽅法,将向量存储⽤作检索器。在这⾥我们使⽤ Redis 向量存储
python
# 构建检索器
retriever = vector_store.as_retriever()
# 执行检索
docs = retriever.invoke("数据库表怎么设计的?")LangChain 检索器是⼀个 Runnable 的对象 ,它是 LangChain 组件的标准接⼝。这意味着它有⼀些常⽤⽅法,包括 invoke ,⽤于与其交互。默认情况下,向量存储检索器使⽤相似性搜索
python
结果是:
******************************
提供两种⽅案有以下好处:
降低⻔槛:单机版让⽤⼾快速体验核
******************************
数据库:MySQL + MyBatis
MySQL 和 M
******************************
不同状态(上架/已租/下架)的查询频率不同,拆分可减少锁争⽤
******************************
分库分表:按user_id哈希分库,按⽉份分表(如chat_要注意的是, Retrievers 检索器虽然是 Runnable 对象,但其不提供任何流式处理,因为它本⾝
通常是同步的、阻塞的操作
使用@chain创建"检索器"
除了使⽤ as_retriever ⽅法,我们还可以⾃⾏创建⼀个"检索器"。回想⼀下检索器的特点:
-
LangChain 检索器是⼀个 Runnable 的对象
-
LangChain 检索器输⼊为查询字符串,输出为⽂档列表(标准化的 LangChain ⽂档对象
Document)
综上所述,我们可以:
python
@chain
def retriever(query: str) -> List[Document]:
return vector_store.similarity_search(query, k=2)
上⾯定义了⼀个函数,使⽤ @chain 修饰,该修饰可以使其成为 Runnable 函数,且满⾜检索器输⼊
输出的要求。在函数中,我们依旧使⽤向量数据库的相似性搜索⽅法,这样灵活性也更⾼,想要进⾏
元数据筛选也更⽅便。
注意,这并不是真正的检索器,检索器是⼀个 Runnable 对象,⽽我们定义的只是⼀个函数,具备其
特点罢了。