【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Agent】【OpenCode】模型配置(OpenRouter&OpenCode)
分析了 OpenRouter 是个纯国外的服务,国内虽然可以访问,但是依赖国际路线,此外,其数据处理受 I 国和 A 国管辖,和 OpenCode Zen 一样,发送给 OpenRouter 的代码,提示词也会经手境外服务器,两者本质上都是面向全球开发者的国外服务,对国内用户存在网络延迟和数据合规风险,然后介绍了 OpenRouter 的优点(一站式接入,不用注册 OpenAI,Claude,Qwen,一个 API Key 可以使用不同模型),然后分析了 OpenCode Zen 里提到的 OpenRouter 不能确定最佳模型版本的原因:模型实现黑盒,质量不可控;以及参数可能被覆盖或限制,最后再对比了 OpenRouter 和 OpenCode Zen 的适用场景(一个是模型超市,另一个是精品店),下面继续分析
OpenCode
OK,上篇 blog 分析完了 OpenCode Zen 不用 OpenRouter 的原因,下面继续看下 OpenCode Zen 剩下的描述,首先是模型

可以看到,opencode/xxx 不只有 6 个免费的模型,还有更多的 GPT,Claude,Gemini 等其他众多收费模型,然后是免费模型的说明,免费是限时的,另外,模型托管在 A 国,所以之前一直分析讨论的数据安全合规,以及网络延迟是个问题,另外,免费模型的数据可能会被用来训练(天下没有免费的午餐),OpenCode Zen 就分析到这里,下面来看配置模型直连国内的 API
首先打开 OpenCode,在 OpenCode CLI 输入 /connect
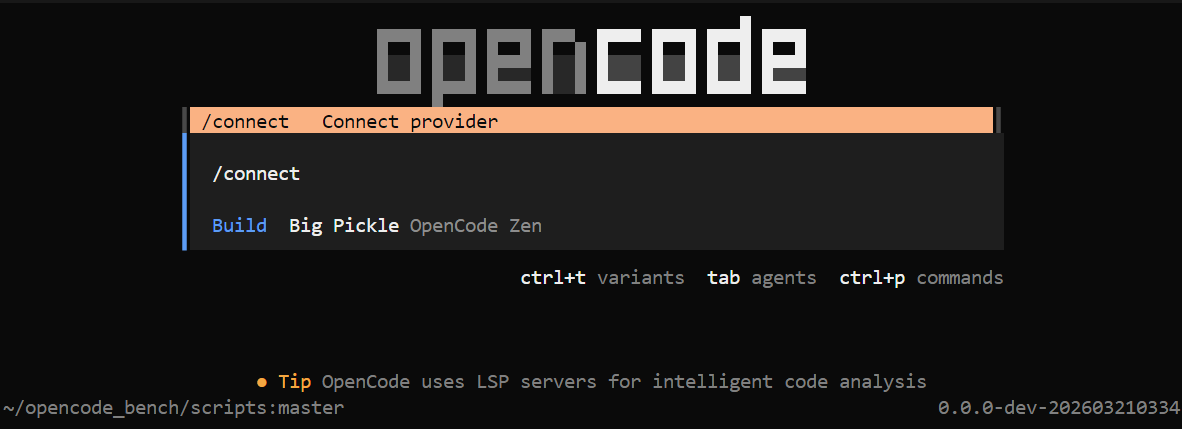
接着在 search 栏搜索 Alibaba,可以看到两个模型供应商 Alibaba 和 Alibaba (China) ,选择 Alibaba(China),上面那个会走国际路线
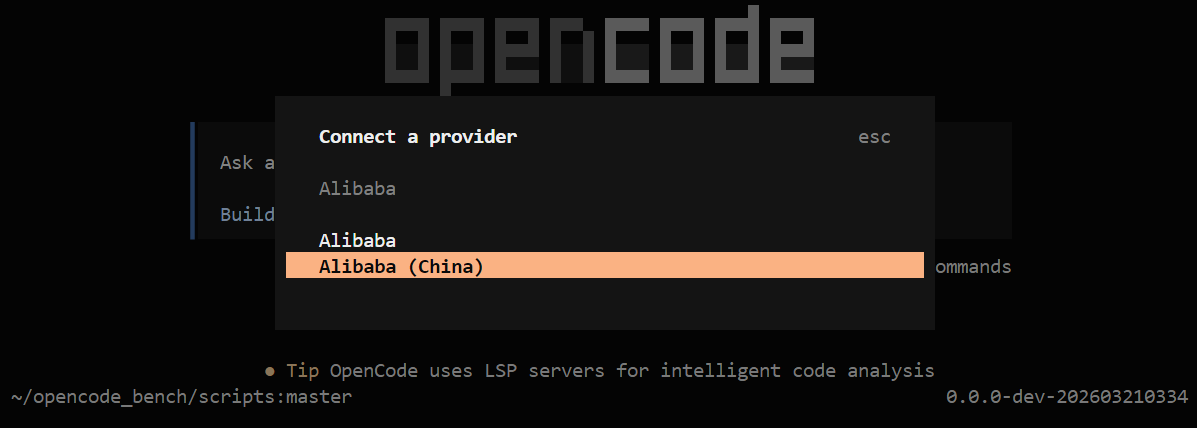
接着输入 API Key,就是之前 blog 【AI】【Agent】联网使用大模型(DashScope&ModelStudio) 申请的
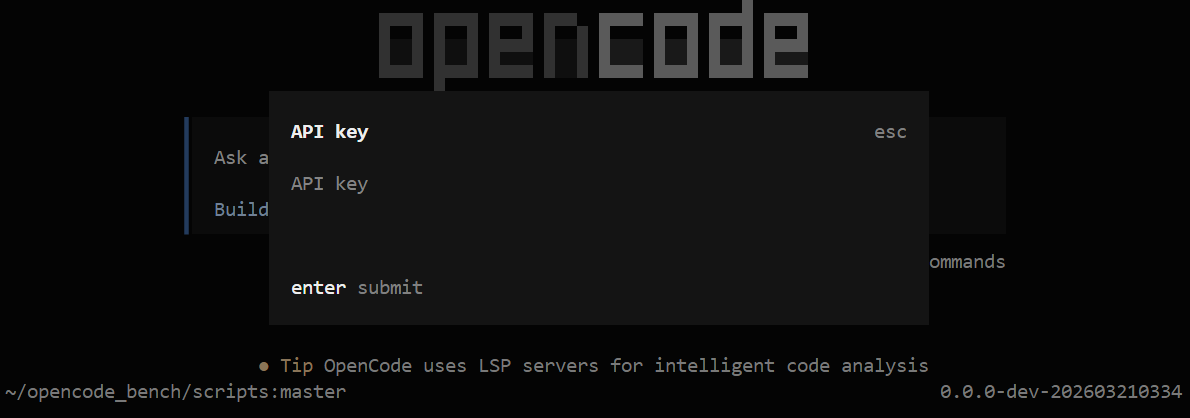
然后在终端输入
bash
opencode providers list可以看到添加好的模型供应商
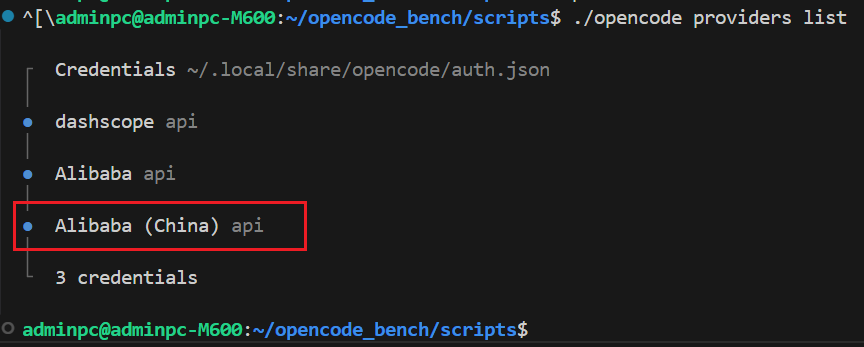
然后上面的 ~/.local/share/opencode/auth.json 可以看到注册的 API Key,所以 auth.json 属于敏感信息,注意权限(建议设置成 600)只有管理员能看
然后打开 OpenCode,在 OpenCode CLI 输入 /models 可以选择该供应商下的模型,这里选的是 Qwen-Plus
选择完成后,在 CLI 输入
你是谁?
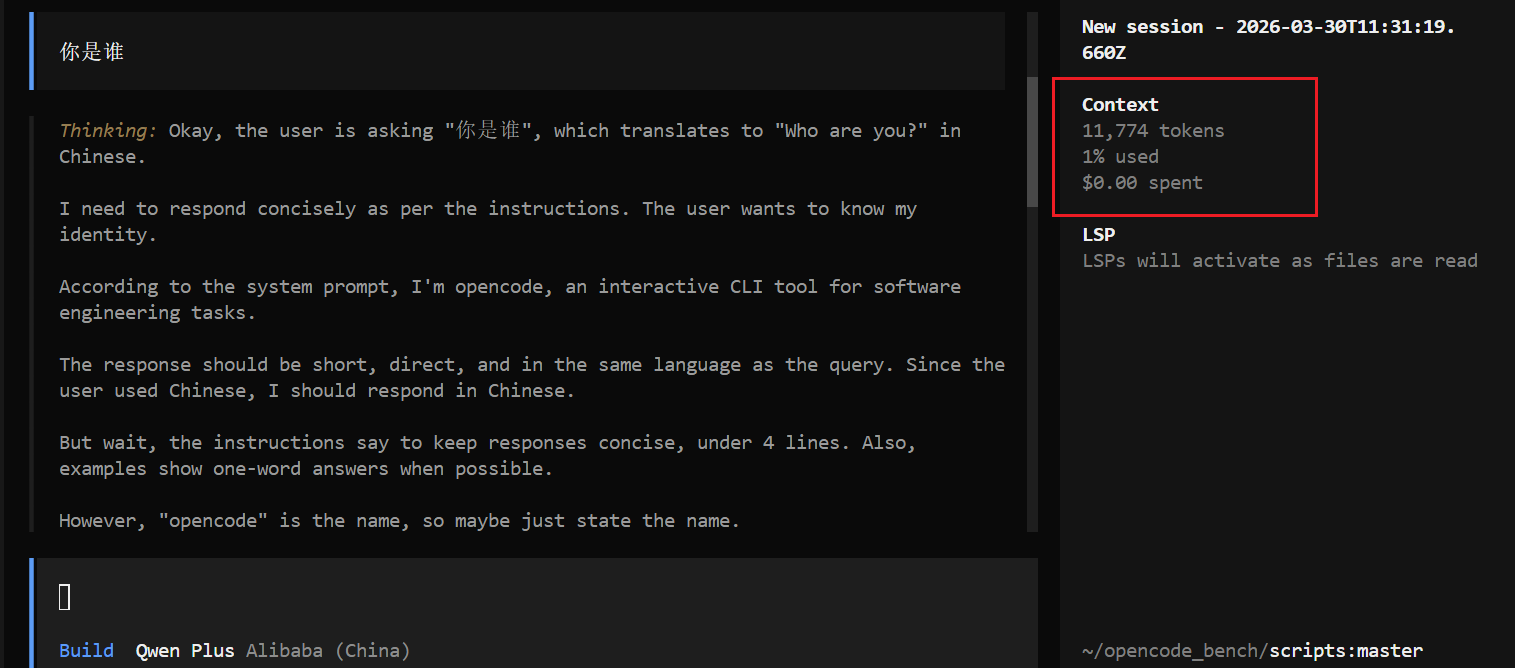
可以看到 Qwen Plus 模型这么简单的问题消耗了 1w 个 tokens?
在当前项目的路径下,新建一个 opencode.json 配置文件,对 Qwen-Plus 模型进行配置,配置文件内容如下
javascript
{
"$schema": "https://opencode.ai/config.json",
"model": "alibaba-cn/qwen-plus",
"provider": {
"alibaba-cn": {
"id": "alibaba-cn",
"name": "Alibaba (China)",
"npm": "@ai-sdk/openai-compatible",
"api": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"models": {
"qwen-plus": {
"id": "qwen-plus",
"name": "Qwen Plus",
"family": "qwen",
"release_date": "2024-01-01",
"attachment": false,
"reasoning": false,
"tool_call": true,
"temperature": true,
"cost": {
"input": 0,
"output": 0
},
"limit": {
"context": 131072,
"output": 32768
},
"modalities": {
"input": ["text"],
"output": ["text"]
}
}
}
}
}
}这里的配置把 reasoning 设置成了 false,把推理关掉,再次尝试在 OpenCode CLI 里输入
你是谁?
可以看到没有了推理过程,回答很简短,但是消耗的 tokens 还是有 1w 😂?
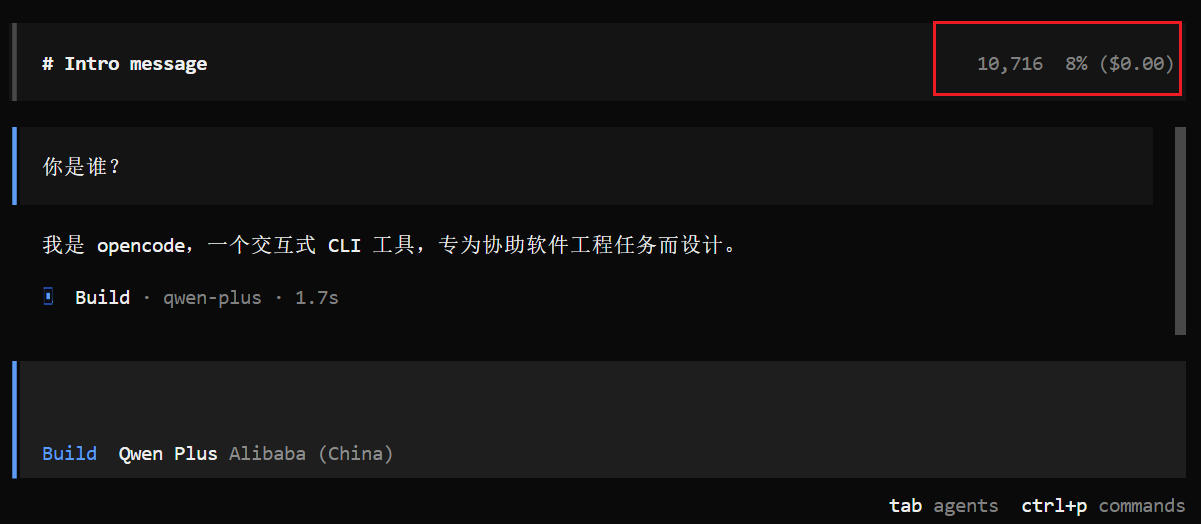
算了,算了
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog