
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》《C++入门到进阶&自我学习过程记录》
《算法题讲解指南》--优选算法
《算法题讲解指南》--递归、搜索与回溯算法
《算法题讲解指南》--动态规划算法
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
[一. 核心认知:unordered 系列容器是什么?](#一. 核心认知:unordered 系列容器是什么?)
[二. 模板参数介绍与基础接口使用](#二. 模板参数介绍与基础接口使用)
[1.1 模板参数介绍](#1.1 模板参数介绍)
[1.2 核心接口使用](#1.2 核心接口使用)
[2.1 模板参数介绍](#2.1 模板参数介绍)
[2.2 核心接口使用](#2.2 核心接口使用)
3、支持冗余的版本:unordered_multiset/unordered_multimap
[三. 关键差异:unordered 系列 VS map/set](#三. 关键差异:unordered 系列 VS map/set)
前言
在 C++ 开发中,map/set 与unordered_map/unordered_set 是高频使用的关联式容器,前者基于红黑树实现 ,后者基于哈希表实现 。刚接触两者时很多朋友都会纠结于 "该选哪一个"------ 其实核心在于理解两者的底层差异:红黑树保证有序但效率是 O (logN) ,哈希表追求 O (1) 极高平均效率但无序。本文聚焦unordered_map/unordered_set 的使用方法、与 map/set 的核心差异、性能对比,用代码示例和场景分析帮你快速掌握其用法,精准选择适合自己的容器。
一. 核心认知:unordered 系列容器是什么?
unordered_map 和 unordered_set 是 C++11 引入的关联式容器,底层基于哈希表(哈希桶) 实现,核心特点如下:
- 存储特性:unordered_set 存储单个 key(去重 + 无序),unordered_map 存储 key-value 对(key 去重 + 无序);
- 效率:增删查改平均时间复杂度 O (1),最坏情况 O (N)(哈希冲突严重时);
- 迭代器 :单向迭代器 (不支持 -- 操作 ),遍历结果无序;
- 对 key 的要求 :需支持 "转换为整形 "(哈希函数需求)和 "相等比较"(冲突判断需求)。
参考文档:
二. 模板参数介绍与基础接口使用
unordered_set:
1.1 模板参数介绍

-
unordered_set 的声明如上,Key 就是 unordered_set 底层关键字的类型
-
unordered_set 默认要求 Key 支持转换为整形 ,如果不支持或者想按自己的需求走可以自行实现支持将 Key 转成整形 的仿函数传给第二个模板参数
-
unordered_set 默认要求 Key 支持比较相等 ,如果不支持或者想按自己的需求走可以自行实现支持将Key比较相等 的仿函数传给第三个模板参数
-
unordered_set 底层存储数据的内存 是从空间配置器申请的,如果需要可以自己实现内存池,传给第四个参数。
-
一般情况下,我们都不需要传后三个模板参数
-
unordered_set 底层是用哈希桶实现 ,增删查平均效率是O(1),迭代器遍历不再有序,为了跟set 区分,所以取名 unordered_set。
1.2 核心接口使用
cpp
#include<iostream>
#include <unordered_set>
using namespace std;
//unordered_set 核心接口使用:
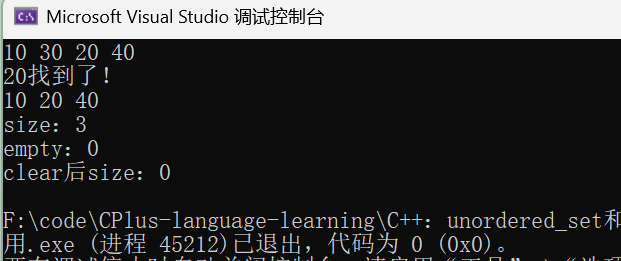
void test_unordered_set()
{
unordered_set<int> us;
// 插入(返回pair<iterator, bool>,bool标记是否插入成功)
us.insert(10);
us.insert({ 30, 20, 40 });//和set一样支持初始化列表批量插入
//void insert ( initializer_list<value_type> il );
//迭代器遍历(无序)
unordered_set<int>::iterator it = us.begin();
while (it != us.end())
{
cout << *it << " ";
it++;
}
cout << endl;
// 查找(返回迭代器,未找到返回end())
auto find = us.find(20);
if (find != us.end())
{
cout << *find << "找到了!" << endl;
}
else
{
cout << "没有找到!" << endl;
}
// 删除(按key删除,返回删除个数)
us.erase(30);
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
// 其他常用接口
cout << "size:" << us.size() << endl; // 元素个数
cout << "empty:" << us.empty() << endl; // 是否为空
us.clear(); // 清空容器
cout << "clear后" << "size:" << us.size() << endl;
}
int main()
{
test_unordered_set();
return 0;
}
unordered_map:
2.1 模板参数介绍

由于 unordered_map 的模板参数和 unordered_set 是完全一致的,区别点和 set与map之间的区别点是一样的,这里也就不过多赘述了。
2.2 核心接口使用
cpp
#include<iostream>
#include <unordered_map>
using namespace std;
//unordered_map 核心接口使用:
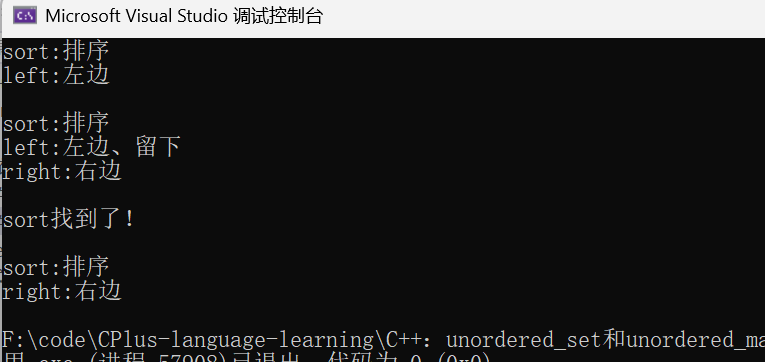
void test_unordered_map()
{
unordered_map<string, string> um;
// 插入
um.insert({ "sort", "排序"});
um.insert(make_pair("left", "左边"));
//迭代器遍历(无序)
unordered_map<string, string>::iterator it = um.begin();
while (it != um.end())
{
cout << it->first << ":" << it->second << endl;
it++;
}
cout << endl;
// []运算符(插入+访问/修改,最常用)
um["right"] = "右边"; // 插入
um["left"] = "左边、留下"; // 修改
for (auto e : um)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
// 查找
auto find = um.find("sort");
if (find != um.end())
{
cout << find->first << "找到了!" << endl;
}
else
{
cout << "没有找到!" << endl;
}
cout << endl;
// 删除
um.erase("left");
for (auto e : um)
{
cout << e.first << ":" << e.second << endl;
}
}
int main()
{
test_unordered_map();
return 0;
}
3、支持冗余的版本:unordered_multiset/unordered_multimap
与 multiset/multimap 类似,支持 key 重复:
- unordered_multiset :允许相同 key 重复插入 ,遍历无序;
- unordered_multimap :允许相同 key 重复插入 ,不支持 \[\] 运算符(key 不唯一);
- 核心差异 :无去重机制,其他接口与 unordered_map/unordered_set 一致。
三. 关键差异:unordered 系列 VS map/set
| 对比维度 | unordered_map / unordered_set | map / set |
|---|---|---|
| 底层结构 | 哈希表(数组 + 链表/红黑树) | 红黑树(自平衡二叉搜索树) |
| 元素顺序 | 无序(取决于哈希函数) | 有序(按 key 默认升序排列) |
| 时间复杂度 | 平均 O(1) ,最差 O(n) | 稳定 O(logN) |
| 迭代器特性 | 单向迭代器(仅支持向前遍历) | 双向迭代器(支持向前/向后遍历) |
| 对 Key 的要求 | 1. 支持 == 比较 2. 可计算哈希值 |
支持 < 比较(或自定义严格弱序) |
| 内存占用 | 较高(需预留桶空间减少冲突) | 较低(树结构紧凑,无预留开销) |
| 数据分布 | 数据分散在桶中 | 数据在树结构中平衡分布 |
| 主要优势 | 极速查找(常数级平均时间) | 有序遍历、稳定性能 |
| 典型场景 | 高频查询、缓存系统、去重操作 | 需要有序数据、范围查询、顺序相关操作 |
四、unordered_set和set的性能实测
测试代码(核心逻辑):
cpp
#include<iostream>
#include <unordered_set>
#include <unordered_map>
#include <set>
using namespace std;
//unordered_set和set的性能测试
void test()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
v.push_back(rand()); // N比较大时,重复值比较多
//v.push_back(rand() + i); // 重复值相对少
//v.push_back(i); // 没有重复,有序
}
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << "ms" << endl;
size_t begin2 = clock();
us.reserve(N);
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << "ms" << endl << endl;
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = s.find(e);
if (ret != s.end())
{
++m1;
}
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << "->" << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = us.find(e);
if (ret != us.end())
{
++m2;
}
}
size_t end4 = clock();
cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;
cout << "插入数据个数:" << s.size() << endl;
cout << "插入数据个数:" << us.size() << endl << endl;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << "ms" << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << "ms" << endl << endl;
}
int main()
{
test();
return 0;
}三组测试结果:
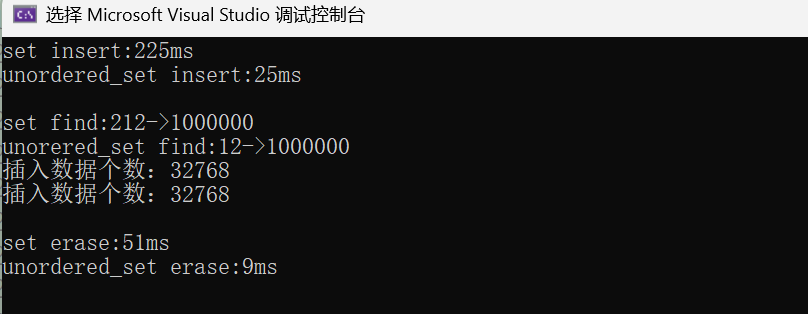
(1)N比较大且重复值比较多:
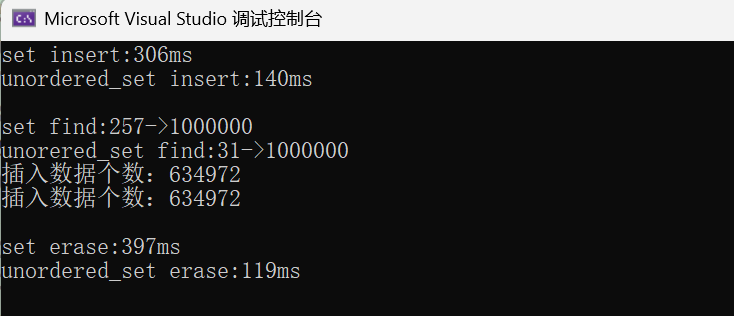
(2)N比较大且重复值相对少:
(3)N比较大且没有重复,有序:
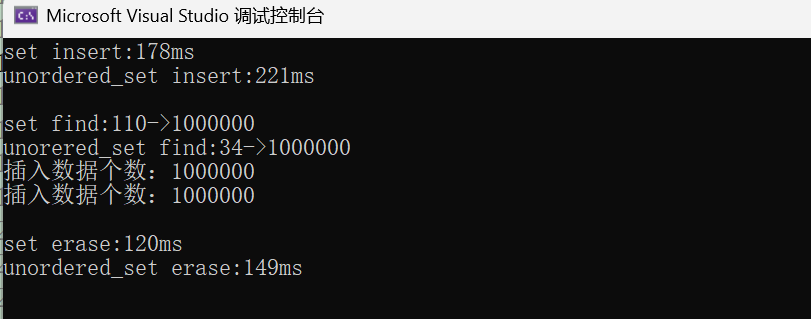
关键结论:
- unordered 系列在插入、查找、删除场景下均显著快于 map/set,尤其是高频查询场景;
- unordered 系列使用时建议先用reserve(N)预分配空间,避免频繁扩容导致性能下降;
- 数据量越小 ,性能 差距越不明显 ;数据量越大 ,unordered 系列的优势越突出 ;数据有序 时,unoredered系列的插入效率没 set 高。
结束语
到此,unordered_set和unordered_map的使用介绍就讲解完了。
unordered_map/unordered_set 的核心价值是 "以空间换时间",用哈希表的结构实现 O (1) 平均效率,完美适配高频查询场景;而 map/set 则以 "有序 + 稳定" 为核心优势,适合需要排序或空间敏感的场景。两者的接口高度兼容,切换成本极低,实际使用开发中可根据 "是否需要有序" 和 "查询频率" 快速决策。希望对大家学习C++能有所收获!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/