1. list的介绍和使用
1.1 list的介绍
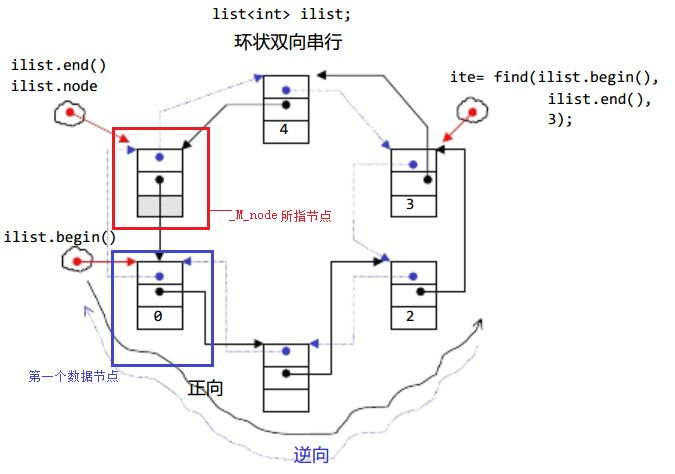
C++ 标准库中的 list是一个基于环状双向串行结构 实现的序列容器。如图所示,它的内部包含一个头结点(node),该结点由成员指针 M_node指向,作为整个数据结构的入口,其中并不存储实际数据。真实的节点首尾相连形成闭环,使得从任意节点出发都能正向或逆向遍历整个链表。对于使用者来说,list.begin()返回的是第一个实际存放数据的节点,而 list.end()指向头结点,表示范围的结束。这种设计使得 list支持高效的任意位置插入与删除操作(时间复杂度为 O(1)),但它不支持随机访问,且由于节点内存不连续,在进行排序等需要大量元素移动的操作时,通常不如 vector高效。
1.2 对于迭代器知识的补充
首先按照功能和性质对迭代器进行划分:
按照功能来划分的话,迭代器可以分为:
- iterator
- reverse_iterator
- const_iterator
- const_reserve_iterator
按照性质来划分的话,迭代器可以分为:
|-------|-------------------------------|-----------|
| 性质 | 举例 | 支持的运算 |
| 单向迭代器 | forward_list、unordered_map... | ++ |
| 双向迭代器 | list、map、set... | ++、-- |
| 随机迭代器 | vector、string、deque... | ++、--、+、- |
如果想要查看某种数据结构的迭代器到底是哪种性质的迭代器,可以在官方文档的Member types中进行查看,例如查看list的迭代器属于哪种性质的迭代器,我们可以查看到如下结果:
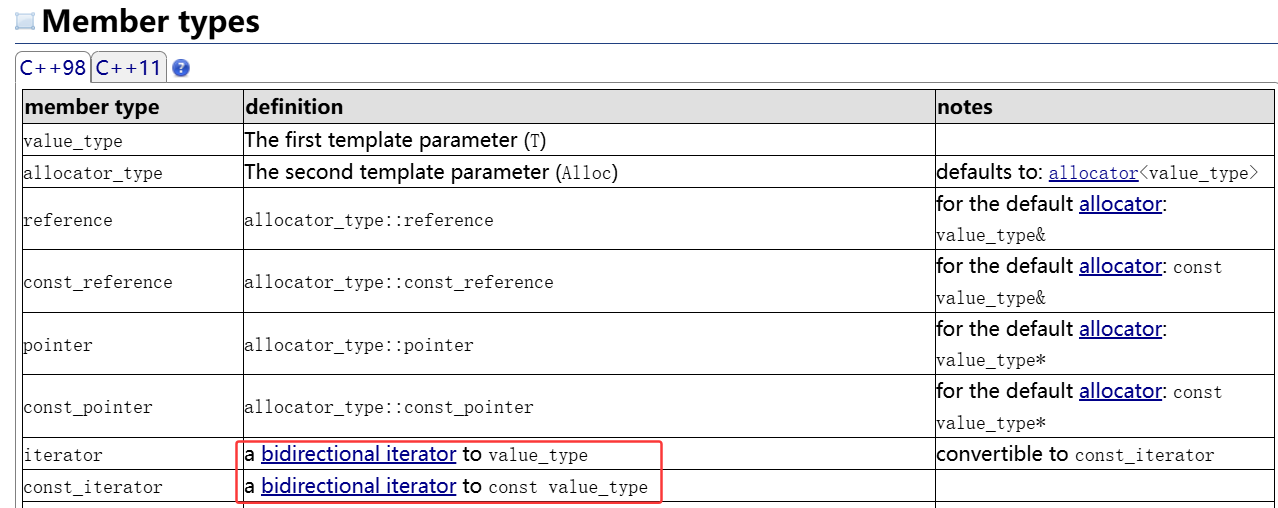
所以迭代器的性质取决于容器的底层结构,因为string,vector这种容器的底层物理存储空间的地址是连续的,所以相应的迭代器可以支持+/-运算,而list的底层物理存储空间的地址并不是连续的所以并不能支持+/-运算,而对于后续将会学习到的forward_list的底层结构采用的是单向链表,所以迭代器只能够单方向的进行遍历(向后遍历)。
同时还值得一提的一点是,容器的底层结构也决定了可以使用哪些算法。

以 std::sort为例,虽然它采用模板定义,表面上似乎能适配各类迭代器,但实际上它仅支持随机访问迭代器(RandomAccessIterator)。这是因为 std::sort底层通常采用快速排序(Quicksort)等算法,这些算法在执行过程中依赖随机访问特性(例如通过 +或 -运算符直接跳转到序列中的任意位置)。由于只有随机访问迭代器才能满足这种高效的跳跃式访问需求,因此 std::sort无法直接与仅支持顺序访问的容器(如 std::list)配合使用。
正是由于标准库全局的 std::sort算法要求迭代器必须是随机访问迭代(RandomAccessIterator),而 std::list仅提供双向迭代器(BidirectionalIterator),无法满足随机跳转的性能需求,因此 C++ 标准库特意为 std::list在类内部重载定义了专属的 sort成员函数。这种设计允许链表在不支持随机访问的情况下,依然能利用底层的归并排序(Merge Sort)算法实现高效的原地排序,同时也规避了将链表节点拷贝到连续内存的开销。
再举个例子,C++标准库中的reverse函数所要求的迭代器如下:

std::reverse函数要求迭代器类型为双向迭代器(BidirectionalIterator)。因此,std::forward_list 无法直接调用该函数,因为它仅支持单向迭代器;而 std::list 满足条件,可以正常使用。同时,std::vector 也能调用该函数,因为随机访问迭代器是一种特殊的双向迭代器,自然兼容该要求。同理,双向迭代器也是一种特殊的单向迭代器。
但是,可以发现C++标准库中还有一类函数所支持的迭代器比较特殊,比如find函数:

如上图所示,std::find的模板参数只需要 输入迭代器(InputIterator) 。相比之前的 std::sort(需要随机访问)和 std::reverse(需要双向访问),输入迭代器的限制是最小的,它仅要求能够单向遍历并读取元素即可。
因此,这类算法具有极高的通用性。无论是 vector、list这样的双向或随机访问容器,还是 forward_list(单向链表),甚至包括用于读取文件的流迭代器(如 std::istream_iterator),都可以使用 find函数进行查找操作。
为了更直观地理解各类迭代器的关系,我们可以参考标准库的定义:迭代器根据其提供的功能被划分为五大类别。正如下图所见,这五类迭代器构成了一个层层递进的层级结构。位于顶端的随机访问迭代器(Random Access)功能最强大,向下依次是双向迭代器(Bidirectional)和前向迭代器(Forward),而输入(Input)和输出(Output)迭代器则位于基础层,功能最为单一。
这种设计的精髓在于"继承性":如果一个容器支持更高级别的迭代器(例如 vector支持随机访问),那么它天然向下兼容,也能作为更低级别迭代器(如双向、前向、输入)被使用。这也就是为什么我们之前看到 vector能调用 find、reverse和 sort的原因。

1.3 list的使用
list 提供的常用成员函数(如 push_back、push_front、erase、insert等)在接口设计和使用方式上与 vector、string 基本一致,因此不再逐一展开说明。这里仅特别介绍几个在 list 中需重点关注的函数或特性,其余函数的详细用法可查阅相关标准库文档。
https://cplusplus.com/reference/list/list/?kw=list![]() https://cplusplus.com/reference/list/list/?kw=list
https://cplusplus.com/reference/list/list/?kw=list
1.3.1 emplace_back
push_back 和**emplace_back** 都是向 list 尾部添加元素的方法,核心区别在于构造效率:
push_back 接受一个已构造好的对象 (或临时对象),会调用拷贝构造或移动构造将其放入容器;而 emplace_back则直接接受构造对象所需的参数 ,在容器内部原地构造对象,避免了一次额外的拷贝或移动构造 ,效率更高。例如对于**list<A>,push_back(A(2,2))** 会先构造临时对象再移动(或拷贝)到容器,而 emplace_back(3,3) 则直接在链表节点中构造 A对象,省去了临时对象的构造和转移开销。因此,在 C++11 之后,推荐优先使用**emplace_back**来提升性能。
测试代码如下:
cpp
struct A
{
public:
A(int a1 = 1, int a2 = 1)
:_a1(a1)
,_a2(a2)
{}
int _a1;
int _a2;
};
void test_list2()
{
list<A> lt;
A aa1(1, 1);
lt.push_back(aa1);
lt.push_back(A(2, 2));
//lt.push_back(3,3);-->会直接报错
lt.emplace_back(aa1);
lt.emplace_back(A(2, 2));
//支持直接传构造A对象的参数
lt.emplace_back(3, 3);
}如果想要直观的看到每行调用中构造和拷贝构造的详情,可以改写代码如下:
cpp
struct A
{
public:
A(int a1 = 1, int a2 = 1)
:_a1(a1)
,_a2(a2)
{
cout << "A(int a1 = 1,int a2 = 1)" << endl;
}
A(const A& aa)
:_a1(aa._a1)
,_a2(aa._a2)
{
cout << "A(const A& aa)" << endl;
}
int _a1;
int _a2;
};
void test_list2()
{
list<A> lt;// 1. 创建一个空链表,准备存放A类对象
A aa1(1, 1);// 2. 创建一个A对象aa1
lt.push_back(aa1);
lt.push_back(A(2, 2));
//lt.push_back(3,3);
lt.emplace_back(aa1);
lt.emplace_back(A(2, 2));
cout << endl;
//支持直接传构造A对象的参数
lt.emplace_back(3, 3);
}输出结果为:
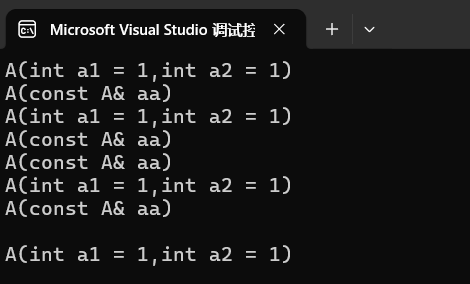
具体解读如下:
| 输出序号 | 对应的代码行 | 调用的函数 | 原因解释 |
|---|---|---|---|
| ① | A aa1(1, 1); |
A(int, int) |
直接构造对象 aa1 |
| ② | lt.push_back(aa1); |
A(const A&) |
push_back 拷贝 aa1 进链表 |
| ③ | lt.push_back(A(2, 2)); |
A(int, int) |
先构造临时对象 A(2,2) |
| ④ | lt.push_back(A(2, 2)); |
A(const A&) |
push_back 拷贝那个临时对象 |
| ⑤ | lt.emplace_back(aa1); |
A(const A&) |
传了对象进去,emplace 只能拷贝它 |
| ⑥ | lt.emplace_back(A(2, 2)); |
A(int, int) |
先构造临时对象 A(2,2) |
| ⑦ | lt.emplace_back(A(2, 2)); |
A(const A&) |
emplace_back 拷贝那个临时对象 |
| ⑧ | lt.emplace_back(3, 3); |
A(int, int) |
最佳实践:直接在链表内用参数构造对象 |
1.3.2 insert
因为list底层是双向链表,其迭代器不支持算术运算(如 +、-)及随机访问,这意味着无法像 vector那样通过加减偏移量来定位任意位置。
因此,若要在指定位置插入元素,必须先通过迭代器(如 begin())逐个遍历移动到目标位置,然后再调用 insert方法完成插入。
cpp
void test_list3()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
auto it = lt.begin();
int k = 3;
while (k--)
{
++it;
}
lt.insert(it, 30);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
输出结果:
1 2 3 4
1 2 3 30 41.3.3 erase
使用代码演示:
cpp
void test_list3()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
//删除操作
int x = 0;
cin >> x;
it = find(lt.begin(), lt.end(), x);
if (it != lt.end())
{
lt.erase(it);
}
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
}
输出结果:
1 2 3 4
输入x=3
输出:
1 2 4这里面进行删除操作的if判断条件之所以为it != lt.end(),是因为库中find函数的算法实现如下,看一下就很好理解了:

1.4 vector 排序 VS list 排序
在实际开发中,当我们面对链表(list)的排序需求时,一个常见的经验是:将链表数据转移到 vector 中排序,再转移回链表,比直接对链表排序更快。这是为什么呢?
性能对比实验
下面通过两组测试来验证这个结论:
实验1:直接排序对比
cpp
void test_op1()
{
const int N = 1000000;
list<int> lt1;
vector<int> v;
// 初始化相同数据
for (int i = 0; i < N; ++i) {
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
int begin1 = clock();
sort(v.begin(), v.end()); // vector排序
int end1 = clock();
int begin2 = clock();
lt1.sort(); // list排序
int end2 = clock();
printf("vector sort: %dms\n", end1 - begin1);
printf("list sort: %dms\n", end2 - begin2);
}结果示例:
vector 排序:约 150ms
list 排序:约 3000ms
vector 排序速度是 list 的 20 倍左右。
实验2:转移排序方案
cpp
void test_op2()
{
const int N = 1000000;
list<int> lt1;
list<int> lt2;
// 初始化相同数据
for (int i = 0; i < N; ++i) {
auto e = rand() + i;
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 1. 从list拷贝到vector
vector<int> v(lt2.begin(), lt2.end());
// 2. 在vector中排序
sort(v.begin(), v.end());
// 3. 从vector拷贝回list
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort(); // 直接对list排序
int end2 = clock();
printf("拷贝+vector排序+拷贝回: %dms\n", end1 - begin1);
printf("list直接排序: %dms\n", end2 - begin2);
}结果示例:
拷贝+vector排序+拷贝回:约 350ms
list 直接排序:约 3000ms
即使加上两次拷贝的开销,vector 方案仍然比 list 直接排序快 8-9 倍。
原因分析
1. 缓存局部性
vector 在内存中是连续存储的,CPU 缓存能够高效预加载相邻元素。排序过程中频繁的随机访问在 vector 上表现极佳。
list 是离散存储的,每个元素分布在堆内存的不同位置,每次访问都可能引发缓存未命中(cache miss),严重影响性能。
2. 算法实现
std::sort使用的快速排序/内省排序依赖随机访问,复杂度为 O(NlogN)。
list::sort使用的是归并排序的变体,虽然也是 O(NlogN),但由于指针操作频繁和缓存不友好,常数项极大。3. 拷贝开销相对较小
从 list 拷贝到 vector 是 O(N) 的线性操作,虽然需要额外内存,但连续的写入操作非常高效。排序的 O(NlogN) 占据主导,拷贝开销相对较小。
结论
在 C++ STL 中,list 的直接排序是性能陷阱。**"拷贝到 vector → 排序 → 拷贝回 list"** 虽然看似多了一步,但由于现代 CPU 缓存架构的特性,反而能获得数量级的性能提升。这是空间换时间的典型范例,也是理解数据结构内存布局重要性的生动案例。
2. list迭代器的实现原理
2.1 迭代器设计的背景与挑战
在前面的章节中,我们已经学习了vector和string的迭代器实现,它们的特点是底层物理存储空间连续。在这种连续存储结构中,迭代器本质上就是原生指针的简单封装,通过指针的自增/自减就能遍历整个容器。
然而,list(双向链表)的情况完全不同。list的节点在内存中是离散分布 的,每个节点通过指针相互连接。如果使用原生指针作为迭代器,++操作将无法正确地移动到下一个节点,因为下一个节点的地址与当前节点的地址在物理上不连续。
2.2 迭代器的封装设计
设计思想
为了让用户能够使用统一的方式操作不同类型的容器,list采用了迭代器封装模式 。我们创建一个专门的迭代器类,在内部重载运算符,使得++、--、*等操作符在list的上下文中具有正确的语义。
代码实现框架
cpp
namespace YJ
{
// 链表节点结构
template<class T>
struct list_node
{
T _data; // 数据域
list_node<T>* _next; // 后继指针
list_node<T>* _prev; // 前驱指针
// 构造函数
list_node(const T& data = T())
:_data(data)
,_next(nullptr)
,_prev(nullptr)
{}
};
// list迭代器类
template<class T>
struct list_iterator
{
typedef list_node<T> Node; // 节点类型别名
typedef list_iterator<T> Self; // 迭代器自身类型别名
Node* _node; // 当前指向的节点指针
// 构造函数
list_iterator(Node* node)
:_node(node)
{}
// 解引用运算符重载
T& operator*()
{
return _node->_data;
}
// 前置自增运算符重载
Self& operator++()
{
_node = _node->_next; // 移动到下一个节点
return *this;
}
// 前置自减运算符重载
Self& operator--()
{
_node = _node->_prev; // 移动到前一个节点
return *this;
}
// 不等运算符重载
bool operator!=(const Self& s) const
{
return _node != s._node; // 比较节点指针
}
// 相等运算符重载
bool operator==(const Self& s) const
{
return _node == s._node; // 比较节点指针
}
};
}补充: 在 C++ 中,class与 struct的唯一区别在于默认访问权限:struct默认为 public,而 class默认为 private,除此之外二者在功能上完全相同。这里选择使用 struct来定义链表的节点和迭代器,是因为这些内部结构中的成员变量(如 _data、_next、_prev等)需要被外层容器类频繁访问和操作,将其默认设为 public可以简化代码,避免反复书写 public:访问说明符,使实现更为清晰和直接。
2.3 迭代器在list类中的集成
迭代器类型定义
在list类中,我们将**list_iterator<T>** 定义为公有类型**iterator** ,这样用户可以通过**list<T>::iterator**访问迭代器类型。
cpp
template<class T>
class list
{
typedef list_node<T> Node;
public:
typedef list_iterator<T> iterator; // 迭代器类型定义
// 获取起始迭代器
iterator begin()
{
// 三种等效写法:
// 1. 创建临时对象
// iterator it(_head->_next);
// return it;
// 2. 显式构造
// return iterator(_head->_next);
// 3. 隐式转换(最简洁)
return _head->_next; // Node*隐式转换为iterator
}
// 获取结束迭代器
iterator end()
{
return _head; // 头节点作为end标志
}
private:
Node* _head; // 头节点(哨兵节点)
size_t _size; // 元素个数
};2.4 关键操作的实现原理
1. 构造函数
list采用带头节点的双向循环链表实现,初始化时创建头节点并让其前后指针都指向自己,形成空链表。
cpp
list()
{
_head = new Node; // 创建头节点
_head->_next = _head; // 后继指向自己
_head->_prev = _head; // 前驱指向自己
_size = 0; // 大小为0
}2. 插入操作
insert操作展示了迭代器的实际应用。通过迭代器可以精确定位插入位置。
cpp
void insert(iterator pos, const T& x)
{
Node* cur = pos._node; // 当前位置节点
Node* prev = cur->_prev; // 前一个节点
Node* newnode = new Node(x); // 创建新节点
// 重新链接指针
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
prev->_next = newnode;
++_size; // 更新大小
}3. 删除操作
erase操作同样通过迭代器定位要删除的元素。
cpp
void erase(iterator pos)
{
assert(pos != end()); // 不能删除end()
Node* prev = pos._node->_prev;
Node* next = pos._node->_next;
// 跳过要删除的节点
prev->_next = next;
next->_prev = prev;
delete pos._node; // 释放节点
--_size; // 更新大小
}4. 完整代码
cpp
namespace YJ
{
template<class T>
struct list_node
{
T _data;
list_node<T>* _prev;
list_node<T>* _next;
//构造函数
list_node(const T& data = T())
:_data(data)
,_prev(nullptr)
,_next(nullptr)
{}
};
template<class T>
struct list_iterator
{
typedef list_node<T> Node;
typedef list_iterator<T> Self;
//实例化节点
Node* _node;
//构造函数
list_iterator(Node* node)
:_node(node)
{}
T& operator*()
{
return _node->_data;
}
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self& operator--()
{
_node=_node->prev;
return *this;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}
};
template<class T>
class list
{
//内接口
typedef list_node<T> Node;
public:
//外接口
typedef list_iterator<T> iterator;
list()
{
_head = new Node;
_head->_prev = _head;
_head->_next = _head;
_size = 0;
}
iterator begin()
{
iterator it(_head->_next);//哨兵位_head的下一个节点就是头节点 begin()指向第一个有效元素
return it;
}
iterator end()
{
return _head;//end()指向最后一个有效元素的下一个位置
}
//void push_back(const T& x)
//{
// Node* newnode = new Node(x);
// Node* tail = _head->_prev;
// tail->_next = newnode;
// newnode->_prev = tail;
// newnode->_next = _head;
// _head->prev = newnode;
// ++_size;
//}
void insert(iterator pos, const T& x)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(x);
//prev newnode cur
newnode->_next = cur;
cur->_prev = newnode;
newnode->_prev = prev;
prev->_next = newnode;
++_size;
}
//可以直接复用insert对push_backde的实现进行改写
void push_back(const T& x)
{
insert(end(), x);
}
//前插同理
void push_front(const T& x)
{
insert(begin(), x);
}
void erase(iterator pos)
{
assert(pos != end());
Node* prev = pos._node->prev;
Node* next = pos._node->next;
prev->_next = next;
next->_prev = prev;
delete pos._node;
--_size;
}
void pop_back()
{
erase(--end());
}
void pop_front()
{
erase(begin());
}
size_t size() const
{
return _size;
}
bool empty() const
{
return _size == 0;
}
private:
Node* _head;
size_t _size;
};
}2.5 测试示例
cpp
void test_list_iterator()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
// 使用迭代器遍历
list<int>::iterator it = lt.begin();
while (it != lt.end())
{
cout << *it << " "; // 解引用获取数据
++it; // 移动到下一个元素
}
cout << endl; // 输出: 1 2 3 4
}2.6 设计要点总结
3.节点封装:每个元素存储于独立的节点中,节点包含数据、前驱和后继指针。
迭代器封装:通过自定义迭代器类,重载运算符实现链表特有的遍历逻辑。
隐式转换 :利用构造函数实现
Node*到iterator的隐式转换,简化代码。哨兵节点 :使用头节点简化边界条件处理,
begin()返回头节点的下一个节点,end()返回头节点本身。运算符重载:
operator*():返回节点数据的引用
operator++():移动到后继节点
operator--():移动到前驱节点
operator!=()、operator==():比较底层节点指针这种设计使得list的迭代器在使用方式上与vector、string的迭代器完全一致,用户无需关心底层实现差异,体现了C++STL的抽象之美。
你说得对,让我具体分析"隐式转换"在代码中的体现。
3.隐式转换的具体体现
1. 转换构造函数的作用
cpp
// 在list_iterator类中
list_iterator(Node* node) // 单参数构造函数
:_node(node)
{}这个构造函数是隐式转换 的关键。它是一个单参数构造函数,C++编译器允许它作为隐式转换的桥梁。
2. 代码中的具体应用
在list类的begin()函数中:
cpp
iterator begin()
{
return _head->_next; // 这里发生隐式转换
}3. 隐式转换的步骤分解
实际上,编译器看到return _head->_next;时:
_head->_next的类型是Node*(节点指针)函数的返回类型是
iterator编译器检查是否存在从
Node*到iterator的转换路径发现
list_iterator有一个接受Node*的构造函数编译器隐式调用 构造函数:
return list_iterator(_head->_next);
4. 等效的显式写法对比
cpp
// 显式写法1:临时对象
iterator begin()
{
iterator it(_head->_next); // 显式构造
return it;
}
// 显式写法2:显式转换
iterator begin()
{
return iterator(_head->_next); // 显式调用构造函数,匿名对象写法
}
// 隐式写法(实际使用的简洁形式)
iterator begin()
{
return _head->_next; // 自动隐式转换
}5. 更多的隐式转换例子
在insert()和erase()函数中也有体现:
cpp
void insert(iterator pos, const T& x)
{
Node* cur = pos._node; // iterator → Node*
// ...
}
void erase(iterator pos)
{
Node* cur = pos._node; // iterator → Node*(通过成员访问)
// ...
}6. 隐式转换的便利性对比
假设没有隐式转换,遍历代码会变得很冗长:
cpp
// 没有隐式转换的繁琐写法
list<int> lt;
// ... 插入数据
// 需要显式构造迭代器
list<int>::iterator it = list_iterator<int>(lt.get_head()->_next);
while (it != list_iterator<int>(lt.get_head())) // 每次比较都要构造
{
cout << *it << " ";
it = list_iterator<int>(it._node->_next); // 每次赋值都要构造
}
cpp
// 有隐式转换的简洁写法
list<int>::iterator it = lt.begin(); // 自动转换
while (it != lt.end()) // 自动转换
{
cout << *it << " ";
++it; // 通过重载的++操作符
}7. 隐式转换的原理图
cpp
隐式转换过程
┌─────────────────────┐
Node* │ _head->_next │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│编译器自动调用构造函数│
│list_iterator(Node*) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
iterator │ _node = _head->_next │
└─────────────────────┘