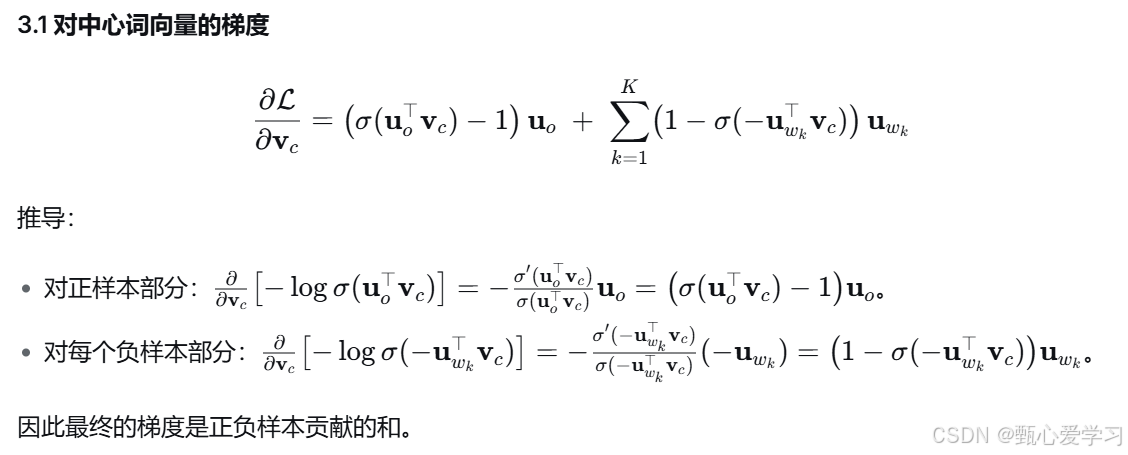代码与定义
python
def negSamplingLossAndGradient(
centerWordVec,
outsideWordIdx,
outsideVectors,
dataset,
K=10
):
"""负采样损失函数用于word2vec模型
实现中心词向量和外部词索引对应的负采样损失和梯度
作为word2vec模型的构建模块。K是负样本的数量。
注意:同一个词可能被多次负采样。例如如果一个外部词
被采样了两次,你需要针对该词的梯度进行双倍累加。
三次采样则累加三次,依此类推。
"""
negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K)
indices = [outsideWordIdx] + negSampleWordIndices
loss = 0.0
gradCenterVec = np.zeros_like(centerWordVec)
gradOutsideVecs = np.zeros_like(outsideVectors)
# 正样本词
u_o = outsideVectors[outsideWordIdx] # 获取正样本词向量
z_o = np.dot(u_o, centerWordVec) # 计算点积
p_o = sigmoid(z_o) # 计算概率
loss -= np.log(p_o) # 累加正样本损失
gradCenterVec += (p_o - 1.0) * u_o # 更新中心词梯度
gradOutsideVecs[outsideWordIdx] += (p_o - 1.0) * centerWordVec # 更新正样本词梯度
# 负样本词
u_k = outsideVectors[negSampleWordIndices] # 获取负样本词向量
z_k = np.dot(u_k, centerWordVec) # 计算点积
p_k = sigmoid(-z_k) # 计算负样本概率
loss -= np.sum(np.log(p_k)) # 累加负样本损失
gradCenterVec += np.dot(1.0 - p_k, u_k) # 更新中心词梯度
# 对每个负样本单独更新词向量梯度
for i, k in enumerate(negSampleWordIndices):
gradOutsideVecs[k] += (1.0 - p_k[i]) * centerWordVec
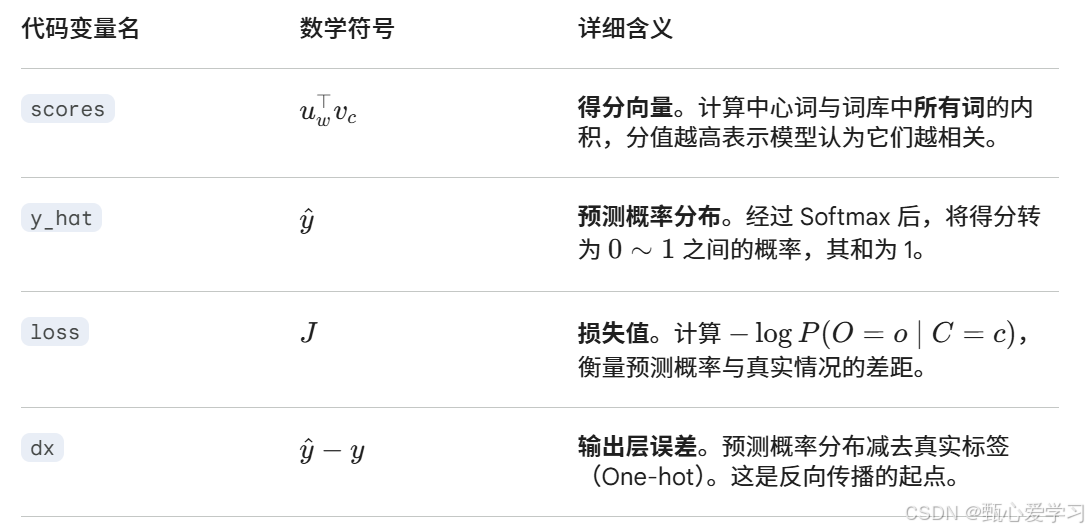
return loss, gradCenterVec, gradOutsideVecs| 代码变量名 | 数学符号 | 详细含义 |
|---|---|---|
centerWordVec |
v_c | 中心词向量。当前窗口正中间那个词的词向量,它是我们要更新的"输入"。 |
outsideWordIdx |
o | 真实上下文词的索引。即在语料库中,实际出现在中心词身边的那个词的编号。 |
outsideVectors |
U | 外部词向量矩阵。形状为 (V, N),每一行 u_w 代表词汇表中第 w 个词作为"上下文"时的特征。 |
dataset |
- | 用于负采样的工具。它包含了词频信息,确保高频词更有可能被选为负样本。 |
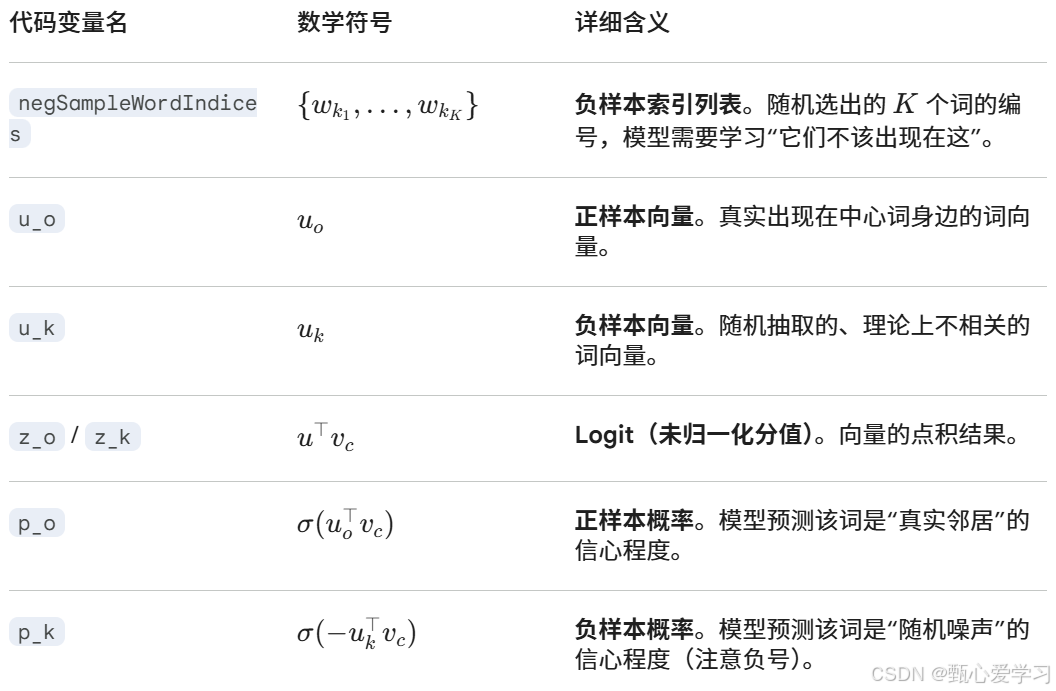
分析
用两个矩阵(中心词向量 centerWordVec 和外部词向量矩阵 outsideVectors)是为了分别表示词作为中心词 和词作为上下文词时的不同向量表征

如果不分开两个矩阵,而让每个词只有一个向量,那么当这个词作为中心词时和作为上下文词时,梯度更新会相互干扰(比如更新中心词时也会影响它作为上下文词时的表示)。实验证明分开训练效果更好。
gradCenterVec = np.zeros_like(centerWordVec) # 与中心词向量同形状(一维)
gradOutsideVecs = np.zeros_like(outsideVectors) # 与上下文矩阵同形状(词汇表大小 × 维度)-
gradCenterVec:只对应当前这一个中心词的梯度。因为损失函数中只有当前中心词向量出现,其他中心词向量不参与本次更新。 -
gradOutsideVecs:对应所有可能被更新到的上下文词向量。正样本词outsideWordIdx和每个负样本词negSampleWordIndices都需要更新其对应的行。这些词可能重复(同一个词被多次负采样),所以梯度要累加。
代码中为什么只传一个 centerWordVec 而不是整个中心词矩阵?
因为负采样损失函数是 每次处理一个中心词 (以及它的一个正样本和 K 个负样本)。在训练循环中,会遍历所有中心词,每次取出当前中心词的向量 centerWordVec(从中心词矩阵中取一行),并传入整个上下文矩阵 outsideVectors,因为需要根据索引从中取出正负样本的向量。
损失函数与梯度