本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(23) -AI知识库Agent平台(2)-文档向量化与向量库存储
前言
本文为 RAG(Retrieval-Augmented Generation,检索增强生成)智能检索问答系统的完整实现教程。
一、功能完整说明
RAG 系统是 AI 知识库的核心功能,解决了传统大模型"记忆有限、易编造内容"的痛点,核心逻辑是"先检索、再生成",本次实现的功能如下:
- 用户交互:支持命令行输入问题,输入"quit"即可退出;
- 语义检索:基于用户问题生成向量,与 Milvus 向量库中存储的文档片段进行相似度匹配,筛选出最相关的内容(默认取前3条,可灵活调整);
- 精准回答:调用 GPT-4 模型,严格基于检索到的知识库内容生成回答,不编造、不偏离文档原意;
- 日志监控:沿用前两天的日志工具,记录用户问题、检索过程、回答结果,方便排查问题、追溯操作;
- 兼容性:完全复用原有代码。
简单来说,前两天我们完成了"把文档存入知识库"的操作(写入),第三天则完成"从知识库中找答案"的操作(读取+生成端),两者结合,就构成了一个完整的企业级AI知识库。
二、核心原理
RAG 系统的核心优势的是"检索增强",避免大模型"一本正经地胡说八道",其完整工作流程分为4步:
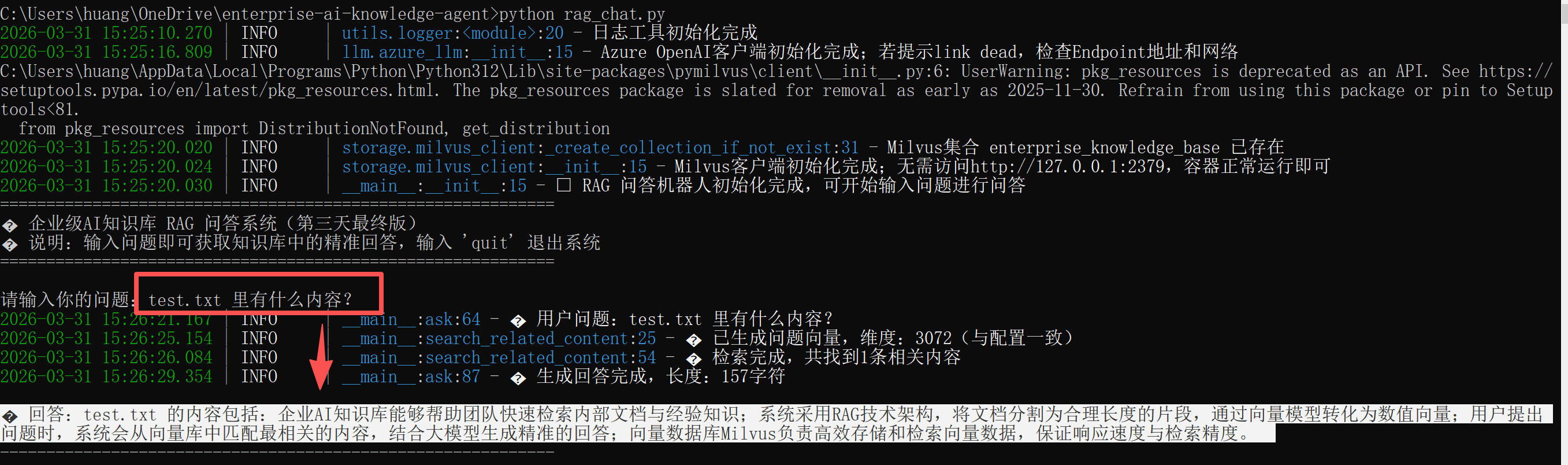
- 用户输入问题:比如"test.txt 文档里包含哪些内容?",系统接收用户输入的自然语言问题;
- 问题向量生成:调用 text-embedding-3-large 模型,将用户问题转换成 3072 维的向量;
- 语义检索:Milvus 向量库根据问题向量,计算库中所有文档片段向量的相似度,筛选出相似度最高的前N条(本次默认3条),作为回答的"参考资料";
- 智能生成回答:将检索到的参考资料和用户问题,一起传入 GPT-4 模型,模型基于参考资料生成精准、贴合原意的回答,同时避免编造内容。
代码实现
在根目录创建文件 rag_chat.py:
python
from utils.logger import logger
from llm.azure_llm import AZURE_LLM_CLIENT # 复用第二天的Azure LLM客户端
from storage.milvus_client import MILVUS_CLIENT # 复用第二天的Milvus客户端
class RAGChatBot:
def __init__(self):
"""
初始化RAG问答机器人
复用前序代码中的全局客户端,避免重复初始化,提升效率
"""
self.llm = AZURE_LLM_CLIENT # 加载Azure OpenAI客户端(已配置GPT-4和Embedding模型)
self.milvus = MILVUS_CLIENT # 加载Milvus向量库客户端(已连接集合)
self.collection_name = "enterprise_knowledge_base" # 与前两天的向量库集合名一致
self.top_k = 3 # 检索时取前3条最相关的文档片段(可调整,越多越全面但速度稍慢)
logger.info(" RAG 问答机器人初始化完成,可开始输入问题进行问答")
def search_related_content(self, question: str):
"""
核心检索函数:根据用户问题,从Milvus向量库中检索最相关的文档片段
:param question: 用户输入的自然语言问题
:return: 拼接后的相关文档片段(字符串),作为GPT回答的参考资料
"""
# 1. 生成问题的向量(与文档向量维度一致:3072维)
query_vector = self.llm.get_embedding(question)
logger.info(f" 已生成问题向量,维度:{len(query_vector)}(与配置一致)")
# 2. 调用Milvus的search方法,进行语义相似度检索
# 重点:output_fields指定返回的字段,与前两天存入的字段(text、doc_name)一致
search_results = self.milvus.client.search(
collection_name=self.collection_name, # 目标向量库集合
data=[query_vector], # 待检索的问题向量(列表格式,支持批量检索)
limit=self.top_k, # 检索前top_k条最相关的内容
output_fields=["text", "doc_name"], # 检索后返回的字段:文本内容、文档名称
metric_type="IP" # 相似度计算方式:内积(适合向量相似度对比,无需修改)
)
# 3. 提取检索结果,拼接成可直接用于GPT提示词的格式
related_context = []
for idx, result in enumerate(search_results[0], 1):
# 提取单条检索结果的信息
doc_name = result["entity"]["doc_name"] # 文档名称(如test.txt)
text = result["entity"]["text"] # 文档片段内容
similarity = result["distance"] # 相似度(值越接近1,相关性越高)
# 拼接成结构化的文本,方便GPT识别
related_context.append(f"【相关文档{idx}】文档名称:{doc_name},相似度:{round(similarity, 3)},内容:{text}")
# 若未检索到相关内容,返回提示信息
if not related_context:
logger.warning(" 未从知识库中检索到相关内容")
return "未从知识库中检索到与问题相关的内容,无法回答,请尝试更换问题表述。"
# 拼接所有相关内容,返回给GPT
context_str = "\n\n".join(related_context)
logger.info(f" 检索完成,共找到{len(related_context)}条相关内容")
return context_str
def ask(self, question: str):
"""
问答主函数:接收用户问题,完成检索+回答生成
:param question: 用户输入的自然语言问题
:return: GPT生成的精准回答(字符串)
"""
# 记录用户问题(日志监控)
logger.info(f" 用户问题:{question}")
# 步骤1:检索相关内容(调用上面的检索函数)
context = self.search_related_content(question)
# 步骤2:构造GPT提示词(关键:引导GPT只基于检索到的内容回答,不编造)
prompt = f"""
你是一个专业的企业AI知识库助手,你的核心职责是基于用户提供的参考资料,精准回答用户问题,严格遵循以下规则:
1. 回答必须完全基于提供的参考资料,不得编造任何未提及的内容,若资料中没有相关信息,直接说明"未检索到相关内容";
2. 回答要简洁明了、逻辑清晰,贴合用户问题,不要添加无关内容;
3. 若参考资料中有多条相关内容,需整合所有信息,避免重复;
4. 若用户问题与参考资料无关,直接拒绝回答,不要勉强编造。
参考资料:
{context}
用户问题:{question}
请按照上述规则,生成回答:
"""
# 步骤3:调用GPT-4生成回答(复用前两天的chat_completion方法,无需重新配置)
answer = self.llm.chat_completion(prompt)
logger.info(f" 生成回答完成,长度:{len(answer)}字符")
return answer
# 主函数:运行RAG问答系统(命令行交互)
if __name__ == "__main__":
# 初始化RAG机器人
rag_bot = RAGChatBot()
# 命令行交互界面(简洁易懂,适合测试)
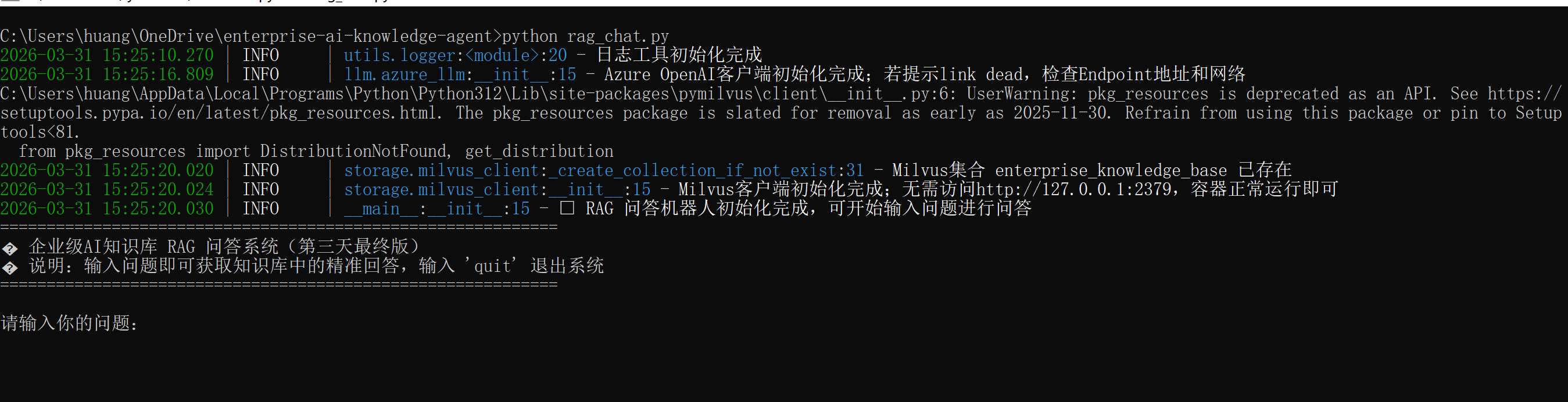
print("=" * 60)
print(" 企业级AI知识库 RAG 问答系统(第三天最终版)")
print(" 说明:输入问题即可获取知识库中的精准回答,输入 'quit' 退出系统")
print("=" * 60 + "\n")
# 循环接收用户输入,实现连续问答
while True:
try:
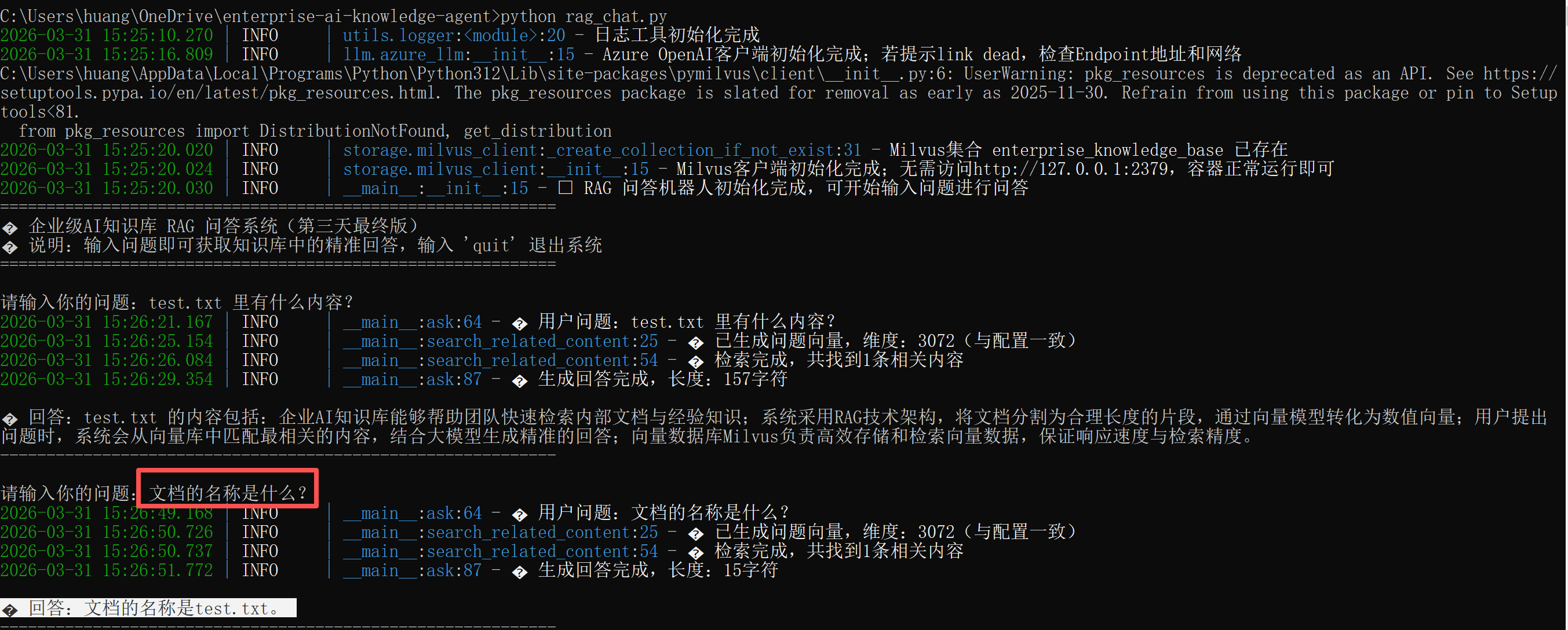
user_input = input("请输入你的问题:")
# 退出逻辑
if user_input.lower().strip() == "quit":
print("\n感谢使用,系统已退出!")
logger.info(" RAG 问答系统已正常退出")
break
# 空输入处理
if not user_input.strip():
print("请输入有效的问题,不要输入空内容!")
continue
# 生成回答并打印
response = rag_bot.ask(user_input)
print(f"\n 回答:{response}")
print("-" * 60 + "\n")
except Exception as e:
# 异常处理,避免系统崩溃,同时记录日志
error_msg = f"问答过程中出现异常:{str(e)}"
print(f" {error_msg},请稍后重试!")
logger.error(error_msg)详细运行说明
运行前请确认:前两天的代码已正常跑通(文档已存入Milvus向量库)、config.yaml配置正确(向量维度3072、Azure密钥有效),然后按照以下步骤操作,与第二天的运行方式完全一致:
- 准备工作(确认环境)
- 确认 Docker 中的 Milvus 容器已启动(若未启动,运行命令:docker start milvus-standalone);
- 确认前两天的依赖包已安装(无需新增依赖,沿用之前的环境即可);
- 确认 test.txt 文档已成功存入 Milvus 向量库(可运行第二天的 check_milvus.py 查看数据)。
- 运行命令
打开终端,进入项目根目录(与 document_processor.py、check_milvus.py 同级),运行以下命令:
python
python rag_chat.py- 运行效果示例
- 关键注意点(避免运行报错)
- 若提示"Azure 连接失败":检查 config.yaml 中的 endpoint、api_key 是否正确,网络是否正常;
- 若提示"Milvus 连接失败":检查 Docker 中的 Milvus 容器是否启动,port 配置是否为 19530;
- 若回答"未检索到相关内容":检查 test.txt 是否已成功存入向量库,或问题表述是否与文档内容相关;
- 若想调整检索条数:修改代码中 self.top_k = 3,数值越大,检索内容越全面,但生成回答速度稍慢。
常见问题排查
结合前两天的运行经验,整理第三天最可能出现的3个问题,给出具体排查方法,适合学习时参考,也可作为文章的"问题排查"章节:
问题1:运行后提示"未检索到相关内容"
排查步骤:
- 运行 check_milvus.py,确认 Milvus 向量库中是否有数据;
- 若没有数据:重新运行第二天的 document_processor.py,确保文档成功存入;
- 若有数据:检查用户问题与文档内容是否相关(比如文档是"AI知识库搭建",问题是"天气如何",则无法检索到内容);
- 若问题相关仍无法检索:调整 self.top_k 数值(比如改为5),或检查 Embedding 模型是否正确(确保是 text-embedding-3-large)。
问题2:GPT 回答编造内容
排查步骤: - 检查 prompt 提示词,确保包含"必须基于参考资料回答,不得编造"的约束;
- 确认检索到的 context 内容是否正确(可在代码中添加 print(context) 打印检索结果);
- 检查 GPT 部署名是否正确(config.yaml 中的 deployment_name_gpt4 需与 Azure 中的部署名一致)。
问题3:运行时出现"维度不匹配"报错
排查步骤: - 确认 config.yaml 中 vector_dim: 3072(与 text-embedding-3-large 维度一致);
- 确认 Milvus 集合已重建为 3072 维度(可重新运行 reset.py 删除旧表,重新生成新表);
- 确认 get_embedding方法返回的向量维度是 3072(可添加 print(len(query_vector)) 验证)。
总结
今天我们完成了 RAG 智能检索问答系统的完整实现,核心是"复用前序代码、实现检索+生成闭环",与前两天的内容形成完整的 AI 知识库搭建流程:
- 第一天:搭建基础环境(Azure OpenAI、Milvus),配置 config.yaml,定义核心客户端;
- 第二天:实现文档处理(读取、分块、生成向量),将文档存入 Milvus 向量库,可查看库中数据;
- 第三天:实现 RAG 问答(问题向量生成、语义检索、GPT 回答),完成"存入-检索-回答"的完整闭环。