论文总结
1、作者提出了TIP,适用于学习不完整表格数据的分类任务。作者在完整数据和不完整数据两种情境下展开了对比实验。
2、使用Transformer作为表格编码器,并使用自监督学习策略,用于解决数据缺失的掩码表格重建任务。
摘要
图像和结构化表格是现实数据库中不可或缺的组成部分。尽管表图表示学习在创造新见解方面前景看好,但这仍然是一项挑战,因为表式数据通常异构且不完整,与图像在模态上存在显著差异。早期研究主要聚焦于完整数据场景中的简单模态融合策略,未考虑缺失数据问题,因此在实际操作中存在限制。本文提出了TIP,一种新型的表图像预训练框架,用于学习对不完整表格数据具有鲁棒性的多模态表示。具体来说,TIP研究了一种新型自监督学习(SSL)策略,包括用于解决数据缺失的掩蔽表格重建任务,以及图像-表格匹配和对比学习目标以捕捉多模态信息。此外,TIP提出了一款适用于不完整、异构表格数据的多功能表格编码器,以及用于多模态表示学习的多模态交互模块。实验在下游多模态分类任务中进行,同时使用自然图像和医学图像数据集。结果显示,TIP在完全和不完整数据场景下均优于最先进的监督/SSL图像/多模态方法。我们的代码可在 https://github.com/siyi-wind/TIP 获取
引言
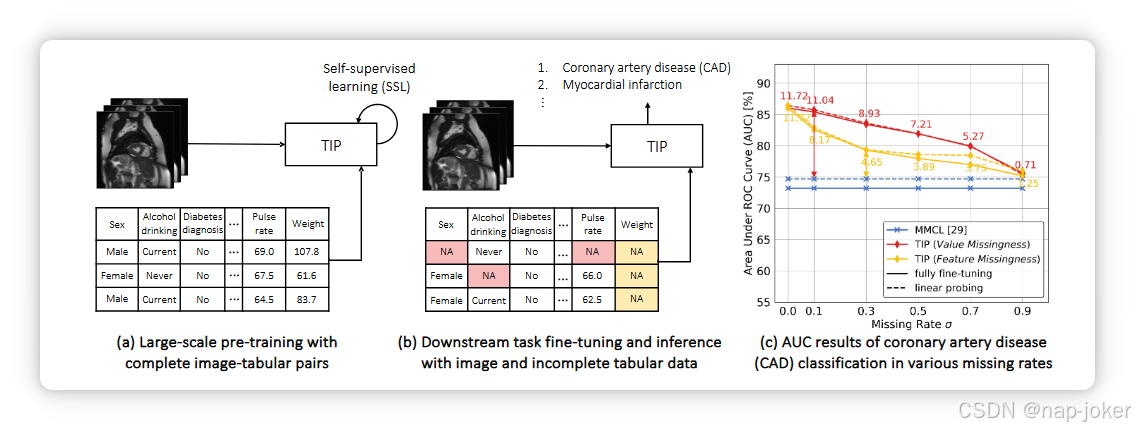
图1:TIP的工作流程(pipeline),该流程在大型多模态数据集(a)上预训练,可部署到数据缺失(b)的下游任务,例如值缺失(红色)和特征缺失(黄色)。冠状动脉疾病分类(c)结果显示TIP优于SOTA多模态预训练方法(数字表示性能提升)。完整结果见图4。
虽然结合图像和文本等多种模态构建多模态人工智能(AI)系统取得了显著进展,但整合表格数据的探索较少6, 9。然而,表格数据在多模态数据集中越来越容易获得,其集成在各种应用中至关重要 1,15,34,36,37。例如,在医疗领域,丰富的表格信息,如人口统计、生活方式和实验室检测(见图1(a)),通常与影像数据一起在医院收集,随后用于临床决策的联合指导方式5, 13, 16。大型人群研究14, 42,如英国生物样本库,进一步促进了机器学习和医学研究人员广泛获取此类多模态资源。尽管如此,目前图像表数据分析的技术相对有限。人们越来越关注开发有效的多模态表示学习方法,以充分利用图像和表格信息,以加深我们对人类健康的理解。与视觉语言建模相比,将图像和表格数据应用于实际应用是一项更为困难的任务,主要面临两个挑战。(1)低质量数据:尽管有大型多模态数据库支持预训练,但针对特定下游任务(如罕见病分类)的数据集可能有限,且常常存在数据稀疏性10。在图1(b)中,这些数据集可能无意中遗漏某些受试者的表格值,即值缺失(红色表格单元格),或仅遗漏整个特征(列),即特征缺失(黄色单元格),由于各中心的数据收集标准不同7,39,49。(2)模态差异:与图像和文本的同质性质不同,表格数据具有异质性,既有密集的数值特征,也有稀疏的类别特征。数据列显示出不同的值区间、含义,且没有明确定义的相互关系10。因此,如何设计一个能够有效学习表格和图像表示以弥补模态差距并弥补缺失数据的模型并非易事。虽然有一些处理噪声和缺失数据的解决方案26, 38, 61,但它们主要侧重于单模表格数据分析,而非多模态任务。以往的图像表格模型37,69,77大多在相对较小的标记数据集上训练和测试(例如,653个样本69),且表格信息有限(例如,12个特征77)。这些方法通常采用浅层多层感知器(MLP)和简单的模态融合策略,未考虑不完整数据和模态差异的挑战38。最近,Hager等人。29 提出了MMCL,这是首个SSL方法,通过多模态对比学习共同训练图像编码器和表格编码器。然而,它仅在下游任务中使用图像编码器,忽视了表格数据中丰富的决策信息。本研究为应对上述两个挑战,提出了TIP,这是一个基于新型多模态表示学习网络的表图预训练框架,以及一种用于管理小型、不完整下游数据的新颖SSL预训练策略(见图1(a,b))。具体来说,我们引入了基于Transformer的表编码器,配备多功能表嵌入模块,具有两个目的:(1)支持异构表输入和多样化数据缺失;(2)它捕捉了表格特征之间的相互依赖关系,并增强了表示学习。我们进一步设计了一个基于跨模态关注的多模态交互模块,以提取模态间信息。为了学习对缺失数据的稳健表示,我们引入了三个预训练任务:(1)掩蔽表重构,从随机掩蔽数据中提取模态内和模态间关系;(2)图像表对比学习以提升单模和多模态表示的学习;(3)图像表匹配以获得下游任务的联合图像-表表表示。对两个代表性数据集的实验,即来自英国生物样本库的心脏数据14和DVM汽车广告数据集的自然图像数据36,展示了TIP的优越性能。特别是如图1(c)所示,即使表格中缺失50%的值,TIP的AUC仍比SOTA多模预训练方法MMCL高出7.21%。我们的贡献可以总结如下。(1)据我们所知,我们是首个提出SSL图像表预训练,以应对低质量数据和模态差异的挑战,并调查多模态任务中各种数据缺失问题的机构。(2)我们引入了TIP,采用基于变换器的多模态架构以增强表示学习,并采用一种新的SSL预训练策略来解决表格缺失问题。(3)在自然和医学数据集上的实验表明,TIP在完全和不完全数据场景中显著优于SOTA监督/SSL图像/多模态方法,且缺失率各异。
相关工作
自监督学习(SSL)方法旨在通过在无标签数据集上预训练模型,通过各种模态内或模态间的前提任务,获得有用的中间表示41, 53。目前流行的两类模态内任务:(1)对比学习,模拟多个输入视图之间的相似性(和差异性)4, 18, 19, 61, 68;以及(2)基于世代的学习,预测缺失/损坏输入的值3, 12, 20, 32, 54, 65, 71, 73。随着多模态数据集的日益普及,模态间借口任务正受到更多关注,并展现出显著的性能17, 30。Radford 等人。57 引入了CLIP,该技术对海量网络数据进行图像-文本对比预训练,并展现出显著的零射击性能。后续研究45, 46, 74增加了诸如掩饰语言等任务建模更复杂的跨模态交互。然而,很少有研究探讨图像表预训练2, 29, 44。曾提出一些生成式像表模型2, 44,但仅限于使用两到四个表表特征。尽管MMCL 29使用了117个表格特征,但它只支持单模态下游任务,忽视了多模态信息在微调和推理时间中的实用性。我们是首个使用表格图像SSL预训练处理数据不完整多模态下游任务的公司。
深度学习(DL)与表格数据因其实现端到端多模态数据学习的能力而备受关注10。大多数现有作品依赖MLP并执行SSL任务来学习表示4, 65, 73。近年来,变换器被引入以处理更具挑战性的情况50,例如缺失和噪声数据38、列置换偏差70以及跨表学习68,71。这些最新发展激励我们将强大的Transformer架构应用于图像表学习。 多模态图像-表格学习利用表格数据作为辅助,促进视觉任务学习,这在医学领域尤为流行8, 35, 37,并且已取得优于纯图像模型的效果56, 66。以往的工作通常通过两个独立编码器提取图像和表格特征,这些编码器通过各种方法融合 11, 24, 24, 62, 66, 69, 77。然而,这些方法大多在表格特征有限的小数据集上测试,未考虑缺失数据。有些作品29, 40将表格知识转化为图像模型,但仅在下游任务中使用图像特征,忽略了表格数据中可能有用的信息。
缺失的表格数据是科学数据分析中的常见问题,已有许多解决方案被提出52, 60。一些统计方法使用列均值或中位数来填补缺失值52。另一种流行的方法是迭代补补,其中每个缺失值列将它建模为其他列的函数,采用轮询补补过程直到收敛 39, 58, 59, 63。随着深度生成模型的出现,基于深度生成模型的补补算法被引入51, 72,尽管这些算法仅限于预处理步骤,且仅支持值缺失26。一些算法利用SSL预训练,通过重建38, 73、对比学习4或去噪61,使模型对噪声或不完整的表格数据更具鲁棒性38, 73。相比之下,我们的研究是首次在多模态环境中探讨各种表格缺失的情况。
方法
本节介绍我们的TIP,一种表态图像预训练框架,先在大型多模态数据集上进行预训练,然后在下游任务中进行微调,例如完整/不完整数据分类。为了编码不完整、异构的表格数据并增强表示学习,我们提出了一种定制化的表格编码器,具有多功能的表格嵌入和变换器层,以及基于跨模态注意力的多模态交互模块。此外,我们还设计了一种新的多模态SSL预训练策略信息提取以及解决潜在数据缺失。TIP的整体框架如图2所示。我们在第3.1节介绍了TIP的模型架构,随后在第3.2节讨论其SSL预训练策略。
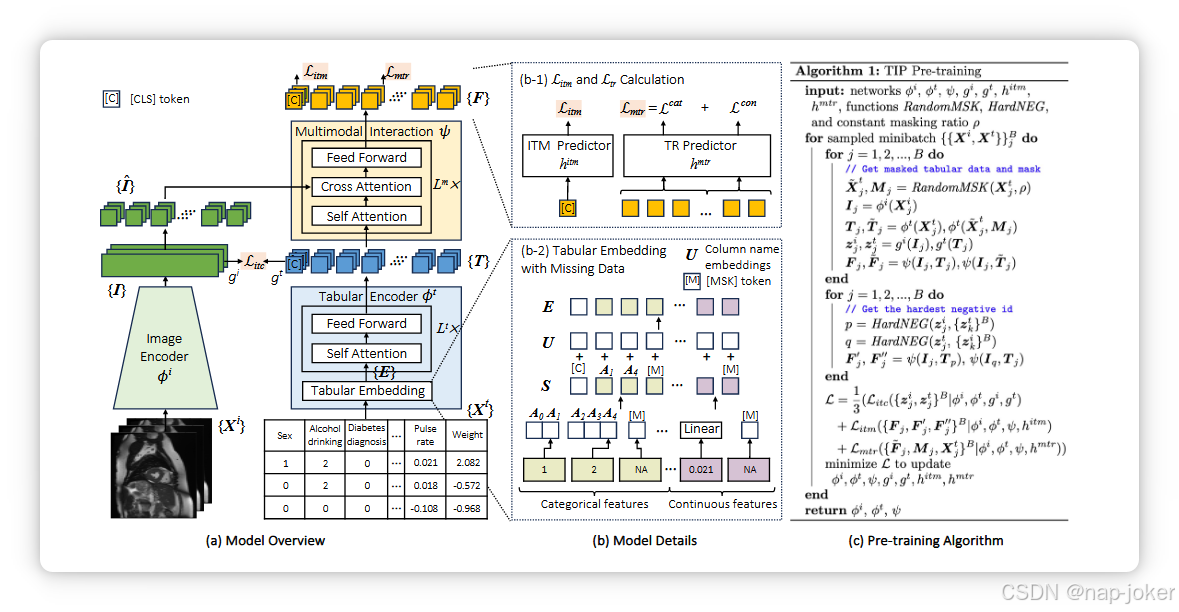
图2:TIP的模型架构和算法:(a)模型概述,包含其图像编码器、表格编码器和多模态交互模块,这些模块使用三种SSL损耗预训练:Litc、Litm和Lmtr。(b)用于(b-1)Litm和Lmtr计算的模型细节,以及(b-2)带缺失数据的表格嵌入。(c) 预训练算法。
TIP模型架构
设(Xi ∈ RH×W ×3, Xt = xt1, ..., xt N ∈ RN)为一对像表对,其中N为表特征数量。假设每个表格输入包含Na的范畴特征xt1、...、xt Na和N−Na连续特征xt Na+1, ..., xt N。我们将类别数据转换为序数,并将连续数据标准化为29。如图2(a)所示,TIP包含基于卷积神经网络(CNN)的图像编码器φi、表格编码器φt和多模态交互模块ψ。图像编码器分别提取图像表示I∈RH′×W ′×C,表表示T∈RN×D,其中C和D分别为对应的通道维度。我们将 I 转换为并投影为嵌入序列 Iˆ ∈ R(H′W ′)×D。基于此,多模交互模块接收 Iˆ 和 T 的输入,进行模态间学习,得到多模态表示 F ∈ RN×D。表编码器:处理潜在缺失的异构数据,并从表特征中提取丰富的上下文信息, 我们提议将每个表形式特征视为基本元素,并通过一个多功能的表表嵌入模块将其转换为标记嵌入(见图2(b-2))。然后,我们通过变换器层,使嵌入的令牌能够关注相关令牌。我们的表格嵌入模块包含三个部分:异构数据处理、缺失数据处理和列多样性集成。
(1) 异构数据处理:表格数据通常包含类别变量和连续变量,这些变量属性类型差异很大,无法用单一函数嵌入10, 27。因此,我们的表格嵌入模块可以独立处理这两种特征。特别地,我们将每个范畴特征转换为符号嵌入,使用可学习嵌入矩阵A∈RN ̄a×D,其中N��a是Na范式特征中唯一值数量的求和。同时,我们采用共享线性层将每个连续特征投影到D维空间中。(2)缺失数据处理:为了处理不完整数据并告知模型在训练中缺失的数据,我们建议使用特殊的可训练D维MSK令牌嵌入每个缺失值。该方法无需在输入前进行数据补补,且可处理各种类型的缺失数据场景,比以往仅支持随机缺失的技术4, 39, 73更灵活。嵌入特征通过特殊的可调CLS令牌串接,生成嵌入序列S。CLS 令牌在最后一个变换器层的状态作为下游分类任务的学习表示,如45, 46。(3)列多样性积分:表格数据中的每一列通常有不同的含义,因此不适合将它们统一地视为图像中的像素44,70。为了区分不同的列并捕捉列间关系,我们提出通过一系列可学习的列名嵌入 U ∈ R(N+1)×D 来整合列多样性。我们无需使用预训练语言模型将列名标记为固定的文本嵌入68, 70, 71,而是通过数据驱动策略动态捕捉训练数据中隐藏的列依赖关系。例如,"体重"和"饮酒"两项可能语义相似性不大,但可能具有强烈的临床关联。最终嵌入表述为:E = S + U。受变换器通过自我关注捕捉长距离依赖67和嵌入大型数据库知识30, 43的能力驱动,我们利用Lt变换器层67编码表信息并提取高层表表示T .为避免缺失数据对模型学习的潜在负面影响32,我们采用了自我关注掩码,限制每个标记只关注自身和未缺失标记,从而确保表表表示学习更稳健稳定。多模态交互模块:为增强多模态表示学习并捕捉跨模态关系,我们提出利用变换器解码模块中的交叉注意力机制67,使CLS令牌和每个表格令牌能够交叉关注相关图像信息。交互模块由多个 Lm 层组成,每个层包括自关注、跨模态注意、MLP 前馈模块和层规范化。l层的跨模态注意力可以写成:
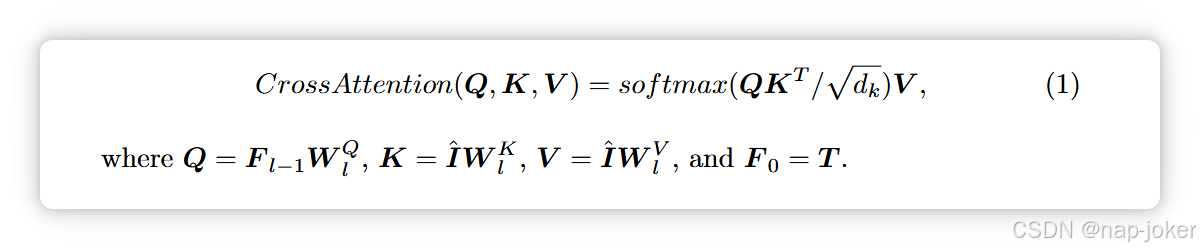
SSL预训练策略
为了使模型对不完整的下游数据保持鲁棒性,同时提升表示学习能力,我们建议用三个目标预训练模型,包括掩蔽表重建、图像-表格对比学习和图像-表格匹配,如图2(a,c)所示。 图像表对比学习(ITC):我们设计ITC任务,旨在捕捉更优的单模表示并在模态融合前对齐其特征空间。这与图像-文本对比学习的动机相似,后者已证明能够提取下游任务的可转移表征并促进跨模态学习45,46,57。ITC鼓励匹配样本中的图像和表格表示与未匹配样本的表示接近。我们利用两个投影头 gi 和 gt 将 I 和 T 带到共享的低维隐空间,并计算图像到表格和表格到图像的相似度,即 si2t j 和 st2i j ,格式为 46。图像表对比损耗可计算为 Litc = −(si2t j + st2i j )/2。 图像-表格匹配(ITM):我们提出ITM任务,使TIP的多模态交互模块能够捕捉模态间关系并生成联合多模态表示,灵感来自图像-文本匹配的成功45, 46。我们的ITM旨在预测一对成像和表格输入是正(匹配)还是阴(未匹配)。如图2(b1)所示,我们将F的CLS嵌入输入,该嵌入捕获了图像-表格对的联合表示,输入ITM预测器hitm(线性层),以基于二元交叉熵损失Litm进行匹配预测。为了增强表征学习和捕捉判别特征,我们利用46提出的硬负挖掘策略(HardNEG)将模型暴露给更具信息量的负对。具体来说,对于每个图像/表格表示,我们从小批量中选择一个未匹配的表/图像表示,使用ITC中计算的相似度作为采样权重。 掩面表重建(MTR):该任务旨在学习多模态表示,能够对下游任务中缺失的表格数据保持鲁棒性。以往研究发现,重建掩蔽数据有助于缓解噪声或缺失数据问题,并在SSL表示学习中获得有前景的性能21,38,50,55,64,76。因此,我们提出了多模态表示学习的MTR,并要求模型基于图像和未掩蔽的表信息预测表表数据中的遮蔽部分。具体来说,我们对基于掩蔽比值ρ的表格输入应用随机遮罩(RandomMSK),生成掩蔽版本 X ̃ t,即将掩蔽值视为缺失数据,并生成用于记录掩蔽位置的掩蔽矩阵 M。 所得的 X ̃ t 随后被输入模型,生成掩码多模表示 F ̃ = f ̃1, ..., f ̃N 。生成的F ̃作为MTR预测器hmtr的输入,用于重建缺失值。由于重建类别数据是分类任务,而重建连续数据是回归任务,hmtr 具有两个不同的线性层,分别是 Na 类别处理和N − Na 连续特征对应:
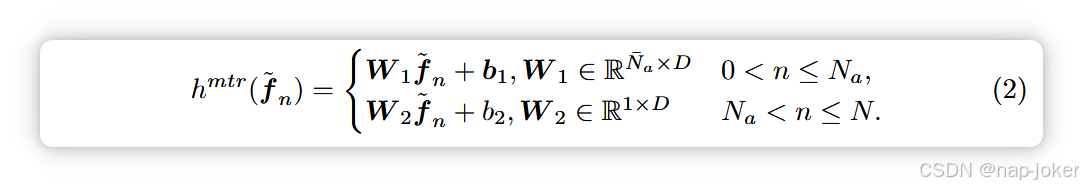
我们仅基于掩蔽特征构建重建损失,Lmtr = Lcat + Lcon,其中Lcat表示范式特征的交叉熵损失,Lcon是连续特征的均方误差损失。与以往用随机选择值填充掩蔽单元格的表格技术38, 73相比,我们采用随机掩蔽策略的MTR任务使模型能够学习下游任务中缺失数据的掩码令牌,从而使模型能够充分理解缺失的值并处理多样化的数据缺失情况, 即使缺少整列。最终,整体训练前损失函数被表述为:
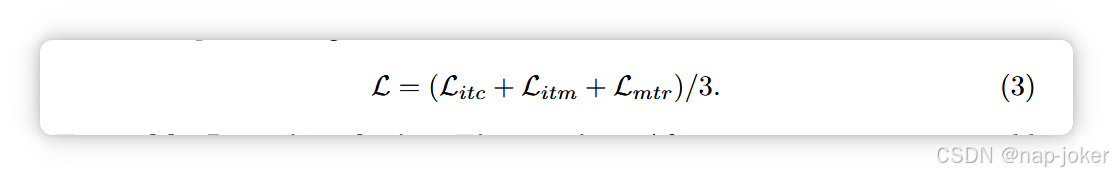
微调中的集合学习:预训练后,我们可以在特征提取器后添加线性分类器,用于下游分类任务。鉴于我们的预训练策略使图像编码器、表格编码器和多模态交互模块能够学习对后续任务有益的丰富表征,同时受到集合学习提升模型泛化性和结果能力的激励22, 25,我们提出构建一个集合模型以进一步提升模型性能。具体来说,我们在三个模块后面集成一个线性分类器,并将三个分类器的预测值平均,生成最终输出。
实验
数据集与指标:与29类似,我们在两个大型数据集上进行了实验:一个是医学数据集------UK生物样本库(UKBB)14和一个自然图像数据集Data Visual Marketing(DVM)36。UKBB包含从英国个体收集的丰富心脏影像和临床表格数据48。我们执行两项心脏疾病分类任务:冠状动脉疾病(CAD)和心肌梗死(梗死),使用二维短轴磁共振(MR)图像和75个与疾病相关的表格特征(详见Sec.补充材料(补充))。该数据集包含36,167对图像表对,分为训练组(26,040组)、验证组(6,510组)和测试组(3,617组)。由于疾病患病率较低(梗死3%,CAD6%),我们使用平衡训练数据集进行微调,CAD共3,482个,梗死1,552个,并评估所有曲线下面积(AUC)模型。DVM 36 是一个公开可用的汽车应用数据集,包括二维汽车图像和与汽车相关的表格数据。我们获得了176,414对图像-表格(17个表格特征,详情见Sec.A的补充。)并实现包含283个类别的汽车模型分类任务。我们将数据集分为训练组(70,565)、验证组(17,642组)和测试组(88,207组),并以准确率进行评估。
表1:DVM、CAD和梗死分类任务对TIP与监督/SSL图像/多模态技术的完整数据比较结果。表示线性探测,即特征提取器被冻结,只有预训练模型的线性分类器被调优。] 表示完全微调,即所有参数均可训练。对于监督方法,所有参数都可以在 和 ] 列中训练。
实现细节:我们使用了ResNet-50 33作为图像编码器。我们的表格编码器和多模交互模块均有4个变换器层,8个注意力头和隐藏维数512。我们在 ITC 中用了 MLP,GI 隐藏尺寸为 2048,gt 隐藏尺寸为 512。这两个MLP的输出大小均为128。ITC的温度参数τ为0.1,MTR的遮蔽比ρ为0.5。图片缩放为128×128。在预培训期间,我们对ITC和ITM进行了表格增强,并为3项预培训任务进行了图像增强。注意,CAD和梗死任务在微调时使用相同的预训练模型。TIP及其他比较模型的更多实现细节见补充品B节。
与SOTA在完整下游数据上的比较
我们首先通过比较TIP与其他监督和SSL预训练算法,研究其在完整下游数据体系中的表现。对于监督学习,我们训练了一个全监督图像模型ResNet50,并重现了4种图像-表格学习策略:串接融合(CF)62、最大融合(MF)66、通过通道乘法进行交互融合(IF)24和动态仿射特征映射变换(DAFT)69。为了公平对比,所有这些方法中使用的图像编码器均为ResNet-50。对于SSL图像预训练,我们测试了4种流行的对比学习解决方案:SimCLR 18、BYOL 28、SimSiam 19和BarlowTwins 75。我们还将TIP与MMCL进行了比较,后者是一种近期的多模态图像-表格预训练方法。我们用线性探测(仅调优线性分类器)和全微调(训练所有参数)评估了所有预训练模型。
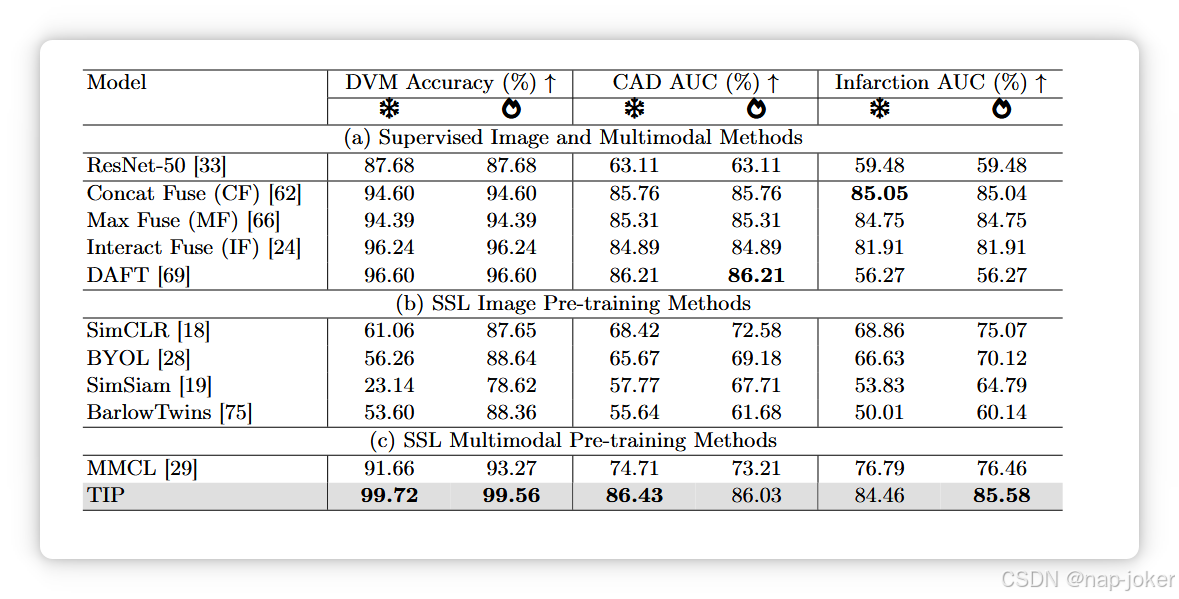
如图1(a,b)所示,TIP在线性探测和完全微调中远远优于监督/SSL仅图像模型,这表明在预训练中整合多种模态提升了表征学习效果,且表格信息有助于我们的分类任务。此外,TIP在线性探测等方面显著优于MMCL,在DVM上准确率提升了8.06%,在CAD上AUC提高了11.72%。MMCL将与视觉特征相关的表格信息传输到图像分支,并在微调时丢弃表格分支,而表格数据通常包含图像中不可见的任务相关补充信息1,5。我们的结果展示了TIP可以利用图像中可见或不可见的表格信息来改进后续任务。最后,与监督式多模态方法相比(见表1(a)),TIP在DVM上表现更佳,例如线性探测的准确率提升了3.12%。在CAD和梗死任务中,TIP在监督多模态方法中表现优异,表明通过自监督预训练学习的特征具有实用价值,且需要更大的预训练数据集(DVM为70,565,UKBB为26,040)。对低数据体系的鲁棒性:由于下游任务的数据注释通常成本较高,我们建议评估TIP及其他SOTA方法在低数据状态下(原始训练数据大小的10%和1%)的性能。我们使用了7,056个(10%)和705个(1%)的DVM训练样本,CAD的训练样本349和35个,梗死的训练样本分别为156和16个。对于SSL镜像方法,仅展示SimCLR的结果,因为它在其中表现最佳(完整结果见补充C节)。图3显示TIP在低数据区段更为稳健,且在DVM上优于其他SOTA。对于TIP,10%的训练数据已能达到接近100%的性能,表明可以减少微调所需的数据。仅在1%CAD和10%梗死的两个案例中,TIP略逊于CF(一种监督多模态方法),这可能是由于TIP使用的CAD和梗死的预训练数据集相对较小。
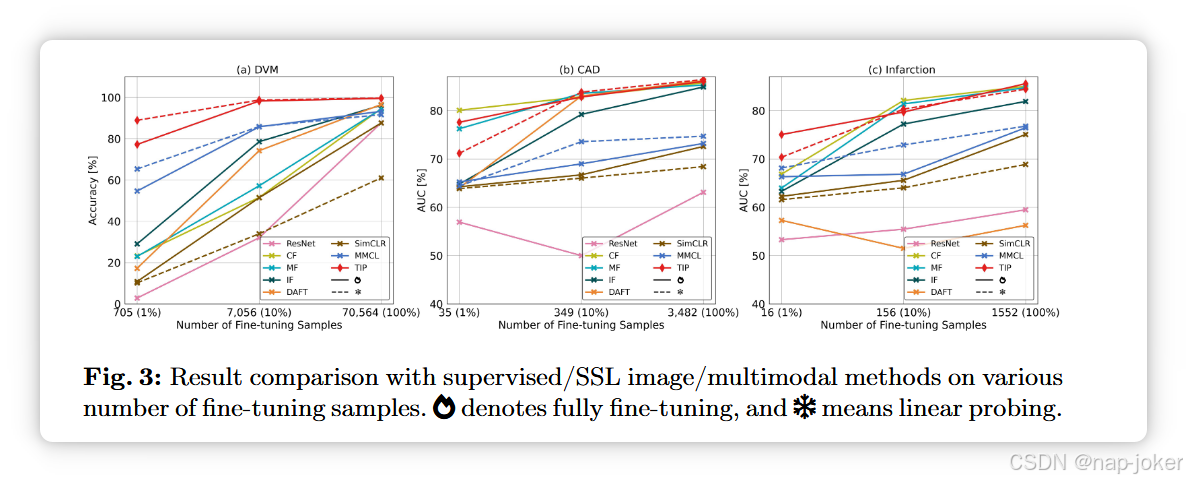
与SOTA在不完整下游数据上的比较
我们开展一项研究,评估模型在解决表格缺失问题上的表现。为此,我们引入了4种缺失情景类型:(a) 随机值缺失性(RVM),表中值(单元格)随机缺失;(b) 随机特征缺失(RFM),即一组随机特征(列)缺失;(c) 最重要的特征缺失(MIFM),即预测任务中最重要的特征按降序被消除;(d) 最不重要的特征缺失(LIFM),即优先去除最不重要的特征。特征的重要性通过随机森林算法47在下游训练数据集上训练确定。为了展示TIP利用多模态信息处理缺失数据的能力,我们将其与3种SSL表预训练方法进行比较:VIME 73、SCARF 4和SAINT 61。基于MLP的VIME和SCARF不支持功能缺失,而基于变压器的SAINT则能处理所有缺失场景。因此,我们仅通过用随机选择的值填补缺失位置,如4, 73,来评估RVM中的VIME和SCARF。监督多模态方法无法解决随机值缺失问题。因此,它们在RFM、MIFM和LIFM中进行比较。SSL图像技术和MMCL不会受到缺失的表格数据影响。为了全面比较,我们包含了其中最高的MMCL结果。我们执行每个场景时缺少6个缺失率。 如图4所示,最具挑战性的场景是MIFM,大多数模型的性能显著下降。此外,还有监督下的多模态方法当 σ = 0.1 时,在 MIFM 和 RFM 中运行 ResNet 和 MMCL,并在 LIFM 的不同缺失率下实现更好的结果。
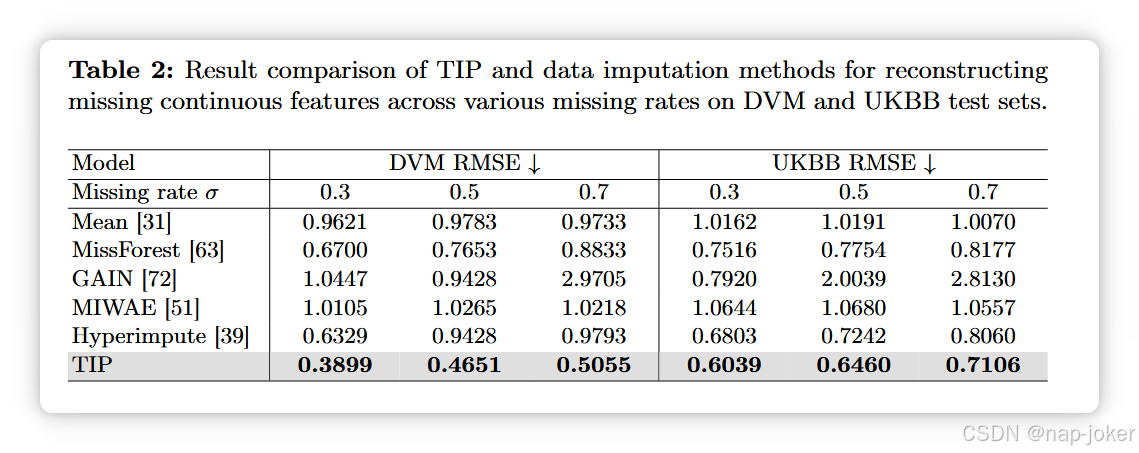
这意味着即使下游数据不完整,它们仍然可以提供有用信息,尤其是在没有缺少MI特征的情况下。我们注意到一些模型在MIFM缺失率较高时表现出显著增加,并将其归因于其特征重要性与随机森林模型识别的不完全相同。与其他方法相比,TIP能够应对各种类型的数据缺失情景,并且显著优于其他方法。对于监督多模模型(图4(b,c,d)),缺失数据会显著降低其性能,尤其是在缺失率较高时。然而,TIP在不同缺失率下依然稳健,并表现出更好的表现。例如,在RFM(σ = 0.5)中,TIP在DVM上比DAFT提高了3.9%,在CAD上AUC提高了4.7%。这意味着我们的预训练策略允许模型从未标注的图像-表格对中捕捉有价值的多模态嵌入及其关系。此外,TIP的表现优于表格预训练技术(见图4(a)中的VIME和SCARF),尤其是在缺失率较高的情况下,例如当σ = 0.5时,TIP在DVM上准确率提升了75.02%。与同样在微调时使用可学习掩码令牌的SAINT相比,TIP的优异性能表明我们的SSL策略在处理不完整的下游数据时更有效,并使模型能够整合视觉和表格信息以预测缺失的组件。最后,与多模预训练模型MMCL相比,TIP在所有场景下都远远优于MMCL,即使缺失率高达0.7。这表明TIP能够充分利用不完整数据中的表格信息。即使下游任务中的某些表格特征不可访问,预训练期间学习到的模态内和模态间关系仍使TIP能够产生有希望的结果。缺失值重建:我们进一步评估TIP缺失数据重建表现,比较5种数据补值方法:列均值替换(Mean)31、MissForest63、GAIN 72、MIWAE 51和HyperImpute39。由于GAIN和MIWAE难以应用于包含连续和类别特征的混合类型数据,我们的实验重点关注DVM和UKBB测试集中的连续数据,并使用均方根误差(RMSE)进行评估。在这种情况下,我们掩盖了类别TIP的数据输入。如表2所示,TIP在不同缺失率上超过了这些补补算法,这表明我们的预训练任务和多模态架构使模型能够捕捉多模数据的关系,从而更准确地预测缺失信息。
消融实验和可视化
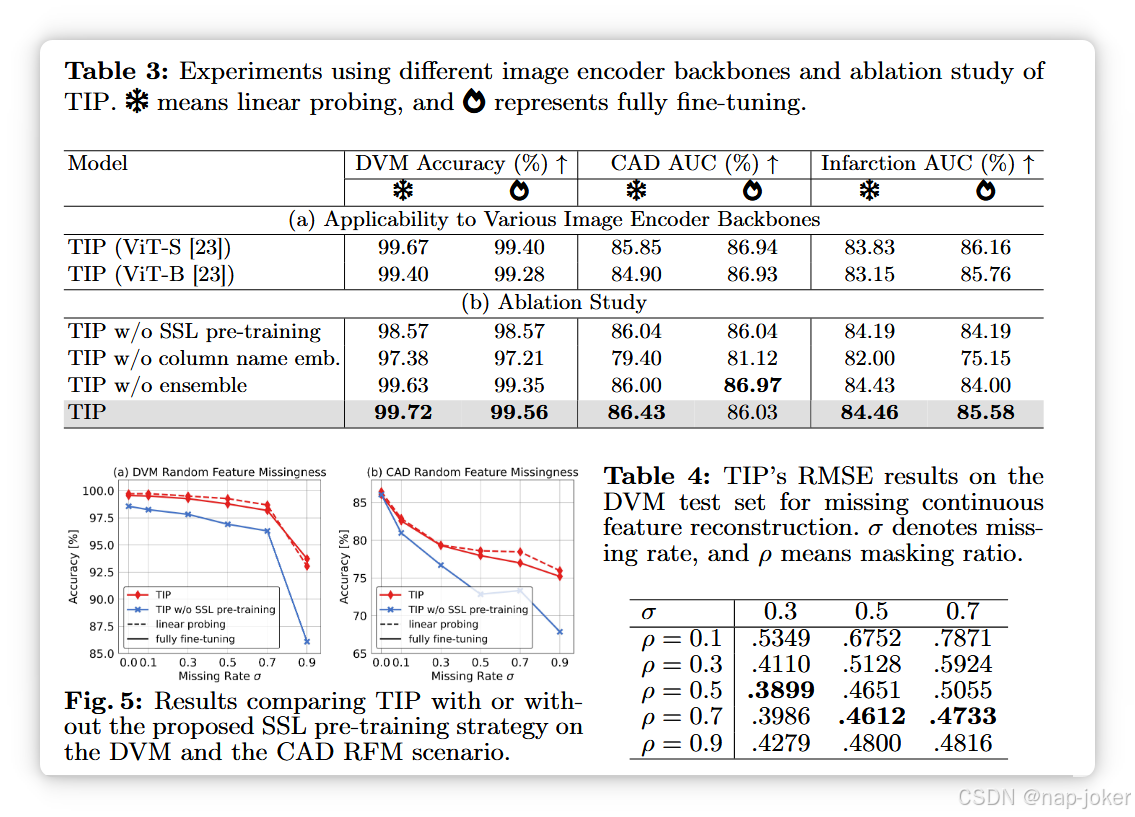
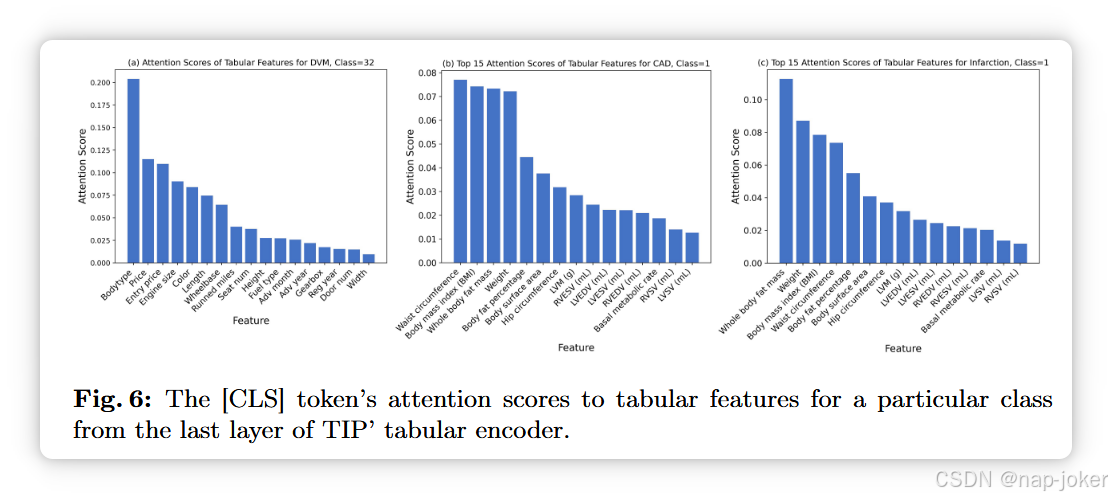
适用于不同图像编码器骨干:我们提议变换图像编码器骨干,以展示所提方法的普遍适用性。具体来说,我们使用了两种视觉变换器(ViT):ViT-S/16 和 ViT-B/16 23,作为图像编码器的变体。由于ViT输出的是序列表示,我们直接将其投影到与表格表示相同的隐藏维度中。表3(a)示例说明,使用ViT的结果与使用ResNet-50相似,且大ViT-B表现并不优于较小的ViT-S。我们怀疑这是因为ViT在预训练后,在更大数据集上表现优于CNN,如23所示。 关键模型组件的消融研究:我们直接在监督下训练了TIP的模型架构,以评估SSL预训练策略的有效性。表3(b)和图5表明,我们的预训练策略能提升下游任务的性能,尤其是在缺失率较高且不完整数据时。此外,我们还进行了实验,去除了表格编码器中的列名嵌入或者微调过程中的集合学习。第3(b)条显示,扣除上述任何一项技术会导致性能下降。关于每个预训练任务及TIP表格编码器在补充品C.2-3条款中的额外消融研究。 掩蔽比的敏感性分析:我们研究不同掩蔽比ρ在MTR任务中的影响。表4显示,中等的掩蔽比ρ ∈(0.5, 0.7)能获得最佳性能,而过高(0.9)或过低(0.1)比值则不利于模型学习。更多分析见补充条款C.4。TIP表格特征注意力的可视化:在图6中,我们可视化了TIP在预测下游任务中特定类别时对不同表格特征的关注。为此,我们对测试集中同类样本的自注意力映射取平均,并给出CLS标记的注意力分数。我们观察到,TIP不仅关注与图像相关的特征,例如DVM中的颜色,还关注图像中不直接可见的特征,例如DVM中的价格。这凸显了整合多模态数据的重要性,因为它能在后续任务中提供额外的补充信息,而这些信息仅凭图像数据往往难以获得。关于交叉注意力和案例研究的更多可视化见补充文C.5。
总结
我们提出了TIP,一种用于多模态表示学习的新型表图预训练框架。TIP是一种基于Transformer的多模态网络,配备多功能的表式编码器和多模交互模块,这些模块通过一种新型自监督预训练策略进行训练。特别是,TIP考虑了表格数据缺失,使其适用于现实世界数据集。在自然和医学图像数据集上的实验展示了TIP在各种缺失数据场景中的SOTA表现以及所提模型组件的有效性。当前的工作利用模拟缺失数据和二维图像。未来的研究将纳入现实世界的不完整数据,并扩展到更高维度的图像,如三维和时间成像数据。潜在的社会影响在补充材料中进行了讨论。