前言
朴素贝叶斯作为概率论中的概念,通过对文本内容的训练,可以概率的方式进行情感分析!
一、概率基础复习
1.1 条件概率
- 定义:在事件 B 已经发生的条件下,事件 A 发生的概率,记作 P(A∣B)。
- 公式:
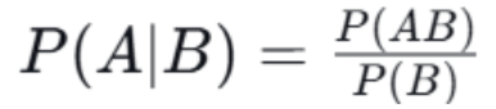
1.2 联合概率
- 定义:多个事件同时发生的概率,记作 P(AB)。
- 一般公式:P(AB)=P(A)⋅P(B∣A)=P(B)⋅P(A∣B)。
- 独立事件:若 A 与 B 独立,则 P(AB)=P(A)P(B)。
1.3 条件概率与联合概率示例
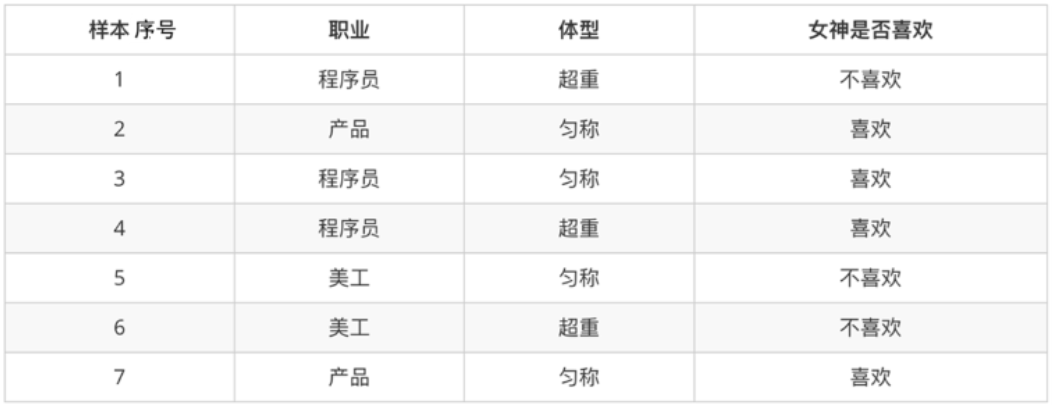
根据示例数据表(包含职业、体型、是否喜欢):
- P(程序员∣喜欢)=2/4=0.5
- P(程序员且匀称)=3/7×1/3=1/7
- P(程序员且超重∣喜欢)=0.5×0.5=0.25(在独立假设下)
二、贝叶斯公式
2.1 公式
数学公式:
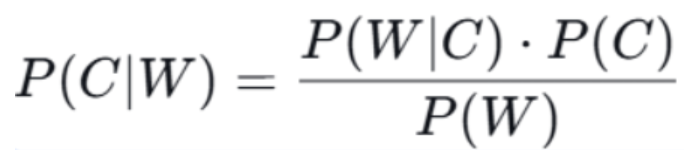
等同于:

注释:
-
P (C ):先验概率(没有观察到任何特征(证据)的情况下 ,类别 C 在样本空间中出现的概率)
-
P(W∣C):似然/条件概率(已知样本属于类别 C 的条件下,该样本具有特征 W 的概率)
-
P(W):证据/全局概率(在整个样本集中,特征 W 出现的概率)
-
P(C∣W):后验概率(已知特征 W,样本属于类别 C 的概率)
核心逻辑 :通过先验概率 + 条件概率,推导后验概率,实现样本分类。
2.2 示例

三、朴素贝叶斯
朴素贝叶斯的核心思想可以概括为:利用贝叶斯定理计算后验概率,并假设特征之间相互独立以简化计算。它通过统计先验和条件概率,实现对样本的分类。虽然独立假设在现实中可能不成立,但其简单高效和较好的性能使其成为机器学习中的经典算法之一,特别适合文本分类等任务。
3.1 特征条件独立假设
如果特征不止一个(比如既有天气,又有温度、湿度),那么计算似然概率 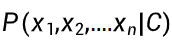
会非常复杂,因为需要知道特征之间的联合分布。为了简化计算,朴素贝叶斯引入了一个强假设 :所有特征在给定类别的条件下相互独立。
即:
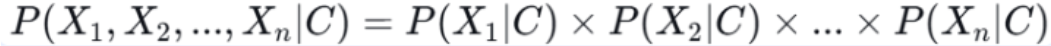
例:
-
P(程序员,超重∣喜欢) = P(程序员∣喜欢)⋅P(超重∣喜欢)
-
P(程序员,超重) = P(程序员)⋅P(超重)
这个假设称为"朴素"(naive),因为在现实中特征往往并不独立(例如"晴天"和"高温"可能相关),但实践表明它仍然能取得不错的效果。
为什么这样假设?
- 将联合概率分解为多个边缘概率的乘积,大大简化了计算。
- 每个
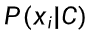
可以独立地从训练数据中统计得到,避免了高维联合分布估计的困难。
3.2 拉普拉斯平滑(也称为加一平滑)
- 问题:若某特征在训练集中未出现,则概率为 0,导致后验概率为 0,影响分类。
- 解决:引入拉普拉斯平滑系数 α(通常取 1):
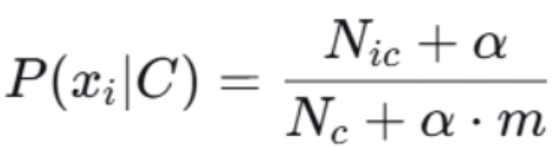
等同于:

注释 :
核心逻辑
它主要解决的是**"零概率问题"------ 当某个特征在训练集中从未出现过时,直接计算为 0 会导致整个模型预测失效,平滑机制可以给它一个很小的非零值。避免零概率,保证所有特征都有非零概率。**
核心原理(为什么要这么写?)
1. 为什么要加 α?(解决零概率)
如果不加分,当 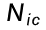 =0(没见过这个词)时,概率会变成 0。这会导致后续的乘积计算变成 0,模型无法判断。加上 α(通常取 1),就是给这个没见过的词留一条活路,让它拥有一个极小的概率。
=0(没见过这个词)时,概率会变成 0。这会导致后续的乘积计算变成 0,模型无法判断。加上 α(通常取 1),就是给这个没见过的词留一条活路,让它拥有一个极小的概率。
2. 为什么分母要乘 m?(归一化保证和为 1)
- 不加 m 时:
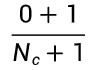
,这会导致该类别下所有概率之和 ≠1。 - 加上 m 后:相当于给每一个特征 (哪怕是没见过的)都预先分配了一个
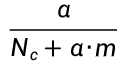
的概率,保证所有可能的特征概率之和为 1,符合概率定义。
3.3 朴素贝叶斯的三种常见变体
根据特征分布假设的不同,朴素贝叶斯有以下几种常用模型:
| 模型 | 适用特征 | 假设 | 典型应用 |
|---|---|---|---|
| 高斯朴素贝叶斯 | 连续特征 | 特征服从高斯分布(正态分布) | 身高、体重等连续值分类 |
| 多项式朴素贝叶斯 | 离散特征(计数) | 特征服从多项分布 | 文本分类(词频) |
| 伯努利朴素贝叶斯 | 布尔特征(0/1) | 特征服从伯努利分布 | 文本分类(词是否出现) |
- 多项式朴素贝叶斯 是最常用的文本分类模型,因为它能很好地处理词频。
- 高斯朴素贝叶斯 适用于连续特征,如鸢尾花数据集。
- 伯努利朴素贝叶斯 适合特征为二值的情况,如"是否包含某词"。
3.4 朴素贝叶斯的优缺点
优点
- 算法简单,易于实现:只需要统计先验和条件概率。
- 训练速度快:一次扫描数据即可完成统计。
- 对小规模数据表现良好:不需要大量训练样本。
- 可解释性强:分类结果基于概率,可以给出置信度。
- 适合多分类任务:天然支持多类别。
缺点
- 特征独立假设在现实中往往不成立,可能导致概率估计偏差。
- 对输入数据的表达形式敏感:例如连续特征需假设分布。
- 零概率问题需要平滑处理(已通过拉普拉斯解决)。
四、朴素贝叶斯 API 及案例
4.1 API 介绍(sklearn)
python
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=1.0)alpha:拉普拉斯平滑系数,默认 1.0。- 适用于离散特征(如文本分类中的词频)。
4.2 案例:商品评论情感分析
需求:根据评论内容判断是好评还是差评。
4.2.1 需求说明
任务目标
利用已有的商品评论数据(包含评论文本和对应的情感标签),训练一个文本分类模型,使其能够自动判断新的评论是好评还是差评。这是一个典型的二分类问题。
数据概况
-
数据来源:
书籍评价.csv(样本片段共13条,实际完整数据可能更多) -
字段:
-
内容:评论的文本内容(中文)评价:情感标签("好评"或"差评")
-
数据特点:文本长度不一,包含口语化表达、标点符号等;标签为二值类别。
业务意义
帮助电商平台或内容网站自动分析用户反馈,量化产品口碑,及时发现负面评价,辅助产品改进和运营决策。
4.2.2 处理思维流程
1. 数据加载与理解
- 读取CSV文件,查看数据结构和样本分布(好评、差评各自数量)。
- 检查是否存在缺失值或空文本,若有则进行剔除或填充。
2. 文本预处理
- 标签编码:将"好评"映射为1,"差评"映射为0(或其他数值),便于模型计算。
- 文本清洗:去除无关符号(如标点、数字、特殊字符),统一大小写(英文),但中文需保留汉字。
- 分词:使用中文分词工具(如jieba)将评论文本切分成词语序列。
- 去停用词:加载停用词表,过滤掉"的"、"了"、"是"等无实际意义的词语,减少噪声。
3. 特征提取
-
将分词后的文本转换为数值特征向量,常用方法:
-
- 词袋模型(CountVectorizer):统计每个词在文档中出现的次数。
- TF-IDF(可选):不仅考虑词频,还考虑词语在整个语料中的稀有程度,可提升效果。
-
注意:特征维度可能较高,但朴素贝叶斯对此有较好的适应性。
4. 数据集划分
- 将数据划分为训练集 和测试集(例如80%训练,20%测试)。
- 由于数据量可能较小,可采用分层采样 (
stratify)确保训练/测试集中正负样本比例与原始数据一致。 - 若数据极少,可考虑交叉验证。
5. 模型选择与训练
- 选择朴素贝叶斯 分类器,具体为多项式朴素贝叶斯(MultinomialNB),因为它适合离散计数特征(如词频)。
- 设置拉普拉斯平滑系数(
alpha,默认1.0)避免零概率问题。 - 用训练集拟合模型。
6. 模型评估
- 在测试集上进行预测,输出分类报告 (精确率、召回率、F1-score)和混淆矩阵,评估模型对好评和差评的识别能力。
- 若数据不平衡,可重点关注少数类的召回率。
- 也可计算准确率,但需结合其他指标综合判断。
7. 模型优化(可选)
- 调整特征提取参数(如ngram_range、max_features)。
- 尝试不同的分词工具或停用词表。
- 若效果不佳,可考虑其他模型(如支持向量机、逻辑回归),但朴素贝叶斯在文本分类中通常表现良好且高效。
8. 模型保存与应用
- 将训练好的模型和向量化器保存为文件(如
.pkl),便于后续对新评论进行实时预测。 - 部署时可封装为API,接收文本返回情感类别。
4.2.2 代码实现
python
# 导入必要的包
import re # 导入正则表达式包
import pandas as pd # 导入数据处理包
import jieba # 导入分词包"结巴"
from sklearn.feature_extraction.text import CountVectorizer # 导入词频统计工具
from sklearn.naive_bayes import MultinomialNB # 导入朴素贝叶斯对象
from sklearn.metrics import (classification_report, # 评价报告包
confusion_matrix) # 混淆矩阵包
from sklearn.model_selection import train_test_split # 导入数据集划分工具
import pickle # 导入pickle包
##### 1. 数据加载与理解
# 读取数据
data = pd.read_csv(r'file/书籍评价.csv', encoding='gbk') # 文件内容是中文,在win系统下需要GBK编码
# 查看数据结构和样本分布(好评、差评各自数量)
print("数据结构:",data.shape) # 样本结构:(13行, 3列)
print("字段信息:", data.info())
print("样本分布:\n",data['评价'].value_counts())
# 检查是否存在缺失值或空文本,若有则进行剔除或填充。
print("缺失值:", data.loc[:,data.isnull().any()].sum()) # 仅显示有缺失值的字段
print("重复值:", data.duplicated().sum())
# # 缺失值处理,若存在缺失,采用中位数填充或删除。
# data.fillna(data.median(), inplace=True)
# # 删除重复行
# data.drop_duplicates(inplace=True)
print("数据预览:\n", data.head())
##### 2. 文本预处理
### 标签映射编码:
# 将"好评"映射为1,"差评"映射为0(或其他数值),便于模型计算。
data['标签'] = data['评价'].apply(lambda x: 1 if x == '好评' else 0) # 映射标签
print("标签映射:\n", data.head())
### 文本清洗:
# 去除无关符号(如标点、数字、特殊字符),统一大小写(英文),但中文需保留汉字。
# 保留中文字符、英文字母,将其他字符替换为空格
# 中文字符范围:\u4e00-\u9fff
# 英文字母:a-zA-Z
# 使用re.sub,将不匹配保留字符的任意字符替换为空格
cleaned = data['内容'].apply(lambda x: re.sub(r"[^a-zA-Z\u4e00-\u9fff]", " ", x))
# 将英文字母转为小写
cleaned = cleaned.apply(lambda x: x.lower())
# 合并多个空格为一个空格
cleaned = cleaned.apply(lambda x: re.sub(r"\s+", " ", x).strip())
data['内容'] = cleaned
print("文本清洗:\n", data.head())
### 文本分词:
# 对用户的评论信息,做切词
comment_list = []
for line in data['内容']:
# 对每一行进行切词
result = jieba.lcut(line)
comment_list.append(' '.join(result))
print("文本分词:\n", comment_list)
### 去停用词:加载停用词表,过滤掉"的"、"了"、"是"等无实际意义的词语,减少噪声。
with open('file/stopwords.txt', encoding='utf-8') as f:
stopwords_list = f.readlines() # 逐行读取文件
stopwords_list = [x.strip() for x in stopwords_list] # 去掉换行符
stopwords_list = list(set(stopwords_list)) # 去重
print("停用词:\n", stopwords_list)
### 3.特征提取
# 将分词后的文本转换为数值特征向量,常用方法:
# 词袋模型(CountVectorizer):统计每个词在文档中出现的次数。
# 定义词袋模型吗,创建CountVectorizer对象,参数:停用词列表
transfer = CountVectorizer(stop_words=stopwords_list)
x = transfer.fit_transform(comment_list) # 返回词频矩阵
# print("特征矩阵:\n", x, x.shape) # (13行, 37列)
### 4.数据集划分
# 将数据划分为训练集和测试集(例如80%训练,20%测试)。
x_train, x_test, y_train, y_test = train_test_split(x, data['标签'], train_size=0.8, test_size=0.2, random_state=42)
### 5. 模型选择与训练
# 选择朴素贝叶斯分类器,具体为多项式朴素贝叶斯(MultinomialNB),因为它适合离散计数特征(如词频)。
# 创建贝叶斯对象
bayes = MultinomialNB(alpha=1.0)
# 模型训练
bayes.fit(x_train, y_train)
print("模型训练完成!")
# 模型预测
y_predict = bayes.predict(x_test)
print("预测结果:", y_predict)
print("真实结果:", y_test)
print("准确率:", bayes.score(x_test, y_test))
### 6. 模型评估
# 在测试集上进行预测,
# 输出分类报告(精确率、召回率、F1-score)和混淆矩阵,
# 评估模型对好评和差评的识别能力。
print("分类报告:\n", classification_report(y_test, y_predict))
print("混淆矩阵:\n", confusion_matrix(y_test, y_predict))
print("准确率:", bayes.score(x_test, y_test))
# 测试模型
# 创建测试用例
test_case = ['我非常喜欢这个书,非常推荐给朋友!', '这个书 sucks, 垃圾']
test_case = [' '.join(jieba.lcut(x)) for x in test_case]
test_case = transfer.transform(test_case)
y_predict = bayes.predict(test_case)
print("预测结果:", y_predict)
# 7. 模型调参,意义不大,所以跳过
# 8. 模型保存
pickle.dump(bayes, open('file/商品评论情感分析.pkl', 'wb'))