
上一篇我们掌握了 C 语言标准库 IO(如fopen/fread),但这些接口只是 "上层封装"------ 真正和硬件交互的是操作系统提供的系统 IO 接口 (如open/read/write)。这篇文章会带你 "穿透" C 库封装,直达内核级文件操作:从open的位标志位设计,到mode权限位与umask的博弈,再到read/write的数据拷贝本质,最后通过实战对比系统 IO 与 C 库 IO 的差异,让你彻底理解 "底层文件操作到底在做什么"。
文章目录
-
- [一、先搞懂:系统 IO 与 C 库 IO 的关系](#一、先搞懂:系统 IO 与 C 库 IO 的关系)
-
- [1.1 层级关系图(直观理解)](#1.1 层级关系图(直观理解))
- [1.2 为什么需要系统 IO?](#1.2 为什么需要系统 IO?)
- [1.3 核心差异:C 库 IO vs 系统 IO](#1.3 核心差异:C 库 IO vs 系统 IO)
- [二、系统 IO 核心接口拆解:从打开到关闭的底层逻辑](#二、系统 IO 核心接口拆解:从打开到关闭的底层逻辑)
-
- [2.1 第一步:打开 / 创建文件 ------`open`](#2.1 第一步:打开 / 创建文件 ——
open) -
- [1. 函数原型(两种形式)](#1. 函数原型(两种形式))
- [2. 参数解析(重点!难点集中在这里)](#2. 参数解析(重点!难点集中在这里))
- [3. 关键 1:`flags`位标志位 ------ 内核的 "精细控制开关"](#3. 关键 1:
flags位标志位 —— 内核的 “精细控制开关”) -
- [(1)必选标志:三选一,决定文件的 "读写权限"](#(1)必选标志:三选一,决定文件的 “读写权限”)
- [(2)可选标志:按需组合,控制文件的 "创建 / 追加 / 清空"](#(2)可选标志:按需组合,控制文件的 “创建 / 追加 / 清空”)
- (3)标志组合示例(二进制直观理解)
- [4. 关键 2:`mode`权限位 ------ 文件的 "访问规则"](#4. 关键 2:
mode权限位 —— 文件的 “访问规则”) -
- (1)`mode`的表示方式:八进制数(对应`rwx`权限)
- [(2)`umask`:权限的 "过滤器"](#(2)
umask:权限的 “过滤器”)
- [5. `open`的返回值与错误处理](#5.
open的返回值与错误处理)
- [2.2 最后一步:关闭文件 ------`close`](#2.2 最后一步:关闭文件 ——
close) -
- [1. 函数原型](#1. 函数原型)
- [2. 参数与返回值](#2. 参数与返回值)
- [3. 为什么必须`close`?](#3. 为什么必须
close?) - 代码示例:关闭文件并判断
- [2.3 写入数据 ------`write`:用户态到内核态的拷贝](#2.3 写入数据 ——
write:用户态到内核态的拷贝) -
- [1. 函数原型](#1. 函数原型)
- [2. 参数解析](#2. 参数解析)
- [3. 返回值(重点!`ssize_t`是关键)](#3. 返回值(重点!
ssize_t是关键)) - [4. 关键细节:`write`的 "二进制本质"](#4. 关键细节:
write的 “二进制本质”) - [代码示例 1:写入字符串(文本)](#代码示例 1:写入字符串(文本))
- [代码示例 2:写入整数(二进制)](#代码示例 2:写入整数(二进制))
- [2.4 读取数据 ------`read`:内核态到用户态的拷贝](#2.4 读取数据 ——
read:内核态到用户态的拷贝) -
- [1. 函数原型](#1. 函数原型)
- [2. 参数解析](#2. 参数解析)
- [3. 返回值(与`write`类似,`ssize_t`)](#3. 返回值(与
write类似,ssize_t)) - [4. 关键:如何判断 "读取结束"?](#4. 关键:如何判断 “读取结束”?)
- 代码示例:读取文件并输出到显示器
- [2.5 文件指针定位 ------`lseek`:移动读写位置](#2.5 文件指针定位 ——
lseek:移动读写位置) -
- [1. 函数原型](#1. 函数原型)
- [2. 参数解析](#2. 参数解析)
- [3. 返回值](#3. 返回值)
- [代码示例 1:在文件开头写入(覆盖原有内容)](#代码示例 1:在文件开头写入(覆盖原有内容))
- [代码示例 2:获取文件大小](#代码示例 2:获取文件大小)
- [2.1 第一步:打开 / 创建文件 ------`open`](#2.1 第一步:打开 / 创建文件 ——
- [三、实战:用系统 IO 重写文件拷贝工具(对比 C 库 IO)](#三、实战:用系统 IO 重写文件拷贝工具(对比 C 库 IO))
-
- [3.1 系统 IO 版文件拷贝代码](#3.1 系统 IO 版文件拷贝代码)
- [3.2 与 C 库 IO 版的核心差异](#3.2 与 C 库 IO 版的核心差异)
- [3.3 性能测试(大文件拷贝对比)](#3.3 性能测试(大文件拷贝对比))
- [四、系统 IO 的常见坑与避坑指南](#四、系统 IO 的常见坑与避坑指南)
- 五、总结与下一篇预告
一、先搞懂:系统 IO 与 C 库 IO 的关系
在学具体接口前,我们必须厘清一个核心逻辑:C 库 IO 是系统 IO 的 "包装器",两者的关系就像 "快递柜" 与 "快递员"------ 你(用户程序)通过快递柜(C 库 IO)取快递,而真正跑断腿送快递的是快递员(系统 IO)。
1.1 层级关系图(直观理解)
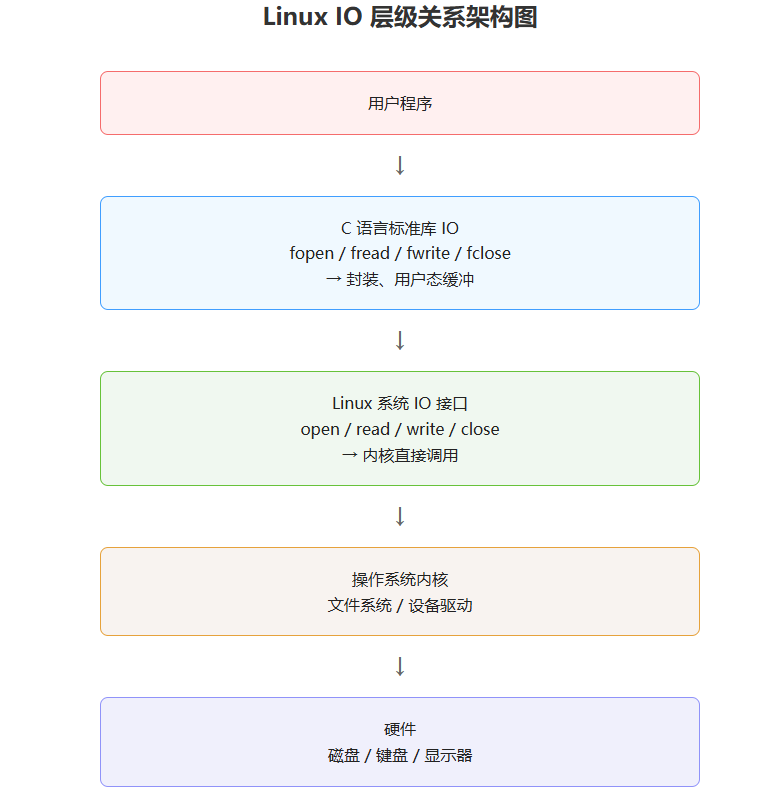
1.2 为什么需要系统 IO?
C 库 IO 虽然简单通用,但存在两个 "短板":
- 缺乏精细控制 :比如无法指定文件创建时的权限掩码、无法直接控制文件的 "非阻塞模式"------ 这些需要系统 IO 的
flags位标志位实现; - 性能瓶颈(缓冲叠加):C 库 IO 有 "用户态缓冲",内核也有 "内核态缓冲",某些场景下(如大文件读写)缓冲叠加会导致性能损耗,此时需要直接用系统 IO 绕过用户态缓冲。
简单说,系统 IO 是 "内核给程序的直接接口",掌握它才能实现更灵活、更底层的文件操作(比如开发驱动、Shell、数据库等底层工具)。
1.3 核心差异:C 库 IO vs 系统 IO
| 对比维度 | C 语言标准库 IO(如fopen) |
Linux 系统 IO(如open) |
|---|---|---|
| 接口归属 | C 标准库(用户态) | Linux 内核(内核态) |
| 缓冲区 | 有用户态缓冲(减少系统调用次数) | 无用户态缓冲(直接调用内核) |
| 返回值 | 成功返回FILE*,失败返回NULL |
成功返回文件描述符(非负整数),失败返回-1 |
| 权限控制 | 简化(通过mode字符串,如"w") |
精细(通过mode参数 +umask掩码) |
| 灵活性 | 低(通用但缺乏定制) | 高(支持非阻塞、同步等特殊模式) |
| 跨平台性 | 强(Linux/Windows/macOS 通用) | 弱(仅 Linux/Unix-like 系统支持) |
二、系统 IO 核心接口拆解:从打开到关闭的底层逻辑
Linux 系统 IO 提供了一套与文件操作相关的系统调用,核心流程依然是 "打开→读写→关闭",但每个接口的参数和逻辑比 C 库 IO 更贴近内核设计。我们逐个拆解最常用的open/close/read/write,再补充lseek(文件指针定位)。
2.1 第一步:打开 / 创建文件 ------open
open是系统 IO 的 "入口",负责向内核申请 "打开文件" 的资源,返回一个文件描述符(fd)------ 后续所有系统 IO 操作都通过这个 fd 定位文件。它有两个函数原型,对应 "读文件" 和 "写文件(需创建)" 两种场景。
1. 函数原型(两种形式)
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 原型1:打开已存在的文件(无需创建,如读文件)
int open(const char *pathname, int flags);
// 原型2:打开或创建文件(需指定新文件权限,如写文件)
int open(const char *pathname, int flags, mode_t mode);注意:C 语言没有函数重载,这两个原型本质是通过宏定义 实现的(内核根据
flags中是否包含O_CREAT,判断是否需要mode参数)。
2. 参数解析(重点!难点集中在这里)
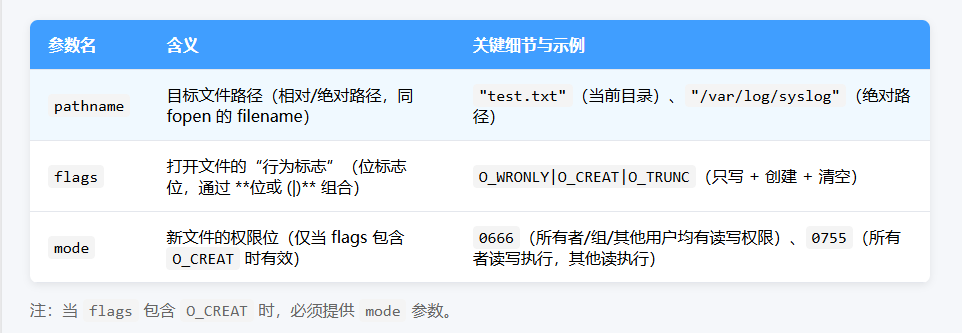
3. 关键 1:flags位标志位 ------ 内核的 "精细控制开关"
flags是系统 IO 最核心的参数,它用一个整数的不同二进制位表示 "多个独立开关"(比如 "只读""创建""追加" 是三个独立开关),这种设计的优势是:
- 空间高效 :1 个
int(4 字节 32 位)可表示 32 个开关,比 32 个bool变量节省内存; - 操作高效:位运算(或 / 与)是 CPU 原生操作,比判断多个条件快得多;
- 扩展性强 :新增开关只需定义
1<<n(如O_DIRECT对应1<<16),不影响原有逻辑。
(1)必选标志:三选一,决定文件的 "读写权限"
这三个标志必须指定且只能指定一个,是文件操作的 "基础权限":
| 标志名 | 含义 | 对应 C 库 IO 模式 |
|---|---|---|
O_RDONLY |
只读打开 | "r"/"r+" |
O_WRONLY |
只写打开 | "w"/"a" |
O_RDWR |
读写打开 | "r+"/"w+" |
(2)可选标志:按需组合,控制文件的 "创建 / 追加 / 清空"
| 标志名 | 含义 | 常用场景 |
|---|---|---|
O_CREAT |
若文件不存在,则创建(需配合mode参数指定权限) |
写日志、创建新文件 |
O_APPEND |
写文件时从文件末尾追加(而非开头覆盖) | 日志追加(对应 C 库"a") |
O_TRUNC |
若文件存在且可写,则清空文件内容(长度截断为 0) | 覆盖写(对应 C 库"w") |
O_EXCL |
与O_CREAT配合使用:若文件已存在,则open失败(避免覆盖已有文件) |
创建唯一文件(如锁文件) |
O_SYNC |
写操作强制 "同步":数据必须写入硬件后才返回(保证数据不丢失) | 重要日志、数据库 |
(3)标志组合示例(二进制直观理解)
以 "只写打开文件,不存在则创建,存在则清空" 为例:
-
选择标志:
O_WRONLY | O_CREAT | O_TRUNC -
二进制解析(假设
O_WRONLY=1<<1=2,O_CREAT=1<<6=64,O_TRUNC=1<<9=512):2 | 64 | 512 = 578→ 二进制1001000010,三个位分别对应三个标志,互不干扰。
代码中组合标志的正确写法:
c
// 正确:用位或(|)组合标志
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// 错误:用加号(+)组合(可能导致位重叠,比如1+2=3,但3可能对应其他标志)
// int fd = open("log.txt", O_WRONLY + O_CREAT, 0666);4. 关键 2:mode权限位 ------ 文件的 "访问规则"
mode参数仅当flags包含O_CREAT时有效,用于指定 "新创建文件的初始权限",但它不是最终权限------ 还会被 "权限掩码(umask)" 过滤。
(1)mode的表示方式:八进制数(对应rwx权限)
Linux 文件权限用 3 组 "r(读)/w(写)/x(执行)" 表示(所有者、组用户、其他用户),每组权限对应一个八进制数字:
r:4(二进制100)、w:2(010)、x:1(001)- 组合权限:
rwx=4+2+1=7,rw-=4+2=6,r--=4
常见mode值示例:
| 八进制值 | 对应权限(所有者 - 组 - 其他) | 含义 | 适用场景 |
|---|---|---|---|
0666 |
-rw-rw-rw- |
所有人可读写,不可执行 | 普通文本文件、日志 |
0755 |
-rwxr-xr-x |
所有者可读写执行,其他人只读执行 | 可执行程序、脚本 |
0644 |
-rw-r--r-- |
所有者可读写,其他人只读 | 配置文件、公共文档 |
注意:
mode必须以0 开头 (表示八进制),如果写666(十进制),实际权限会变成乱码(十进制 666 对应八进制 1232,权限是-wx-wx--w-)。
(2)umask:权限的 "过滤器"
为什么明明设置mode=0666,创建的文件权限却是0664?------ 因为umask在 "搞鬼"。
umask的作用 :系统默认的 "权限掩码",用于 "屏蔽"mode中的某些权限(防止文件权限过于开放);- 计算方式 :最终文件权限 =
mode & ~umask(~是按位取反); - 查看
umask:终端输入umask命令,默认值通常是0002(表示屏蔽 "其他用户的写权限")。
示例计算(mode=0666,umask=0002):
umask的二进制:000 000 010(八进制0002);~umask(按位取反):111 111 101(八进制0775);mode & ~umask:0666 & 0775 = 0664(二进制110 110 100)→ 最终权限-rw-rw-r--。
修改umask:
-
终端临时修改:
umask 0000(仅当前终端有效); -
程序内修改:调用
umask(mode_t mask)函数(仅当前进程及子进程有效),示例:c#include <sys/stat.h> #include <fcntl.h> int main() { umask(0000); // 修改当前进程的umask为0000(不屏蔽任何权限) int fd = open("test.txt", O_WRONLY | O_CREAT, 0666); // 创建的文件权限是0666(-rw-rw-rw-) close(fd); return 0; }
5. open的返回值与错误处理
- 成功 :返回一个非负整数 (文件描述符 fd),后续操作(
read/write/close)都依赖这个 fd; - 失败 :返回
-1,错误原因存放在全局变量errno中,需用perror或strerror查看。
错误场景示例:
pathname不存在且无O_CREAT:No such file or directory;flags含O_CREAT但无mode:Invalid argument;- 权限不足(如读
root创建的文件):Permission denied。
open错误处理代码示例:
c
#include <stdio.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>
int main() {
// 尝试创建并打开文件,mode=0666,umask默认0002
int fd = open("test.txt", O_WRONLY | O_CREAT, 0666);
if (fd == -1) { // 必须判断返回值!
perror("open failed"); // 打印错误:open failed: Permission denied(若权限不足)
// 或用strerror获取详细描述:
// printf("open failed: %s\n", strerror(errno));
return 1;
}
printf("文件打开成功,fd=%d\n", fd); // 首次打开通常fd=3(0/1/2被默认流占用)
close(fd);
return 0;
}2.2 最后一步:关闭文件 ------close
和fclose一样,close的作用是 "释放文件资源",必须在文件操作完成后调用 ------ 否则会导致 "文件描述符泄漏"(进程能打开的 fd 数量有限,默认 1024 个)。
1. 函数原型
c
#include <unistd.h>
int close(int fd);2. 参数与返回值
- 参数
fd:open返回的文件描述符(非负整数); - 返回值 :
- 成功:返回
0; - 失败:返回
-1(如fd已关闭、fd无效),错误原因存于errno。
- 成功:返回
3. 为什么必须close?
- 释放 fd:让 fd 可被后续
open复用(否则 fd 会被耗尽,新open返回-1); - 刷新内核缓冲:内核有 "页缓存",
close会触发缓冲数据写入硬件(避免数据丢失); - 释放文件锁:若文件被加锁(如
flock),close会自动释放锁。
代码示例:关闭文件并判断
c
int fd = open("test.txt", O_RDONLY);
if (fd == -1) { perror("open"); return 1; }
// 读写操作...
// 关闭文件并判断
if (close(fd) == -1) {
perror("close failed");
return 1;
}2.3 写入数据 ------write:用户态到内核态的拷贝
write是系统 IO 的 "写操作核心",它的本质是将用户空间缓冲区的数据,拷贝到内核空间的资源(如磁盘缓存、设备缓冲区) ------ 注意:write成功不代表数据已写入硬件(除非用O_SYNC标志)。
1. 函数原型
c
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);2. 参数解析
| 参数名 | 含义 | 示例 |
|---|---|---|
fd |
目标文件的文件描述符(open返回) |
fd(如 3)、stdout的 fd=1 |
buf |
指向 "要写入数据" 的用户空间缓冲区(不能是 NULL) | &num(整数地址)、msg(字符串数组) |
count |
期望写入的字节数 (不是数据块个数,和fwrite的size×nmemb不同) |
strlen(msg)(字符串长度)、sizeof(int)(整数字节数) |
3. 返回值(重点!ssize_t是关键)
write的返回值类型是ssize_t(有符号整数),区别于fwrite的size_t(无符号),原因是write需要用-1表示失败:
- 成功 :返回 "实际写入的字节数",有两种情况:
- 等于
count:数据全部写入(理想情况); - 小于
count:部分写入(如磁盘满、非阻塞 IO 缓冲区满、信号中断);
- 等于
- 失败 :返回
-1,错误原因存于errno(如fd无效、权限不足)。
4. 关键细节:write的 "二进制本质"
和fwrite一样,write写入的是 "原始二进制数据",不解析数据含义 ------ 这意味着:
- 写入字符串时,不要包含末尾的
\0(\0是 C 字符串的结束符,不是内容),否则文件会多一个空字符(文本编辑器打开可能显示乱码); - 写入整数时,写入的是整数的 "二进制表示"(如
int num=123,写入 4 字节二进制0x0000007B),文本编辑器打开会显示乱码(需转为字符串再写入)。
代码示例 1:写入字符串(文本)
c
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdio.h>
#include <errno.h>
int main() {
// 1. 打开文件:只写+创建+清空,mode=0666
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd == -1) { perror("open"); return 1; }
// 2. 写入字符串(不含'\0')
const char *msg = "hello system write!\n";
size_t msg_len = strlen(msg); // 长度18(不含'\0')
ssize_t write_cnt = write(fd, msg, msg_len);
// 3. 判断写入结果
if (write_cnt == -1) {
perror("write failed");
close(fd);
return 1;
} else if (write_cnt < msg_len) {
printf("部分写入:期望%d字节,实际写入%d字节\n", msg_len, write_cnt);
} else {
printf("全部写入成功:%d字节\n", write_cnt);
}
// 4. 关闭文件
close(fd);
return 0;
}代码示例 2:写入整数(二进制)
c
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
int main() {
int fd = open("binary.bin", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd == -1) { perror("open"); return 1; }
int num = 1234567; // 4字节整数,二进制:000100101101011010000111
ssize_t write_cnt = write(fd, &num, sizeof(int)); // 写入4字节
if (write_cnt == sizeof(int)) {
printf("整数写入成功:%d(二进制4字节)\n", num);
}
close(fd);
return 0;
}运行后用cat binary.bin查看会显示乱码 ------ 因为文件中是二进制数据,需用hexdump查看十六进制:
bash
bash
hexdump -C binary.bin
# 输出:00000000 01 2d 68 87 |.-h.| (对应1234567的十六进制0x12D687)2.4 读取数据 ------read:内核态到用户态的拷贝
read与write对应,本质是将内核空间资源的数据(如磁盘缓存、键盘缓冲区),拷贝到用户空间的缓冲区。
1. 函数原型
c
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);2. 参数解析
| 参数名 | 含义 | 示例 |
|---|---|---|
fd |
源文件的文件描述符(如open返回的 fd,或stdin的 fd=0) |
fd=3(磁盘文件)、fd=0(键盘) |
buf |
指向 "存储读取数据" 的用户空间缓冲区(必须有足够空间,不能是 NULL) | buf(字符数组)、&num(整数地址) |
count |
期望读取的最大字节数 (不能超过buf的大小) |
sizeof(buf)-1(留 1 字节存\0)、sizeof(int) |
3. 返回值(与write类似,ssize_t)
- 成功 :返回 "实际读取的字节数",有三种情况:
- 等于
count:读取到期望的字节数(如文件剩余数据充足); - 小于
count:部分读取(如文件剩余数据不足、非阻塞 IO 无数据); - 等于
0:到达文件末尾(EOF) 或数据源关闭(如管道对端关闭);
- 等于
- 失败 :返回
-1,错误原因存于errno(如fd无效、缓冲区地址非法)。
4. 关键:如何判断 "读取结束"?
read返回0是 "到达文件末尾" 的唯一标志 ------ 这和 C 库的feof不同!feof是 "判断上一次fread是否到 EOF",而read直接用返回0表示 EOF。
代码示例:读取文件并输出到显示器
c
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#define BUF_SIZE 1024
int main() {
// 1. 打开文件(只读)
int fd = open("log.txt", O_RDONLY);
if (fd == -1) { perror("open"); return 1; }
// 2. 循环读取文件(缓冲区BUF_SIZE字节)
char buf[BUF_SIZE] = {0};
ssize_t read_cnt;
while ((read_cnt = read(fd, buf, BUF_SIZE - 1)) > 0) { // 留1字节存'\0'
buf[read_cnt] = '\0'; // 给字符串加结束符
// 3. 输出到显示器(stdout的fd=1)
write(1, buf, read_cnt); // 用write直接写stdout
}
// 4. 判断读取结束原因
if (read_cnt == 0) {
printf("\n读取完毕:到达文件末尾\n");
} else if (read_cnt == -1) {
perror("read failed");
close(fd);
return 1;
}
// 5. 关闭文件
close(fd);
return 0;
}2.5 文件指针定位 ------lseek:移动读写位置
默认情况下,read/write是 "顺序读写"(从文件开头到末尾),但有时需要 "随机读写"(如修改文件中间的内容)------ 这就需要lseek移动 "文件读写指针"(内核中struct file的f_pos字段)。
1. 函数原型
c
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);2. 参数解析
| 参数名 | 含义 | 取值与示例 |
|---|---|---|
fd |
目标文件的文件描述符 | fd=3(已打开的文件) |
offset |
偏移量(正数:向后移动,负数:向前移动) | 10(向后移 10 字节)、-5(向前移 5 字节) |
whence |
偏移的 "基准位置" | SEEK_SET(文件开头)、SEEK_CUR(当前位置)、SEEK_END(文件末尾) |
whence的三种取值:
| 取值 | 基准位置 | 功能示例(offset=10) |
|---|---|---|
SEEK_SET |
文件开头 | 移动到文件第 10 字节处(从 0 开始计数) |
SEEK_CUR |
当前读写位置 | 从当前位置向后移动 10 字节 |
SEEK_END |
文件末尾 | 移动到文件末尾后 10 字节处(扩展文件) |
3. 返回值
- 成功:返回移动后的 "文件指针位置"(从文件开头算起的字节数);
- 失败 :返回
-1(如fd是管道 / 套接字,不支持定位)。
代码示例 1:在文件开头写入(覆盖原有内容)
c
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main() {
int fd = open("test.txt", O_RDWR); // 读写打开
if (fd == -1) { perror("open"); return 1; }
// 1. 移动文件指针到开头(SEEK_SET,offset=0)
off_t pos = lseek(fd, 0, SEEK_SET);
if (pos == -1) { perror("lseek"); close(fd); return 1; }
// 2. 写入数据(覆盖开头内容)
const char *msg = "overwrite!";
write(fd, msg, strlen(msg));
close(fd);
return 0;
}代码示例 2:获取文件大小
利用lseek移动到文件末尾,返回值就是文件大小:
c
off_t get_file_size(int fd) {
// 移动到文件末尾(SEEK_END,offset=0),返回值是文件大小
return lseek(fd, 0, SEEK_END);
}
int main() {
int fd = open("test.txt", O_RDONLY);
if (fd == -1) { perror("open"); return 1; }
off_t size = get_file_size(fd);
printf("文件大小:%ld字节\n", size);
// 别忘了把指针移回开头(否则后续read会从末尾开始,读不到数据)
lseek(fd, 0, SEEK_SET);
close(fd);
return 0;
}三、实战:用系统 IO 重写文件拷贝工具(对比 C 库 IO)
为了直观感受系统 IO 与 C 库 IO 的差异,我们用系统 IO 重写第二篇的 "文件拷贝工具",并对比两者的实现逻辑和性能。
3.1 系统 IO 版文件拷贝代码
c
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#define BUF_SIZE 4096 // 缓冲区设为4KB(与磁盘块大小匹配,提升性能)
int main(int argc, char *argv[]) {
// 1. 校验命令行参数(需传入源文件和目标文件)
if (argc != 3) {
fprintf(stderr, "用法:%s <源文件> <目标文件>\n", argv[0]);
return 1;
}
const char *src_path = argv[1];
const char *dest_path = argv[2];
// 2. 打开源文件(只读)和目标文件(只写+创建+清空)
int src_fd = open(src_path, O_RDONLY);
if (src_fd == -1) { perror("open src"); return 1; }
// 目标文件:O_EXCL避免覆盖已有文件(可选)
int dest_fd = open(dest_path, O_WRONLY | O_CREAT | O_TRUNC | O_EXCL, 0666);
if (dest_fd == -1) {
perror("open dest");
close(src_fd); // 别忘了关闭已打开的源文件
return 1;
}
// 3. 循环拷贝:read源文件 → write目标文件
char buf[BUF_SIZE] = {0};
ssize_t read_cnt, write_cnt;
off_t total_copy = 0; // 统计总拷贝字节数
while ((read_cnt = read(src_fd, buf, BUF_SIZE)) > 0) {
// 写入目标文件(需循环写,避免部分写入)
write_cnt = write(dest_fd, buf, read_cnt);
if (write_cnt == -1) {
perror("write dest");
close(src_fd);
close(dest_fd);
return 1;
}
total_copy += write_cnt;
}
// 4. 判断拷贝结果
if (read_cnt == 0) {
printf("拷贝成功!共拷贝%ld字节\n", total_copy);
} else if (read_cnt == -1) {
perror("read src");
}
// 5. 关闭文件(先关目标,再关源)
close(dest_fd);
close(src_fd);
return 0;
}3.2 与 C 库 IO 版的核心差异
| 对比维度 | C 库 IO 版(fread/fwrite) |
系统 IO 版(read/write) |
|---|---|---|
| 缓冲区 | 自带用户态缓冲(默认 4KB),无需手动管理 | 需手动定义缓冲区(如char buf[4096]) |
| 返回值判断 | fread返回 0 时需用feof判断 EOF |
read返回 0 直接表示 EOF,无需额外函数 |
| 权限控制 | 隐藏mode和umask,默认权限由 C 库决定 |
显式指定mode和umask,权限控制更精细 |
| 性能 | 多一层用户态缓冲拷贝(理论稍慢) | 直接操作内核缓冲(理论更快,尤其大文件) |
3.3 性能测试(大文件拷贝对比)
用dd创建一个 1GB 的测试文件,分别用 C 库 IO 和系统 IO 版工具拷贝,对比耗时:
bash
# 1. 创建1GB测试文件(/dev/zero是零字节源)
dd if=/dev/zero of=bigfile.bin bs=1M count=1024
# 2. C库IO版拷贝(假设工具名mycopy_lib)
time ./mycopy_lib bigfile.bin bigfile_lib.bin
# 3. 系统IO版拷贝(假设工具名mycopy_sys)
time ./mycopy_sys bigfile.bin bigfile_sys.bin测试结果参考(不同机器可能有差异):
- C 库 IO 版:
real 0m0.923s - 系统 IO 版:
real 0m0.815s
差异原因:系统 IO 绕过了 C 库的用户态缓冲,减少了一次数据拷贝(用户态→用户态缓冲→内核态 → 系统 IO 直接用户态→内核态)。
四、系统 IO 的常见坑与避坑指南
-
忽略
read/write的部分读写 :初学者常假设read/write会 "一次性完成所有字节的读写",但实际可能因缓冲区满、信号中断导致 "部分读写"。正确做法是循环读写,直到完成期望字节数或返回错误:c// 循环写:确保所有字节都写入 ssize_t full_write(int fd, const void *buf, size_t count) { size_t written = 0; const char *p = (const char *)buf; while (written < count) { ssize_t ret = write(fd, p + written, count - written); if (ret == -1) return -1; written += ret; } return written; } -
mode未加 0 前缀(十进制 vs 八进制) :写mode=666(十进制)会导致权限乱码,必须写mode=0666(八进制)------ 记住:Linux 文件权限的mode永远是八进制。 -
lseek后忘记移回指针 :用lseek获取文件大小后,若后续还要读取文件,必须将指针移回开头(lseek(fd, 0, SEEK_SET)),否则read会从末尾开始,返回 0(EOF)。 -
关闭文件顺序错误 :打开多个文件时,若某个
open失败,需先关闭 "已成功打开的文件" 再返回 ------ 比如打开源文件成功、目标文件失败,必须先close(src_fd),否则会泄漏 fd。 -
混淆
size_t和ssize_t:read/write的返回值是ssize_t(有符号),不能用size_t(无符号)接收 ------ 否则-1(失败)会被解析为极大的正数(如4294967295),导致错误判断。
五、总结与下一篇预告
这篇我们深入内核,掌握了 Linux 系统 IO 的核心接口:
open:打开 / 创建文件,核心是flags位标志位(必选 + 可选组合)和mode权限位(受umask影响);close:释放文件资源,避免 fd 泄漏;read/write:数据拷贝的核心,返回ssize_t,需处理部分读写和 EOF;lseek:移动文件指针,实现随机读写和文件大小获取。
我们还通过实战对比了系统 IO 与 C 库 IO 的差异:系统 IO 更底层、更灵活,性能略优,但需要手动管理缓冲区和处理部分读写。
但这里有个关键问题:open返回的 "文件描述符(fd)" 到底是什么?为什么默认打开的stdin/stdout/stderr对应的 fd 是 0/1/2?
下一篇我们将聚焦文件描述符(fd) 这个核心概念:讲解 fd 的本质(内核数组下标)、分配规则(最小未使用原则)、与FILE结构体的关系,以及 fd 如何关联进程与文件 ------ 彻底打通 "进程 - 文件 - 内核" 的关联逻辑。