安装
ubutun的MySQL安装
shell
# 更新软件包列表并升级已安装的软件包
sudo apt update && sudo apt upgrade
# 清理系统中已删除软件包的残留配置文件
dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P
# 安装 MySQL 服务器
sudo apt install mysql-server
# 以 root 用户身份登录 MySQL
mysql -uroot -pwindows安装
- 网站:dev.mysql.com/downloads/m...
- 你需要下载压缩包版本,解压后放到你想放的位置,进入解压后的文件夹建立
mysql.ini文件。文件输入以下内容:
shell
[mysqld]
# 设置MySQL安装目录(替换为你的解压路径)
basedir=D:\Users\wnan\AppData\Local\mysql-8.0.44-winx64
# 设置MySQL数据存储目录(自动生成,无需手动创建)
datadir=D:\Users\wnan\AppData\Local\mysql-8.0.44-winx64\data
# 设置端口号(默认3306,若被占用可修改为3307等)
port=3306
# 设置字符集(默认UTF-8,支持中文)
character-set-server=utf8mb4
# 设置默认存储引擎
default-storage-engine=INNODB
# 允许最大连接数
max_connections=100
[mysql]
# MySQL客户端字符集
default-character-set=utf8mb4
[client]
# 客户端连接端口
port=3306
# 客户端字符集
default-character-set=utf8mb4- 设置环境变量:
D:\Users\wnan\AppData\Local\mysql-8.0.44-winx64\bin - 打开poershell,这里需要管理员权限的方式打开。执行指令:
shell
# 初始化
mysqld --initialize --console
# 窗口会输出一串日志,找到 root@localhost: 后面的字符串(例如:root@localhost:abcd1234!),这是 临时密码,复制保存(后续登录需要);
# 注册安装MySQL服务
mysqld -install
# 输出:Service successfully installed. 就表示成功用户管理
用户建立、授权、收权、删除
- 建立用户
sql
-- 建立用户
create user '[用户的名字]'@'[设备的IP地址]' identified by '[用户的登录密码]';
-- 查看权限
show grants for '[用户的名字]'@'[设备的IP地址]';设备的IP地址:
%表示任意IP均可以登录;localhost表示本地登录。
- 授权
sql
-- 授予所有权限
grant all privileges on testDB.* to '[用户的名字]'@'[设备的IP地址]' identified by '[用户的登录密码]';
-- 查看权限
show grants for '[用户的名字]'@'[设备的IP地址]';
-- 刷新系统
flush privileges;在
grant语句中,testDB.*指的是数据库testDB中的所有表。这里的星号(*)作为一个通配符,代表数据库中的所有表。具体来说:testDB是数据库的名称。.是点操作符,用于指定数据库层级。*代表所有表。因此,当您看到grant语句中的on testDB.* to时,它意味着授予用户对testDB数据库中所有表的指定权限。这是一种简洁的方式来一次性授予对多个表的操作权限,而不是单独为每个表列出权限。
可能错误
sql
mysql> revoke all on bbs.* from 'admin1'@'localhost';
ERROR 1044 (42000): Access denied for user 'root'@'%' to database 'bbs'
-- 1044提示root访问bbs库被拒绝
mysql> grant all privileges on bbs.* to 'root'@'%';
ERROR 1044 (42000): Access denied for user 'root'@'%' to database 'bbs'
mysql> grant all on *.* to 'root'@'%';
ERROR 1045 (28000): Access denied for user 'root'@'%' (using password: YES)
-- 1045提示root访问被拒绝
sql
-- 查看用户权限
select user,host from mysql.user;
select host,user,Grant_priv,Super_priv from mysql.user;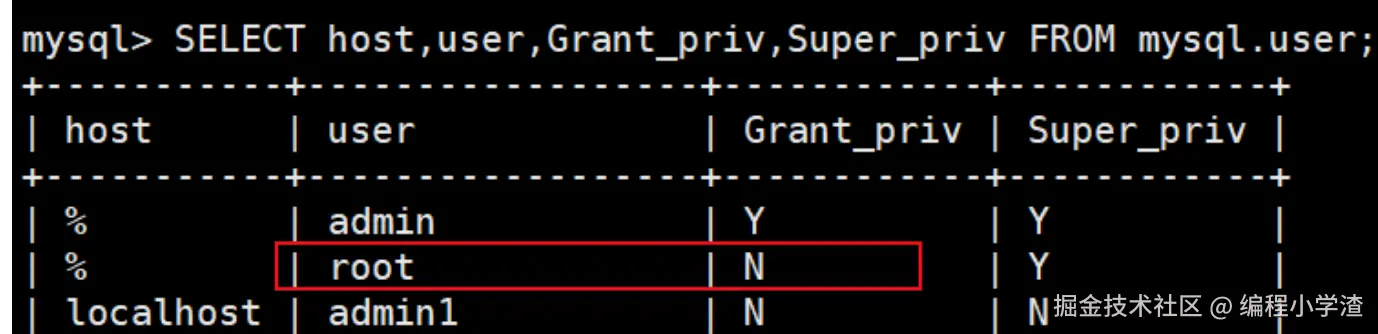
可以看到Grant_priv是N。很显然,因为root@'%'这个用户没有授予权限的权限,所以之前的操作报错。修改一下Grant_priv的值为Y,刷新下,然后退出重新登录。问题就解决了。
sql
update mysql.user set Grant_priv='Y' where user='root';
flush privileges;- 移除权限
sql
-- 移除全部权限
revoke all privileges on *.* from '[用户的名字]'@'[设备的IP地址]';
flush privileges;- 删除用户
sql
use mysql;
drop user '[用户的名字]'@'[设备的IP地址]';远程登录
- MySQL8及以上版本
sql
-- 创建'root'@'%'账户
create user 'root'@'%' identified by '[用户登录密码]';
-- 给'root'@'%'账户设置权限
grant all privileges on *.* to 'root'@'%';
-- 刷新权限
flush privileges;
-- 查看root
use mysql;
select host, user, authentication_string, plugin from user;应该可以看到有两个root账户,一个是'root'@'localhost'和'root'@'%'。看一下两个账号的加密插件是不是caching_sha2_password,为什么要看呢?具体原因往下看。 这次应该可以正常连接了。如果连接的时候显示plugin caching_sha2_password could not be loaded,那我们就需要改一下加密插件了。 方法一: 这种方法应当在创建'root'@'%'之前设置,不然就使用第二种更加方便。 可以理解为,方法一是为之后所有新用户指定加密插件。 方法二是修改指定一个用户的加密插件。
修改my.ini文件。
shell
[mysqld]
default_authentication_plugin=mysql_native_password方法二:
sql
alter user 'root'@'%' identified with mysql_native_password by '123456'服务器没有开放端口
shell
netstat -an | grep 3306
# 如果没有如下信息,则不是任意IP可访问
tcp6 0 0 :::3306 :::* LISTEN
vim /etc/mysql/mysql.conf.d/mysqld.cnf
# 修改,注释 bind-address = 127.0.0.1
# ---------------以下是文件截图----------------
# Instead of skip-networking the default is now to listen only on
# localhost which is more compatible and is not less secure.
# bind-address = 127.0.0.1
mysqlx-bind-address = 127.0.0.1
# -------------------------------------------
# 重启mysql
/etc/init.d/mysql restart数据库操作
建立数据库
sql
create database if not exists [数据库名称];
-- 设置字符集和排序规则【建立数据库时】
create database if not exists [数据库名称] character set 'utf8mb4' collate utf8mb4_unicode_ci;
-- 设置字符集和排序规则【建立数据库后修改】
alter database [数据库名称] character set 'utf8mb4' collate utf8mb4_unicode_ci;
utf8mb4:平时的utf8字符集。
utf8mb4_unicode_ci:不区分大小写排序规则。
删除数据库
sql
drop database if exists [数据库名称];查看数据库是否存在
sql
select schema_name
from information_schema.schemata
where schema_name='[数据库名称]';表操作
建立表
sql
create table if not exists 表名(
列名1 数据类型 [约束条件],
列名2 数据类型 [约束条件],
... [表级约束]
) [表选项];| 约束条件 | 解释 |
|---|---|
| default null | 默认字段为空 |
| not null | 字段非空 |
| comment '对字段的标记注释' | 对字段的标记注释 |
| unique | 确保修饰列的所有值是唯一的 |
| auto_increment | 设置字段自增 |
| 表级约束 | 解释 |
|---|---|
| primary key(主键字段名称1,主键字段名称2,...) | 设置表的主键 |
| constraint 外键约束名称 foreign key (当前表的字段名1,当前表的字段名2,...) references 被参照的外表名称(外表的字段名称1,外表的字段名称2,...) | 设置外键参照 |
| index 索引名称(表字段名称1,表字段名称2,...) | 复合索引 |
| unique index 唯一索引名称(表字段名称1,表字段名称2,...) | 唯一索引 |
| 表选项 | 解释 |
|---|---|
| engine=InnoDB | 设置存储引擎 |
default charset= |
字符集 |
collate= |
排序规则 |
建立临时表
sql
create temporary table 临时表名(
列名1 数据类型 ,
列名2 数据类型 ,
...
);
-- 或
create temporary table 临时表名 as sql_语句;删除表
sql
drop table 表名称;修改表名
sql
rename table 当前表名字 to 需要改为的表名字;清空表数据,但是不删除表
sql
truncate table 表名字;表是否存在
sql
show tables like '表名字';
-- 模糊查询级联删除
sql
drop table 表名字 cascade;
-- 会删除与表有关联得其他表和数据添加列名
sql
alter table 表名字 add 字段名字 字段类型 remark;删除列
sql
alter table 表名字 drop column 表字段名字;重命名列
sql
alter table 表名字 change 当前表字段名字 新的字段名字;修改列的数据类型
sql
alter table 表名字 modify column 表字段名字 新的字段类型 字段的定义;
-- 如果字段有唯一性约束,可能会无法执行表约束
添加约束
sql
alter table 表名字 add [constraint 约束的名字] 约束的定义;
-- 添加外键约束
alter table 表名字
add constraint 约束的名字
foreign key (表字段的名字1,表字段的名字2,...) references 外部表的名字(外部表的字段名字1,外部表的字段名字2,...);
-- 添加主键约束
alter table 表名 add primary key (表字段的名字);修改约束
sql
-- 先删除约束,再添加约束删除约束
sql
alter table 表名字 drop 约束描述;表信息
显示表信息
sql
desc 表名字;
-- 或
describe 表名字;查看表列信息
sql
show columns from 表名字;
-- 或
select *
from information_schema.columns
where table_name='表名字' and table_schema='数据库名字';查看表索引信息
sql
show indexes from 表名字;
-- 或
select *
from information_schema.statistics
where table_name='表名字' and table_schema='数据库名字';查看表约束信息
sql
select *
from information_schema.table_constraints
where table_name='表名字' and table_schema='数据库名字';查看表外键约束信息
sql
select *
from information_schema.key_column_usage
where table_name='表名字' and table_schema='数据库名字';查看建表SQL
sql
show create table 表名字;单元格操作
添加
添加一行数据
sql
insert into 表名(表字段名1,表字段名2,...) value ('val1','val2',...);添加多行数据
sql
insert into 表名字(表字段名1,表字段名2,...) values
('val1_0','val2_0',...),
('val1_1','val2_2',...),
('...','...',...);删除
删除行
sql
delete from 表名字 where 字段名字='delete_condition',...;模糊删除
sql
delete from 表名字 where 字段名字 like '%delete_condition%',...;修改
sql
update 表名字
set 字段名字1='new_data1',
set 字段名字1='new_data2',...
where 更新数据的条件;查询
查询全部数据
sql
select * from 表名字;条件查询
sql
select 字段名字1,字段名字2,...
from 表名字
where 字段名字1='select_condition' [and|or] ...;模糊查询
sql
select 字段名字1,字段名字2,...
from 表名字
where 字段名字1 like '%select_condition%' [and|or]...;
- % 零个或者多个字符
- _ 单个占位符
排序查询
sql
select 字段名字1,字段名字2,...
from 表名字
order by 字段名字1 [asc|desc],字段名字2 [asc|desc],... ;
- asc:升序
- desc:降序
- order by field_name1:这里的field_name1可以设置为数字,数字表示字段的位置顺序
限制返回数查询
sql
-- 指定查询数量
select 字段名字1,字段名字2,...
from 表名字
limit number;
-- number:返回数量
-- 指定查询位置和数量
select 字段名字1,字段名字2,...
from 表名字
limit number offset row_index;
-- number:返回数量
-- row_index:开始行的索引,分组查询
sql
select 字段名字,count(字段名字)
from 表名字
GROUP BY 字段名字 [WITH rollup];
-- ----------------------- +
2024-01-24 1
2024-02-24 1
2024-10-24 2
2024-11-24 4
2024-11-25 2
null 10 -- [WITH rollup] 上面的总和
-- ------------------------+union查询
sql
-- 会把数据叠成一个表,去掉重复
select 字段名字1,字段名字2,...
from 表名字1;
union [all] -- 有all就是不去掉重复
select 字段名字1,字段名字2,...
from 表名字2;连接查询:选中指定的列,两个表进行拼接
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。保留两个表都有的数据
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。保留左表全部数据
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。保留右表全部数据
内连接查询
sql
select 字段名字1,...
from 表名字1
inner join 表名字2 on 表名字1.字段名字 = 表名字2.字段名字;左连接查询
sql
select 字段名字1,...
from 表名字1
left join 表名字2 on 表名字1.字段名字 = 表名字2.字段名字;右连接查询
sql
select 字段名字1,...
from 表名字1
right join 表名字2 on 表名字1.字段名字 = 表名字2.字段名字;比较运算符
SELECT 语句中的条件语句经常要使用比较运算符。通过这些比较运算符,可以判断表中的哪些记录是符合条件的。比较结果为真,则返回 1,为假则返回 0,比较结果不确定则返回 NULL。
| 符号 | 描述 | 备注 |
|---|---|---|
| = | 等于 | |
| <>, != | 不等于 | |
| 大于 | ||
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| BETWEEN | 在两值之间 | between var1 and var2 |
| NOT BETWEEN | 不在两值之间 | |
| IN | 在集合中 | |
| NOT IN | 不在集合中 | |
| <=> | 严格比较两个NULL值是否相等 | 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| LIKE | 模糊匹配 | |
| REGEXP 或 RLIKE | 正则式匹配 | rlike pattern; |
| IS NULL | 为空 | |
| IS NOT NULL | 不为空 | |
| having | 过滤 | having 过滤条件【通常与select后的函数一起使用】; 在数据分组后用于过滤分组的结果 |
| where | 过滤 | where 过滤条件; 在数据分组前用于过滤分组的结果 |
数据导出和导入
导出为sql语句到文件
sql
mysqldump -u 用户名字 -p 数据库名字 > output_file_path.sql查询结果输出到文件
sql
select * from 表名字 into outfile './user_table.txt';
-- 大概率会失败,显示没有权限导入sql文件
sql
mysqldump -u 用户名字 -p 数据库名字 < input_file_path.sql事务
开启事务-显示
sql
begin;
-- or
start transaction;提交事务
sql
commit;
-- or
commit work;事务回滚【会结束事务】
sql
rollback;
-- or
rollback work;
-- 回滚到事务设置的保存点
rollback to savepoint save_rollback_point;设置事务回滚点
sql
savepoint save_rollback_point;查看当前事务状态
sql
show engine innodb status;锁定表进行事务操作
sql
lock tables table_name write;
-- or
lock tables table_name read;释放锁定的表
sql
unlock tables;一些奇奇怪怪的命令
查看当前用户
sql
select user();退出mysql
sql
exit;刷新权限
sql
flush privileges;索引
索引分类
- 主键索引(Primary Key)
- 每个表只能有一个主键索引。
- 主键索引确保了每条记录的唯一性,并且不允许NULL值。
- 它通常是聚簇索引(Clustered Index),意味着数据行本身按照主键的顺序存储。
- 唯一索引(Unique Index)
- 确保索引列中的所有值都是唯一的,但允许存在一个或多个NULL值(取决于存储引擎)。
- 可以在一个表上创建多个唯一索引。
- 普通索引(Index/Secondary Index)
- 这是最基本的索引类型,可以创建在单个或多个列上。
- 不强制值的唯一性,也不限制NULL值的存在。
- 用于加速WHERE子句、ORDER BY、GROUP BY等操作。
- 全文索引(Fulltext Index)
- 专门用于全文搜索,适用于
TEXT、CHAR、VARCHAR类型的列。 - 允许对文本内容进行复杂的搜索,如自然语言搜索、布尔搜索等。
- 在处理大量文本数据时非常有用。
- 专门用于全文搜索,适用于
索引失效
- 使用函数或表达式操作索引列:当对索引列应用函数、进行计算或转换时,索引通常会失效。
sql
-- YEAR(hire_date) 会导致索引失效。
SELECT * FROM 表名字 WHERE YEAR(字段名字) = 2023;- 类型不匹配:如果索引列的数据类型与查询条件中的数据类型不匹配,可能会导致索引失效。例如,索引列是
VARCHAR类型,但查询条件中使用了整数:
sql
select * from 表名字 where 字段名字 = 12345;应确保类型匹配:
sql
select * from 表名字 where 字段名字 = '12345';- 使用
!=或<>:对于不等于的比较(如!=或<>),MySQL可能无法有效利用索引,特别是当涉及大量数据时。 like语句开头使用通配符:如果like语句的第一个字符是通配符(如%或_),则索引将不会被使用:
sql
SELECT * FROM 表名字 WHERE 字段名字 LIKE '%smith';但如果通配符不在第一个位置,则索引仍然可以被使用:
sql
SELECT * FROM 表名字 WHERE 字段名字 LIKE 'smith%';- 使用
OR条件:如果OR连接的条件不是全部都是索引列,那么整个OR条件下的索引可能会失效。
sql
SELECT * FROM 表名字 WHERE 字段名字1 = 'value' OR 字段名字2 = 'value';索引语法
建立索引是都指定索引名
- 建表时建立索引:看建表部分
- 建立普通索引
sql
create index 索引名字
on 表名字(字段名字1,字段名字2,...);- 建立唯一索引
sql
create unique index 索引名字
on 表名字(字段名字1,字段名字2,...);- 建立全文索引
sql
create fulltext index 索引名字
on 表名字(字段名字)
character set character_set_name;- 修改索引:删除索引再添加索引
- 删除索引
sql
alter table 表名字 drop index 索引名字;SQL调优
SQL调优是一个系统性工程,涉及索引优化、查询语句重写、表结构设计以及数据库配置等多个层面。以下是结合两者特性的核心SQL调优方法:
索引优化(最核心的手段)
索引是提升查询速度最直接的方法,但滥用索引会降低写入性能。
- 遵循最左前缀原则 (Leftmost Prefix)
- 原理:对于联合索引
(a, b, c),查询条件必须从a开始匹配,否则索引失效。 - 注意:在联合索引中,如果中间列使用了范围查询(
>,<,between),后续列的索引将失效。
- 原理:对于联合索引
- 避免索引失效的场景
- 函数操作:不要在索引列上使用函数或计算。
- ❌
WHERE YEAR(create_time) = 2026 - ✅
WHERE create_time >= '2026-01-01' AND create_time < '2027-01-01'
- ❌
- 隐式类型转换:字符串类型的字段不要传数字,否则会导致全表扫描。
- ❌
WHERE phone_num = 13800000000(phone_num 是 varchar) - ✅
WHERE phone_num = '13800000000'
- ❌
- 模糊查询:
LIKE '%keyword%'(前缀通配符)会导致索引失效。如果必须使用前缀通配,考虑使用覆盖索引 或全文索引 (MySQL FullText / SQL Server Full-Text Search)。 - OR 条件:如果
OR连接的两个条件中有一个没有索引,整个索引可能失效。建议拆分为UNION ALL。
- 函数操作:不要在索引列上使用函数或计算。
- 覆盖索引 (Covering Index)
- 概念:查询的列全部包含在索引中,无需回表(Lookup)。
- 效果:极大减少IO操作。
- 示例:
SELECT id, name FROM user WHERE age = 25,建立(age, name)联合索引。
- 区分度高的列建索引
- 性别、状态枚举等区分度低的列,单独建索引效果极差,数据库优化器可能直接放弃索引走全表扫描。
查询语句 (SQL) 重写优化
-
只取需要的列 (Avoid
SELECT *)- 原因:减少网络传输量,增加覆盖索引命中的概率,减少内存消耗。
- 做法:明确列出所需字段
SELECT id, name ...。
-
优化
JOIN操作- 小表驱动大表:确保驱动表(外层循环表)数据量较小。
- 关联字段必须有索引:
ON后面的关联字段在两张表中都应建立索引。 - 类型一致:关联字段的字符集和排序规则(Collation)必须一致,否则可能导致索引失效。
-
分页优化 (
LIMIT/OFFSET)-
问题:
LIMIT 100000, 10需要扫描前100010条记录并丢弃,效率极低。 -
优化方案:
- 延迟关联:先查ID,再回表。
sqlSELECT t.* FROM table t INNER JOIN (SELECT id FROM table LIMIT 100000, 10) tmp ON t.id = tmp.id;- 游标法(推荐):记录上一页最大的ID,直接
WHERE id > last_max_id LIMIT 10。
-
-
EXISTSvsIN- 一般情况:现代优化器(MySQL 5.7+/SQL Server 2016+)对两者处理差异不大。
- 特定场景:
- 子查询结果集小,主表大:用
IN。 - 子查询结果集大,主表小:用
EXISTS。
- 子查询结果集小,主表大:用
- NOT IN:尽量避免使用
NOT IN(特别是子查询包含NULL值时),推荐使用NOT EXISTS或LEFT JOIN ... WHERE ... IS NULL。
-
批量插入
- 避免循环单条插入。
- MySQL:
INSERT INTO t VALUES (...), (...), (...); - SQL Server: 同样支持多值插入,或使用
BULK INSERT处理海量数据。
六、调优实战步骤总结
- 定位慢SQL:
- MySQL: 开启慢查询日志 (
slow_query_log),或使用performance_schema。 - SQL Server: 使用 Profiler, Extended Events, 或查询
sys.dm_exec_query_stats。
- MySQL: 开启慢查询日志 (
- 分析执行计划:找出全表扫描、高成本算子、回表操作。
- 检查索引:是否缺失?是否失效?是否多余?
- 重写SQL:优化逻辑,去除函数,调整 Join 顺序。
- 验证测试:在生产环境镜像或测试环境中验证优化效果,确保没有副作用(如锁竞争加剧)。
- 监控:上线后持续观察 CPU、IO 和 响应时间。