文章目录
- 一、索引
- 二、索引的数据结构
-
- 1.B+树索引结构
- 2.Hash索引结构
- [3.为什么 InnoDB 选择 B+Tree 而不是其他结构?](#3.为什么 InnoDB 选择 B+Tree 而不是其他结构?)
- 三、索引的分类
- 四、索引的语法
- 五、索引的性能优化
- 六、索引的使用原则
一、索引
索引是一种有序的数据结构,它存储了表中某一列或某几列的值以及这些值对应的物理地址(或主键)。你可以把它想象成一本厚书的"目录":通过目录,你可以快速定位到某个章节的页码,而不需要一页一页地翻阅全书。
在数据库中,索引指向原始数据 ,为查询提供快速定位的能力。没有索引时,数据库只能进行全表扫描(Full Table Scan),逐行检查是否满足条件;有了合适的索引,数据库可以通过索引结构直接跳转到目标数据所在的位置,极大减少磁盘 I/O 次数。
- 索引的优点:
- 提高查询效率 :快速定位数据,减少扫描行数,尤其对 WHERE、JOIN、GROUP BY 效果显著。
- 提高排序效率 索引本身是有序的,ORDER BY 可以直接利用索引顺序,避免额外的文件排序(filesort)。
- 缺点:
- 占用磁盘空间:索引也是数据,需要额外的存储空间(尤其是 B+Tree 索引可能占表空间的 1~2 倍) 。
- 降低增删改效率:当对表进行 INSERT、UPDATE、DELETE 时,索引也需要同步维护,导致写操作变慢。
读多写少的表(如报表、日志分析、商品目录)适合建索引;写频繁的表(如流水记录、实时交易日志)应谨慎添加索引。
二、索引的数据结构
MySQL 支持多种索引数据结构,不同存储引擎的实现不同。常见的索引结构包括:
- B+Tree 索引:最常用,支持等值查询和范围查询,适用于 InnoDB 和 MyISAM。
- Hash 索引:只支持精确等值匹配(=、IN),查询速度极快,但不支持范围查询和排序。
- 空间索引(R-Tree):用于地理坐标等几何数据,MyISAM 支持。
- 全文索引(Full-Text):用于文本字段的关键词搜索,MyISAM 默认支持,InnoDB 从 5.6 版本开始支持。
下表汇总了 MySQL 主流存储引擎对各类索引的支持情况:
| 索引类型 / 存储引擎 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree 索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持(但有自适应哈希) | 不支持 | 支持 |
| R-Tree 索引 | 不支持 | 支持 | 不支持 |
| Full-Text 索引 | 5.6+ 支持 | 支持 | 不支持 |
InnoDB 虽然不直接支持创建 Hash 索引,但内部有自适应哈希索引(Adaptive Hash Index, AHI) 功能,会在运行时根据查询模式自动为热点数据建立哈希索引。
1.B+树索引结构
B+Tree 是 B-Tree 的一种变体,也是 MySQL 默认且最核心的索引结构,可以结合数据结构可视化网站 进行理解
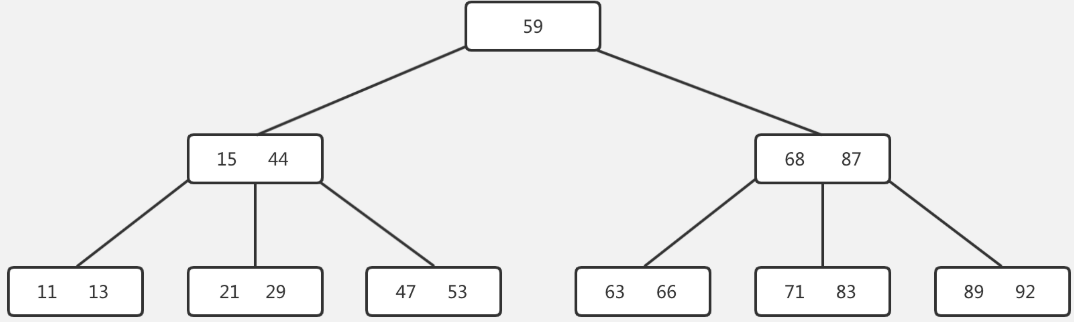
- B-Tree(以 5 阶为例)如下图所示
- 每个节点最多存储 4 个 key(关键值)和 5 个指针(指向子节点)。
- 节点中的 key 按升序排列。
- 所有节点的 key 值不重复(除非是唯一索引)。
- 插入时若节点 key 数量达到上限,则中间 key 向上分裂,形成新的父节点。
- B+Tree 相对于 B-Tree 做了以下改进:
所有数据记录(或指向数据行的指针)都存储在叶子节点中,非叶子节点只存储 key 值,用于路由搜索。- 叶子节点之间通过
单向链表相连,便于顺序遍历。
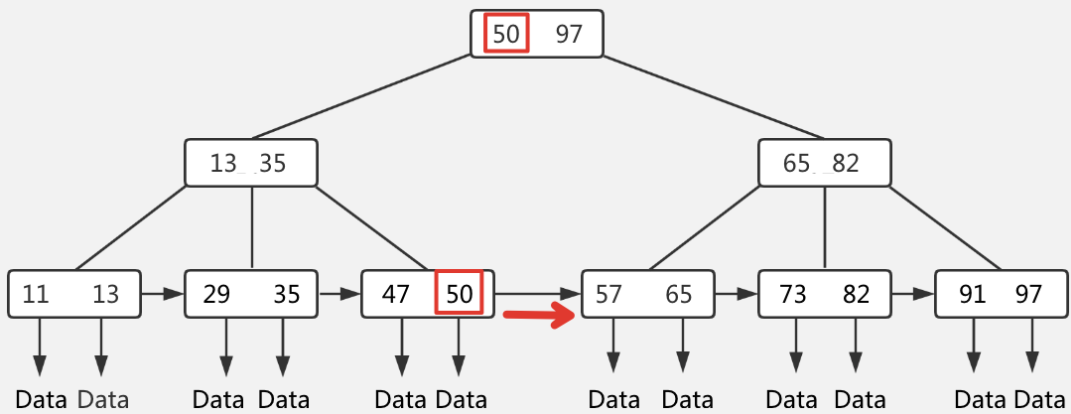
MySQL 的 InnoDB 存储引擎对经典 B+Tree 做了进一步优化:将叶子节点的单向链表改为双向链表。这样既可以从左向右遍历,也可以从右向左遍历,显著提升了逆序范围查询(ORDER BY ... DESC)的性能。
2.Hash索引结构
哈希索引基于哈希表实现。对索引列的值应用哈希函数,计算出固定长度的哈希码(hash code),然后映射到哈希表的某个槽位(bucket),槽位中存储指向实际数据行的指针。
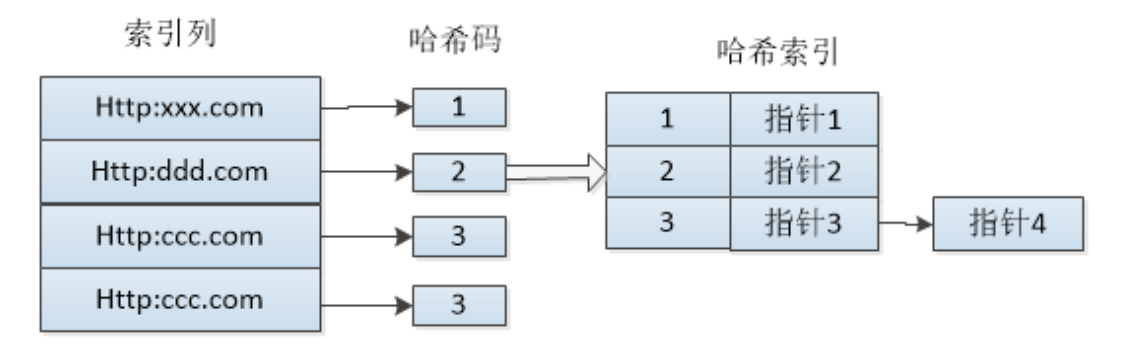
当两个不同的 key 通过哈希函数得到相同的哈希码并指向同一个槽位时,就发生了哈希冲突。常见的解决方法是链地址法:每个槽位维护一个链表,冲突的 key 依次链接在链表上。
- Hash索引特点
等值查询极快:通常一次哈希计算 + 一次查找即可定位,时间复杂度 O(1)不支持范围查询:无法处理 >、<、BETWEEN,因为哈希值无序无法利用索引排序:哈希表本身不存储原值顺序,无法用于 ORDER BY不支持部分索引列匹配:联合索引中,只有使用全部索引列的等值条件才能命中
在MySQL中,支持hash索引的是Memory引l擎,InnoDB中具有自适应Hash功能,Hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
3.为什么 InnoDB 选择 B+Tree 而不是其他结构?
- 二叉树 / 红黑树:树的高度随数据量增长而增加(例如 1000 万行时高度可达 20+),每次查询需多次随机 I/O,效率低下;
- B-Tree:非叶子节点存储数据和key,导致每个节点存储的数据量较少,树的高度较高 (节点大小有限);且叶子节点之间无链表,范围查询仍需回溯父节点,效率不如 B+Tree
- Hash:不支持范围查询、排序、模糊匹配;哈希冲突时性能不稳定;无法利用索引做最左前缀匹配
- B+Tree:
- 矮胖结构(高度一般 3~4),I/O 次数少;
- 叶子节点有序链表,范围查询和排序性能优秀;
- 非叶子节点只存 key,单页可存储更多 key,进一步降低树高;
- 天然适合磁盘预读和页缓存机制
三、索引的分类
1.基本分类
- 按功能逻辑分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | (无,即普通 INDEX) |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个,适用于 TEXT 类型 | FULLTEXT |
- 在 InnoDB 存储引擎中,根据索引的存储形式(即索引结构与数据存放的位置关系),可以分为以下两种:
| 类型 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一起,索引结构的叶子节点保存了完整的行数据 |
必须有,且只有一个。默认主键作为聚集索引;没有主键则使用第一个唯一索引;如果也没有,则 InnoDB 自动生成一个隐藏的 ROWID 作为聚集索引 |
| 非聚集索引 / 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键值(而不是行数据) |
可以存在多个。查询时通常需要回表 |
2.回表查询
当使用二级索引进行查询时,二级索引的叶子节点存储的是主键值 (而不是完整的行数据)。数据库首先在二级索引中找到匹配的主键值(例如 id),然后再根据这个主键值回到聚集索引 (通常是主键索引)中查找完整的行数据。这个过程需要两次 B+Tree 查找,称为回表。
先通过"目录(二级索引)"找到主键,再通过主键去"正文(聚集索引)"中找到完整的一行。
3.InnoDB主键索引的B+tree高度为多高呢?
-
假设条件:
- 一行数据大小约为 1 KB
- InnoDB 页大小默认为 16 KB,因此一页中可以存储 16 行 这样的数据
- 非叶子节点中的指针占用 6 字节(InnoDB 默认)
- 主键类型为 BIGINT,占用 8 字节
-
在高度为 2 的 B+Tree 中:
- 根节点(非叶子)可存储的 key 数量为 n
- 每个 key 占 8 字节,每个指针占 6 字节,根节点总大小需 ≤ 16 KB
- 计算公式如下,n ≈ 1170,即根节点最多可以存储 1170 个 key,每个 key 对应一个子节点指针。每个叶子节点存储 16 行数据,因此高度为 2 时,最多可存储1171 × 16 ≈ 18736 行
text
n × 8 + (n + 1) × 6 = 16 × 1024- 高度为 3 时,根节点同样可指向约 1171 个第二层节点,而每个第二层节点又可指向 1171 个叶子节点,每个叶子节点存储 16 行数据。因此总行数为:1171 × 1171 × 16 ≈ 21,939,856 行 (约 2194 万行)
四、索引的语法
- 创建索引
sql
CREATE [UNIQUE\|FULLTEXT] INDEX index_name ON table_name (col1, col2, ...);
# UNIQUE:可选,表示创建唯一索引(列值不能重复)。
# FULLTEXT:可选,表示创建全文索引(用于文本搜索)。
# 不指定关键字时,创建的是**普通索引**(非唯一、非全文)。
# index_name:索引名称,建议见名知意(如 `idx_name`、`uniq_phone`)。
# table_name:表名。
# (col1, col2, ...):单列索引写一个列名,联合索引写多个列名(用逗号分隔)。- 查看索引
sql
SHOW INDEX FROM table_name;- 删除索引
sql
DROP INDEX index_name ON table_name;
sql
# 1.为 name 字段创建普通索引
CREATE INDEX idx_name ON user(name);
# 2.为 phone 字段创建唯一索引
CREATE UNIQUE INDEX uniq_phone ON user(phone);
# 3.为profession、age、status创建联合索引。
CREATE INDEX idx_profession_age_status ON user(profession, age, status);
# 4.为 email 建立合适的索引
CREATE INDEX idx_email ON user(email);五、索引的性能优化
通过以下命令可以查看当前 MySQL 服务器的各类 SQL 语句执行频率(增删改查等),有助于分析整体负载:
SQL
SHOW GLOBAL STATUS LIKE 'Com_______';输出结果示例
SQL
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_select | 1234 |
| Com_insert | 567 |
| Com_update | 890 |
| Com_delete | 12 |
+---------------+-------+Com_______ 为 7 个下划线,匹配 Com_select、Com_insert、Com_update、Com_delete 等,Com_select就表示对当前表进行查询的操作有几次。
1.慢查询日志
慢查询日志记录了所有执行时间超过指定参数 long_query_time(单位:秒,默认 10 秒)的 SQL 语句。默认关闭,需要手动开启。
在 MySQL 配置文件(例如 /etc/my.cnf)中添加以下内容:
ini
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2配置完成后,重启 MySQL 服务使配置生效
sql
# 配置完成后重启MySQL
systemctl restart mysqld可以查看慢查询的日志
sql
show variables like"slow_query_log';·
2.profile详情
show profiles能够帮助我们在 SQL 优化时了解时间耗费在哪个阶段。通过 have_profiling 参数查看当前 MySQL 是否支持 Profile 功能:
sql
SELECT @@have_profiling;默认 profiling 是关闭的,可以通过 SET 语句在 SESSION 或 GLOBAL 级别开启:
sql
SET profiling =1;执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
sql
-- 查看每一条 SQL 的耗时基本情况
SHOW PROFILES;
-- 查看指定 query_id 的 SQL 语句各个阶段的耗时情况
SHOW PROFILE FOR QUERY query_id;
-- 查看指定 query_id 的 SQL 语句 CPU 使用情况
SHOW PROFILE CPU FOR QUERY query_id;3.explain执行计划
EXPLAIN 或 DESC 命令用于获取 MySQL 如何执行 SELECT 语句的信息,包括表连接顺序、使用的索引等。其语法如下,
sql
-- 直接在 SELECT 语句之前加上关键字 EXPLAIN 或 DESC
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;返回的示例如下,
sql
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | s | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 100.00 | NULL |
| 1 | SIMPLE | sc | NULL | ALL | NULL | NULL | NULL | NULL | 2000 | 50.00 | NULL |
| 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 500 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+EXPLAIN返回结果的个字段说明如下:
- id:SELECT 查询的序列号,表示查询中执行 SELECT 子句或
操作表的顺序。- id 相同:执行顺序从上到下
- id 不同:id 值越大,越先执行
- select_type:表示
SELECT 的类型,常见取值:- SIMPLE:简单表,不使用表连接或子查询
- PRIMARY:主查询,即外层的查询
- UNION:UNION 中的第二个或后面的查询语句
- SUBQUERY:SELECT / WHERE 之后包含了子查询
- type:表示
连接类型,性能由好到差依次为:NULL > system > const > eq_ref > ref > range > index > all- NULL:几乎不会出现,除非不操作表
- const:根据主键或唯一索引进行等值匹配时出现
- ref:使用非唯一性索引进行等值匹配时出现
- possible_keys:显示
可能应用在这张表上的索引(一个或多个) - key:
实际使用的索引。如果为 NULL,则没有使用索引 - key_len:表示索引中使用的字节数。该值为索引字段最大可能长度,并非实际使用长度。在不损失精确性的前提下,长度越短越好
- rows:MySQL 认为必须执行查询的行数(估算值)。在 InnoDB 中为一个估计值,可能不完全准确
- filtered:表示返回结果的行数占需读取行数的百分比。filtered 值越大越好
- Extra:包含额外的执行信息,如 Using index(覆盖索引)、Using where、Using temporary、Using filesort 等
- 示例 1:多表连接查询,执行结果中的执行顺序通常为:首先 student(s),然后 student_course(sc),最后 course(c)。类型为 SIMPLE。
sql
EXPLAIN SELECT s.*, c.*
FROM student s, course c, student_course sc
WHERE s.id = sc.studentid AND c.id = sc.courseid;- 示例 2:子查询,执行顺序为:先执行最内层子查询(course),再执行 student_course,最后执行外层查询(student)。
sql
EXPLAIN SELECT * FROM student s
WHERE s.id IN (
SELECT studentid FROM student_course sc
WHERE sc.courseid = (
SELECT id FROM course c WHERE c.name = 'MySQL'
)
);六、索引的使用原则
1.联合索引的使用原则
(1)最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将部分失效(后面的字段索引失效)。
sql
-- 符合最左前缀法则,使用到了索引 idx_profession_age_status
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- 使用到了索引(profession + age)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31;
-- 使用到了索引(仅 profession)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程';
-- 没有使用到索引,因为最左边的 profession 不存在
EXPLAIN SELECT * FROM tb_user WHERE age = 31 AND status = '0';
-- 同样没有使用索引
EXPLAIN SELECT * FROM tb_user WHERE status = '0';
-- 使用到了索引,但因为跳过了 age,所以后面的 status = '0' 会失效(只有 profession 走索引)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND status = '0';
-- 使用到了索引,与条件的书写位置无关,只要字段存在即可(MySQL优化器会调整顺序)
EXPLAIN SELECT * FROM tb_user WHERE age = 31 AND status = '0' AND profession = '软件工程';(2)范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
sql
-- 此时 status = '0' 的索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age > 30 AND status = '0';
-- 如果使用 >=,则右侧列不会失效(建议使用 >= 或 <=)
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age >= 30 AND status = '0';解决方案:尽量使用 >= 或 <= 代替 > 和 <,避免索引失效。
2.索引失效的情况
索引列运算:不要在索引列上进行运算操作,索引将失效。
sql
-- 对 phone 字段截取运算,索引失效
EXPLAIN SELECT * FROM tb_user WHERE SUBSTRING(phone, 10, 2) = '15';字符串不加引号:字符串类型字段使用时,不加引号,索引将失效,但此时查询不会出错(MySQL 会隐式转换)。
sql
-- status 字段是字符串,但条件中写成了数字 0,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = 0;
-- phone 字段是字符串,条件中未加引号,索引失效
EXPLAIN SELECT * FROM tb_user WHERE phone = 17799990015;模糊查询:如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
sql
# 使用索引
-- 尾部模糊匹配,使用索引
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '软件%';
-- 头部模糊匹配,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '%工程';
-- 头部和尾部都模糊,索引失效
EXPLAIN SELECT * FROM tb_user WHERE profession LIKE '%工%';or连接的条件:用 OR 分割开的条件,如果 OR 前的条件中的列有索引,而后面的列中没有索引,那么涉及的所有索引都不会被用到。只有给 OR 后面的字段也创建索引,才会生效。
sql
-- id 有索引,但 age 没有索引,整个查询不走索引
EXPLAIN SELECT * FROM tb_user WHERE id = 10 OR age = 23;
-- phone 有索引,age 没有索引,同样索引失效
EXPLAIN SELECT * FROM tb_user WHERE phone = '17799990017' OR age = 23;数据分布影响:如果 MySQL 评估使用索引比全表扫描更慢,则不会使用索引。【当查询需要返回表中大部分数据时(例如 WHERE phone >= '17799990005' 匹配了表中 80% 的行),MySQL 认为全表扫描的 I/O 效率更高(因为索引需要回表,随机 I/O 可能更慢)。反之,如果查询只返回少量数据(例如 WHERE phone >= '17799990015' 只匹配 5% 的行),则使用索引更优。不是单纯看数据量多少,而是看命中比例。】
sql
-- 如果 '17799990005' 之前的记录很少,可能走索引;如果很多,可能不走
SELECT * FROM tb_user WHERE phone >= '17799990005';
-- 如果 '17799990015' 之后的记录很少,大概率走索引
SELECT * FROM tb_user WHERE phone >= '17799990015';3.SQL提示
SQL 提示是优化数据库的一个重要手段,即在 SQL 语句中加入一些人为的提示,影响优化器的选择(例如一个字段存在联合索引和普通索引,优化器可能选择了非预期的索引)。
- use index:建议使用何种索引(MySQL 内部评估,也可能不使用)
sql
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';- ignore index:不要使用何种索引
sql
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';- force index:强制使用何种索引
sql
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';4.覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少 SELECT *。
下面的例子中,假设 id 是主键索引,profession, age, status 是联合索引。前两个查询所需字段都在索引中,不需要回表;第三个查询需要 name 字段(不在索引中),因此需要回表。
sql
-- Extra: Using where; Using index(不需要回表)
EXPLAIN SELECT id, profession FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- Extra: Using where; Using index(不需要回表)
EXPLAIN SELECT id, profession, age, status FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';
-- Extra: Using index condition(需要回表)
EXPLAIN SELECT id, profession, age, status, name FROM tb_user WHERE profession = '软件工程' AND age = 31 AND status = '0';Extra 字段含义:
- Using index condition:查找使用了索引,但是需要回表查询数据。
- Using where; Using index:查找使用了索引,且需要的数据都在索引列中能找到,不需要回表。
5.前缀索引
当字段类型为字符串(VARCHAR、TEXT 等)时,有时需要索引很长的字符串,这会使得索引变得很大,查询时浪费大量磁盘 I/O,影响查询效率。此时可以只将字符串的一部分前缀建立索引,大大节约索引空间,提高索引效率。
sql
CREATE INDEX idx_xxxx ON table_name(column(n));
-- 其中 n 表示前缀长度- 前缀长度的选择:可以根据索引的选择性来决定。选择性 = 不重复的索引值(基数) / 数据表的记录总数。选择性越高,查询效率越高。唯一索引的选择性是 1,性能最好。
sql
-- 计算 email 列完整的选择性
SELECT COUNT(DISTINCT email) / COUNT(*) FROM tb_user;
-- 计算 email 前 5 个字符的选择性
SELECT COUNT(DISTINCT SUBSTRING(email, 1, 5)) / COUNT(*) FROM tb_user;执行过程:通过前缀索引找到前 5 个字符匹配的记录主键,然后回表查询完整行数据,再对比完整 email 是否匹配(因为前缀可能重复,需要二次校验)。
6.单列索引与联合索引
- 单列索引:一个索引只包含单个列。
- 联合索引:一个索引包含了多个列。
- 在业务场景中,如果存在多个查询条件,建议建立联合索引,而非多个单列索引。
多条件联合查询时,MySQL 优化器会评估哪个字段的索引效率更高,选择该索引完成本次查询。但即使选择了某个单列索引,其他条件往往需要回表过滤,效率较低。
7.索引的设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引。小表或写密集的表不建议建过多索引。
- 针对于常作为查询条件(WHERE)、排序(ORDER BY)、分组(GROUP BY)操作的字段建立索引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引。区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,且字段长度较长,可以针对于字段的特点建立前缀索引,以节省空间。
- 尽量使用联合索引,减少单列索引。联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善。索引越多,维护索引结构的代价越大,会影响增删改的效率。
- 如果索引列不能存储 NULL 值,请在创建表时使用 NOT NULL 约束它。当优化器知道每列是否包含 NULL 值时,可以更好地确定哪个索引最有效地用于查询。