"我们运维上百套裸金属 Kafka 集群多年,最头疼的就是业务高峰期消费积压拖垮整个集群的写入。切换到 AutoMQ 后,日志检索平台的生产 P99 从 10 秒降到 500 毫秒,积压量下降了 40 倍,硬件成本还节省了一半。现在团队终于可以把精力从基础设施运维转向业务优化。" 作者:王任义(360 云平台,智汇云中间件团队)
关于 360:从安全到云原生基础设施
360 集团是中国领先的互联网安全公司,也是互联网免费安全的倡导者和先行者。自 2005 年创立以来,先后推出 360 安全卫士、360 手机卫士、360 安全浏览器等安全产品,服务数亿用户。随着业务版图从安全延伸到搜索、游戏、智能硬件等领域,360 内部的数据规模也在持续膨胀------每天产生千亿级日志,PB 级数据需要实时采集、传输和分析。
支撑这一切的底座,是 360 云平台。作为集团技术中台,360 云平台为所有业务线提供存储、计算、中间件等基础云服务,而 Kafka 是其中最核心的消息队列中间件。生产环境运行着上百套 Kafka 集群,主要采用裸金属部署,单 topic 峰值 60 万 QPS,集群峰值 500 万 QPS。
随着集群规模持续增长,运维成本 和隔离性问题日益突出------硬件故障处理、扩容迁移、追赶读拖垮写入,这些都是大规模裸金属 Kafka 的老大难问题。在云原生和 Serverless 的大趋势下,360 云平台开始思考:是否有更先进的 Kafka 架构,能更好地适配云时代?
团队开始调研新一代方案,AutoMQ 基于 S3 的 Diskless Kafka 架构引起了关注------存算分离、读写路径隔离、秒级弹性伸缩,这些特性恰好对准了 360 在大规模 Kafka 运维中最头疼的问题。而 360 内部团队基于 Apache Ozone 提供了支持 S3 API 标准协议的分布式存储系统,意味着 AutoMQ 所需的对象存储底座在 360 内部已经具备,落地条件成熟。
冷读:从 Kafka 的架构短板到 AutoMQ 的解法
追赶读(catch-up read) 是消息系统中非常常见的场景:下游消费者因为处理瓶颈或批处理任务,需要从较早的位点开始消费已经不在内存中的"冷数据"。对于大多数消息系统来说,这本不应该是个难题,但 Apache Kafka 的架构设计让冷读变成了一个影响全局的性能杀手。
问题的根源在于 Kafka 读写路径上的两个关键技术选择:
- 第一,Page Cache 无法区分冷热数据。 Kafka 将内存管理完全交给操作系统的 Page Cache,自身不做冷热分离。当消费者读取冷数据时,大量磁盘数据被加载进 Page Cache,挤占了热数据的内存空间,导致原本可以从内存直接读取的实时消费(tail read)也开始频繁触发磁盘 IO。
- 第二,SendFile 系统调用阻塞网络线程。 Kafka 的零拷贝机制依赖 SendFile 系统调用,而这个调用发生在 Kafka 的网络线程池中。当 SendFile 需要从磁盘拷贝冷数据时,会阻塞网络线程。由于同一个线程池同时处理读写请求,冷读不仅拖慢自己,还会级联影响同集群所有 topic 的写入性能。
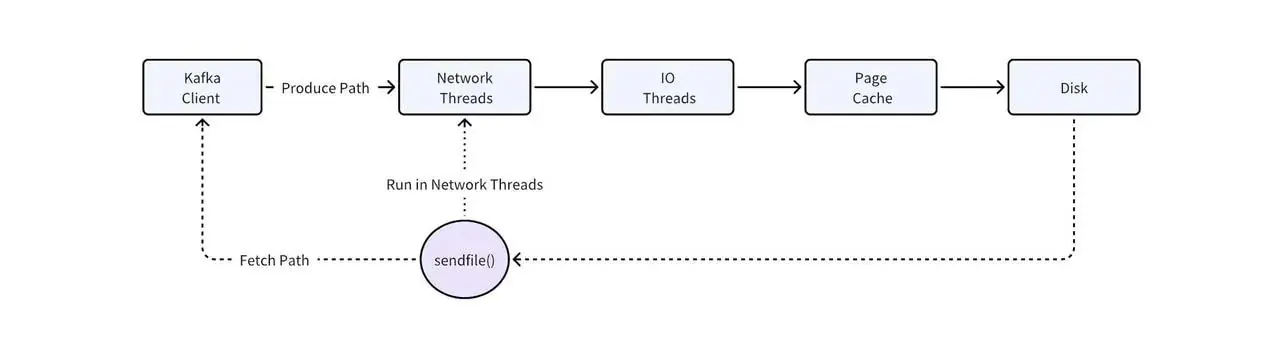
这是一个已知的架构问题(KAFKA-7504),至今未被根本解决。
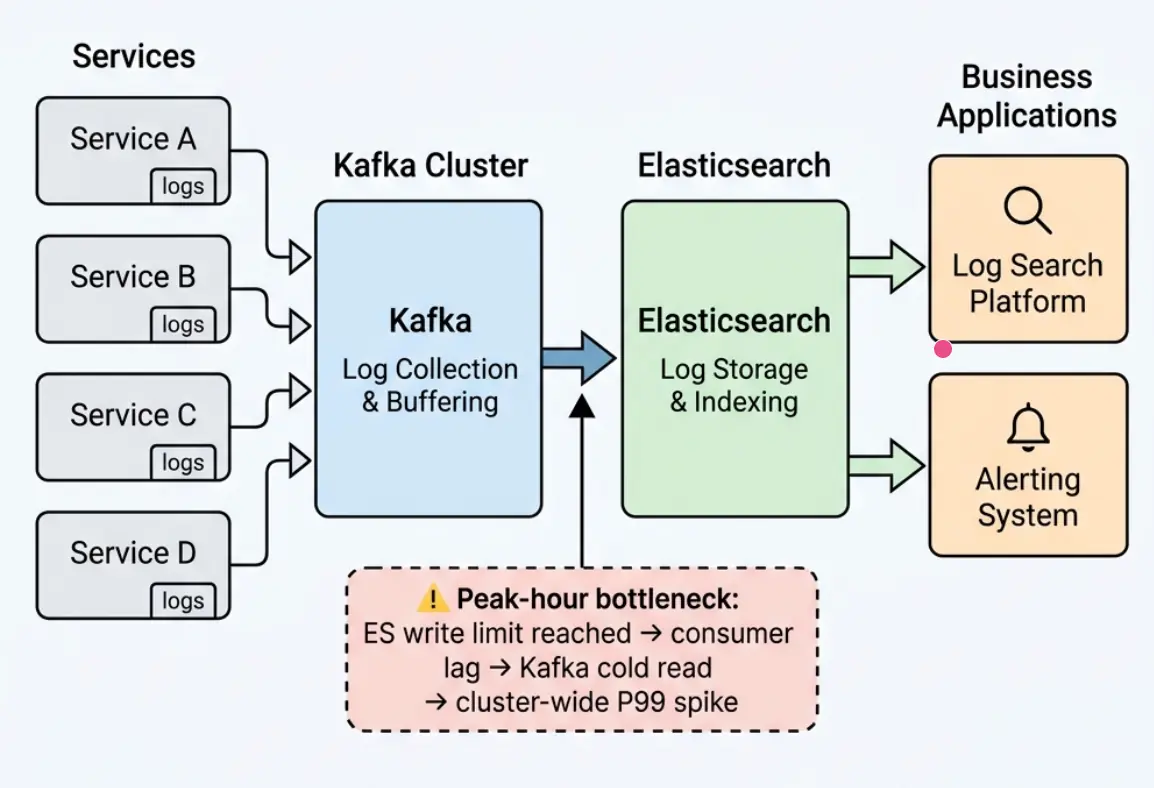
360 云平台对此深有体感。360 有一个核心业务场景:线上服务的统一日志检索平台,所有服务的运行日志通过 Kafka 收集,统一写入 Elasticsearch,业务基于 ES 做日志检索和告警。这个业务的特点是波峰波谷明显------每天业务高峰期,下游 ES 写入达到瓶颈,消费者跟不上生产者,消息开始积压,正是上面描述的冷读场景。实际表现:业务高峰期消息积压达到 10 亿条、约 200 GB,集群写入 P99 飙升到约 10 秒,同集群内其他业务的 topic 也受到影响,日志检索和告警的及时性无法保障。
AutoMQ 从架构设计的第一天就考虑了冷热数据隔离问题,将数据路径拆分为三条独立通道:
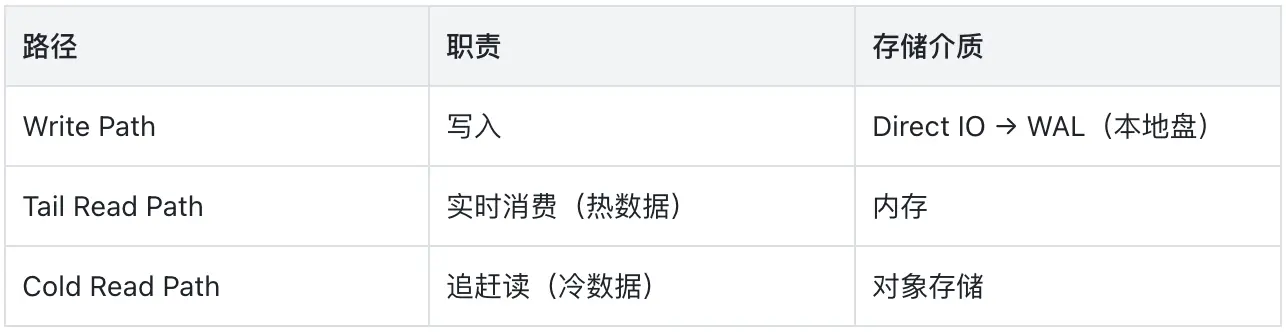 写入使用 Direct IO 绕过 Page Cache,从根本上避免了冷读对写入路径的干扰。冷读走对象存储的高吞吐通道,充分利用对象存储的带宽能力,不与写入和实时消费争抢资源。三条路径在架构层面彻底隔离,意味着无论下游消费者积压多少数据,追赶读都不会影响生产者的写入性能。
写入使用 Direct IO 绕过 Page Cache,从根本上避免了冷读对写入路径的干扰。冷读走对象存储的高吞吐通道,充分利用对象存储的带宽能力,不与写入和实时消费争抢资源。三条路径在架构层面彻底隔离,意味着无论下游消费者积压多少数据,追赶读都不会影响生产者的写入性能。
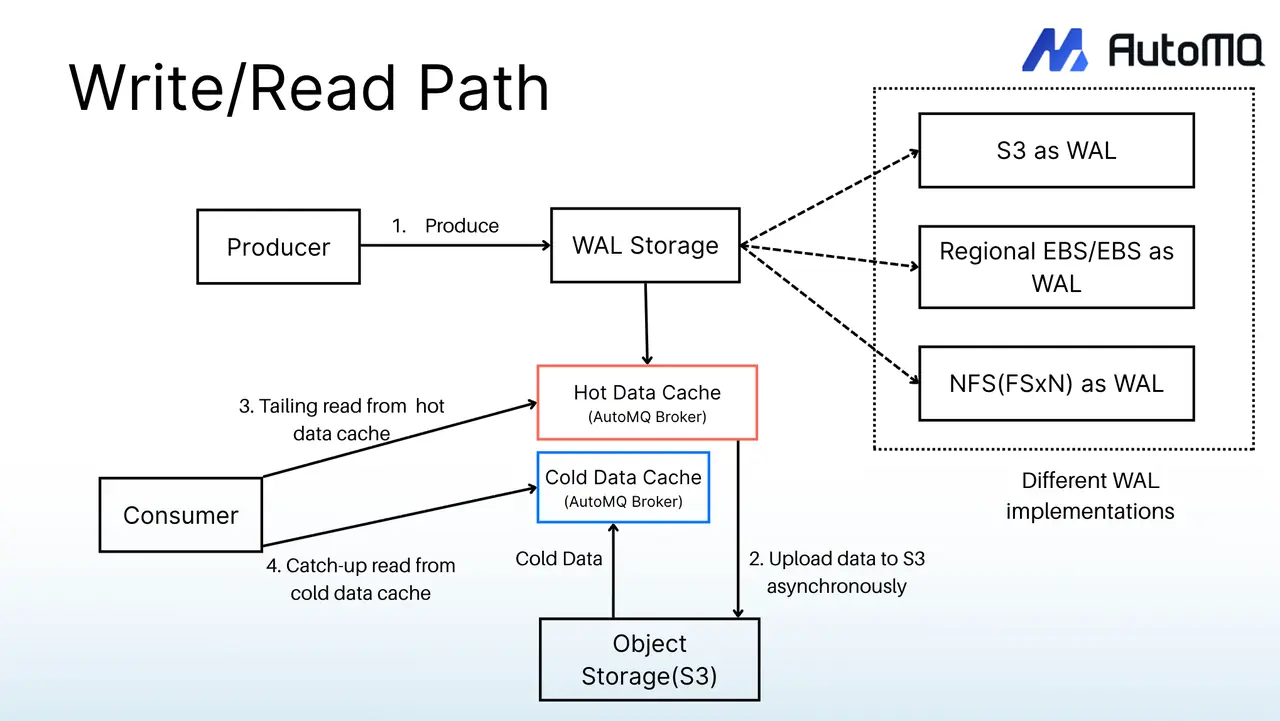
对 360 来说,AutoMQ 的三路径架构直接对应了日志检索平台面临的冷读问题。同时,AutoMQ 100% 兼容 Kafka 协议,360 已有的业务代码和自研 Client 框架无需改造;云原生的 K8s 部署模式也与 360 云平台已全面容器化的基础设施天然契合。
性能评估与验证
在正式投入生产之前,360 团队在 Kubernetes 上搭建了评估集群,从基础延迟、冷读隔离、弹性伸缩三个维度对 AutoMQ 进行了系统性验证。评估集群使用 StatefulSet 分别管理 AutoMQ 的 Controller(2C/4GB)和 Broker(4C/16GB),数据持久化到对象存储。
性能基准测试
评估环境就绪后,第一步是验证基础延迟是否满足生产要求。团队在 8 节点 Broker 集群上,使用业界标准的 OpenMessaging Benchmark 框架,分别以 100 MiB/s 和 500 MiB/s 两个负载级别进行压测(acks=all,确保数据持久化后再返回成功):
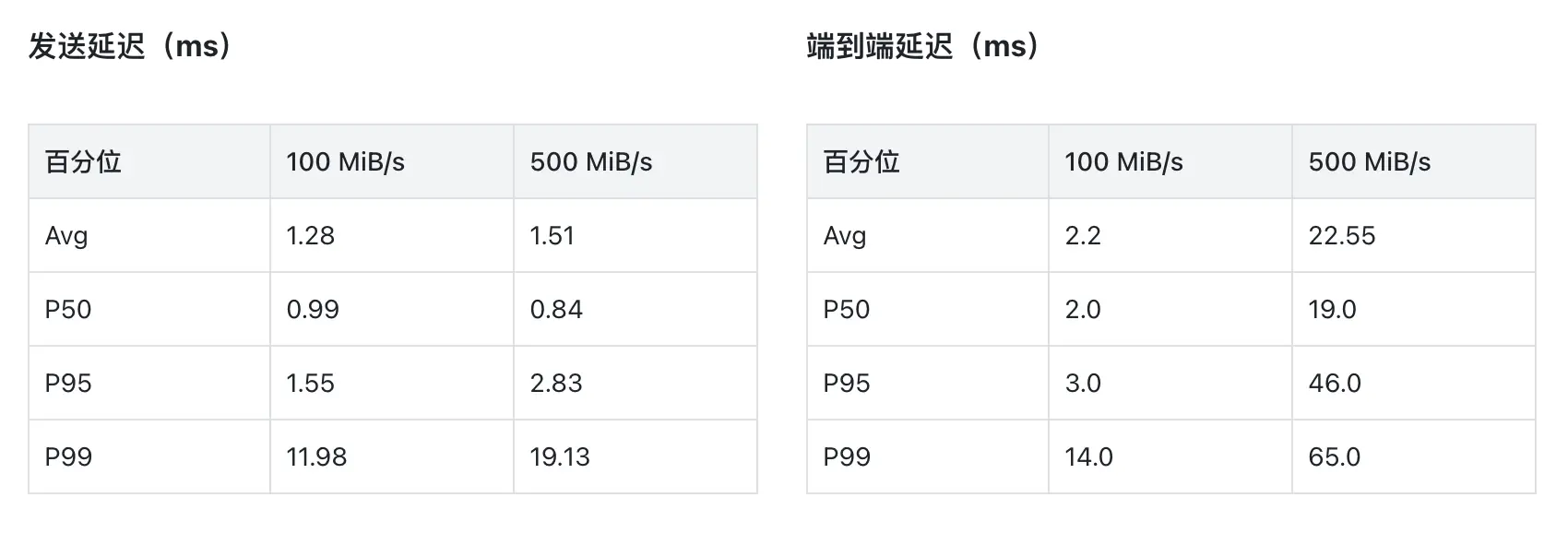
追赶读隔离测试
团队以 100 MiB/s 持续发送,在累积 100 GiB 数据后拉起消费者从最早位点开始消费,模拟业务高峰期的冷读场景。结果表明:写入速率和延迟在追赶读期间保持稳定,追赶读峰值达到约 461 MiB/s,能够快速消化积压消息。读写路径的隔离性得到验证。
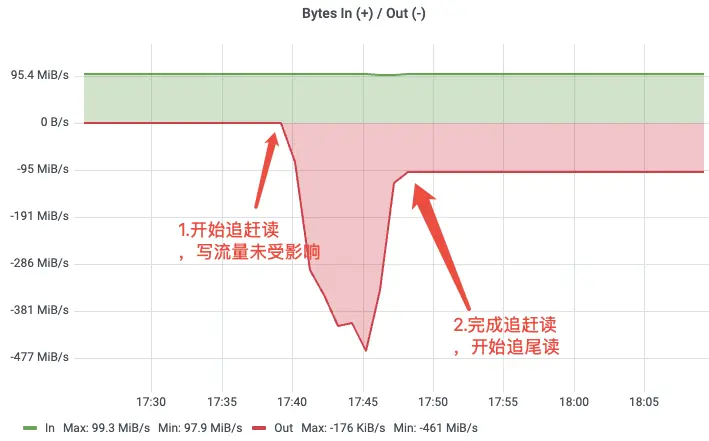
弹性伸缩测试
对于 360 这样拥有上百套 Kafka 集群的团队来说,弹性伸缩能力直接决定了运维负担的大小。传统 Apache Kafka 的扩容之所以慢,根本原因在于 Broker 是有状态的------每个 Broker 本地磁盘上存储着大量 partition 数据,新增节点后需要跨网络迁移这些数据才能实现负载均衡,数据量越大迁移越慢,动辄数小时甚至数天。AutoMQ 的存算分离架构从根本上改变了这一点:数据全部持久化在对象存储中,Broker 是无状态的,新节点启动后只需接管 partition 的元数据,无需迁移任何数据,因此可以做到秒级分区迁移和分钟级弹性扩容。扩容完成后,AutoMQ 内置的自动重平衡机制会持续监测各节点负载,动态调度分区分配,确保流量在新旧节点间自动均衡。
360 团队设计了一个极端场景来验证这一能力:集群初始只有 1 个 Broker,创建 1000 分区的 Topic,直接以 1 GiB/s 的流量发送。从监控告警触发到批量扩容再到流量自动均衡,全程 4 分钟完成,无需人工干预,实际验证效果如下图所示。
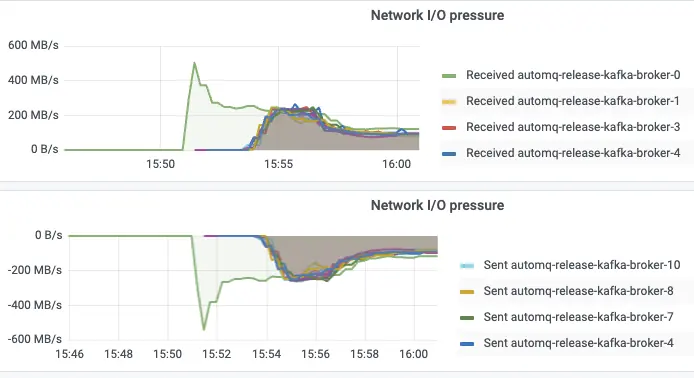
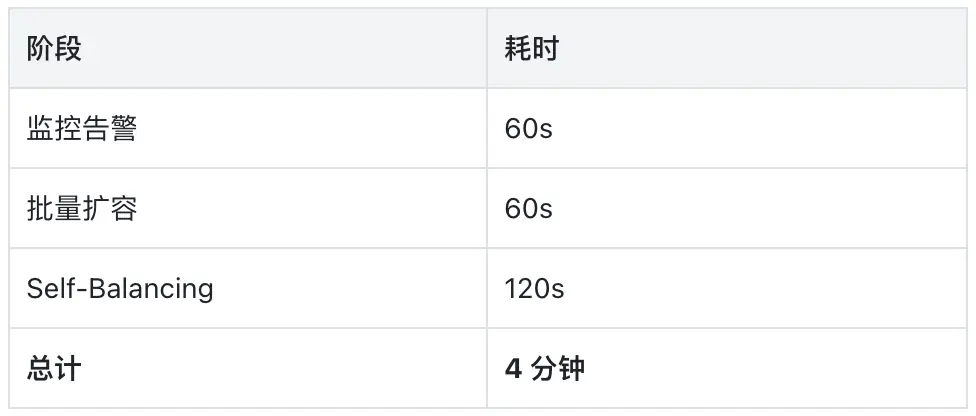
相比传统 Kafka 扩容动辄数小时的数据迁移,这个结果意味着 360 未来面对突发流量时,可以真正实现自动化的弹性响应,而不再依赖人工值守和提前预留大量冗余资源。
评估结论
三轮测试全部符合预期。基础延迟在 acks=all 配置下依然保持毫秒级;追赶读期间写入性能完全不受影响,冷热隔离的架构承诺得到了实测验证;弹性伸缩从 0 到 1 GiB/s 仅需 4 分钟,彻底改变了传统 Kafka 扩容的运维模式。
生产部署与收益
基于评估结果,360 团队决定将日志检索平台------冷读问题最突出的业务------作为第一个生产业务切换到 AutoMQ。
生产部署架构
生产环境沿用了评估阶段的部署模式。AutoMQ 的架构设计理念是将数据持久性和可用性卸载给云存储,对象存储本身的高可用性是整个架构的基石。为了在此基础上进一步提升可用性,360 额外设计了集群级故障切换方案。
360 的做法是:每个 AutoMQ 集群配备一个 HA 备用集群,定时同步集群元数据。生产集群通过实时写检测持续监控健康状态,一旦检测到异常,自动将集群 DNS 解析切换到备用集群,同时修改 Endpoint 服务返回的集群地址。客户端侧配置 metadata.recovery.strategy=rebootstrap(Kafka KIP-899),故障发生后客户端自动重新初始化连接地址完成集群切换,备用集群按需弹性扩容承接流量。这套方案充分利用了 AutoMQ Broker 无状态的特性------备用集群无需预先承载数据,只需在切换时快速扩容即可。
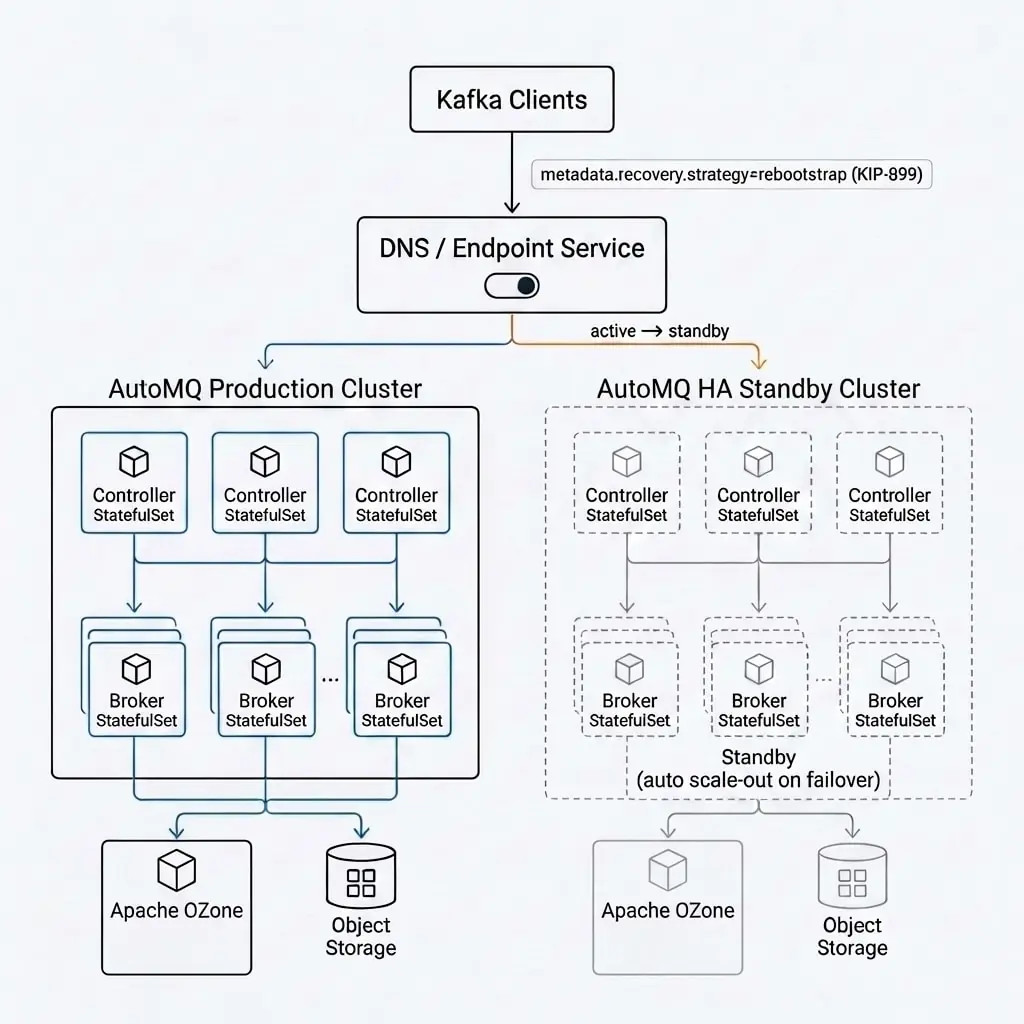
在资源配置上,单个日志检索集群高峰期部署 30 个 Broker Pod(4C/16GB),配合 HPA 自动伸缩,低峰期自动缩容节省资源。相比此前裸金属 Kafka 需要长期预留大量物理机应对峰值流量,容器化部署的资源利用率有了质的提升。
上线收益
日志检索平台切换到 AutoMQ 后,困扰团队已久的业务高峰期消息积压问题被彻底解决。下表对比了切换前后积压数据处理的核心指标,可以看到 AutoMQ 显著提升了 Kafka 生产消费链路在消息堆积场景下的处理效率。
Kafka 常被用于削峰填谷,消息堆积本身是正常现象,关键在于消费者能否快速消化这些积压数据。Apache Kafka 的传统架构下,冷读会触发 Broker 磁盘 I/O,显著拖慢消费速率。
AutoMQ 采用 Diskless 架构,天然实现冷热数据分离:冷读时通过 prefetch 和并发优化直接从对象存储拉取历史数据,既不影响实时写入和追尾读,也不会引发 Broker 侧的磁盘 I/O 和性能劣化,因此能够显著提升积压数据的消费速率,避免流量高峰期间堆积过多的数据。
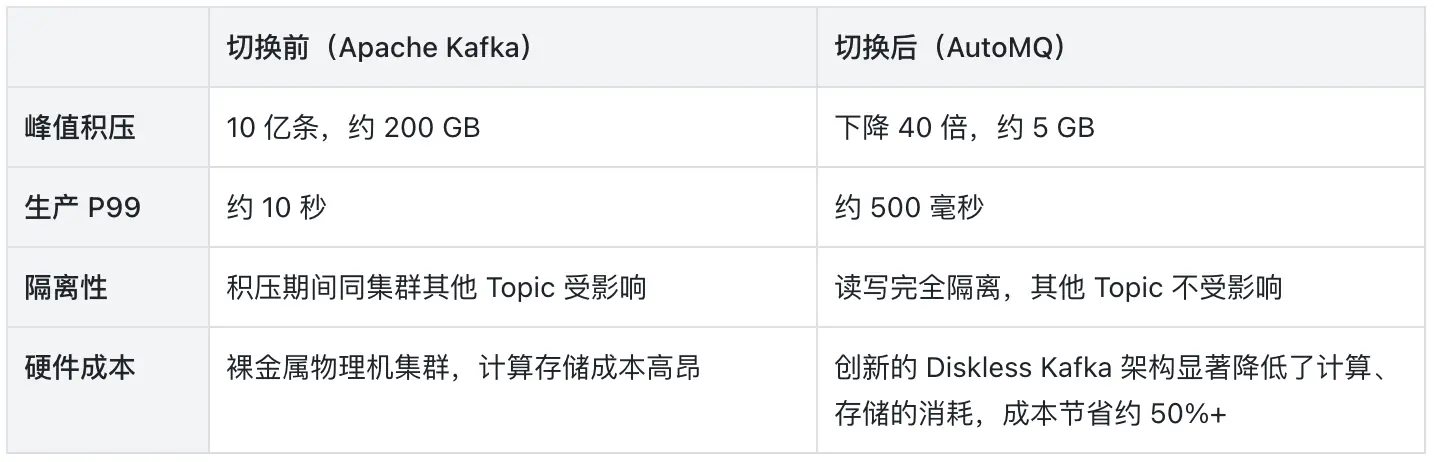 从吞吐监控可以看到,切换后的日志检索集群在业务高峰期峰值吞吐达到 1.4 GB/s,30 个 4C/16GB 的 Pod 即可稳定承载,写入曲线平滑无毛刺。
从吞吐监控可以看到,切换后的日志检索集群在业务高峰期峰值吞吐达到 1.4 GB/s,30 个 4C/16GB 的 Pod 即可稳定承载,写入曲线平滑无毛刺。
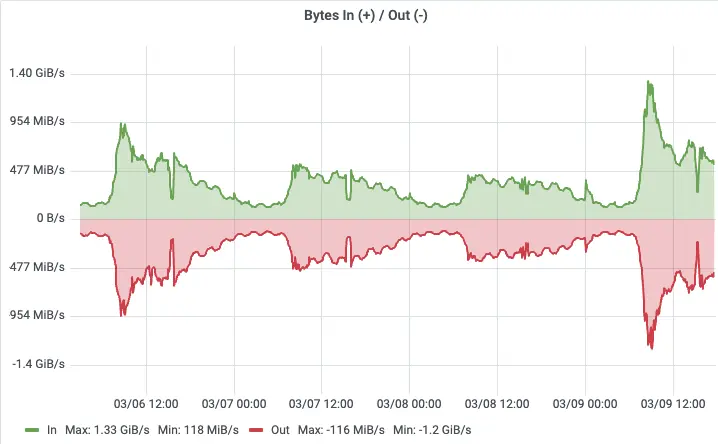
存储方面,数据自动持久化到对象存储,存储容量随业务量弹性增长,无需提前规划磁盘容量,也不再有裸金属时代磁盘空间告警的运维负担。
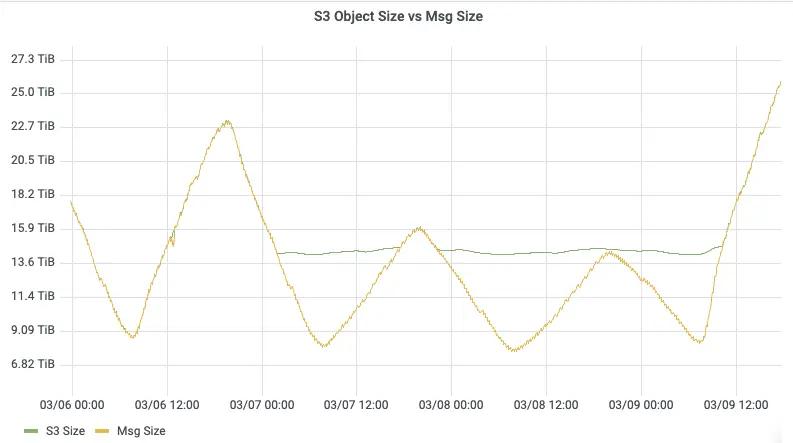
对比最为直观的是 Consumer Lag 曲线:切换前,业务高峰期积压峰值超过 10 亿条消息;切换后,同样的业务流量下积压量下降了 40 倍,消费者能够快速追上生产进度。
其中最关键的变化是隔离性:切换前,业务高峰期的消息积压会通过冷读污染 Page Cache,级联拖垮同集群所有 Topic 的写入;切换后,由于 AutoMQ 的读写路径在架构层面彻底隔离,即使下游 ES 出现写入瓶颈导致消费积压,生产端的写入延迟依然保持在毫秒级,日志检索和告警的及时性得到保障。
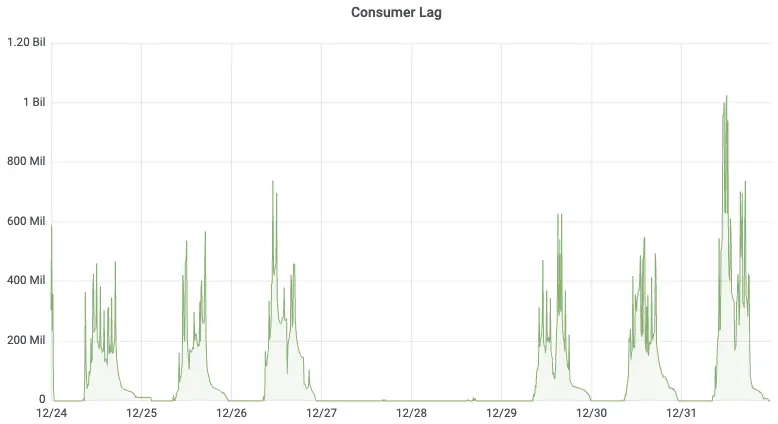 切换 AutoMQ 前的 Consumer Lag
切换 AutoMQ 前的 Consumer Lag
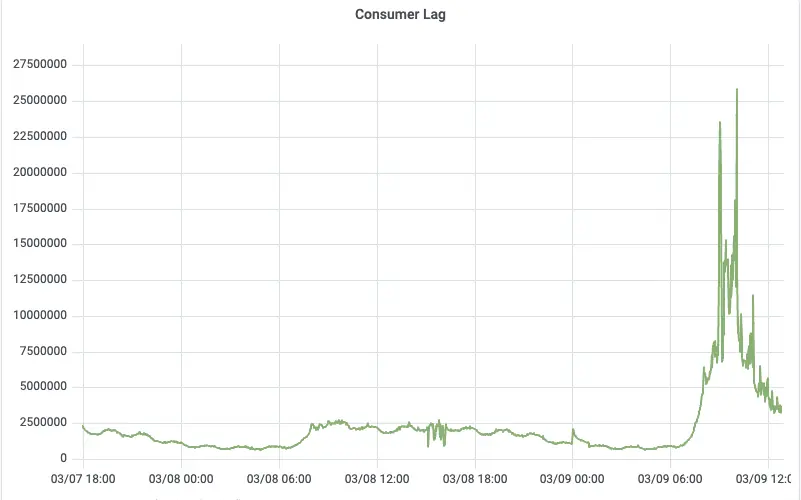 切换 AutoMQ 后的 Consumer Lag (积压下降 40 倍)
切换 AutoMQ 后的 Consumer Lag (积压下降 40 倍)
展望
日志检索平台的上线验证了 AutoMQ 在 360 生产环境中的可行性。作为集团技术中台,360 云平台承载着上百套 Kafka 集群,覆盖日志采集、实时计算、监控告警、数据同步等多种业务场景。日志检索平台只是第一步,接下来团队计划将 AutoMQ 逐步推广到更多业务线的 Kafka 集群,充分利用存算分离架构带来的弹性伸缩和成本优势,最终实现从裸金属到云原生 Kafka 架构的整体升级。