1、训练基本流程
LLM 训练是一项复杂、高资源消耗的系统工程,核心目标是将基础"文本补全器"打磨为可理解、遵循指令的智能助手,整体分为三大核心训练阶段 与三大配套支撑环节。
1.1 核心训练三阶段
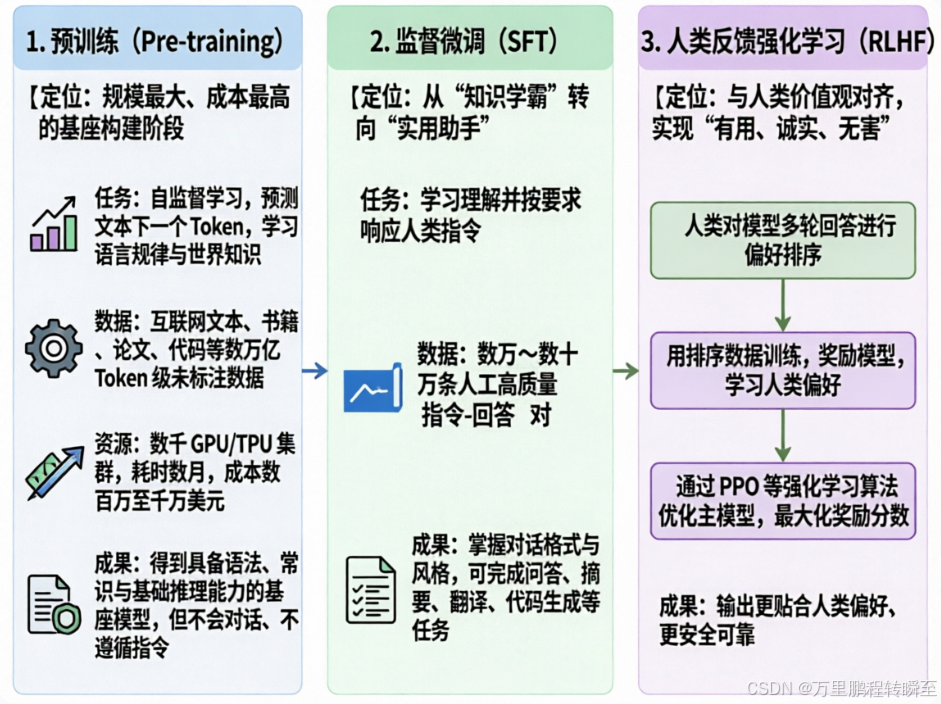
三个阶段具体对比如下
| 维度 | Pre-Train 预训练 | SFT 有监督微调 | RLHF 人类反馈强化学习 |
|---|---|---|---|
| 目标 | 学习语言、知识、通用能力 | 对齐人类意图,适配对话 / 任务 | 对齐人类偏好 ,优化有用性、诚实性、无害性 |
| 数据 | 海量无标注纯文本 | 少量高质量标注对话 / 指令数据 | 人类对模型多个回答的偏好排序数据 |
| 数据量 | 极大(万亿 Token 级别) | 较小(百万~亿级) | 更小(万~十万级偏好对) |
| 训练成本 | 极高(卡量、时间、电费) | 低很多,单卡 / 小集群即可 | 较高,需训练奖励模型和PPO优化 |
| 模型输出 | 续写文本,不一定听话 | 按指令回答,更像助手 | 输出更符合人类口味,更安全、更有帮助 |
| 阶段顺序 | 第一步 | 第二步(在 Pre-Train 之后) | 第三步(在 SFT 之后) |
| 典型结果 | 基座模型(base) | 对话模型(chat/instruct) | 对齐模型(aligned) |
1. 预训练(Pre-training)
用海量无标注文本(网页、书籍、百科等)训练基座模型,让模型学会语言规律、世界知识、逻辑推理。最终产出:Base Model / 基座模型(如 LLaMA、Qwen Base)。
- 定位:规模最大、成本最高的基座构建阶段
- 任务 :自监督学习,预测文本下一个 Token,学习语言规律与世界知识。例如,给定句子"苹果很美味,我每天都吃一个__",模型会学习预测出"苹果"这个词。
- 数据:互联网文本、书籍、论文、代码等数万亿 Token 级未标注数据
- 资源:数千 GPU/TPU 集群,耗时数月,成本数百万至千万美元
- 成果 :得到具备语法、常识与基础推理能力的基座模型,但不会对话、不遵循指令
训练目标为:
p(x1,x2,...,xT)=∏t=1Tp(xt∣x1,...,xt−1) p(x_1,x_2,...,x_T) = \prod_{t=1}^T p(x_t \mid x_1,...,x_{t-1}) p(x1,x2,...,xT)=t=1∏Tp(xt∣x1,...,xt−1)
2. 监督微调(SFT)
用高质量问答对(指令 + 回答)微调基座模型,让模型学会遵循指令、对话、写作等任务范式。
- 定位:从"知识学霸"转向"实用助手"
- 任务 :学习理解并按要求响应人类指令。例如,输入指令"请帮我写一个冒泡排序",模型学习输出正确的代码实现。
- 数据 :数万~数十万条人工高质量指令-回答对
- 成果:掌握对话格式与风格,可完成问答、摘要、翻译、代码生成等任务
训练目标如下,n前面的为用户指令,n后面的为模型要预测的结果。
p(xn,xn+1,...,xT)=∏t=1Tp(xt∣x1,...,xt−1) p(x_n,x_{n+1},...,x_T) = \prod_{t=1}^T p(x_t \mid x_1,...,x_{t-1}) p(xn,xn+1,...,xT)=t=1∏Tp(xt∣x1,...,xt−1)
3. 人类反馈强化学习(RLHF)
- 定位:与人类价值观对齐,实现"有用、诚实、无害"
- 流程 :
- 人类对模型多轮回答进行偏好排序
- 用排序数据训练奖励模型,学习人类偏好
- 通过 PPO 等强化学习算法优化主模型,最大化奖励分数
- 成果:输出更贴合人类偏好、更安全可靠
1.2 关键配套环节
-
数据准备
训练前对原始数据清洗、去重、过滤有害信息、标准化处理。
-
评估与测试
通过 MMLU、HumanEval 等学术基准及红队攻击,全面检验性能、安全性与可靠性。
-
部署优化
采用量化、剪枝、知识蒸馏等技术压缩模型,降低推理成本,提升运行效率。
2、pre-train与sft有什么区别
预训练(Pre-training)和监督微调(SFT)是大型语言模型(LLM)训练中两个截然不同但又紧密相连的核心阶段。它们的主要区别体现在训练目的、数据、方法等多个方面。
简单来说,预训练是"博闻强识"的奠基阶段,而SFT是"学以致用"的转化阶段。
2.1 核心区别对比
预训练 就像让一个学生阅读图书馆里所有的书。他因此变得知识渊博,掌握了语言和世界的规律,但他还不知道如何将这些知识用于解决具体问题或与人交流。
监督微调 (SFT) 则像是为这个学生安排了一系列练习题和模拟考试。通过练习"如何回答问题"、"如何写摘要"、"如何翻译句子",他学会了如何运用自己庞大的知识库来满足特定的要求,成为一个能解决实际问题的专家。
| 对比维度 | 预训练 (Pre-training) | 监督微调 (SFT) |
|---|---|---|
| 核心目标 | 学习语言的底层规律、世界常识和通用知识,构建"基座模型"。 | 教会模型理解并遵循人类指令,将通用能力转化为特定任务能力。 |
| 学习方式 | 自监督学习:模型自己从数据中学习规律,例如预测下一个词。 | 监督学习:使用人工标注的"指令-回答"对进行训练。 |
| 数据特点 | 海量无标注:万亿级别的网页、书籍、代码等原始文本。 | 少量高质量:数万至百万级别精心编写的"指令-回答"对。 |
| 数据格式 | 连续的文本片段,通常被填充到固定长度(如4K, 8K)。 | 结构化的对话格式,包含system、user、assistant等角色标记。 |
| 计算成本 | 极高:需要数千GPU/TPU集群训练数月,成本巨大。 | 相对较低:可以在更少的计算资源上完成,尤其是使用LoRA等高效微调技术时。 |
2.2 预训练(Pre-train)
预训练阶段的目标是让模型成为一个"万事通"。但其训练任务,就像一个人从出生到大学毕业,疯狂看书、学知识、学说话逻辑,但不会主动帮你做事,你问它问题它可能乱写、续写、答非所问。
- 任务:模型通过"自监督"的方式学习,最常见的任务是"下一个词预测"。给定上文,模型需要预测出下一个最可能出现的词。这个过程让它学会了语法、事实知识(如"巴黎是法国的首都")和一定的逻辑推理能力。
- 成果:得到一个"基座模型"(Base Model)。这个模型知识渊博,但它并不知道如何与人对话或回答问题,它只会做一件事------根据上文续写文本。
2.3 监督微调 (SFT)
SFT阶段的目标是将"基座模型"转化为一个有用的"助手"。就像毕业后做岗前培训,给它看大量 "问题→标准答案" 案例,让它学会:听懂指令、只回答问题不瞎编、保持对话格式、更有用、更安全
- 任务:使用精心准备的"指令-回答"对来训练模型。例如,输入指令"请总结这篇文章",并提供一个高质量的总结作为标准答案。模型通过学习这些示例,掌握如何响应用户的需求。
- 关键技巧 :
- 角色标记 (Special Tokens) :引入如
<|user|>、<|assistant|>等特殊标记,明确区分对话中的不同角色,让模型理解对话的结构。 - 损失函数掩码 (Loss Masking):在计算损失时,通常只对模型的"回答"部分计算,而忽略"指令"部分。这迫使模型专注于学习如何生成正确的回答,而不是去记忆指令本身。
- 角色标记 (Special Tokens) :引入如
- 成果:得到一个"指令微调模型"(Instruction-Tuned Model),它能够理解并遵循指令,可以进行对话、问答、翻译等,更像一个我们能与之交互的AI助手。
3、数据构造差异
在大型语言模型(LLM)的训练中,预训练(Pre-training)和监督微调(SFT)在数据构造(data-target)和损失(Loss)计算上存在根本性的差异。这些差异直接服务于它们各自不同的训练目标。
核心区别在于:预训练希望模型学会预测序列中的所有词,而SFT则希望模型只学会生成助手的回答部分。
3.1 teacher forcing
在大型语言模型(LLM)的预训练(Pre-training)阶段,Teacher Forcing(教师强制) 是一种核心的训练技术。简单来说,它是一种"作弊"但高效的训练策略,旨在加速模型的收敛过程。
它的核心思想是:在训练时,模型总是使用"真实的前一个词"来预测"下一个词",而不是使用自己"预测出的前一个词"。
🚀 Teacher Forcing 如何工作?
Teacher Forcing在训练阶段,无论模型在上一步预测得是否正确,都会直接把训练数据中真实的下一个词 喂给它作为输入。
例子:
- 输入: "今天天气真"
- 模型预测: "不错"
- 计算损失: 将"不错"与真实标签"不错"比较,计算损失。
- 下一步输入 (关键步骤) : 无论上一步预测结果如何,直接从训练数据中取出真实序列,将"今天天气真不错"作为新的输入,去预测下一个词"很"。
通过这种方式,模型在每一步的学习都站在"正确答案"的肩膀上,避免了误差累积,使得训练过程更快、更稳定。
py
text = "大语言模型是..."
text=tokenizer(text)
input_ids = text[:-1]
labels = text[1:]
loss = cross_entropy(input_ids, labels) # 全部算⚙️ 技术实现:并行化与损失计算
Teacher Forcing 不仅是理论上的策略,它在工程实现上带来了巨大的效率提升,主要体现在以下两个方面:
-
并行计算
由于训练时模型的每一步输入都是已知的真实数据,而不是依赖于上一步的预测结果,因此整个序列的计算可以并行化。
- 训练时 (Teacher Forcing): 模型可以一次性处理整个句子。例如,对于句子"A B C D",基于三角形mask,模型可以同时计算:
- 用 "A" 预测 "B"
- 用 "A B" 预测 "C"
- 用 "A B C" 预测 "D"
这使得GPU的利用率极高,训练速度非常快。
- 推理时 (自回归): 模型必须一个词一个词地生成,无法并行,因此速度较慢。
- 训练时 (Teacher Forcing): 模型可以一次性处理整个句子。例如,对于句子"A B C D",基于三角形mask,模型可以同时计算:
-
损失函数中的"移位" (Shifting)
在代码层面(例如使用 Hugging Face 的
transformers库),Teacher Forcing 是通过移位来实现的。- 模型输入 (
input_ids) :[A, B, C] - 预测目标 (
labels) :[B, C, D]
模型会一次性接收[A, B, C],并输出对应位置的预测 logits。然后,损失函数会将这些 logits 与"移位"后的目标[B, C, D]进行比较,计算交叉熵损失。这个过程精确地实现了"用前一个真实词预测下一个真实词"的 Teacher Forcing 机制。
- 模型输入 (
Teacher Forcing引发的训练推理不一致问题,如何解决
训练时(Teacher Forcing)
输入永远是干净的真实前缀:
x1 → x2 → x3 → x4 → ...模型永远不会看到自己的错误。
推理时(Free Running)
输入是模型自己生成的:
x1 → x2_hat → x3_hat → x4_hat → ...一旦某一步生成错,后面会一路错到底。
解决策略
① 模型足够大 + 数据足够多(最有效)
千亿级参数量 + 海量文本
模型学会极强的上下文纠错能力
即使前面错了,也能拉回来。
这是 GPT、Llama 系列最核心解决方案。
② 训练时加入噪声(Masked Language Modeling 思想)
类似 T5、BERT 做法:
随机把一些 token 替换成其他词
让模型学会从被污染的上下文继续生成
纯 decoder 模型也会在数据层面加入噪声增强。
③ 长度控制 + 束搜索 Beam Search / 采样策略
推理时用:
- top-k / top-p / temperature
- beam search
减少单步错误带来的雪崩。
④ SFT + DPO/RLHF
让模型学会:
- 更稳定生成
- 更少胡说
- 更符合人类分布
从而减少单步错误概率。
3.2 预训练 (Pre-training)
预训练的目标是让模型掌握语言的通用模式,因此它需要学习预测文本中的每一个词。
数据构造
预训练的数据通常是海量的、非结构化的纯文本。在构造训练样本时,一段长文本会被直接分词(Tokenize)成一系列连续的 input_ids。
- 输入 (Input): 整个文本序列。
- 目标 (Target): 模型的目标是预测序列中的下一个词。对于一个长度为
L的序列[t₀, t₁, ..., tₗ₋₁]:- 模型输入:
[t₀, t₁, ..., tₗ₋₁,tₗ] - 预测目标 (Labels):
[t₁, t₂, ..., tₗ,EOS]
这通常通过在代码中将input_ids右移一位来实现,即labels = input_ids[1:]。对于输入的最后一个字符,则对应到终止符。
- 模型输入:
Loss 计算方式
在预训练中,损失函数(通常是交叉熵损失)会在所有有效的预测位置上进行计算。对于t个输入,
- Loss Mask: 这是一个与序列等长的掩码向量,用于指示哪些位置的词需要参与损失计算。对于预训练,除了用于填充(padding)的位置外,几乎所有位置的
loss_mask都为 1。 - 计算过程: 模型会对输入序列中的每一个词(除了最后一个)计算预测下一个词的概率,并与真实的目标词进行比较。最终的损失是所有这些位置损失的平均值。
- 目的: 最大化整个文本序列的似然概率,鼓励模型对任意位置的下一个词都能做出准确预测。
3.3 监督微调 (SFT)
SFT的目标是教会模型遵循指令,因此它只需要学习如何生成高质量的回答,而不需要学习预测用户的指令。
数据构造
SFT的数据是结构化的"指令-回答"对或多轮对话。在构造时,会使用特定的聊天模板(Chat Template)将对话拼接成一个完整的序列,并加入特殊标记来区分角色(如 <|user|>, <|assistant|>)。
例如,一个单轮对话 {"conversations": [{"role": "user", "content": "你好"}, {"role": "assistant", "content": "你好!有什么可以帮助你的吗?"}]} 会被处理成类似这样的序列:
<|user|> 你好 <|im_end|> <|assistant|> 你好!有什么可以帮助你的吗? <|im_end|>
- 输入 (Input): 完整的、经过模板拼接的对话序列。
- 目标 (Target): 只有"助手"(assistant)回答的部分是预测目标。
3.3 Loss 计算方式
SFT的损失计算是有选择性的,只对"助手"回答部分的token计算损失,而"用户"指令和特殊标记部分则被忽略。
-
Loss Mask (关键区别): 这是SFT与预训练最核心的实现差异。
- 定位回答区间: 首先,通过解析特殊标记(如
<|assistant|>),精确地找到助手的回答在序列中的起始和结束位置。 - 构造掩码: 创建一个
loss_mask,在助手回答对应的**目标词(labels)**位置上设置为 1,在用户指令和其他位置设置为 -100(或一个被忽略的索引值)。 - 对齐预测位置: 由于模型是用位置
t的输出来预测位置t+1的词,所以loss_mask需要与模型的预测位置对齐。这意味着,如果助手回答的目标词在索引[s, e],那么loss_mask应该在预测索引[s-1, e-1]上为 1。
- 定位回答区间: 首先,通过解析特殊标记(如
-
计算过程: 在计算总损失时,只有
loss_mask为 1 的位置的损失会被累加和平均。模型在"用户"部分的预测误差不会被计算,从而不会更新模型参数。 -
目的: 强制模型学习在给定指令(作为条件)的情况下,生成符合人类期望的回答,而不是学习预测指令本身。
4、loss计算
在大型语言模型(LLM)的训练中,损失(Loss)的计算、以及数据(Data)与标签(Label)的构造,是模型学习的核心机制。整个过程围绕着一个核心思想:通过"移位"(Shift)来构造标签,并使用交叉熵(Cross-Entropy)来计算损失。
4.1 核心原理:下一个词预测
LLM训练的基本任务是"下一个词预测"(Next-Token Prediction)。
P(wt∣w1,w2,...,wt−1)P(w_t | w_1,w_2,...,w_{t-1})P(wt∣w1,w2,...,wt−1)
给定一个token序列,模型的目标是根据前面的词预测出下一个词。
例如,对于句子 "我 喜欢 吃 苹果",模型的训练方式是:
- 看到 "我",预测 "喜欢"
模型这一步预测结果不一定正确 - 看到 "我 喜欢",预测 "吃"
即使模型在上一步预测错了,也会强制使用正确的target预测下一个词,这就是teacher forcing - 看到 "我 喜欢 吃",预测 "苹果"
4.2 Data与Label的构造:移位操作
虽然核心计算方式相同,但在不同的训练阶段,我们计算损失的位置是不同的。这通过一个"损失掩码"(Loss Mask)来控制。
预训练 (Pre-training)
- 目标: 让模型学会预测序列中的所有词。
- Loss Mask : 除了用于填充(padding)的位置,序列中几乎所有有效预测位置的
loss_mask都为 1。这意味着模型需要对整个文本序列的下一个词预测负责。
训练数据是自然预料,input 和 label 直接错位一位:
input_ids: 大 语 言 模 型 很 强
labels: 语 言 模 型 很 强 大所有真实 token 都计算 loss,只有 padding 部分设为 -100
伪代码如下
py
text = "大语言模型正在改变世界"
input_ids = tokenizer(text, return_tensors="pt")["input_ids"]
# label = input 直接错位
labels = input_ids.clone()
# 计算 loss(模型自动处理错位)
outputs = model(input_ids, labels=labels)
loss = outputs.loss监督微调 (SFT)
- 目标: 让模型只学习如何生成高质量的回答。
- Loss Mask : 这是与预训练的关键区别。
loss_mask只在"助手"(assistant)回答部分的对应位置上为 1,而在"用户"(user)指令部分为 0(或在计算中被忽略的-100)。 - 构造方式 :
- 首先,通过特殊标记(如
<|assistant|>)定位回答的起始和结束位置。 - 然后,构造
loss_mask,使其在助手回答对应的**目标词(labels)**位置上为 1。 - 由于模型的预测是"用前一个词预测后一个词",所以
loss_mask需要与模型的预测位置 对齐。这意味着,如果助手回答的目标词在索引[s, e],那么loss_mask应该在预测索引[s-1, e-1]上为 1。
- 首先,通过特殊标记(如
必须是 指令 + 回答 格式:
用户:你好 助手:你好呀!我是助手input 不变,但 label 要把指令部分变成 -100!
最终序列:
用户:你好 助手:你好呀!我是助手
用户指令[MASK掉] 助手回答 [计算Loss]Label 最终长成这样
input_ids: 用户:你好 助手:你好呀!我是助手
labels: -100 -100 -100 你 好 呀 ! 我 是 助 手伪代码如下
python
# 构造指令对话
prompt = "用户:介绍AI 助手:AI是人工智能技术"
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"]
# 构造 label:指令部分设为 -100
labels = input_ids.clone()
# 假设指令长度是 6 个 token
labels[:, :6] = -100 # 指令不参与 Loss
# 训练
outputs = model(input_ids, labels=labels)
loss = outputs.loss4.3 Loss计算流程:交叉熵
一旦有了输入和标签,就可以计算损失了。这个过程可以分为四步:
-
模型前向传播 :
模型接收
input_ids(形状为[batch_size, seq_len]),并输出每个位置的 logits。Logits 是一个未归一化的得分向量,代表模型预测下一个词是词表中任何一个词的可能性。
logits = model(input_ids)
logits的形状为[batch_size, seq_len, vocab_size]。 -
维度展平 (Flatten) :
为了方便计算,通常会将
logits和labels展平。logits从[batch_size, seq_len, vocab_size]变为[batch_size * seq_len, vocab_size]labels从[batch_size, seq_len]变为[batch_size * seq_len]
这相当于把批次中所有序列的所有预测位置都排成一列,一次性计算损失。
-
计算交叉熵损失 (Cross-Entropy Loss) :
交叉熵损失函数会衡量模型预测的概率分布(由
logits经过 Softmax 得到)与真实分布(由labels表示的独热编码)之间的差异。在 PyTorch 等框架中,可以直接调用
CrossEntropyLoss函数。这个函数内部会自动对logits进行 Softmax,然后计算负对数似然(Negative Log-Likelihood, NLL)。
loss = CrossEntropyLoss(logits_flat, labels_flat) -
处理序列末尾 :
一个长度为
L的序列,只有前L-1个位置能产生有效的预测(这里是假设最后一个字符为结束符 )。最后一个位置的输出没有对应的"下一个词"作为标签,因此在计算损失时会被忽略。在代码实现中,这通常通过对logits和labels进行切片来实现,例如logits[..., :-1, :]和labels[..., 1:],确保两者对齐。
L=−1N∑t=1NlogP(yt=wt∣x1:t−1) \mathcal{L} = -\frac{1}{N} \sum_{t=1}^N \log P(y_t = w_t | x_{1:t-1}) L=−N1t=1∑NlogP(yt=wt∣x1:t−1)
5、训练时数据处理
不同文本长度不一样,无法拼成一个矩阵(batch) 送入 GPU:形状不同 → 不能直接训练。
文本1:我 爱 学 习 (长度4)
文本2:你 好 (长度2)处理长度不一的数据是一个关键的工程问题。核心挑战在于,GPU为了高效并行计算,要求同一个批次(Batch)内的数据必须是长度统一的张量(Tensor)。
针对这个问题,业界主要有两种处理思路:传统的填充与截断(Padding & Truncation) ,以及更高效的序列打包(Sequence Packing)。
5.1 传统方法:填充与截断 (Padding & Truncation)
这是最基础且直观的方法,通过将所有序列强制对齐到同一个固定长度来满足模型输入要求。
其中Dynamic Padding,适用于SFT阶段。
1. 截断 (Truncation)
当文本序列的长度超过了预设的最大长度(max_length)时,就需要进行截断。
- 策略 :
- 尾部截断 (Truncate from Tail):保留文本的开头部分,丢弃末尾。这是最常见的策略,因为文本的核心信息通常在开头。
- 头部截断 (Truncate from Head):保留文本的末尾部分,丢弃开头。适用于对话历史等场景,因为最近的对话内容更重要。
- 缺点:会直接导致信息丢失,被截断的文本内容无法被模型学习。
2. 填充 (Padding)
当文本序列的长度短于预设的 max_length 时,就需要进行填充。
- 策略 :使用一个特殊的
[PAD]标记(Token)将所有数据统一补到max_seq_len(如 512 / 2048)。 - 关键处理 - 注意力掩码 (Attention Mask) :为了让模型忽略这些无意义的
[PAD]标记,会引入一个与输入序列等长的"注意力掩码"。掩码中,真实文本对应的位置为1,[PAD]标记对应的位置为0。模型在计算注意力时会乘以这个掩码,从而确保[PAD]标记不影响计算结果。 - 缺点 :造成了巨大的计算资源浪费。如果一个批次内大部分是短文本,那么GPU的大部分算力都耗费在了计算
[PAD]标记上,导致训练效率低下。 - 优化方案:Dynamic Padding,每个 batch 内部补到当前 batch 的最长句子。【省显存】【训练更快】【训练框架默认首选】
具体示意如下
A: 我 爱 自 然 [PAD] [PAD] [PAD] [PAD]
B: 今 天 天 气 好 [PAD] [PAD] [PAD]
C: 人 工 智 能 [PAD] [PAD] [PAD] [PAD]5.2 高效方法:序列打包 (Sequence Packing)
为了解决填充带来的计算浪费和截断带来的信息丢失,序列打包 (也称 Document Packing)已成为现代LLM训练(如LLaMA-3)的主流选择。适用在基模预训练阶段。
核心思想
将多个短的文档(Document)"打包"拼接成一个完整的、长度为 max_length 的长序列。这样既能填满整个序列,避免了填充,又能保留每个短文档的完整信息,避免了截断。
例如,如果 max_length 是 2048,我们可以把一个长度为 500 的文档A、一个长度为 800 的文档B和一个长度为 700 的文档C拼接在一起,形成一个完美的 2048 长度的训练样本。
具体拼接示意如下:
py
[样本A][EOS][样本B][EOS][样本C][EOS][PAD...]Attention 的mask示意如下
┌─────────────── Pack ───────────────┐
│ [A A A A] [EOS] [B B B B] [EOS] [C C] │
└───────────────────────────────────┘
A区域注意力范围:
● ● ● ● ○ ○ ○ ○ ○ ○ ○ ○
B区域注意力范围:
○ ○ ○ ○ ○ ● ● ● ● ○ ○ ○
C区域注意力范围:
○ ○ ○ ○ ○ ○ ○ ○ ○ ○ ● ●关键技术细节
打包并非简单的拼接,它需要两个关键技术来保证模型正确学习:
-
分隔符 (Separator Token)
在拼接不同文档时,会插入一个特殊的分隔符(如
[SEP]),明确告知模型一个文档的结束和另一个文档的开始。物理上:它们在一个张量里,比如 A...AB...BC...C。
逻辑上:模型必须认为 A 的结尾和 B 的开头毫无关系。
-
跨文档注意力掩码 (Cross-Document Attention Mask)
这是打包技术的精髓。我们需要修改注意力机制,确保模型只能关注同一个文档内的词元(Token),而不能跨越文档边界去关注其他文档的内容。
- 实现方式:通过一个精心设计的二维注意力掩码来实现。在这个掩码中,只有属于同一个文档的词元对之间才是可见的(值为1),不同文档的词元对之间是隔离的(值为0)。
-
损失计算掩码 (Loss Masking)
在计算损失(Loss)时,也需要特殊处理。模型不应学习"根据文档A的结尾预测文档B的开头"这种无意义的任务。
- 实现方式 :在构造标签(Labels)时,将每个文档的第一个词 以及所有分隔符对应的预测位置的损失设为忽略(例如,在PyTorch中设为-100)。这样,损失函数就只会在每个文档的内部进行计算,保证了学习任务的有效性。
- 位置索引 为每个子样本维护独立的 position_ids(位置索引);样本 A:位置索引为 0, 1, 2, 3、样本 B:位置索引重置为 0, 1;packing后的position_ids 是:0, 1, 2, 3, 0, 1
-
ROPE位置
每个样本从 0 重新开始!
py
Pack 序列:
A0 A1 A2 A3 EOS B0 B1 B2 B3 EOS C0 C1
ROPE 位置:
0 1 2 3 (A独立)
0 1 2 3 (B独立)
0 1 (C独立)打包算法
如何高效地将成千上万个不同长度的文档打包成尽可能少、填充也尽可能少的序列,是一个经典的"装箱问题"(Bin Packing Problem)。实践中常采用一些高效的近似算法,例如:
- 首次适应递减算法 (First-Fit Decreasing, FFD):先将所有文档按长度从大到小排序,然后依次将每个文档放入第一个能容纳它的"箱子"(即训练序列)中,如果都放不下就开一个新箱子。
- 最佳适应递减算法 (Best-Fit Decreasing, BFD):与FFD类似,但它会将文档放入能容纳它且剩余空间最小的"箱子"里,使得打包结果更加紧凑。
总而言之,虽然填充与截断是实现简单的基础方法,但序列打包通过更智能的数据组织方式,在保留全部信息的同时极大地提升了训练效率,是当前大规模LLM训练的首选方案。