从"检索一次就完事"到"Agent 自主决策":Agentic RAG 架构深度解析与实战
你的 RAG 系统是不是也经常答非所问?问一个稍微复杂点的问题就开始胡说八道?别急,这篇文章带你从根上理解为什么传统 RAG 不够用,以及 Agentic RAG 是怎么解决这些问题的。
一、先说痛点:传统 RAG 到底哪里不行?
我在项目中用 RAG 做企业知识库问答已经快两年了。最开始觉得 RAG 简直是银弹------把文档切块、向量化、存进 Milvus,用户一问就检索 Top-K,拼进 Prompt 让大模型回答。上线第一周,老板都夸"这个 AI 真聪明"。
然后现实就来打脸了。
痛点 1:一次检索根本不够用
用户问:"我们公司 2024 年 Q3 的营收和 Q2 相比增长了多少?增长的主要原因是什么?"
传统 RAG 的做法是把这个问题向量化,检索一次,拿到 Top-5 的文档块。问题是,Q3 营收数据和 Q2 营收数据大概率不在同一个文档块里,增长原因分析可能在第三个文档里。一次检索,能命中其中一个就不错了。
痛点 2:检索到了垃圾也照用不误
传统 RAG 没有"质量判断"能力。检索回来 5 个文档块,哪怕其中 3 个完全不相关,它也会一股脑塞进 Prompt。结果就是大模型被噪声干扰,输出质量直线下降。
痛点 3:不会变通,死脑筋
用户的问题表述可能不精确,比如"那个什么隐身模式怎么开"。传统 RAG 直接拿这句话去检索,大概率什么都检索不到。它不会想到"哦,用户说的可能是 invisible mode,我换个关键词试试"。
痛点 4:单一数据源的局限
真实业务场景中,答案往往分散在多个数据源------内部文档、数据库、API 接口、甚至需要实时搜索。传统 RAG 只认一个向量库,其他数据源?不存在的。
这些痛点的根源在于:传统 RAG 是一个线性管道(Pipeline),而不是一个能思考的系统。
二、Agentic RAG 是什么?为什么它能解决这些问题?
2.1 核心思想:让 Agent 来掌控检索过程
Agentic RAG 的核心思想其实很简单:把一个能推理、能决策的 AI Agent 放到 RAG 管道的中心,让它来决定什么时候检索、检索什么、检索结果好不好、要不要重新检索。
传统 RAG 是"流水线工人"------接到任务就按固定流程走,不管结果好不好。Agentic RAG 是"项目经理"------它会分析任务、制定计划、分配子任务、检查结果质量、不满意就返工。
用一句话总结两者的区别:
传统 RAG:检索是一个预处理步骤 ,执行一次就结束。 Agentic RAG:检索是一个可控的行为,嵌入在推理循环中,可以反复执行和调整。
2.2 架构对比
下面这张图清晰地展示了两种架构的差异:
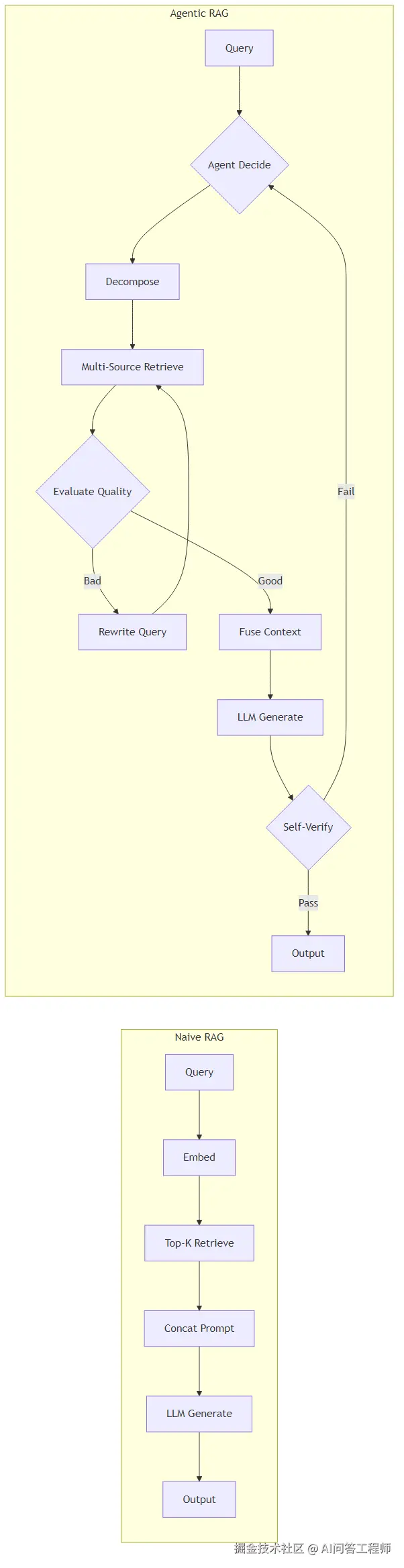
传统 RAG 是一条直线:查询 → 向量化 → 检索 → 拼接 → 生成 → 输出。没有分支,没有循环,没有判断。
Agentic RAG 是一个带反馈循环的控制流:Agent 在每一步都会做决策------要不要检索?检索结果够不够好?需不需要换个方式重新检索?生成的回答质量过关吗?
2.3 Agentic RAG 的四大核心能力
能力 1:查询规划与分解(Query Planning)
Agent 拿到用户问题后,不是直接去检索,而是先分析这个问题需要哪些信息,然后把它分解成多个子查询。
比如用户问:"对比 React 和 Vue 在大型项目中的状态管理方案,哪个更适合我们的电商项目?"
Agent 会分解为:
- 子查询 1:React 大型项目状态管理方案有哪些?(Redux、Zustand、Jotai...)
- 子查询 2:Vue 大型项目状态管理方案有哪些?(Pinia、Vuex...)
- 子查询 3:电商项目的状态管理有什么特殊需求?
- 子查询 4:两者在性能、学习曲线、生态方面的对比数据
每个子查询独立检索,最后汇总。这就是为什么 Agentic RAG 能回答复杂的多跳问题。
能力 2:检索质量评估(Relevance Grading)
每次检索回来的文档,Agent 都会做一次"相关性打分"。不相关的直接丢掉,相关但不够的触发重新检索。
这一步至关重要。根据 IEEE Computer Society 发表的研究,在多跳问题上,传统 RAG 的准确率只有约 42%,而 Agentic RAG 可以达到 94.5%。差距的核心就在于:Agent 能判断检索结果的质量,并在不够好的时候主动采取行动。
能力 3:多工具协同(Tool Integration)
Agent 不只是能查向量库。它可以调用多种工具:
- 向量数据库(语义检索)
- 关键词搜索引擎(精确匹配)
- 知识图谱(关系推理)
- SQL 数据库(结构化查询)
- Web 搜索 API(实时信息)
- 计算器(数值计算)
Agent 会根据问题类型选择合适的工具组合。问"2024 年营收是多少"用 SQL 查数据库,问"营收增长的原因"用向量检索查分析报告,问"竞品最新动态"用 Web 搜索。
能力 4:记忆管理(Memory Management)
Agent 有两种记忆:
- 短期记忆:当前对话的上下文、已经检索过的内容、推理过程中的中间结果
- 长期记忆:跨会话的知识积累,比如用户偏好、常见问题的答案缓存
这让 Agent 能在多轮对话中保持连贯性,不会每次都从零开始。
三、核心原理深度解析
3.1 ReAct 框架:推理与行动的交替循环
Agentic RAG 最核心的设计模式是 ReAct(Reasoning + Acting)。这个框架由 Yao et al. 在 2022 年提出,核心思想是让 LLM 交替进行"思考"和"行动"。
一个 ReAct 循环长这样:
vbnet
Thought: 用户问的是对比两个框架,我需要分别检索两个框架的信息
Action: search("React state management large project")
Observation: [检索到 Redux Toolkit, Zustand 相关文档]
Thought: React 的信息够了,现在需要 Vue 的
Action: search("Vue state management large project")
Observation: [检索到 Pinia, Vuex 相关文档]
Thought: 两边信息都有了,但缺少性能对比数据
Action: search("React vs Vue state management performance benchmark")
Observation: [检索到基准测试数据]
Thought: 信息足够了,可以生成对比分析
Action: generate_answer(context=[...])每一步 Agent 都在"想"------我现在有什么信息?还缺什么?下一步该做什么?这就是传统 RAG 完全不具备的能力。
3.2 Agent 控制流的伪代码实现
下面这段伪代码展示了 Agentic RAG 的核心控制循环:
python
class AgenticRAG:
def answer(self, query: str) -> str:
# Agent 维护内部状态
state = {"query": query, "context": [], "attempts": 0}
while not self.is_task_complete(state):
# 1. 推理:分析当前状态,决定下一步
thought = self.reason(state)
# 2. 规划:选择要执行的动作
action = self.plan(thought)
# 3. 执行:调用工具或检索
result = self.act(action)
# 4. 观察:评估执行结果
self.observe(result, state)
# 5. 更新状态
self.update_state(state, result)
# 生成最终回答
return self.generate(state["context"])这个循环的关键在于 is_task_complete 的判断------Agent 会持续循环直到它认为收集到了足够的信息。这和传统 RAG 的"检索一次就完事"形成了鲜明对比。
3.3 查询路由:让问题找到正确的数据源
Agentic RAG 中一个非常重要的组件是查询路由器(Query Router)。它负责判断每个查询应该发往哪个数据源。
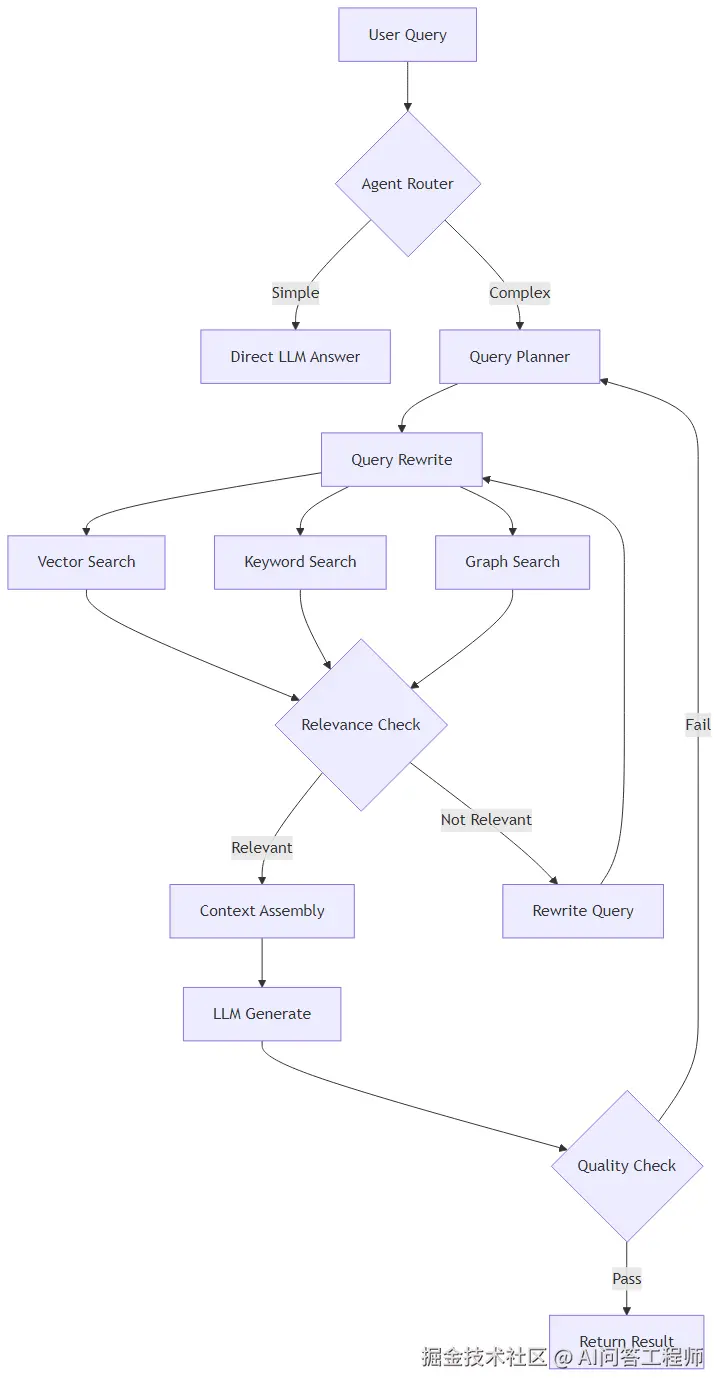
路由决策通常基于以下因素:
| 查询特征 | 路由目标 | 示例 |
|---|---|---|
| 需要精确数值 | SQL 数据库 | "Q3 营收是多少" |
| 需要语义理解 | 向量数据库 | "用户流失的原因分析" |
| 需要实时信息 | Web 搜索 | "竞品最新发布了什么" |
| 需要关系推理 | 知识图谱 | "A 部门和 B 项目的关联" |
| 简单常识问题 | 直接 LLM | "什么是 RESTful API" |
路由器本身也是一个 LLM 调用,通过 Prompt 让模型判断查询类型并选择数据源。
3.4 自纠正机制:检索不好就重来
这是 Agentic RAG 最有价值的特性之一。传统 RAG 检索到什么就用什么,Agentic RAG 会对检索结果做质量评估,不合格就触发纠正流程。
纠正策略有三种:
策略 1:查询重写(Query Rewriting)
如果检索结果不相关,Agent 会分析原因并重写查询。比如原始查询"那个隐身功能"检索不到结果,Agent 会重写为"invisible mode feature"或"用户隐身模式设置"。
策略 2:退化到 Web 搜索(Fallback to Web Search)
如果本地知识库确实没有相关信息,Agent 会判断是否需要从外部获取,然后调用 Web 搜索 API。
策略 3:承认不知道(Graceful Degradation)
如果多次重试后仍然找不到可靠信息,Agent 会诚实地告诉用户"我没有找到足够的信息来回答这个问题",而不是编造答案。这比传统 RAG 的"自信地胡说八道"好太多了。
3.5 从 Naive RAG 到 Agentic RAG 的演进路径
RAG 技术的演进可以分为四个阶段:
| 阶段 | 名称 | 特点 | 典型问题 |
|---|---|---|---|
| 第一代 | Naive RAG | 单次检索 + 生成 | 检索质量差、无法处理复杂问题 |
| 第二代 | Advanced RAG | 查询改写 + 重排序 + 混合检索 | 仍是线性管道,无反馈循环 |
| 第三代 | Modular RAG | 模块化设计,可插拔组件 | 模块间缺乏智能协调 |
| 第四代 | Agentic RAG | Agent 驱动,自主决策,反馈循环 | 延迟增加、调试复杂 |
每一代都在解决上一代的核心问题。Agentic RAG 不是要替代前面的技术,而是在它们的基础上加了一个"大脑"。
四、方案对比:什么时候该用 Agentic RAG?
不是所有场景都需要 Agentic RAG。过度设计和设计不足一样有害。
| 维度 | Naive RAG | Advanced RAG | Agentic RAG |
|---|---|---|---|
| 适用场景 | 简单 FAQ、单文档问答 | 企业知识库、文档搜索 | 多源复杂问答、研究分析 |
| 检索策略 | 单次 Top-K | 混合检索 + 重排序 | 多轮自适应检索 |
| 延迟 | 低(1-2s) | 中(2-5s) | 高(5-30s) |
| 准确率(多跳问题) | ~42% | ~65% | ~94% |
| 实现复杂度 | 低 | 中 | 高 |
| Token 消耗 | 低 | 中 | 高(3-10x) |
| 可解释性 | 差 | 中 | 好(有推理链) |
| 调试难度 | 简单 | 中等 | 复杂(需要 trace) |
我的建议:
- 如果你的场景是简单的文档问答,Naive RAG 就够了,别过度设计
- 如果需要处理企业级知识库,Advanced RAG(加上重排序和混合检索)是性价比最高的选择
- 如果你的用户会问复杂的多跳问题、需要跨多个数据源、或者对准确率要求极高,那就上 Agentic RAG
五、实战代码:用 LangGraph 构建 Agentic RAG
下面用 LangGraph 实现一个完整的 Agentic RAG 系统。LangGraph 是 LangChain 团队推出的 Agent 编排框架,用状态图(State Graph)来管理 Agent 的控制流,非常适合构建 Agentic RAG。
5.1 定义状态和节点
python
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
class RAGState(TypedDict):
query: str # 原始查询
sub_queries: List[str] # 分解后的子查询
documents: List[dict] # 检索到的文档
generation: str # 生成的回答
retry_count: int # 重试次数
def route_query(state: RAGState) -> str:
"""Agent 路由:判断查询类型,决定走哪条路"""
query = state["query"]
# 用 LLM 判断查询是否需要检索
response = llm.invoke(
f"判断这个问题是否需要检索外部知识库才能回答:{query}\n"
f"回答 'retrieve' 或 'direct'"
)
return "retrieve" if "retrieve" in response.lower() else "direct"这段代码定义了 Agent 的状态结构和路由逻辑。route_query 是第一个决策点------Agent 判断这个问题是否需要检索,还是直接用 LLM 的内部知识就能回答。
5.2 实现检索和质量评估
python
def retrieve(state: RAGState) -> RAGState:
"""多源检索:从向量库和关键词索引同时检索"""
query = state["query"]
# 向量检索
vector_docs = vector_store.similarity_search(query, k=3)
# 关键词检索(BM25)
keyword_docs = bm25_retriever.get_relevant_documents(query)
# 合并去重
all_docs = deduplicate(vector_docs + keyword_docs)
return {**state, "documents": all_docs}
def grade_documents(state: RAGState) -> str:
"""质量评估:判断检索结果是否相关"""
docs = state["documents"]
query = state["query"]
relevant_docs = []
for doc in docs:
score = llm.invoke(
f"判断以下文档是否与问题相关。\n"
f"问题:{query}\n文档:{doc['content'][:500]}\n"
f"回答 'relevant' 或 'irrelevant'"
)
if "relevant" in score.lower():
relevant_docs.append(doc)
state["documents"] = relevant_docs
# 决策:有足够相关文档就生成,否则重写查询
if len(relevant_docs) >= 2:
return "generate"
elif state["retry_count"] < 3:
return "rewrite"
else:
return "generate" # 重试次数用完,用现有信息生成grade_documents 是 Agentic RAG 的灵魂。它不是盲目地把所有检索结果塞给 LLM,而是逐个评估相关性,只保留真正有用的文档。如果相关文档不够,就触发查询重写。
5.3 组装状态图
python
def rewrite_query(state: RAGState) -> RAGState:
"""查询重写:让 LLM 优化查询表述"""
original = state["query"]
rewritten = llm.invoke(
f"原始查询检索效果不好,请重写以下查询,使其更精确:\n{original}"
)
return {**state, "query": rewritten, "retry_count": state["retry_count"] + 1}
def generate(state: RAGState) -> RAGState:
"""生成回答"""
context = "\n".join([d["content"] for d in state["documents"]])
answer = llm.invoke(
f"基于以下上下文回答问题。如果上下文不足以回答,请说明。\n"
f"上下文:{context}\n问题:{state['query']}"
)
return {**state, "generation": answer}
# 构建状态图
workflow = StateGraph(RAGState)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade", grade_documents)
workflow.add_node("rewrite", rewrite_query)
workflow.add_node("generate", generate)
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade")
workflow.add_conditional_edges("grade", grade_documents, {
"generate": "generate",
"rewrite": "rewrite",
})
workflow.add_edge("rewrite", "retrieve") # 重写后重新检索
workflow.add_edge("generate", END)
app = workflow.compile()整个流程形成了一个带反馈循环的状态图:检索 → 评估 → 不够好就重写 → 重新检索 → 再评估... 直到质量达标或重试次数用完。
六、踩坑经验和最佳实践
踩坑 1:Agent 陷入无限循环
我在第一个版本中没有设置重试上限,结果 Agent 对检索结果永远不满意,一直在重写查询和重新检索,Token 消耗飙升到天际。
解决方案 :必须设置 max_retries(我一般设 3 次),超过就用现有信息生成,或者诚实地说"信息不足"。
踩坑 2:质量评估的 LLM 调用太贵
每个文档都用 LLM 做相关性判断,5 个文档就是 5 次 LLM 调用。如果检索了 20 个文档,成本直接爆炸。
解决方案 :先用轻量级的 Cross-Encoder(比如 cross-encoder/ms-marco-MiniLM-L-6-v2)做初筛,只对 Top-3 用 LLM 做精细判断。成本降低 80%,效果几乎不变。
踩坑 3:查询重写越改越离谱
LLM 重写查询时,有时候会"过度发挥",把原始意图改没了。比如用户问"Python 怎么读 Excel",重写成了"Python data processing framework comparison"。
解决方案:重写时把原始查询也传进去,并在 Prompt 中强调"保持原始意图不变,只优化表述"。另外,保留原始查询作为 fallback。
踩坑 4:调试困难,不知道 Agent 在想什么
Agentic RAG 的调试比传统 RAG 难 10 倍。因为有循环和分支,你很难知道 Agent 在第几轮检索、为什么决定重写、重写后的查询是什么。
解决方案:必须加 trace 日志。推荐用 LangSmith 或 LangFuse 做全链路追踪,记录每一步的输入、输出、决策原因。没有 trace 的 Agentic RAG 就是在裸奔。
踩坑 5:延迟太高,用户等不了
Agentic RAG 的延迟是传统 RAG 的 3-10 倍。如果 Agent 重试了 3 次,每次检索 + 评估 + 重写需要 5 秒,总延迟就是 15 秒以上。
解决方案:
- 流式输出:先返回"正在为您查找...",然后逐步输出
- 并行检索:多个子查询同时发出,不要串行
- 缓存:对常见问题缓存 Agent 的决策路径和检索结果
- 分级策略:简单问题走 Naive RAG(快),复杂问题才走 Agentic RAG
最佳实践清单
- 先做好基础 RAG:Agentic RAG 是在好的基础 RAG 上加 Agent,如果你的分块策略、Embedding 模型、向量库都没调好,加 Agent 也救不了
- 设置合理的重试上限:3 次是个好的起点
- 用轻量模型做初筛:Cross-Encoder 比 LLM 便宜 100 倍
- 全链路追踪是必须的:LangSmith / LangFuse / Phoenix,选一个
- 渐进式升级:先 Naive → Advanced → Agentic,不要一步到位
- 监控 Token 消耗:Agentic RAG 的 Token 消耗波动很大,需要设置预算上限
七、总结
Agentic RAG 不是什么魔法,它的本质就是把一个能推理的 Agent 放到 RAG 管道中间,让它来做检索决策。这个简单的改变带来了质的飞跃------从"检索一次就完事"变成了"智能地、反复地、有策略地检索"。
但它也不是银弹。延迟增加、成本上升、调试复杂,这些都是真实的代价。关键是根据你的业务场景做出正确的选择:简单场景用 Naive RAG,复杂场景才上 Agentic RAG。
如果你正在做 RAG 系统,我建议你先把基础 RAG 做扎实(分块策略、Embedding 选型、混合检索),然后在此基础上逐步引入 Agent 能力。这比一上来就搞全套 Agentic RAG 靠谱得多。
有问题欢迎评论区讨论,特别是在生产环境中踩过的坑,大家一起交流 🤝
参考来源:
- IEEE Computer Society - Agentic RAG: Embedding Autonomous Agents into RAG
- Towards Data Science - Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop
- Meilisearch - 14 Types of RAG
- Beyond Scale - Agentic RAG: When Standard Retrieval Isn't Enough
- Educative - Agentic RAG: A Next Generation RAG Architecture
- arxiv - Is Agentic RAG worth it? An experimental comparison