一句话核心总结
本文提出 IIGN 任务与 VL-LN 基准,首次系统研究具备主动对话能力的具身导航智能体如何在房屋级长程环境中通过"主动提问"解决指令歧义、提升实例定位精度。arxiv
摘要(3.1)
关键概念与技术领域
-
研究领域 :具身智能(Embodied AI)× 视觉-语言导航(VLN)× 人机对话arxiv
-
核心任务 :Interactive Instance Goal Navigation(IIGN)------在模糊类别指令下,智能体需边导航边向 Oracle 主动提问以定位特定实例arxiv
-
关键术语:
-
IGN(Instance Goal Navigation):需找到特定目标实例,而非任意同类物体
-
IIGN:在 IGN 上扩展,允许智能体自由发起自然语言问答
-
VL-LN Benchmark:基于 MP3D 场景的大规模对话增强导航基准
-
MSP(Mean Success Progress):度量对话有用性与效率的新指标arxiv
-
研究目标与主要贡献
要解决的问题 :现实中导航指令往往模糊(如"帮我找椅子"),现有方法假设指令完整不含歧义,无法处理这种不确定性。arxiv
解决方案 :定义 IIGN 任务 + 构建 VL-LN 基准(大规模数据集 + 在线评测协议),训练具有对话能力的导航模型 VLLN-D。arxiv
三大主要贡献 :arxiv
-
自动生成房屋级、长程 IIGN 对话轨迹的数据管线
-
第一个提供大规模对话增强数据与联合在线评测的 IIGN 基准
-
实验证明主动对话可显著提升 IGN/IIGN 性能,同时揭示关键瓶颈
摘要中文翻译
在现有大多数具身导航任务中,指令通常被明确定义且无歧义,如路径跟随或物体搜索。在这一理想化设定下,智能体只需根据视觉与语言输入产生有效导航动作。然而,真实世界中的导航指令往往模糊,要求智能体通过主动对话解决不确定性并推断用户意图。为弥补这一差距,我们提出交互式实例目标导航(IIGN)任务,要求智能体不仅生成导航动作,还需通过主动对话产生语言输出,从而更贴近实际应用场景。IIGN 扩展了实例目标导航(IGN),允许智能体在导航过程中以自然语言自由咨询 Oracle。在此基础上,我们提出视觉语言-语言导航(VL-LN)基准,提供大规模自动生成数据集及用于训练和评估对话型导航模型的完整评测协议。VL-LN 包含超过 4.1 万条长程对话增强轨迹,并配套能自动回应智能体提问的 Oracle 评测协议。基于此基准训练的对话型导航模型相较基线取得显著提升,大量实验与分析进一步验证了 VL-LN 在推进对话增强具身导航研究方面的有效性与可靠性。arxiv
动机(3.1)
为什么现有方法不够
论文明确指出三层动机,层层递进:arxiv
-
任务层面:ObjectNav 任意找到一个同类物体即可(如 7 把椅子找到任意一把),而 IGN 要找特定实例,难度本质不同------需要更长探索且需区分外观相似的干扰项
-
交互层面:CVDN 收集了人-人对话但无 Oracle,无法在线评测;DialFRED 的 Oracle 只支持单房间小场景;CoIN 的 Oracle 只描述目标属性,不能提供路径指引------没有一个基准同时支持"属性+消歧+路径"三类对话且在房屋级场景下
-
数据层面 :现有训练集规模不足以学到"既主动探索又有效提问"的复合能力arxiv
主要方法(3.2)
整体架构:三层设计
任务定义(IIGN) ↓ 数据构建管线(三步骤) ↓ 模型训练与评测协议(VLLN-D + MSP)
任务定义:IIGN
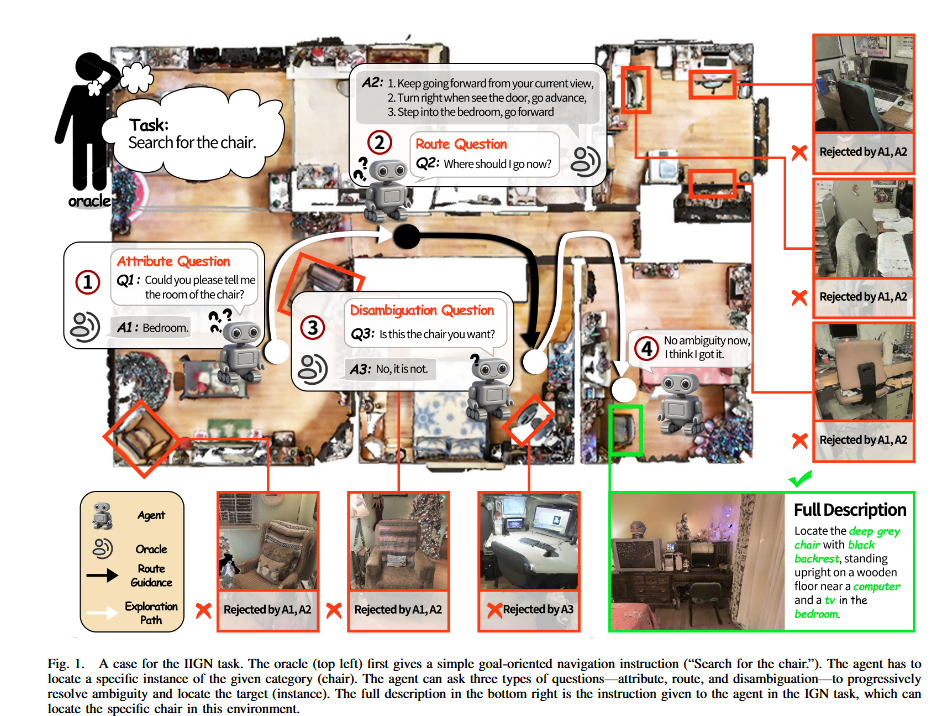
智能体每步从以下动作集选择:arxiv
Ask 动作使智能体可随时发起自然语言提问,Oracle 依据全局信息作答。Oracle 回答三类问题:
-
Attribute:目标属性(颜色/材质/形状/摆放位置),GPT-4o 基于实例元数据生成答案
-
Route:计算 Habitat-Sim 最短路径前 4 m → 提取高曲率转折点/房间切换点为 waypoint → 锚定附近显著物体 → 渲染为自然语言(如"到棕色桌子时右转")
-
Disambiguation :目标实例是否在视野中心 3 m 内,是→"yes",否→"no"arxiv
数据构建管线(三步骤)
Step 1:场景元数据处理
-
利用 MMScan 的层次标注构建房屋级 实例字典 (几何/外观/材质/功能)和区域字典(房间功能/包含物体)
-
用 Sr3D 构建空间关系图 :节点=实例,边连接 1 m 内邻近实例,提供消歧所需的关系线索arxiv
Step 2:Episode 生成
-
起始位姿:72 个场景复用 R2R-CE 起点 + 18 个新场景随机采样(导航网格+碰撞验证)
-
指令生成:
-
Partial instruction(IIGN 用):仅类别,如"Search for the chair"
-
Full instruction(IGN 用):利用字典+关系图选取判别性属性,GPT-4o 生成唯一定位描述
-
-
目标视点:目标 3D 包围盒扩展 0.6 m,盒内所有可行走点为合法 Stop 位置(≤0.25 m 视为成功)arxiv
Step 3:训练轨迹采集
-
使用 FBE(前沿探索)专家代理 + 真值检测器:90% 概率选最近前沿,10% 概率选朝向目标的前沿
-
对话触发规则 (原文 Section III-C3):arxiv
-
Episode 开始 → 随机触发一个 Attribute 问题
-
所选前沿指向目标方向 → 触发 Route 问题
-
视野中出现同类物体 → 触发 Disambiguation 问题
-
-
每类问题预设多种语义等价模板增加多样性
模型与评测设计
-
模型 :以 Qwen2.5-VL-7B-Instruct 为基础,按 InternVLA-N1 流程微调,VLLN-D 在数据中加入对话轨迹arxiv
-
MSP 指标:
MSP=1n∑i=1n(Si−S0)\mathrm{MSP} = \frac{1}{n}\sum_{i=1}^{n}(S_i - S_0)MSP=n1i=1∑n(Si−S0)
其中 S0S_0S0 为无对话基础成功率,SiS_iSi 为 \(i\) 轮对话预算下成功率,同时捕捉对话的有效性 (提升幅度)和效率 (少轮数获大提升得分更高)arxiv
方法新颖性评估
| 维度 | 创新点 |
|---|---|
| 任务 | 首次将"实例级导航+长程探索+主动对话"三者统一到可训练基准 |
| 数据 | GPT-4o+FBE 全自动生成 4.1 万对话轨迹,大幅降低人工成本 |
| Oracle | 同时支持属性/路径/消歧三类问答,且路径指引精确到 4 m 轨迹 |
| 指标 | MSP 首次量化"对话有用性×效率"的双重维度 |
实验结果(3.3)
实验设置
-
数据集 :90 个 MP3D 场景,112 个目标类别,20,476 个实例,333,319 个 Episodearxiv
-
基线方法:
| 方法 | 类型 | 特点 |
|---|---|---|
| FBE | 零样本 | 贪心前沿探索 + Grounded-SAM2 开放词汇检测 |
| VLFM | 零样本 | 发布版本直接使用 |
| VLLN-O | 训练式 | VLN + ObjectNav 数据 |
| VLLN-I | 训练式 | + 过滤后的 IGN 数据(无对话) |
| VLLN-D | 训练式 | + IGN 数据(含对话),具备 Ask 能力 |
核心数字(Table II)
IIGN(模糊指令+对话)
| 方法 | SR | SPL | OS | NE | MSP |
|---|---|---|---|---|---|
| FBE | 8.4 | 4.74 | 25.2 | 11.84 | -- |
| VLFM | 10.2 | 6.42 | 32.4 | 11.17 | -- |
| VLLN-O | 14.8 | 10.36 | 47.0 | 8.91 | -- |
| VLLN-I | 14.2 | 8.18 | 47.8 | 9.54 | -- |
| VLLN-D | 20.2 | 13.07 | 56.8 | 8.84 | 2.76 |
IGN(完整指令,无强制对话)
| 方法 | SR | SPL | OS | NE | MSP |
|---|---|---|---|---|---|
| VLLN-I | 22.4 | 13.43 | 60.4 | 8.16 | -- |
| VLLN-D*(问但无回答) | 21.8 | 14.33 | 54.8 | 8.56 | -- |
| VLLN-D(有回答) | 25.0 | 15.59 | 58.8 | 7.99 | 2.16 |
关键结论 :arxiv
-
IIGN 中加入对话后 SR 从 14.2% 升至 20.2%(+6%),OS 从 47.8% 升至 56.8%
-
IGN 中对话把 SR 从 22.4% 推至 25.0%;VLLN-D* 无回答则反降至 21.8%,说明对话收益来自回答内容本身而非提问动作
-
IIGN 的 MSP(2.76)> IGN(2.16):在本就模糊的任务中,对话边际收益更大
失败类型分析(Table III)
| 方法/任务 | 错检(WD) | 歧义(Ambig) | 探索失败 | Stop失败 |
|---|---|---|---|---|
| VLLN-I / IIGN | 151 (35.2%) | 159 (37.1%) | 89 (20.7%) | 30 (7.0%) |
| VLLN-D / IIGN | 146 (36.6%) | 145 (36.3%) | 71 (17.8%) | 37 (9.3%) |
| VLLN-I / IGN | 127 (32.7%) | 143 (36.9%) | 84 (21.6%) | 34 (8.8%) |
| VLLN-D / IGN | 150 (40.0%) | 124 (33.1%) | 46 (12.3%) | 55 (14.7%) |
-
对话对探索失败 改善最显著(IGN:84→46,降幅 45%),路径问题功不可没arxiv
-
对歧义失败也有改善(IIGN:159→145,IGN:143→124),但改善幅度有限------属性对齐仍是主瓶颈
-
值得注意:IGN 中 VLLN-D 的 Wrong Detection 反而从 127 增至 150,说明对话在某些情况下可能干扰检测决策
对话轮数预算分析(Table V)
| 对话轮限 | SR | SPL | 平均使用轮数 |
|---|---|---|---|
| 0 | 15.4 | 9.86 | 0 |
| 1 | 15.8 | 9.53 | 1.00 |
| 2 | 18.6 | 12.55 | 1.63 |
| 5(无限) | 20.2 | 13.07 | 1.76 |
-
从 1→2 轮增益最大 :仅 1 轮时智能体只能问属性,无法追问;2 轮后方能组合多类问题arxiv
-
不倾向滥用对话:即使允许 5 轮,平均只用 1.76 轮,与训练分布(1-2 轮)高度一致
跨角色评测(Table IV)
| 导航器 -- NPC | SR | 平均轮数 |
|---|---|---|
| Human -- Human | 93% | 2.04 |
| Human -- GPT | 91% | 9.72 |
| VLLN-D -- Human | 16% | 1.54 |
| VLLN-D -- GPT | 17% | 1.66 |
-
人类通过约 2 个问题即可达到 93% SR,而 VLLN-D 只达到约 17%------"问出有信息量的问题"是核心挑战 arxiv
-
GPT-NPC 与人类 NPC 对 VLLN-D 的支持效果相当(17% vs 16%),验证 GPT Oracle 的可靠性
实验严谨性评估
✅ 优点 :同一基础模型不同数据配比对比,消除架构变量;人类实验验证任务难度合理;GPT/Human 双 NPC 交叉验证评测可靠性arxiv
⚠️ 不足:测试集仅 500 个 Episode,统计置信度存疑;VLLN-D 在 IGN 下 Wrong Detection 增加未深入解释;缺乏与 AIUTA/CoIN 的直接定量对比
相关工作(3.4)
研究路线定位与对比
路线一:目标导向导航(Goal-oriented Navigation)
-
ObjectNav :找任意同类实例,指令无歧义;训练式(IL/RL)与零样本(FBE+LLM)两条路线arxiv
-
IGN:找特定实例,IGN 通过实例级图编码颜色/材质/位置特征,PSL 提出优先语义学习------但都把智能体定位为被动接受者,无主动对话arxiv+1
-
VL-LN(本文):在 IGN 之上加主动对话,把智能体从"接受者"升级为"提问者"
路线二:交互式具身机器人(Interactive Embodied Robotics)
| 方法 | 交互范围 | 局限 |
|---|---|---|
| 早期工作arxiv+1 | 询问下一步动作 | 单一交互模式 |
| 候选物确认arxiv | 返回候选图像让人确认 | 仅限目标确认 |
| RMMreddit | 学习"何时提问" | 无长程探索指导 |
| KNOWNOinsidesalespredictability | 语言模型决策何时求助 | 无导航场景特化 |
| AIUTAarxiv (CoIN) | 开放式对话定位实例 | 房间级,无探索路径引导 |
| VL-LN(本文) | 属性+消歧+路径三类对话 | 房屋级,支持长程探索 |
路线三:对话导航基准(Dialog Navigation Benchmarks)
-
CVDN :人-人对话,无 Oracle,不能在线评测arxiv
-
DialFRED :有 Oracle 但仅单房间,Oracle 只给方向指示aclanthology
-
CoIN:有 Oracle 但只描述目标,不指引探索路径arxiv+1
VL-LN 补充的空白 :首个在房屋级场景同时提供"属性+消歧+4 m 路径轨迹"三类对话、大规模训练数据(4.1 万轨迹)和在线评测协议的 IIGN 基准。arxiv
洞察、局限与未来工作(3.4)
核心研究价值
-
理论 :将主动对话纳入导航决策空间,提出 MSP 双维度对话评估框架,为"会问问题的导航智能体"提供标准化研究平台arxiv
-
实践:家庭服务机器人(模糊指令下的物品查找)、室内巡检/搜救(向指挥中心主动澄清目标)
-
领域影响:73% 失败源于图像-属性对齐的揭示,把具身智能的研究视野从"动作决策"延伸到"细粒度感知"
论文明确指出的局限性
-
图像-属性对齐是主瓶颈 :即使有完整指令+对话,SR 仍只有 25%,73% 失败来自检测错误------视觉模型对细粒度属性(颜色、材质)的识别仍不可靠arxiv
-
智能体提问策略薄弱 :人类平均 2 问达 93% SR,VLLN-D 平均 1.76 问只达 17%------问的少不代表问得好,缺乏"选最有信息量问题"的能力arxiv
-
IIGN 比 IGN 更难 :VLLN-D 在 IIGN(20.2%)低于 VLLN-D* 在 IGN(21.8%),说明当前模型从模糊指令+对话中获取的信息量,仍不如一条完整指令arxiv
潜在弱点(论文未显著提及)
-
Oracle 的模拟性:GPT-4o 基于真值几何生成回答,现实中人类回答风格更多样、可能出错或刻意误导
-
数据分布偏差:训练轨迹由脚本化 FBE+规则触发生成,问题分布与真实人类提问行为可能存在差异
-
测试集规模:500 个 Episode 的测试集对于评估高方差任务来说偏小,置信区间需关注
-
Sim-to-Real:全部基于 MP3D+Habitat-Sim,真实机器人平台的迁移性尚未验证
未来工作方向
论文指出及自然延伸方向:arxiv
-
Hard negative 训练:加入同类但不同属性的干扰实例做对比训练,提升细粒度属性 grounding 能力
-
主动提问策略学习:用信息增益/强化学习显式优化"问什么最有价值",而非仅模仿训练分布
-
开放对话类型:突破属性/路径/消歧三类,支持多步计划、目标更改、条件约束等复杂对话
-
Sim-to-Real 迁移:在真实机器人平台上验证,用领域自适应减小模拟-现实差距
-
多智能体协作:多个具备不同专长的机器人通过对话协同完成导航任务