第十一章深入拆解 Delta Lake 与 Lakehouse 架构,这是现代数据工程的核心组件。从传统数据湖的痛点出发,逐层剖析 Delta Lake 的实现原理。
- 第一张:为什么需要 Delta Lake。三大痛点和 Delta Lake 的解法一目了然。
- 接下来看最核心的实现机制------事务日志(Transaction Log):事务日志机制搞清楚了。
- 接下来是最常用的三大核心能力------MERGE、Time Travel 和 Schema Evolution:三大核心能力完整了。
- 最后一张:Lakehouse 的分层架构(Bronze / Silver / Gold)和生产级完整代码。
三大痛点(第一张) 是理解 Delta Lake 存在意义的前提。传统数据湖(S3 上的 Parquet 文件)有三个根本性缺陷:
- 没有 ACID 保证,写入中途崩溃读者会看到不完整数据,两个 Job 同时写同一文件会导致数据损坏;
- 不能 Upsert,改一行数据要重写整个分区,处理 CDC(Change Data Capture)只能全量重刷;
- 小文件地狱,流式写入每分钟产生的数百个小文件让列举和读取操作慢到无法接受,而且 Schema 变更会导致旧文件不兼容。
Delta Lake 用一个核心设计解决所有问题:在 Parquet 文件目录上加一个事务日志层(_delta_log/)。

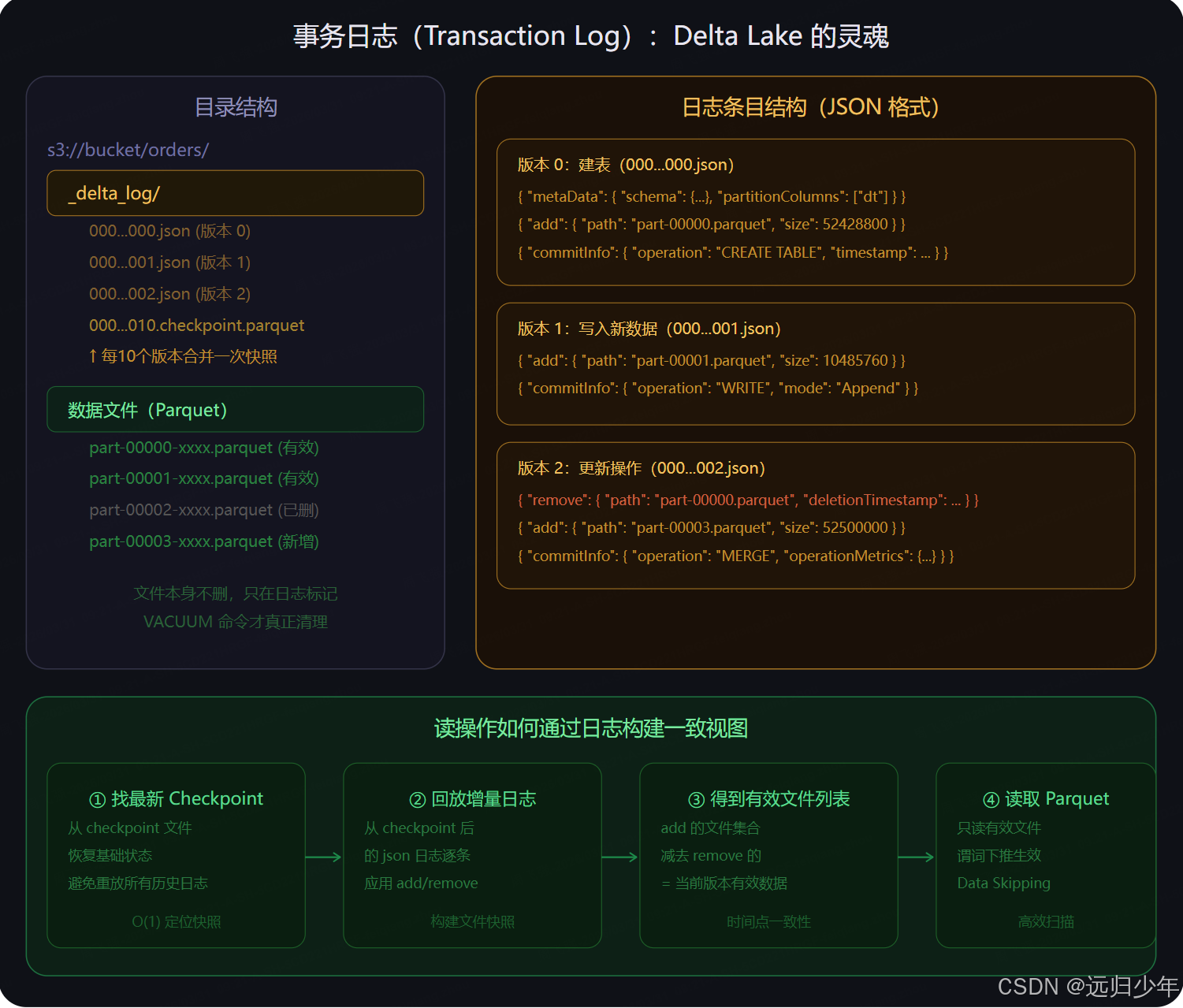
事务日志(第二张) 是 Delta Lake 的灵魂。每次写操作不直接修改已有文件,而是在 _delta_log/ 目录写一个 JSON 日志条目,记录哪些文件被"添加"(add)哪些被"移除"(remove)。读操作通过回放日志来确定"当前哪些文件是有效的",这就是一致性快照的来源。每 10 个版本合并一次 Checkpoint(Parquet 格式,比 JSON 快)避免每次都从头回放。
实际数据文件从不被真正删除 ,只在日志里标记为 removed,要等 VACUUM 命令才会真正清理过期文件------这也是 Time Travel 能查历史的底层原因。
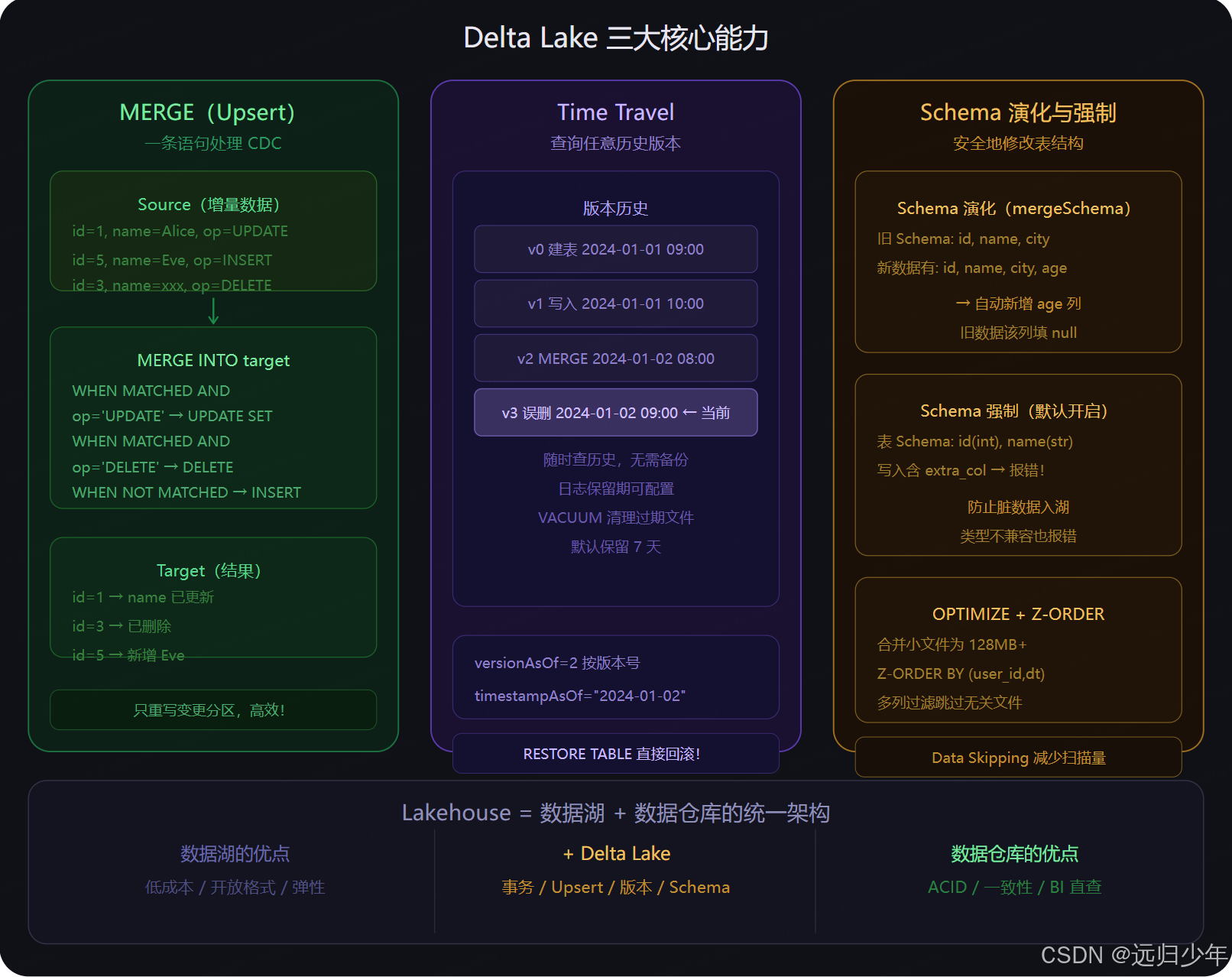
三大核心能力(第三张) 是日常开发最常用的功能。
MERGE INTO是处理 CDC 数据的利器,一条语句同时处理 INSERT、UPDATE、DELETE,只重写变更的分区文件,效率极高。- Time Travel 让你可以用
versionAsOf或timestampAsOf查询任意历史版本,误操作后直接RESTORE TABLE一键回滚,不需要维护额外的备份。 - Schema Evolution 在
mergeSchema=true时允许新增列自动兼容旧数据(旧数据该列填 null),而默认的 Schema Enforcement 会阻止写入不符合表结构的数据,防止脏数据污染数据湖。 OPTIMIZE + Z-ORDER命令合并小文件并按多个过滤列重排数据,让后续查询可以通过 Data Skipping 跳过大量无关文件。
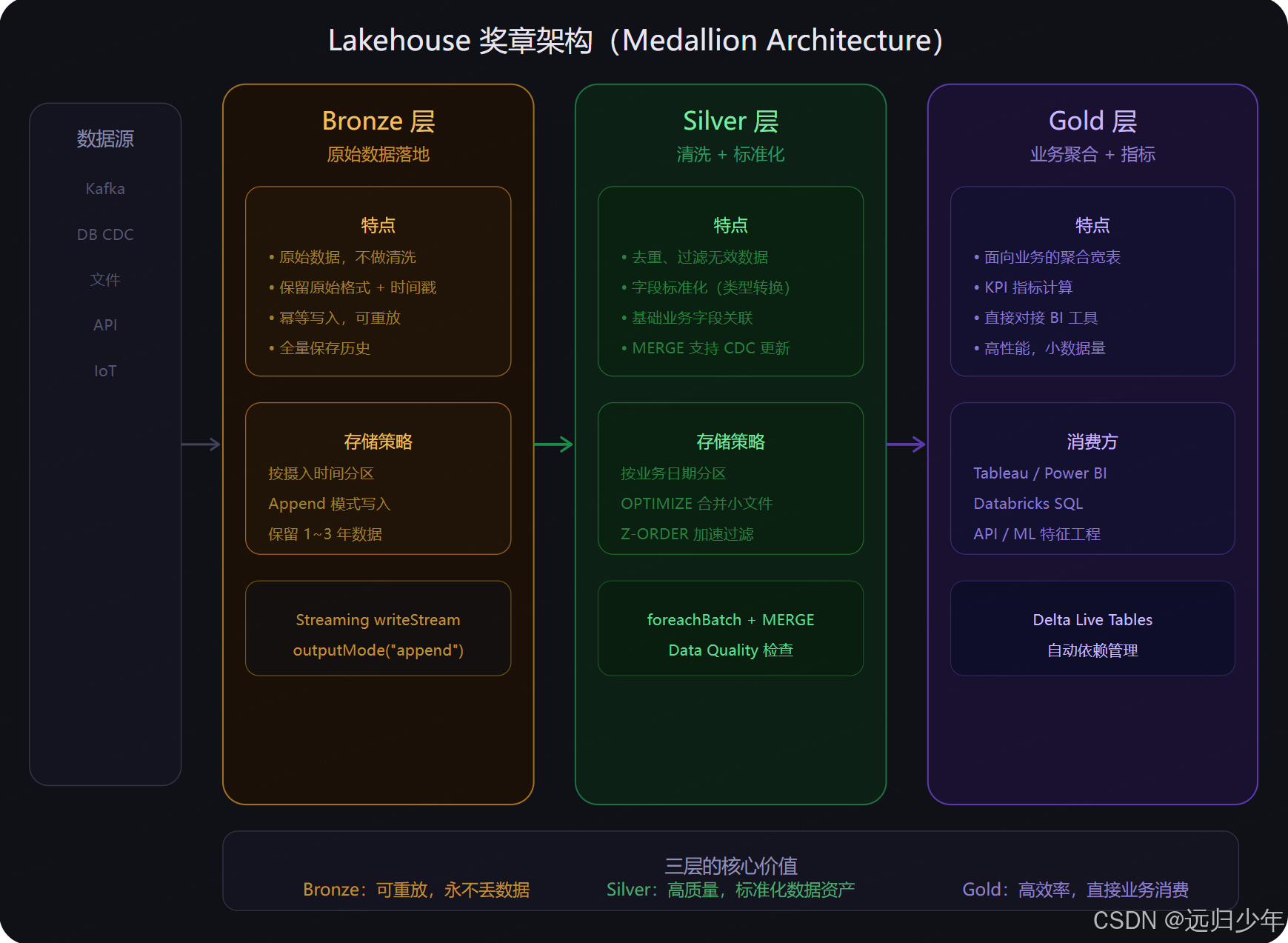
奖章架构(第四张) 是生产环境数据工程的最佳实践。
- Bronze 层是原始数据的忠实复制,不做任何清洗,只追加不更新,保留 1~3 年历史,是出现问题时的"后悔药"。
- Silver 层做标准化处理------去重、类型转换、基础关联、CDC 合并,是数据质量的守门人,对接大多数数据科学和分析需求。
- Gold 层是面向业务的聚合宽表和 KPI 指标,数据量小、查询快、直接对接 BI 工具和 API。
三层分工的本质是:数据质量由低到高,数据粒度由细到粗,消费成本由高到低。
最后附上生产级完整代码:
python
from delta.tables import DeltaTable
from pyspark.sql.functions import col, current_timestamp
# ── 1. Bronze 层:流式写入原始数据 ──
raw_stream = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "broker:9092") \
.option("subscribe", "orders_raw").load()
raw_stream.writeStream \
.format("delta") \
.option("checkpointLocation", "s3://bucket/checkpoints/bronze/") \
.outputMode("append") \
.partitionBy("ingest_date") \
.start("s3://bucket/delta/bronze/orders/")
# ── 2. Silver 层:MERGE 处理 CDC ──
def upsert_to_silver(batch_df, batch_id):
silver = DeltaTable.forPath(spark, "s3://bucket/delta/silver/orders/")
silver.alias("t").merge(
batch_df.alias("s"),
"t.order_id = s.order_id"
).whenMatchedUpdate(
condition="s.op = 'UPDATE'",
set={"amount": "s.amount", "status": "s.status",
"updated_at": "s.event_time"}
).whenMatchedDelete(
condition="s.op = 'DELETE'"
).whenNotMatchedInsert(
condition="s.op != 'DELETE'",
values={"order_id": "s.order_id", "amount": "s.amount",
"city": "s.city", "created_at": "s.event_time"}
).execute()
clean_stream.writeStream \
.foreachBatch(upsert_to_silver) \
.option("checkpointLocation", "s3://bucket/checkpoints/silver/") \
.start()
# ── 3. OPTIMIZE + Z-ORDER(定期执行)──
spark.sql("""
OPTIMIZE delta.`s3://bucket/delta/silver/orders/`
ZORDER BY (city, order_id)
""")
# ── 4. Time Travel ──
# 按版本号查询
df_v1 = spark.read.format("delta") \
.option("versionAsOf", "1") \
.load("s3://bucket/delta/silver/orders/")
# 按时间戳查询
df_yesterday = spark.read.format("delta") \
.option("timestampAsOf", "2024-01-01 00:00:00") \
.load("s3://bucket/delta/silver/orders/")
# 一键回滚到指定版本
spark.sql("""
RESTORE TABLE delta.`s3://bucket/delta/silver/orders/`
TO VERSION AS OF 5
""")
# ── 5. Schema 演化 ──
new_df.write.format("delta") \
.option("mergeSchema", "true") \
.mode("append") \
.save("s3://bucket/delta/silver/orders/")
# ── 6. VACUUM 清理过期文件(保留 7 天历史)──
spark.sql("""
VACUUM delta.`s3://bucket/delta/silver/orders/`
RETAIN 168 HOURS
""")
# ── 7. 查看版本历史 ──
spark.sql("""
DESCRIBE HISTORY delta.`s3://bucket/delta/silver/orders/`
""").show(truncate=False)