目录
[一、交换排序(Swap Sorts)](#一、交换排序(Swap Sorts))
[二、插入排序(Insertion Sorts)](#二、插入排序(Insertion Sorts))
[三、选择排序(Selection Sorts)题目:](#三、选择排序(Selection Sorts)题目:)
[四、归并排序(Merge Sort)](#四、归并排序(Merge Sort))
[五、非比较排序(Non-Comparison Sorts)](#五、非比较排序(Non-Comparison Sorts))
[1. 堆排序的二叉树表达](#1. 堆排序的二叉树表达)
[2. 堆排序原理与步骤示例](#2. 堆排序原理与步骤示例)
[3. 时间复杂度计算](#3. 时间复杂度计算)
[3.1 建堆的时间复杂度:O(n)](#3.1 建堆的时间复杂度:O(n))
[3.2 排序阶段的时间复杂度:O(n log n)](#3.2 排序阶段的时间复杂度:O(n log n))
[3.3 总时间复杂度](#3.3 总时间复杂度)
链表
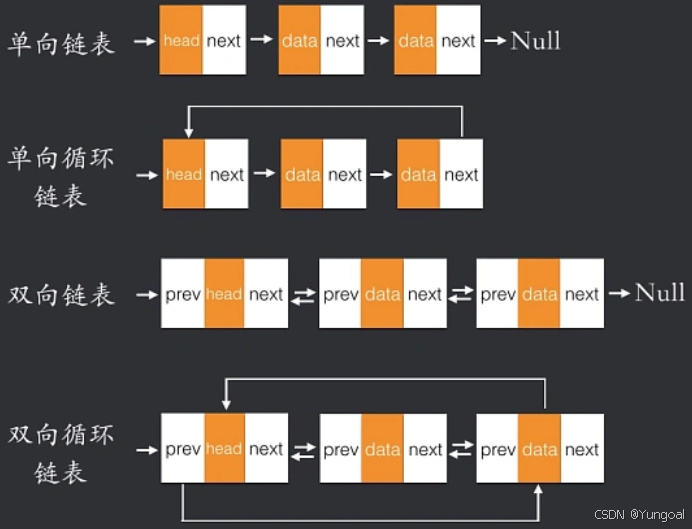

s->prior = p; // 1. s 前驱指 p
s->next = p->next; // 2. s 后继指 p 的后继(关键!必须在 p->next 改变前做)
p->next->prior = s; // 3. 原后继的前驱指回 s
p->next = s; // 4. 最后才改 p 的后继
栈

解题思路:本题考查栈的"后进先出"(LIFO)基本特性
第一步:明确栈的操作规则
栈是一种只能在一端(栈顶)进行插入和删除操作的线性数据结构,遵循后进先出原则 ------ 最后入栈的元素最先出栈,最早入栈的元素最后出栈。
第二步:模拟入栈过程
按题目顺序,元素依次入栈:
1 → 2 → 3 → A → B → C
入栈完成后,栈内从底到顶的顺序为:
1, 2, 3, A, B, C (栈顶为 C)
第三步:模拟出栈过程
依次出栈,即从栈顶开始逐个弹出:
第1个出栈:C
第2个出栈:B
第3个出栈:A
第4个出栈:3
第5个出栈:2
第6个出栈:1
排序
简洁总结:
冒泡排序:每一轮都会把最大值"推"到数组末尾。
快速排序:选第一个元素(或随机选)作为基准,大于它的一组,小于它的一组,在两组中又找基准又排,以此类推。
直接插入排序: 将数组的第一个元素视为一个长度为1的有序序列,剩余部分为无序区。key从第二个数(索引为1)开始,与左侧有序区从右往左做比较,到比它小的地方的后面一个位置插入。
二分插入排序:在已排序区间里面取一个中值,确定是插入左半区还是右半区。
希尔插入排序:确定gap(空隙)之后,先对间隔较大的元素进行排序,逐步缩小间隔。是插入排序的大幅度版本。
一、交换排序(Swap Sorts)
-
冒泡排序 (Bubble Sort)
-
原理:重复遍历,比较相邻元素,若逆序则交换,像气泡一样将最大/最小元素"浮"到顶端。每一轮都会把最大值"推"到数组末尾。
-
特点:稳定、简单,但平均/最坏时间复杂度 O(n²),效率低。
-
-
快速排序 (Quick Sort)
-
原理:分治策略。选取一个"基准",将数组分为"小于基准"和"大于基准"的两部分,递归排序。
-
特点:平均 O(n log n),最坏 O(n²),不稳定,但在实际应用中通常是最快的通用排序。
-
举例:6, 8, 1, 3, 7, 2 ,以第一个元素为基准。
Hoare分区法核心思想:(正是因为Hoare分区法思想,【快速排序】才被放在【交换排序】中)
-
选基准:通常选第一个元素(或随机选)作为基准(pivot)。
-
双指针:
-
左指针
i从左边开始,向右移动,直到找到大于等于基准的元素。 -
右指针
j从右边开始,向左移动,直到找到小于等于基准的元素。
-
-
交换 :如果
i < j,交换这两个位置的元素。 -
循环 :重复步骤2-3,直到
i和j相遇或交错。 -
返回 :最后基准的位置是**
j指针的位置**(相遇点)。
初始 :[6, 8, 1, 3, 7, 2]
递归树
初始调用: quicksort([6,8,1,3,7,2], 0, 5)
│
├─ 分区结果: [2, 3, 1, 6, 7, 8] 基准索引=3
│
├─ 递归左子数组: quicksort([2,3,1], 0, 2)
│ │
│ ├─ 分区结果: [1, 2, 3] 基准索引=1
│ │
│ ├─ 递归左子数组: quicksort([1], 0, 0) → 返回 [1] (终止)
│ │
│ ├─ 递归右子数组: quicksort([3], 2, 2) → 返回 [3] (终止)
│ │
│ └─ 左子数组合并结果: [1, 2, 3]
│
├─ 基准: 6
│
└─ 递归右子数组: quicksort([7,8], 4, 5)
│
├─ 分区结果: [7, 8] 基准索引=4
│
├─ 递归左子数组: quicksort([], ?, ?) → 无操作 (终止)
│
├─ 递归右子数组: quicksort([8], 5, 5) → 返回 [8] (终止)
│
└─ 右子数组合并结果: [7, 8]
│
└─ 最终合并: [1,2,3] 6 [7,8] → [1,2,3,6,7,8]二、插入排序(Insertion Sorts)
1.直接插入排序 (Insertion Sort)
-
原理:将元素一个个插入到已排序序列的合适位置。
-
特点:稳定,对小规模或基本有序数据效率高(O(n)~O(n²))。
将数组的第一个元素视为一个长度为1的有序序列,剩余部分为无序区。
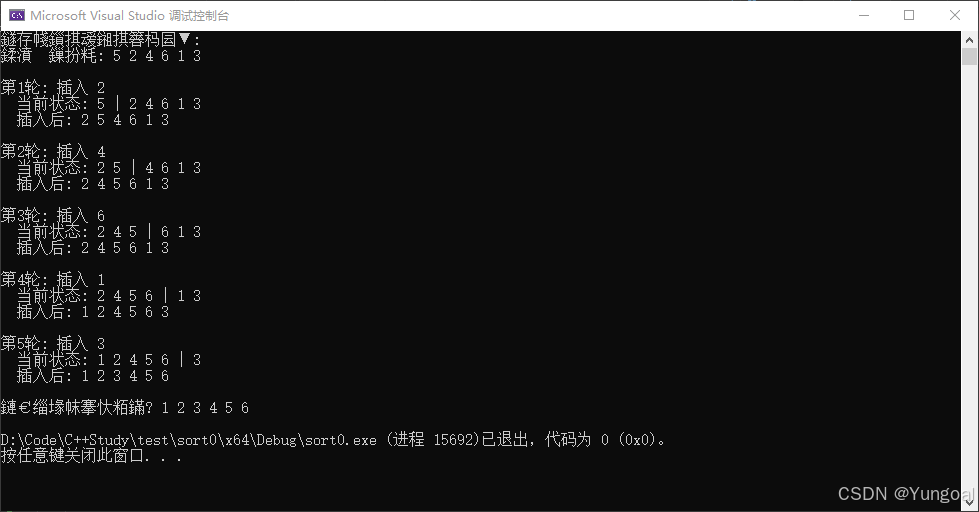
cpp
#include "SortAlgorithms.h"
// 直接插入排序函数定义(带步骤输出)
void insertionSortWithSteps(vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; i++)
{
//key被插入
int key = arr[i];
int j = i - 1;
cout << "\n第" << i << "轮: 插入 " << key << endl;
cout << " 当前状态: ";
//展示当前状态
for (int k = 0; k < n; k++)
{
//|之前是已排序分区
if (k == i) cout << "| ";
cout << arr[k] << " ";
}
cout << endl;
// key在已排序分区从右往左做比较,key比它小,就把它往后挪。这时候移动的元素不是key,而是与它比较的元素
while (j >= 0 && arr[j] > key)
{
arr[j + 1] = arr[j];
j--;
}
// 在key比较完了之后,终于找到了比它小的元素,就会插入key在这个元素后面,j+1这个位置被覆盖之前,是之前那个数字,比如,从25|4613比较之后25|5613,覆盖:24|5613
arr[j + 1] = key;
cout << " 插入后: ";
for (int k = 0; k < n; k++)
{
cout << arr[k] << " ";
}
cout << endl;
}
}2.二分排序
二分排序是直接插入排序的优化版本
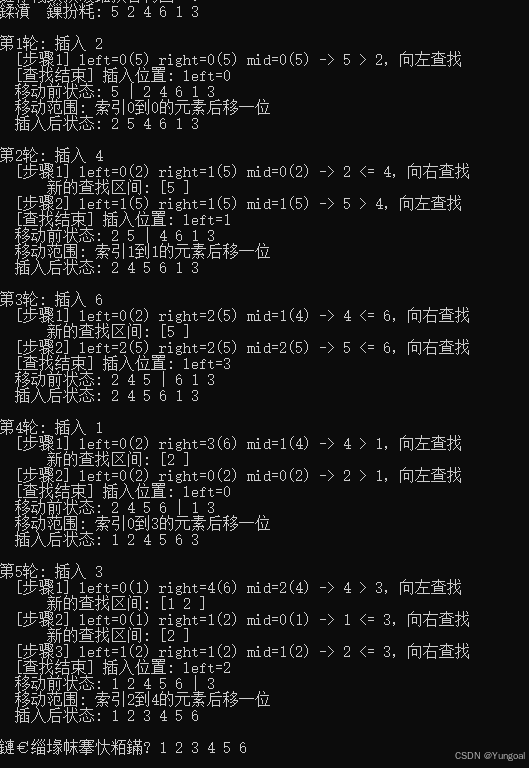
在已排序区间里面取一个中值,确定是插入左半区还是右半区。
3.希尔排序 (Shell Sort)
-
-
原理:插入排序的改进版。先对间隔较大的元素进行排序,逐步缩小间隔。
-
特点:不稳定,时间复杂度约 O(n^1.3),是较早的突破 O(n²) 的算法。
-
理解希尔排序中的 gap 是理解整个算法的关键。简单来说,gap 决定了"分组"的粒度 ,它定义了在进行插入排序时,比较和移动元素的跳跃距离。
gap 的直观类比
想象一下整理书架上的书:
-
直接插入排序 (gap=1):你每次拿起一本书,只能和相邻的书比较 ,如果这本书应该放在左边第10本的位置,你需要一本一本、慢慢地、连续地挪动9本书,腾出位置。
-
希尔排序 (gap>1):gap=5 时,你可以一次跳过4本书 进行比较。如果这本书应该放在左边第10本的位置,你先比较第5本、第10本 ,如果位置不对,一次性将第5本向后移动5个位置 。这样一步到位,大幅减少了小步挪动的次数。
gap 如何工作(以数组 [8,3,1,7,0,9,2,5]为例)
初始:gap = 8/2 = 4
数组索引: 0 1 2 3 4 5 6 7
数组元素: 8 3 1 7 0 9 2 5
分组情况: A B C D A B C D-
gap=4 意味着:间隔4个位置的元素为一组
-
组A: 索引0,4 →
[8, 0] -
组B: 索引1,5 →
[3, 9] -
组C: 索引2,6 →
[1, 2] -
组D: 索引3,7 →
[7, 5]
-
关键 :每组内部做插入排序 ,但比较和移动的距离是4,不是1。
举例:处理组A [8, 0]
-
比较
8和0,发现8 > 0 -
将
8向后移动4个位置(从索引0移到索引4) -
将
0插入索引0,将8和0做了调换移动前: 8 3 1 7 0 9 2 5
移动后: 0 3 1 7 8 9 2 5
注意:这里8一次性跳过了4个元素到达位置4,而不是像直接插入排序那样一步一步挪动。
gap 递减的意义
for (int gap = n / 2; gap > 0; gap /= 2)希尔排序的关键在于 gap 序列逐渐减小到1:
-
gap=4 时:
-
元素可以大跨度跳跃,快速到达大致正确的位置区域
-
减少了大量小步移动
-
数组变得"基本有序"
-
-
gap=2 时:
-
在"基本有序"的基础上进一步调整
-
移动跨度变小,调整更精细
-
-
gap=1 时:
-
就是标准的插入排序
-
但此时数组已经"基本有序",插入排序效率极高
-
gap 代码逻辑
// 直接插入排序
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1; // 与相邻元素比较
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // 向后移动1位
j--; // 前移1位
}
arr[j + 1] = key;
}
// 希尔排序(注意 gap 的插入)
for (int i = gap; i < n; i++) {
int key = arr[i];
int j = i;
while (j >= gap && arr[j - gap] > key) { // 比较间隔gap的元素
arr[j] = arr[j - gap]; // 向后移动gap位
j -= gap; // 前移gap位
}
arr[j] = key;
}为什么 gap 能提高效率?
减少"乌龟"问题
在直接插入排序中,小数值 (乌龟)在数组末尾时,需要一步一步慢慢挪到前面,效率极低。
希尔排序中,大 gap 能让"乌龟"快速跳过中间元素,大幅减少移动次数。
逐步优化策略
| gap值 | 作用 | |
|---|---|---|
| 大gap | 宏观调整:让元素快速进入大致正确区域 | |
| 中gap | 中观调整:在区域内进一步排序 | |
| 小gap | 微观调整:精细排序 | |
| gap=1 | 最终整理 |
三、选择排序(Selection Sorts)题目:
有一组数据 "12, 15, 1, 18, 2, 35, 30, 11",用选择排序 由小到大排序,求第2趟交换数据后数据的顺序。
📌 第一步:理解选择排序的基本原理
选择排序(Selection Sort)的思路是:
-
从第1个位置开始,找后面所有元素中最小的那个,和当前位置交换;
-
然后从第2个位置开始,找后面所有元素中最小的那个,和第2个位置交换;
-
以此类推,直到倒数第二个位置。
每"一趟"指的是完成一次"找最小值 + 交换"的过程。
📌 第二步:原始数据
原始数组:
12, 15, 1, 18, 2, 35, 30, 11
索引: 0 1 2 3 4 5 6 7
📌 第三步:第1趟排序(找第0位的最小值)
从索引0开始,找整个数组最小值 → 最小值是 1(在索引2)
交换索引0 和 索引2:
→ 1, 15, 12, 18, 2, 35, 30, 11
**第1趟交换后顺序:**
1, 15, 12, 18, 2, 35, 30, 11
📌 第四步:第2趟排序(找第1位的最小值)
现在从索引1开始(即从"15"开始)找后面最小值:
子数组:15, 12, 18, 2, 35, 30, 11
最小值是 2(在索引4)
交换索引1 和 索引4:
原数组:1, 15 , 12, 18, 2, 35, 30, 11
交换后:1, 2 , 12, 18, 15, 35, 30, 11
✅ **第2趟交换后数据的顺序是:**
1, 2, 12, 18, 15, 35, 30, 11
✅ **最终答案:**
1, 2, 12, 18, 15, 35, 30, 11
四、归并排序(Merge Sort)
-
归并排序 (Merge Sort)
-
原理:分治策略。将数组递归分成两半,分别排序后,再合并两个有序数组。
-
特点:稳定,时间复杂度 O(n log n),但需要 O(n) 的额外空间。
-
五、非比较排序(Non-Comparison Sorts)
-
计数排序 (Counting Sort)
-
原理:统计每个元素出现的次数,然后按顺序输出。
-
特点:稳定,时间复杂度 O(n + k)(k 为数据范围),但要求数据范围较小且为整数。
-
-
桶排序 (Bucket Sort)
-
原理:将数据分到有限数量的桶里,每个桶单独排序(通常用插入排序),再合并。
-
特点:稳定,时间复杂度 O(n + k),适合数据分布均匀的场景。
-
六、堆排序
1. 堆排序的二叉树表达
堆排序基于一种称为二叉堆 的数据结构。二叉堆是一种完全二叉树,它满足以下性质:
-
结构性质:所有层都完全填满,除了最后一层,最后一层的节点从左到右填充(完全二叉树)。
-
堆序性质:
-
最大堆 :每个节点的值都大于或等于其子节点的值(根节点最大)。
-
最小堆 :每个节点的值都小于或等于其子节点的值(根节点最小)。
-
堆排序通常使用最大堆进行升序排序。
数组表示
由于堆是完全二叉树,它可以高效地用数组表示,无需指针:
-
根节点存储在索引
0处。 -
对于索引为
i的节点:-
父节点索引:
(i-1)//2(整数除法) -
左子节点索引:
2*i + 1 -
右子节点索引:
2*i + 2
-
这种数组表示使得堆排序是原地排序算法,只需要常数额外空间。
2. 堆排序原理与步骤示例
我们以数组 [4, 10, 3, 5, 1]为例,演示堆排序的完整过程。
步骤1:构建最大堆(Heapify)
将无序数组调整成最大堆。从最后一个非叶子节点开始,自底向上进行"向下调整"。
初始数组对应的完全二叉树:
4(0)
/ \
10(1) 3(2)
/ \
5(3) 1(4)(括号内为数组索引)
构建最大堆过程:
-
最后一个非叶子节点索引 =
n//2 - 1 = 5//2 - 1 = 1(值为10)。- 节点10:子节点为5和1,10≥5且10≥1,无需调整。
-
上一个节点索引 = 0(值为4)。
-
节点4:左右子节点为10和3,较大的是10,4<10,交换4和10。
10(0)
/
4(1) 3(2)
/
5(3) 1(4) -
交换后,节点4在索引1,其子节点为5和1,较大的是5,4<5,交换4和5。
10(0)
/
5(1) 3(2)
/
4(3) 1(4)
调整完成,得到最大堆。
-
此时数组为 :[10, 5, 3, 4, 1]
步骤2:排序(重复取堆顶)
排序阶段每次将堆顶(最大值)与当前堆的最后一个元素交换,然后减小堆大小并调整堆。
第1轮:
-
交换堆顶(10)与末尾(1):数组变为
[1, 5, 3, 4, 10],此时10在末尾已排好序。 -
对剩余堆(大小4)从根(1)向下调整:
-
1与子节点(5,3)中较大的5比较,1<5,交换1和5。
5(0)
/
1(1) 3(2)
/
4(3) [10] 已固定 -
交换后,1在索引1,与子节点4比较,1<4,交换1和4。
5(0)
/
4(1) 3(2)
/
1(3) [10]
-
-
调整后数组:
[5, 4, 3, 1, 10]
第2轮:
-
交换堆顶(5)与当前末尾(1):
[1, 4, 3, 5, 10] -
对堆(大小3)向下调整:
-
1与子节点(4,3)中较大的4比较,1<4,交换。
4(0)
/
1(1) 3(2) [5,10] 已固定 -
交换后,1在索引1,无子节点,停止。
-
-
数组:
[4, 1, 3, 5, 10]
第3轮:
-
交换堆顶(4)与当前末尾(3):
[3, 1, 4, 5, 10] -
对堆(大小2)向下调整:
- 3与子节点1比较,3>1,无需调整。
-
数组:
[3, 1, 4, 5, 10]
第4轮:
-
交换堆顶(3)与当前末尾(1):
[1, 3, 4, 5, 10] -
堆大小减为1,排序完成。
最终升序数组 :[1, 3, 4, 5, 10]
整个过程可以总结为两个阶段:
-
建堆阶段:将无序数组构建成最大堆。
-
排序阶段:重复将堆顶元素(最大值)与堆末尾元素交换,然后缩小堆并调整。
3. 时间复杂度计算
堆排序的时间复杂度由两部分组成:建堆 和重复取堆顶并调整。
3.1 建堆的时间复杂度:O(n)
建堆过程从最后一个非叶子节点开始,对每个节点执行"向下调整"。最坏情况下,每个节点需要调整的次数与其高度成正比。
设堆的高度为 h(根节点高度为 h,叶子节点高度为 0)。对于高度为 k 的节点,向下调整最多需要 k 次比较和交换。
计算总操作次数:
-
高度为 h 的节点(只有根节点):最多调整 h 次。
-
高度为 h-1 的节点:最多调整 h-1 次,这样的节点有 2¹ 个。
-
...
-
高度为 0 的节点(叶子):调整 0 次,这样的节点有 2ʰ 个。
设 n 为节点总数,则 n ≈ 2ʰ⁺¹ - 1,h ≈ log₂n。
总调整次数 S = Σ(每层节点数 × 该层节点高度)
S = 2⁰·h + 2¹·(h-1) + 2²·(h-2) + ... + 2ʰ⁻¹·1
用错位相减法计算:
S = h + 2(h-1) + 4(h-2) + ... + 2ʰ⁻¹·1
2S = 2h + 4(h-1) + ... + 2ʰ·1
相减:-S = h - 2 - 4 - ... - 2ʰ⁻¹ + 2ʰ
= h - (2ʰ - 2) + 2ʰ
= h - 2ʰ + 2 + 2ʰ
= h + 2
所以 S = 2ʰ⁺¹ - h - 2
由于 n ≈ 2ʰ⁺¹,所以 S ≈ n - log₂n - 2 = O(n)。
因此,建堆的时间复杂度是 O(n),而不是直觉上的 O(n log n)。
3.2 排序阶段的时间复杂度:O(n log n)
排序阶段执行 n-1 轮,每轮将堆顶与末尾交换后,对新的根节点执行"向下调整"。向下调整的最大次数等于当前堆的高度。
-
第1轮:堆大小为 n,调整次数 ≤ log₂n
-
第2轮:堆大小为 n-1,调整次数 ≤ log₂(n-1)
-
...
-
第n-1轮:堆大小为 2,调整次数 ≤ 1
总调整次数 ≤ log₂n + log₂(n-1) + ... + log₂2
= log₂(n!) ≈ n log₂n (斯特林公式)
因此,排序阶段的时间复杂度是 O(n log n)。
3.3 总时间复杂度
建堆 O(n) + 排序 O(n log n) = O(n log n)。
堆排序在所有情况下的时间复杂度都是 O(n log n),这是其优于快速排序(最坏 O(n²))的地方,但通常在实际应用中常数因子较大,不如快速排序快。
空间复杂度
由于是原地排序,只需要常数空间存储临时变量,所以空间复杂度为 O(1)。
总结
-
原理:利用最大堆的性质,每次取出最大值放到数组末尾。
-
步骤:建堆(O(n))→ 重复取堆顶并调整(O(n log n))。
-
特点:
-
时间复杂度始终为 O(n log n)。
-
原地排序,空间复杂度 O(1)。
-
不稳定排序(交换可能改变相等元素的顺序)。
-
对初始顺序不敏感,适合大数据量排序。
-
七、对比:几种排序的时间复杂度
| 排序方法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 特点 |
|---|---|---|---|---|---|
| 选择排序 | O(n²) | O(n²) | O(1) | ❌ 不稳定 | 每趟选最小,交换次数少 |
| 冒泡排序 | O(n²) | O(n²) | O(1) | ✅ 稳定 | 相邻交换,简单但慢 |
| 快速排序 | O(n log n) | O(n²) | O(log n) | ❌ 不稳定 | 实际最快,分治思想 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | ✅ 稳定 | 分治,需额外空间 |
| 堆排序 | O(n log n) | O(n log n) | O(1) | ❌ 不稳定 | 原地排序,利用堆结构 |
| 插入排序 | O(n²) | O(n²) | O(1) | ✅ 稳定 | 小数据或基本有序时高效 |