目录
文章目录
- 目录
- [Harness Engineering 的诞生](#Harness Engineering 的诞生)
- [Harness 的含义](#Harness 的含义)
- [OpenAI 如何实现 Harness Engineering?](#OpenAI 如何实现 Harness Engineering?)
- [Harness engineering 是 AI Coding 的控制论](#Harness engineering 是 AI Coding 的控制论)
- [Harness Engineering 的架构设计](#Harness Engineering 的架构设计)
-
- [1. 上下文工程(Context Engineering)](#1. 上下文工程(Context Engineering))
- [2. 工具和执行环境](#2. 工具和执行环境)
- [3. Feedback Loop](#3. Feedback Loop)
- [4. 实时可观测](#4. 实时可观测)
- [5. 架构约束(Architectural Constraints)](#5. 架构约束(Architectural Constraints))
- [6. 熵管理(Entropy Management)](#6. 熵管理(Entropy Management))
- [Harness Engineering 案例实践](#Harness Engineering 案例实践)
-
- 软件清单
-
- 基础设施
- 后端(Python)
- 前端(JavaScript)
- [CI/CD 平台](#CI/CD 平台)
- 可观测性
- 开发辅助
- 项目结构
- [AGENTS.md 示例](#AGENTS.md 示例)
- [Makefile 统一命令入口](#Makefile 统一命令入口)
- [后端:自定义 Linter 实现架构约束](#后端:自定义 Linter 实现架构约束)
-
- [使用 import-linter 控制依赖方向](#使用 import-linter 控制依赖方向)
- [使用 Ruff 进行代码质量检查](#使用 Ruff 进行代码质量检查)
- [前端:自定义 Linter 实现架构约束](#前端:自定义 Linter 实现架构约束)
-
- [使用 eslint-plugin-boundaries](#使用 eslint-plugin-boundaries)
- [Docker Compose 本地开发环境](#Docker Compose 本地开发环境)
- [CI/CD 流水线](#CI/CD 流水线)
- [可观测性:Agent 的查询脚本](#可观测性:Agent 的查询脚本)
- [浏览器自动化:Agent 的 UI 验证](#浏览器自动化:Agent 的 UI 验证)
- [Agent 自动审查工作流](#Agent 自动审查工作流)
- 熵管理:自动清理
- [Pre-commit 钩子配置](#Pre-commit 钩子配置)
- 最后
Harness Engineering 的诞生
2025 年 8 月,OpenAI 启动了一个实验性的研发项目,这个项目从第一个 Commit 开始就是由 CodeX 来完成的,并且规定人类程序员不得手动输入一行代码。
项目初期的进展很慢,OpenAI 发现问题不是 CodeX 太笨,而是缺少让 CodeX 好好工作的 "环境"。在这个环境里,Agent 不只是生成代码,还能够像工程师一样操作系统、运行程序、观察结果并进行迭代。
于是,这 3 人(后来扩展到 7 人)团队的工作变成了为 CodeX 定义规则、设计工具、搭建环境。他们每天的工作不再是敲代码,而是构建一个 CodeX 自主工作的循环 ------ 描述任务 => 运行 Agent => Agent 发起一个 PR => Agent 自我审查 => 其他 Agent 交叉审查 => Agent 根据反馈修改 => 循环,直到所有 "AI 评审" 都通过为止!
五个月后,OpenAI 构建了一个真实上线的、服务数百名内部用户的、拥有约 100 万行代码的复杂系统。期间大约合并了 1500 多个 PR,这些 PR 的实现、测试、文档、配置,全部由 AI 在人类睡觉的时候完成。而人类程序员没有写 1 行代码。
随后,2026 年 2 月 11 日, OpenAI 工程师 Ryan Lopopolo 发布博客《Harness engineering: leveraging Codex in an agent-first world》提出观点 ------ 工程师不再写代码,而是为 Agent 搭建自动化工作的环境。

Harness 的含义
"Harness" 本意是 "马具(缰绳、马鞍、马嚼子)",这是一整套用于引导强大但不可预测的动物走向正确方向的装置。如果没有 Harness,AI Agent 就像一匹在旷野中奔跑的野马,虽然速度惊人,但对完成任务毫无用处。
| 比喻 | 含义 | 作用 |
|---|---|---|
| 马 | AI 模型 | 强大、快速,但不知道自己该往哪走 |
| Harness(马具) | 基础设施 | 约束、护栏、反馈回路,将模型的力量转化为生产力 |
| 骑手 | 人类工程师 | 提供方向,而不是亲自奔跑 |
当 AI 从 "对话系统" 变成 "执行系统" 时,我们需要的是一套完整的约束、反馈、控制机制。
Cobus Greyling 在他的博客中用计算机来类比解释 Harness。而 Andrej Karpathy 用一个比喻精准描述了目前的情况 ------ 我们有了一个强大的新内核(LLM),但没有操作系统来正确运行它,这就是 Harness Engineering 要解决的核心问题。
| 计算机组件 | Harness 对应 | 作用 |
|---|---|---|
| CPU | 大模型 | 原始处理能力 |
| RAM | 上下文窗口 | 有限的工作记忆 |
| 操作系统 | Harness | 管理上下文、初始化序列、标准工具驱动 |
| 应用程序 | Agent | 在操作系统之上运行 |
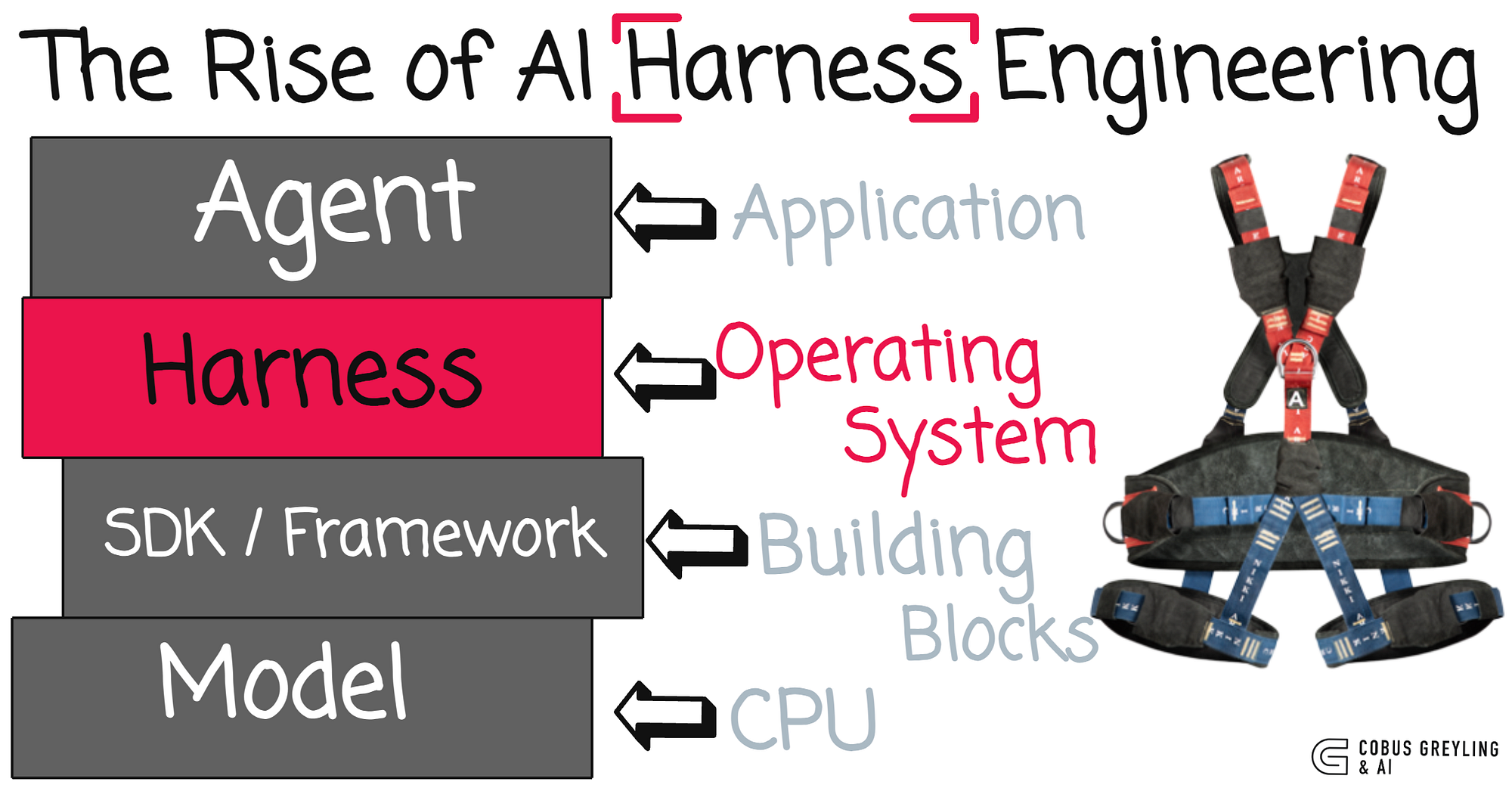
OpenAI 如何实现 Harness Engineering?
1. AGENTS.md 导航文件
AGENTS.md 是 OpenAI Harness Engineering 的 "最初",用于约束 CodeX Agent 的行为规范(OpenClaw 也沿用了这一设计)。CodeX 在每个会话开始时都会自动读取 AGENTS.md 从而获得需要知道的内容,包括:构建步骤、测试命令、编码约定、架构约束、常见陷阱等。
一开始,他们写了一个超大的 AGENTS.md 文件,预期把所有规则、逻辑、注意事项都塞进去。但结果是 AI 直接死机了。所以后来,他们把 AGENTS.md 精简到了只有 100 行,将 AGENTS.md 定义为 "导航目录" 而非 "内容本身",它指向了一个结构清晰的 docs/ 目录,里面有各类文档,包括:架构图、设计文档、质量标准、安全规范等等。通过渐进式披露的方式逐步向 AI 提供它需要了解的内容。
简而言之,OpenAI 对 AGENTS.md 最佳实践总结了 2 点:
- 渐进式披露:让 AGENTS.md 保持约 100 行,作为一个目录清单,指向更深层次的 docs/ 规范文件。
- 记录教训:Agent 的每次失败都更新到 AGENTS.md,使文档成为反馈循环的落实,以求不再从滔覆辙。
bash
# AGENTS.md
## 项目简介
[一句话描述项目目标]
## 技术栈
- 语言:
- 框架:
- 数据库:
- 部署:
## 快速开始
### 构建
[构建命令]
### 测试
[测试命令,包括覆盖率]
### 运行
[本地运行命令]
## 架构原则
### 分层架构
[简要描述分层,指向 docs/architecture/]
### 依赖方向
[允许的依赖方向,如 Types → Config → Service → UI]
### 横切关注点
[如何处理 auth、logging、telemetry]
## 编码规范
### 命名约定
[文件、变量、函数命名规则]
### 代码组织
[文件大小限制、模块划分]
### 错误处理
[错误处理模式、日志规范]
## 测试策略
### 单元测试
[框架、覆盖率要求]
### 集成测试
[范围、运行频率]
### 端到端测试
[工具、关键路径]
## 常见陷阱
### ⚠️ 不要做的事
1. [陷阱 1 及原因]
2. [陷阱 2 及原因]
3. [陷阱 3 及原因]
### ✅ 应该做的事
1. [最佳实践 1]
2. [最佳实践 2]
## 深入阅读,渐进式披露
- 架构详情:docs/architecture/overview.md
- 设计原则:docs/design/principles.md
- 技术债:docs/plans/tech-debt.mddocs/ 目录是 AGENTS.md 的深层次规范文件,包括:
bash
docs/
├── architecture/ # 架构文档
│ ├── overview.md # 分层架构图
│ ├── domains/ # 业务域划分
│ └── layers/ # 各层职责
│
├── design/ # 设计决策
│ ├── decisions/ # ADR(架构决策记录)
│ ├── principles/ # 核心信念
│ └── constraints/ # 约束规则
│
├── plans/ # 执行计划
│ ├── active/ # 进行中
│ ├── completed/ # 已完成
│ └── tech-debt.md # 技术债追踪
│
├── quality/ # 质量评级
│ ├── grades.md # 各领域质量评分
│ └── metrics.md # 关键指标
│
├── generated/ # 自动生成
│ └── db-schema.md # 数据库 Schema
│
├── product-specs/ # 产品规格
│ ├── index.md
│ └── features/ # 功能列表
│
└── references/ # 外部参考
├── design-system-llms.txt
└── libraries-llms.txt2. 构建循环的感知器
构建 CodeX 自主循环(描述任务 => 运行 Agent => Agent 发起一个 PR => Agent 自我审查 => 其他 Agent 交叉审查 => Agent 根据反馈修改 => 循环,直到所有 AI 评审都通过为止)的前提是 Agent 能够 "看见和感知" ------ 循环依赖足够强大的 "感知器" 来进行反馈。
如果一个 Agent:
- 看不到完整的代码仓库结构;
- 无法看到测试结果;
- 也无法获取日志或错误信息。
那么无论 Prompt 写得多复杂,本质上都是让模型在 "猜测"。一旦任务复杂度提高,输出不稳定就变成必然。
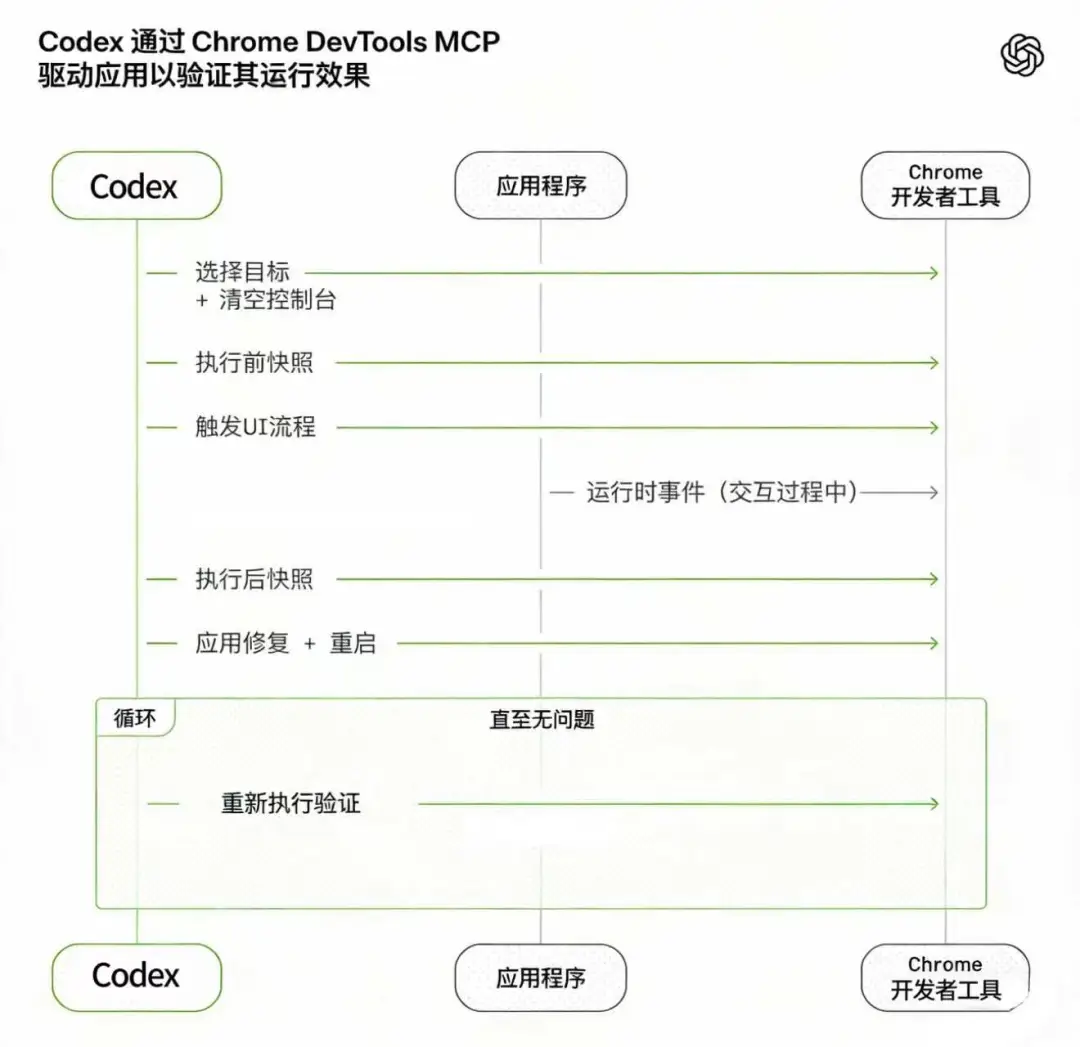
为此,他们把 Chrome 浏览器的 CDP(Chrome Dev Tools Protocol)接入了 CodeX。让 Agent 可以自己打开浏览器,操作自己开发的网页,点按钮、看截图、复现 Bug,然后验证自己写的修复到底有没有用。
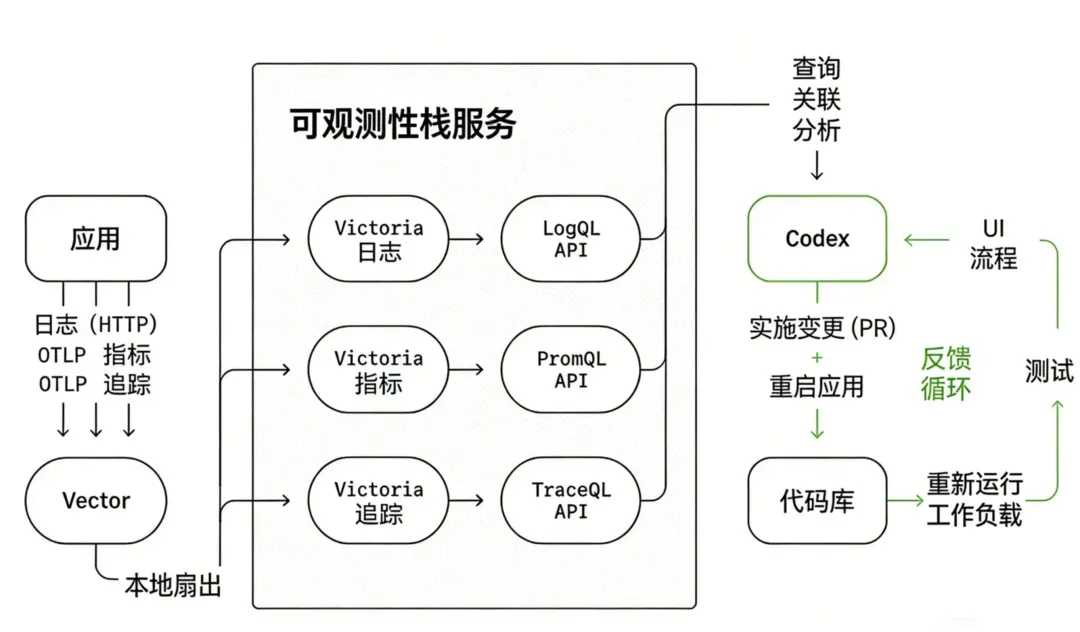
此外,他们还把可观测系统也都接入了 CodeX。使其能够用 LogQL 查 Logs,用 PromQL 查 Metrics 和 Traces。CodeX 写完代码,自己就能去查监控,确认达标了,才提交 PR。
3. 约束才是生产力
OpenAI 证明了一个 "常识",对于 AI 而而言,约束会提升效率。因为约束就意味着更高的准确性、更低的试错机率。
3.1 什么是 "依赖流向模型"?
OpenAI 设计了一个极其严格的分层架构约束,用单向依赖链来控制代码的复杂度:
bash
Types(类型定义)
↓
Config(配置层)
↓
Repo(数据仓库/数据访问层)
↓
Service(业务逻辑层)
↓
Runtime(运行时环境)
↓
UI(界面层)核心规则:依赖只能从上往下流动禁止反向依赖。
这个模型解决的是软件工程中一个经典的循环依赖问题。当 UI 层可以直接访问数据库、业务逻辑可以读取 UI 组件时,代码就会变成一团乱麻,例如:改一个按钮样式可能影响数据库查询,改一个接口可能让整个页面崩溃。
举几个具体例子来理解这条规则:
| ❌ 违规(反向依赖) | 为什么违规 | ✅ 正确做法 |
|---|---|---|
| UI 组件直接 import 数据库查询 | UI 不应该知道数据怎么存 | UI → Service → Repo → DB |
| Service 层引用 UI 状态 | 业务逻辑不应绑定界面 | UI 订阅 Service 的事件 |
| Repo 层包含业务逻辑 | 数据层只负责存取 | Repo 只做 CRUD,逻辑放 Service |
| Config 层调用 Service | 配置是最底层,不该有行为 | Service 读取 Config |
为什么这对 AI 编程特别重要? AI Agent 在写代码时,最大的问题之一就是 "随手引入依赖"。如果不加约束,Agent 可能会让一个数据模型文件引用了 React 组件,或者让一个工具函数依赖了业务逻辑。这些循环依赖在当时看起来 "能跑",但随着代码量增长会变成维护灾难。依赖流向模型本质上是在告诉 AI:"你只能在这个框架内活动",从而大幅降低出错概率。
3.2 什么是 Linter?
Linter(静态代码分析工具)是一种在代码运行之前就检查代码是否符合规范的工具。它不执行代码,只是 "读" 代码,然后根据预定义的规则报告问题。例如:
| 工具 | 检查内容 | 例子 |
|---|---|---|
| ESLint | JavaScript/TypeScript 代码风格和错误 | 变量未使用、分号缺失、== 应该用 === |
| Pylint | Python 代码质量 | 函数太长、变量命名不规范 |
| Prettier | 代码格式化 | 缩进、换行、引号风格统一 |
3.3 Linter 如何实现架构约束?
OpenAI 的关键创新不是用现成的 Linter 检查代码风格,而是编写自定义 Linter 规则来强制执行架构约束。具体实现原理:
第一步:定义依赖规则
用配置文件声明允许的依赖方向。比如 ESLint 插件 eslint-plugin-boundaries 就能做到这一点:
javascript
// eslint 配置中的架构约束规则
{
"rules": {
"boundaries/element-types": ["error", {
"default": "disallow", // 默认禁止所有跨层引用
"rules": [
{
"from": "ui", // UI 层
"allow": ["service", "types", "config"] // UI 只能引用这三层
},
{
"from": "service", // Service 层
"allow": ["repo", "types", "config"] // Service 只能引用这三层
},
{
"from": "repo", // Repo 层
"allow": ["types", "config"] // Repo 只能引用这两层
},
{
"from": "types", // Types 层
"allow": [] // Types 不依赖任何层
}
]
}]
}
}第二步:Linter 扫描 import 语句
当你写了这样的代码:
typescript
// ❌ 违规: UI 层直接引用了 Repo 层
// 文件: src/ui/UserList.tsx
import { getUserFromDB } from '../repo/userRepo'; // ← Linter 报错!Linter 会检查每个 import 语句,发现 ui/ 目录下的文件引用了 repo/ 目录,而规则里 ui 的 allow 列表里没有 repo,于是报错:
❌ error Dependency violation: 'ui' cannot import from 'repo'
Allowed: service, types, config
src/ui/UserList.tsx:3:1第三步:为 AI 优化错误信息
这是 OpenAI 最聪明的一步。普通 Linter 的报错信息是给人类看的,简短且含糊。但 AI 需要更明确、更可操作的指导。所以他们自定义了 Linter 的错误输出格式:
❌ 架构约束违规
文件: src/ui/UserList.tsx(UI 层)
违规: 引用了 src/repo/userRepo(Repo 层)
规则: UI 层 → 只能依赖 Service / Types / Config
🔧 修复方案:
1. 在 src/service/ 创建一个 UserService 来封装数据访问
2. UI 层调用 UserService,而不是直接访问 Repo
示例:
// 修改前
import { getUserFromDB } from '../repo/userRepo';
// 修改后
import { UserService } from '../service/UserService';
const users = await UserService.getUsers();可见,Linter 不仅告诉 AI "你错了",还告诉它 "怎么改"。这样 AI 就能根据报错自动修复代码,形成**"违规 → 检测 → 修复"**的自动化闭环。
3.4 实际使用的工具链
如果你想在自己的项目中实现类似的架构约束,以下是常用工具:
TypeScript/JavaScript 项目:
eslint-plugin-boundaries- 最直接的架构约束插件。eslint-plugin-import- 检查 import 来源,可以禁止特定目录的引用。- 自定义 ESLint 规则 - 用 AST 分析实现更精细的控制。
Python 项目:
import-linter(lint-imports)- 定义层间依赖规则。pylint+ 自定义检查器 - 实现更复杂的架构验证。
通用方案:
- CI 中集成 Lint 检查 - 提交 PR 时自动运行,不通过则无法合并。
- Pre-commit 钩子 - 本地提交前就拦截违规代码。
bash
# .pre-commit-config.yaml 示例
repos:
- repo: local
hooks:
- id: architecture-check
name: "检查架构约束"
entry: npx eslint --rule 'boundaries/element-types: error' src/
language: system
types: [file]
files: ^src/.*\.tsx?$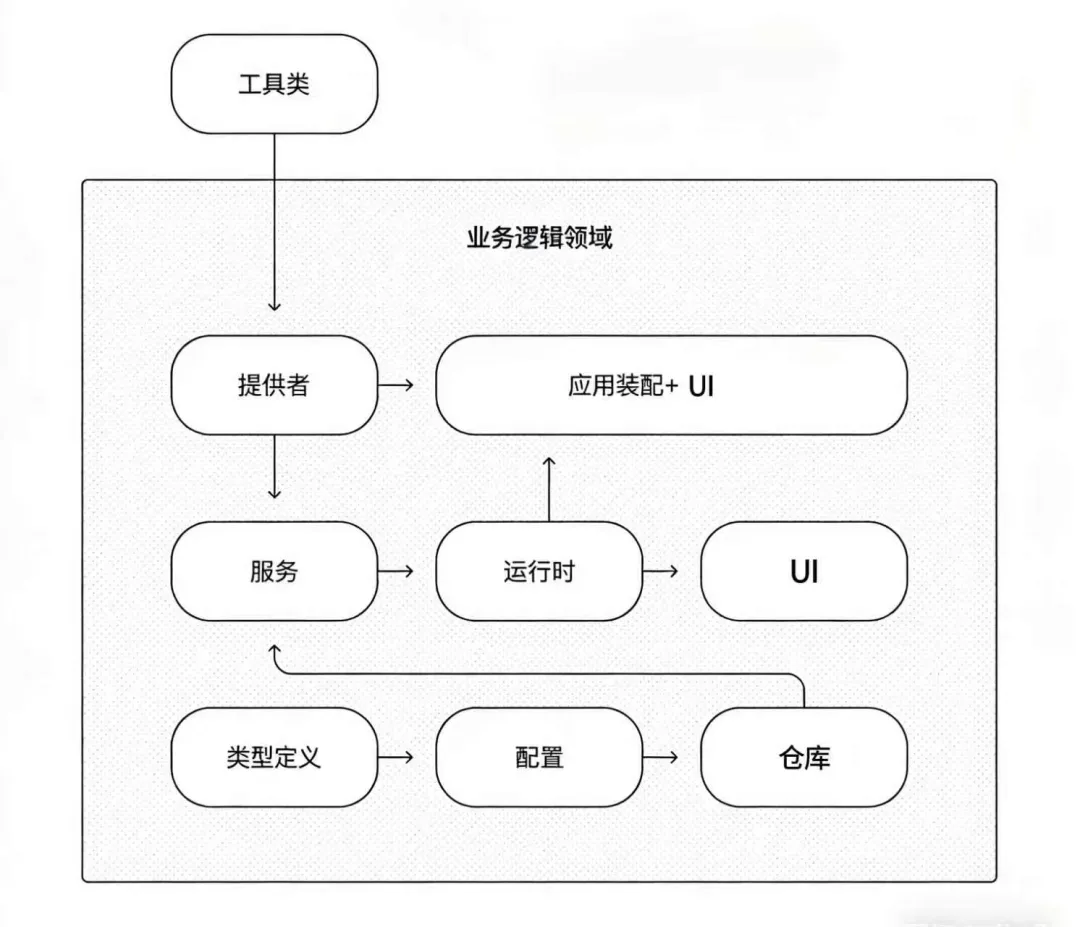
4. 定时清理 "垃圾"
AI 生成的代码 "熵增" 严重,随着时间推移代码必然会变得混乱和重复。于是,他们设立了一个让 AI 循环清理的流程,把清理原则告诉 AI,然后定期扫描文档和代码,发现过时的描述或不一致的地方,就会自动发起 PR 来修复。
bash
自动清理流程:
├── 后台 Codex 任务定期扫描偏差
├── 更新质量评级
├── 打开针对性的重构 PR
└── 大多数可在 1 分钟内审核并自动合并Harness engineering 是 AI Coding 的控制论
在 OpenAI 的报告中,Harness engineering 工程师的核心职责只剩下了 3 件事情:
-
设计环境:给 Agent 搭建自主循环的环境,包括:仓库、CI 流水线、Lint 静态检查规则、开发者工具等等。这些是 Agent 自主循环工作所依赖的基础设施。
-
明确意图:用足够清晰的语言告诉 Agent 需求是什么,而不是模糊地说 "帮我写个功能"。工程师要把需求拆解成 Agent 能理解的、无歧义的规范,SDD 就是为此而诞生的。
-
构建循环:这是最关键的一环,也是 Harness engineering 被称之为 AI 时代的 "控制论(Cybernetics)" 的原因。把 AI Agent 放进一个循环里,给它一个目标,让它反复执行(编码、审查、测试、修复),直到这个 "准出" 为止。这就是反馈闭环工程,随着成熟度的提升,可以把几乎所有的代码审查工作,都交给了 Agent 之间互相审查。过程中人类并不需要审查这些 PR。
传统循环:
bash
需求 → 人工编码 → 人工调试 → 人工测试 → 人工审查 → 人工合并
↑______________________|______|
人工循环Harness 循环:
bash
需求 → Prompt → Agent 编码 → 自动测试 → 自动修复 → Agent 审查 → 自动合并
↑__________________|
自动循环所以说,在 Harness Engineering 里,工程师变成了 "反馈循环系统" 的设计师 ------ 人类掌舵,Agent 执行 ------ 设计环境、构建反馈回路、将架构约束编成规则,然后由 AI Agent 来写代码。
Harness Engineering 的架构设计
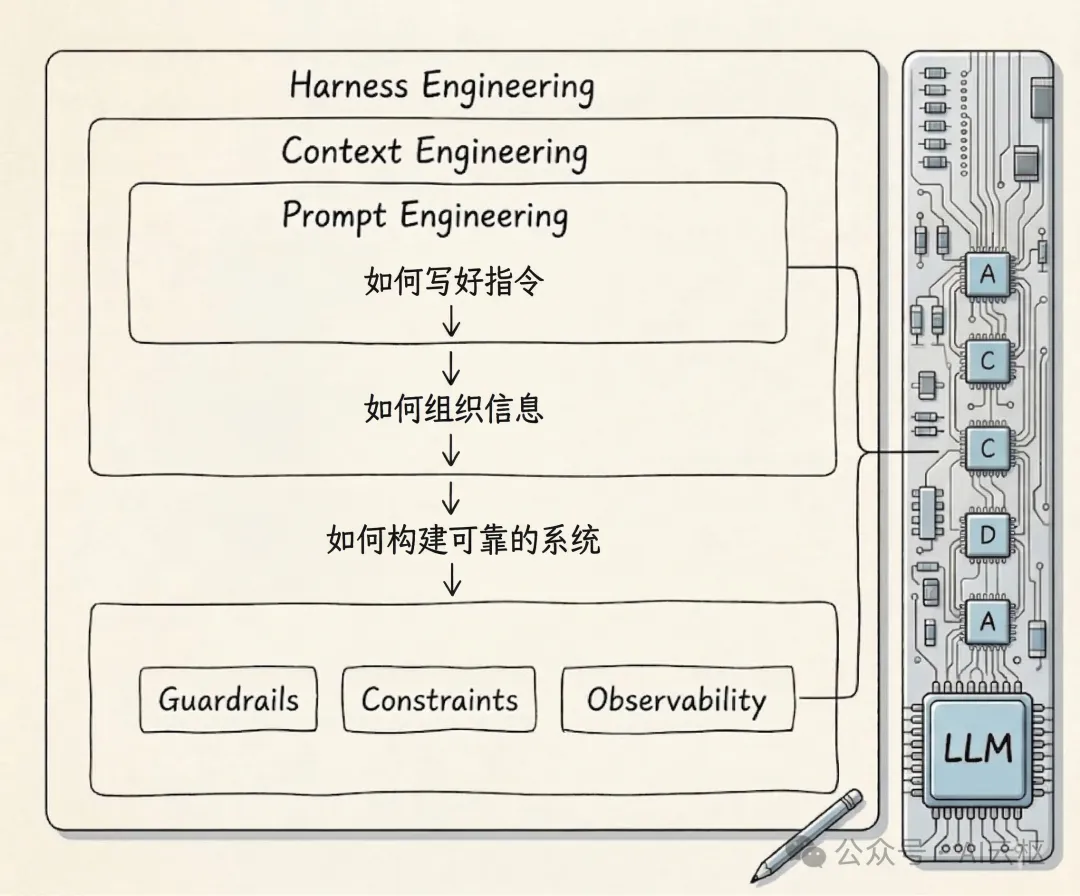
Harness Engineering 通常包含以下几个关键部分:
- 上下文管理(Context):让 Agent 获取与任务相关的代码和信息;
- 工具系统(Tools):允许 Agent 调用命令行、读写文件、操作代码仓库;
- 执行环境(Execution):可以运行代码并获取结果;
- 反馈机制(Feedback Loop):通过测试、日志或指标判断代码是否正确。
当这些组件组合在一起时,AI 的行为就会发生质变,它不再只是生成文本,而是在一个真实的工程环境中 "行动"。
1. 上下文工程(Context Engineering)
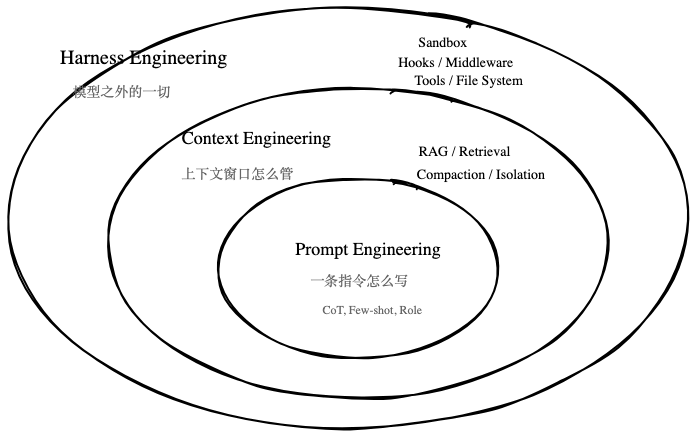
Prompt Engineering(提示词工程):2023 年,LLM 的输出质量极度依赖 Prompt 的质量,进而催生了提示词工程。工程师们精心设计了各种 Prompt 格式、Role 角色以及 Few-shot(少样本学习)、Chain-of-Thought(思维链)等技巧,引导 LLM 输出更准确的结果。但这个阶段的本质,仍然是单次交互的优化。每次对话都是独立的,LLm 缺乏对项目整体上下文的理解,也无法持续跟踪复杂任务的进展。这就好比让一个能力极强的实习生处理零散任务,每次都要重新交代背景。
Context Engineering(上下文工程):2025 年,业界发展从如何提问转向了如何构建上下文,Andrej Karpathy 首次提出了上下文工程 ------ AI 的能力边界,不是大模型本身,而是你给它的上下文是什么。围绕着 "珍贵的上下文窗口" 发展了一系列技术体系,包括:分层记忆系统、RAG 系统、上下文压缩、会话隔离等等。
bash
Context Engineering
├── RAG(检索增强生成)
├── Memory(对话历史、用户画像)
├── Tool Definitions(工具定义)
├── Few-shot Examples(示例引导)
└── System Instructions(系统指令)实际上,上下文的质量远比数量更重要,因为过大的上下文会分散模型的注意力,结果可能导致决策质量下降。所以,上下文工程的核心是一种 "信息筛选机制",目标就是把恰到好处的业务信息、工程规范、上下文逻辑精准传递给 AI,使得 AI 能够准确理解你的意图。
在 AI 编程场景中,人类程序员可以快速扫视页面、跳读、定位关键区域、忽略噪音;但大模型不是这样工作的。大模型是按 token 顺序处理信息的,它没有真正意义上的 "扫视能力",也不会天然忽略上下文里的无关噪音。你给它一大段冗余输出,不是在帮助它,而是在污染它的工作记忆。
这也是为什么很多 agent 在真实代码库里会迅速失控:
- 搜索命令返回几千行结果
- 模型被无关信息淹没
- 开始反复 grep、反复查看文件
- 上下文越来越脏
- 最后不是答错,就是彻底卡住
而做好上下文工程,能解决 AI 编程的 3 大痛点:
- 上下文污染(幻觉信息混入);
- 上下文过载(信息太多导致 AI 性能骤降);
- 工具混淆(工具太多导致 AI 调用出错)。
而做好这件事的关键,不在于喂给 AI 多少信息,而在于精准筛选、合理组织、动态管理,比如:用 RAG 技术筛选核心业务文档,用结构化方式组织工程规范,用隔离策略避免无关信息干扰。
上下文工程的阶段解决了 AI 的信息孤岛问题,让 AI 能够基于更全面的信息进行推理。然而,"知道得多" 不等于 "知道怎么做才对"。所以,2026 年,技术发展来到了 **Harness Engineering(驾驭工程)**阶段。
2. 工具和执行环境
Harness Engineering 的核心思想之一,就是让 Agent 能够调用真实工具。例如:
- 使用 CLI 操作代码仓库
- 运行测试脚本
- 修改文件并提交变更
- 调用构建系统
在这种模式下,AI 不再只是写代码,而是可以完成完整任务流程,例如:
- 阅读需求
- 修改代码
- 运行测试
- 根据报错信息修复问题
这个过程与人类工程师的工作方式高度一致。
3. Feedback Loop
传统 Prompt 的流程通常是一次性的:输入问题 → 生成答案 → 结束。
但在真实的软件工程中,解决问题往往需要多次尝试。代码写完之后,需要运行测试、查看错误、进行修复,直到系统正常工作。
Harness Engineering 引入的反馈闭环正是为了解决这个问题。Agent 可以通过运行代码获得真实反馈,例如测试失败、编译错误或性能问题,然后根据这些信息再次修改代码。
这种循环让 AI 的行为从 "猜答案" 变成 "逐步逼近正确解"。随着迭代次数增加,结果通常会越来越稳定。
4. 实时可观测
对于人类工程师来说,调试系统依赖的是日志、指标和监控信息。AI 其实也需要类似的数据来理解系统状态。
因此 Harness Engineering 还强调一个重要概念:Legibility(可读性)。也就是说,需要把系统状态转换成模型能够理解的信号。例如:
- 日志摘要
- 错误堆栈信息
- 性能指标
- UI 截图
这些信息能够帮助 Agent 判断问题发生在哪里,并推理下一步操作。
如果系统对 AI 来说是一个完全的黑盒,它就无法有效调试和修复问题。
5. 架构约束(Architectural Constraints)
架构约束(Architectural Constraints)采用一系列工具对软件的架构进行约束,比如 Pre-commit 钩子令代码提交前的自动检查;CI 门控令 PR 合并前必须通过所有检查;自定义 Linter 令代码符合自定义的静态检查规则。
6. 熵管理(Entropy Management)
熵管理(Entropy Management)随着时间的推移,AI 生成的代码库会积累熵,比如代码和规范文档脱节、死代码堆积等等。为了降低熵,可以采用人工清理;也可以使用交叉验证 Agent 进行周期性扫描的方式进行自动清理。
Harness Engineering 案例实践
为了更直观地理解 Harness Engineering,我们设定一个具体的场景:开发一个前后端分离的订单管理系统,前端使用 JavaScript,后端使用 Python,数据库使用 MySQL。下面从软件清单、项目结构、核心实践三个方面完整展开。
软件清单
基础设施
| 类别 | 软件 | 版本建议 | 用途 |
|---|---|---|---|
| 操作系统 | Ubuntu Server | 22.04 LTS | 服务器运行环境 |
| 容器 | Docker | 27.x | 应用容器化部署 |
| 容器编排 | Docker Compose | 2.x | 本地多服务编排(MySQL + Redis + 后端 + 前端) |
| 数据库 | MySQL | 8.0+ | 关系型数据存储 |
| 缓存 | Redis | 7.x | 会话缓存、热点数据缓存 |
后端(Python)
| 类别 | 软件 | 版本建议 | 用途 |
|---|---|---|---|
| 语言 | Python | 3.12+ | 后端开发语言 |
| 包管理 | uv | 0.4+ | 高性能 Python 包管理器(替代 pip) |
| Web 框架 | FastAPI | 0.115+ | 异步 API 框架,自带 OpenAPI 文档 |
| ORM | SQLAlchemy | 2.0+ | 数据库访问层 |
| 数据库驱动 | pymysql | 1.1+ | MySQL 连接驱动 |
| 数据校验 | Pydantic | 2.x | 请求/响应数据校验(FastAPI 内建依赖) |
| 认证 | python-jose | 3.3+ | JWT Token 生成与验证 |
| 测试 | pytest | 8.x | 单元测试框架 |
| pytest-cov | 5.x | 测试覆盖率统计 | |
| pytest-asyncio | 0.24+ | 异步测试支持 | |
| httpx | 0.27+ | 异步 HTTP 客户端(测试 API) | |
| 代码质量 | Ruff | 0.8+ | Python Linter + 格式化(替代 pylint + black) |
| import-linter | 2.x | 架构约束检查(依赖方向控制) | |
| mypy | 1.x | 类型检查 | |
| Pre-commit | pre-commit | 4.x | Git 提交前自动检查 |
前端(JavaScript)
| 类别 | 软件 | 版本建议 | 用途 |
|---|---|---|---|
| 语言 | JavaScript | ES2022+ | 前端开发语言 |
| 包管理 | pnpm | 9.x | 高性能 Node.js 包管理器 |
| 运行时 | Node.js | 22.x LTS | 前端构建运行环境 |
| 框架 | React | 19.x | UI 组件框架 |
| 构建工具 | Vite | 6.x | 前端构建打包 |
| 路由 | React Router | 7.x | 前端路由 |
| HTTP 客户端 | Axios | 1.x | API 请求 |
| 状态管理 | Zustand | 5.x | 轻量级全局状态管理 |
| 测试 | Vitest | 2.x | 单元测试 |
| Playwright | 1.49+ | 端到端测试 + 浏览器自动化 | |
| 代码质量 | ESLint | 9.x | JavaScript Linter |
| eslint-plugin-boundaries | 4.x | 前端架构约束检查 | |
| Prettier | 3.x | 代码格式化 |
CI/CD 平台
| 类别 | 软件 | 用途 |
|---|---|---|
| CI 平台 | GitHub Actions | 持续集成(Lint、测试、架构检查) |
| 代码托管 | GitHub | 代码仓库、PR 管理、代码审查 |
| Agent 编码工具 | OpenAI Codex / Claude Code / Cursor | AI Agent 自主编码 |
| PR 自动审查 | Codex CLI / Claude CLI | Agent 自动代码审查 |
可观测性
| 类别 | 软件 | 用途 |
|---|---|---|
| 日志采集 | Loki | 结构化日志存储 |
| 日志查询 | LogCLI | Agent 通过 LogQL 查询日志 |
| 指标监控 | Prometheus | 系统和业务指标采集 |
| 指标查询 | PromCLI | Agent 通过 PromQL 查询指标 |
| 可视化 | Grafana | 监控看板展示 |
| 告警 | Alertmanager | 异常告警通知 |
| APM | Jaeger | 分布式链路追踪 |
开发辅助
| 类别 | 软件 | 用途 |
|---|---|---|
| 版本控制 | Git | 代码版本管理 |
| API 调试 | httpie / curl | 手动测试 API 接口 |
| 数据库管理 | DBeaver | MySQL 可视化管理 |
| 容器管理 | Portainer(可选) | Docker 可视化管理面板 |
项目结构
bash
harness-project/
│
├── 📋 AGENTS.md # Agent 入口导航文件(≈100 行,只做目录)
├── 📋 ARCHITECTURE.md # 架构总览
│
├── 📁 docs/ # 深层规范文档
│ ├── architecture/
│ │ ├── overview.md # 分层架构图 + 各层职责
│ │ └── dependency-rules.md # 依赖方向规则
│ ├── design/
│ │ ├── decisions/ # ADR 架构决策记录
│ │ └── constraints.md # 编码约束规则
│ ├── plans/
│ │ ├── active/ # 进行中的任务
│ │ └── tech-debt.md # 技术债追踪
│ └── quality/
│ └── metrics.md # 质量指标
│
├── 📁 backend/ # Python 后端
│ ├── pyproject.toml # 项目配置 + 依赖声明(uv 管理)
│ ├── uv.lock # 依赖锁文件
│ ├── alembic.ini # 数据库迁移配置
│ ├── alembic/ # 迁移脚本目录
│ │ └── versions/ # 数据库版本迁移文件
│ │
│ ├── app/
│ │ ├── __init__.py
│ │ ├── types/ # 最底层:纯类型定义,零依赖
│ │ │ ├── __init__.py
│ │ │ ├── user.py # 用户相关类型(Pydantic Model)
│ │ │ └── order.py # 订单相关类型(Pydantic Model)
│ │ │
│ │ ├── config/ # 配置层:环境变量、常量
│ │ │ ├── __init__.py
│ │ │ ├── settings.py # Pydantic Settings(读取 .env)
│ │ │ └── constants.py # 业务常量定义
│ │ │
│ │ ├── repo/ # 数据访问层:只做 CRUD
│ │ │ ├── __init__.py
│ │ │ ├── base.py # SQLAlchemy Base + 通用 CRUD 基类
│ │ │ ├── user_repo.py # 用户数据访问
│ │ │ └── order_repo.py # 订单数据访问
│ │ │
│ │ ├── service/ # 业务逻辑层:核心规则
│ │ │ ├── __init__.py
│ │ │ ├── auth_service.py # 认证服务(登录、注册、JWT)
│ │ │ ├── user_service.py # 用户业务逻辑
│ │ │ └── order_service.py # 订单业务逻辑
│ │ │
│ │ ├── api/ # 接口层:HTTP 路由
│ │ │ ├── __init__.py
│ │ │ ├── deps.py # 依赖注入(数据库会话、当前用户)
│ │ │ ├── router.py # 总路由注册
│ │ │ └── v1/
│ │ │ ├── __init__.py
│ │ │ ├── auth.py # 认证接口(/api/v1/auth/*)
│ │ │ ├── users.py # 用户接口(/api/v1/users/*)
│ │ │ └── orders.py # 订单接口(/api/v1/orders/*)
│ │ │
│ │ └── main.py # FastAPI 应用入口
│ │
│ ├── tests/
│ │ ├── conftest.py # 测试夹具(测试数据库、测试客户端)
│ │ ├── unit/ # 单元测试(mock 数据库)
│ │ └── integration/ # 集成测试(连接真实数据库)
│ │
│ └── scripts/
│ ├── query-logs.sh # Agent 调用的日志查询脚本
│ └── query-metrics.sh # Agent 调用的指标查询脚本
│
├── 📁 frontend/ # JavaScript 前端
│ ├── package.json
│ ├── pnpm-lock.yaml
│ ├── vite.config.js
│ │
│ ├── src/
│ │ ├── types/ # 前端类型定义(与后端 types 对齐)
│ │ │ ├── user.js
│ │ │ └── order.js
│ │ │
│ │ ├── config/ # 前端配置
│ │ │ ├── api.js # API 基地址、超时配置
│ │ │ └── constants.js
│ │ │
│ │ ├── services/ # API 调用封装(对应后端 service)
│ │ │ ├── authService.js # 登录/注册 API 调用
│ │ │ ├── userService.js # 用户 API 调用
│ │ │ └── orderService.js # 订单 API 调用
│ │ │
│ │ ├── hooks/ # React Hooks(状态逻辑)
│ │ │ ├── useAuth.js # 认证状态管理
│ │ │ └── useOrders.js # 订单列表状态管理
│ │ │
│ │ ├── pages/ # 页面组件(只能依赖 services/hooks/types)
│ │ │ ├── Login.js
│ │ │ ├── OrderList.js
│ │ │ └── OrderDetail.js
│ │ │
│ │ ├── components/ # 通用组件
│ │ │ ├── Layout.js
│ │ │ └── Pagination.js
│ │ │
│ │ ├── App.js # 应用入口
│ │ └── main.js # 渲染入口
│ │
│ ├── tests/
│ │ ├── unit/ # Vitest 单元测试
│ │ └── e2e/ # Playwright 端到端测试
│ │ ├── login.spec.js
│ │ └── orders.spec.js
│ │
│ └── scripts/
│ └── browser-agent.js # Agent 浏览器自动化脚本
│
├── 📁 infra/ # 基础设施配置
│ ├── docker-compose.yml # 本地开发环境(MySQL + Redis)
│ ├── docker-compose.prod.yml # 生产环境编排
│ ├── prometheus/
│ │ └── prometheus.yml # Prometheus 采集配置
│ ├── grafana/
│ │ └── dashboards/ # 监控看板 JSON
│ └── loki/
│ └── loki-config.yml # Loki 日志配置
│
├── 📁 .github/workflows/ # CI/CD 流水线
│ ├── backend-lint.yml # 后端 Ruff 检查
│ ├── backend-test.yml # 后端 pytest 测试
│ ├── frontend-lint.yml # 前端 ESLint 检查
│ ├── frontend-test.yml # 前端 Vitest 测试
│ ├── arch-check.yml # 架构约束验证
│ ├── agent-review.yml # Agent 自动审查
│ └── entropy-cleanup.yml # 熵管理自动清理
│
├── .pre-commit-config.yaml # Pre-commit 钩子(前后端统一)
├── .env.example # 环境变量模板
└── Makefile # 统一命令入口AGENTS.md 示例
bash
# AGENTS.md
## 项目简介
前后端分离的订单管理系统,前端 React,后端 FastAPI,数据库 MySQL。
## 技术栈
- 前端:JavaScript + React 19 + Vite 6
- 后端:Python 3.12 + FastAPI + SQLAlchemy
- 数据库:MySQL 8.0
- 缓存:Redis 7
- 部署:Docker + Docker Compose
## 快速开始
### 后端
cd backend && uv sync # 安装依赖
uv run alembic upgrade head # 执行数据库迁移
uv run uvicorn app.main:app --reload # 启动开发服务器(端口 8000)
### 前端
cd frontend && pnpm install # 安装依赖
pnpm dev # 启动开发服务器(端口 3000)
### 基础设施
cd infra && docker compose up -d # 启动 MySQL + Redis
## 测试
make test-backend # 后端单元测试 + 集成测试(覆盖率 ≥ 80%)
make test-frontend # 前端单元测试(Vitest)
make test-e2e # 端到端测试(Playwright)
make test-all # 全部测试
## 架构原则
- 后端依赖方向:types → config → repo → service → api(单向流动,禁止反向)
- 前端依赖方向:types → config → services → hooks → pages(单向流动,禁止反向)
- 前后端之间只通过 REST API 通信,前端不直接访问数据库
- 详见:docs/architecture/dependency-rules.md
## 编码规范
- 后端:Ruff(Lint + 格式化),mypy(类型检查)
- 前端:ESLint + Prettier
- 文件不超过 200 行,函数不超过 30 行
- 详见:docs/design/constraints.md
## 常见陷阱
- ⚠️ 不要在 repo 层写业务逻辑(只做 CRUD)
- ⚠️ 不要在 api 层直接操作数据库(通过 service 层)
- ⚠️ 前端不要使用 fetch 直接调用 API(统一通过 services/ 层)
- ✅ 数据库变更必须通过 alembic 迁移,禁止手动修改表结构
- ✅ 错误统一用 service 层抛出自定义异常,api 层统一捕获处理
## 深入阅读
- 架构详情:docs/architecture/overview.md
- 设计原则:docs/design/constraints.md
- 技术债追踪:docs/plans/tech-debt.mdMakefile 统一命令入口
bash
.PHONY: dev test lint
# 开发环境启动
dev:
cd infra && docker compose up -d
cd backend && uv run uvicorn app.main:app --reload &
cd frontend && pnpm dev
# 后端测试
test-backend:
cd backend && uv run pytest --cov=app --cov-report=term-missing --cov-fail-under=80
# 前端测试
test-frontend:
cd frontend && pnpm test
# 端到端测试
test-e2e:
cd frontend && pnpm exec playwright test
# 全部测试
test-all: test-backend test-frontend test-e2e
# 后端 Lint
lint-backend:
cd backend && uv run ruff check app/ tests/
cd backend && uv run ruff format --check app/ tests/
cd backend && uv run mypy app/
# 前端 Lint
lint-frontend:
cd frontend && pnpm lint
# 架构约束检查
arch-check:
cd backend && uv run lint-imports
cd frontend && pnpm lint --rule 'boundaries/element-types: error' src/
# 全部 Lint
lint: lint-backend lint-frontend arch-check
# 数据库迁移
db-migrate:
cd backend && uv run alembic upgrade head
db-makemigration:
cd backend && uv run alembic revision --autogenerate -m "$(msg)"后端:自定义 Linter 实现架构约束
使用 import-linter 控制依赖方向
bash
# backend/.importlinter
[importlinter]
root_packages = app
[importlinter:contract:backend-layers]
name = 后端分层架构约束
type = layers
layers = api service repo config types
containers = app这条规则意味着:api 可以 import service,service 可以 import repo,但 repo 不能反过来 import service。一旦违反,lint-imports 就会报错:
bash
$ uv run lint-imports
app.repo.order_repo -> app.service.order_service (api -> service -> repo)
LINTER ERROR: app.repo.order_repo -> app.service.order_service violates contract '后端分层架构约束'使用 Ruff 进行代码质量检查
bash
# backend/pyproject.toml 中的 Ruff 配置
[tool.ruff]
line-length = 100
[tool.ruff.lint]
select = [
"E", # pycodestyle 错误
"F", # pyflakes
"I", # isort(import 排序)
"N", # pep8-naming(命名规范)
"UP", # pyupgrade(自动升级旧语法)
"B", # flake8-bugbear(常见 Bug 检测)
"SIM", # flake8-simplify(代码简化建议)
]
ignore = ["E501"] # 行长度由 formatter 处理
[tool.ruff.lint.per-file-ignores]
"__init__.py" = ["F401"] # __init__.py 允许未使用的 import前端:自定义 Linter 实现架构约束
使用 eslint-plugin-boundaries
bash
cd frontend && pnpm add -D eslint @eslint/js eslint-plugin-boundaries
javascript
// frontend/eslint.config.js
import boundaries from 'eslint-plugin-boundaries';
export default [
{
files: ['src/**/*.{js,jsx}'],
plugins: { boundaries },
rules: {
'boundaries/element-types': ['error', {
default: 'disallow',
rules: [
{ from: 'types', allow: [] },
{ from: 'config', allow: ['types'] },
{ from: 'services', allow: ['types', 'config'] },
{ from: 'hooks', allow: ['types', 'config', 'services'] },
{ from: 'pages', allow: ['types', 'config', 'services', 'hooks'] },
{ from: 'components', allow: ['types', 'config', 'hooks'] },
],
}],
},
settings: {
'boundaries/elements': [
{ type: 'types', pattern: 'src/types/**' },
{ type: 'config', pattern: 'src/config/**' },
{ type: 'services', pattern: 'src/services/**' },
{ type: 'hooks', pattern: 'src/hooks/**' },
{ type: 'pages', pattern: 'src/pages/**' },
{ type: 'components', pattern: 'src/components/**' },
],
},
},
];Docker Compose 本地开发环境
yaml
# infra/docker-compose.yml
services:
mysql:
image: mysql:8.0
container_name: harness-mysql
environment:
MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD:-devpass}
MYSQL_DATABASE: ${MYSQL_DATABASE:-harness_db}
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "localhost"]
interval: 10s
retries: 5
redis:
image: redis:7-alpine
container_name: harness-redis
ports:
- "6379:6379"
prometheus:
image: prom/prometheus:v2.54
container_name: harness-prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
loki:
image: grafana/loki:2.9
container_name: harness-loki
ports:
- "3100:3100"
grafana:
image: grafana/grafana:11
container_name: harness-grafana
ports:
- "3001:3000"
environment:
GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_PASSWORD:-admin}
depends_on:
- prometheus
- loki
volumes:
mysql_data:CI/CD 流水线
后端质量门控
yaml
# .github/workflows/backend-quality.yml
name: Backend Quality Gate
on: [pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: astral-sh/setup-uv@v4
- name: 安装依赖
run: cd backend && uv sync
- name: Ruff 检查
run: cd backend && uv run ruff check app/ tests/
- name: 类型检查
run: cd backend && uv run mypy app/
- name: 架构约束检查
run: cd backend && uv run lint-imports
test:
runs-on: ubuntu-latest
services:
mysql:
image: mysql:8.0
env:
MYSQL_ROOT_PASSWORD: testpass
MYSQL_DATABASE: test_db
ports: ["3306:3306"]
options: >-
--health-cmd "mysqladmin ping"
--health-interval 10s
--health-timeout 5s
--health-retries 5
steps:
- uses: actions/checkout@v4
- uses: astral-sh/setup-uv@v4
- name: 安装依赖
run: cd backend && uv sync
- name: 运行测试
run: cd backend && uv run pytest --cov=app --cov-report=term-missing --cov-fail-under=80
env:
DATABASE_URL: mysql+pymysql://root:testpass@127.0.0.1:3306/test_db前端质量门控
yaml
# .github/workflows/frontend-quality.yml
name: Frontend Quality Gate
on: [pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: pnpm/action-setup@v4
- uses: actions/setup-node@v4
with:
node-version: 22
cache: pnpm
cache-dependency-path: frontend/pnpm-lock.yaml
- name: 安装依赖
run: cd frontend && pnpm install
- name: ESLint 检查
run: cd frontend && pnpm lint
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: pnpm/action-setup@v4
- uses: actions/setup-node@v4
with:
node-version: 22
cache: pnpm
cache-dependency-path: frontend/pnpm-lock.yaml
- name: 安装依赖
run: cd frontend && pnpm install
- name: 单元测试
run: cd frontend && pnpm test --coverage
- name: 端到端测试
run: cd frontend && pnpm exec playwright install && pnpm exec playwright test可观测性:Agent 的查询脚本
bash
# backend/scripts/query-logs.sh
#!/bin/bash
# 用法:./query-logs.sh --level error --last 1h
SERVICE="${SERVICE:-harness-backend}"
LEVEL="${LEVEL:-error}"
RANGE="${RANGE:-1h}"
QUERY="{service=\"$SERVICE\", level=\"$LEVEL\"}"
END=$(date +%s)
START=$(($(date -v-${RANGE} +%s 2>/dev/null || date -d "-${RANGE}" +%s)))
curl -s "http://localhost:3100/loki/api/v1/query_range?query=$QUERY&limit=100&start=$START&end=$END&direction=backward" | python3 -m json.tool
bash
# backend/scripts/query-metrics.sh
#!/bin/bash
# 用法:./query-metrics.sh --metric http_requests_total
METRIC="${METRIC:-http_requests_total}"
curl -s "http://localhost:9090/api/v1/query?query=$METRIC" | python3 -m json.tool浏览器自动化:Agent 的 UI 验证
javascript
// frontend/scripts/browser-agent.js
const { chromium } = require('playwright');
async function verifyUI(url) {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
await page.goto(url);
// 截图用于 Agent 视觉验证
await page.screenshot({ path: 'screenshots/verify.png', fullPage: true });
// DOM 快照用于 Agent 结构验证
const dom = await page.content();
// 模拟用户操作:登录
await page.fill('#username', 'testuser');
await page.fill('#password', 'testpass');
await page.click('button[type="submit"]');
await page.waitForURL('**/orders');
// 验证订单列表加载
const orderCount = await page.locator('.order-item').count();
await browser.close();
return { screenshot: 'screenshots/verify.png', dom, orderCount };
}
// 从命令行调用
const url = process.argv[2] || 'http://localhost:3000';
verifyUI(url).then(r => console.log(JSON.stringify(r, null, 2)));Agent 自动审查工作流
yaml
# .github/workflows/agent-review.yml
name: Agent Review
on: [pull_request]
jobs:
self-review:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Agent 自我审查(Codex)
run: |
npx codex --approval-mode full-auto \
"审查当前 PR 的所有变更:检查架构约束是否违反、是否有测试遗漏、代码质量是否达标。输出审查报告。"
cross-review:
needs: self-review
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Agent 交叉审查(Claude,用另一个模型审查)
run: |
npx claude --print \
"作为代码审查员,审查这个 PR。重点关注:边界情况、安全隐患、性能问题。如果发现问题,指出文件和行号。"熵管理:自动清理
yaml
# .github/workflows/entropy-cleanup.yml
name: Entropy Cleanup
on:
schedule:
- cron: '0 2 * * 1' # 每周一凌晨 2 点
jobs:
scan-backend:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: astral-sh/setup-uv@v4
- run: cd backend && uv sync
- name: Agent 扫描后端代码熵
run: |
npx codex --approval-mode full-auto \
"扫描 backend/ 目录:
1. 找出所有没有被 import 的 Python 文件(死代码)
2. 找出与代码不一致的文档注释
3. 找出超过 200 行的文件,建议拆分
4. 找出重复的代码片段
对每个发现创建一个修复 PR"
scan-frontend:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: pnpm/action-setup@v4
- uses: actions/setup-node@v4
with:
node-version: 22
- run: cd frontend && pnpm install
- name: Agent 扫描前端代码熵
run: |
npx codex --approval-mode full-auto \
"扫描 frontend/src/ 目录:
1. 找出所有没有被 import 的 JS 文件(死代码)
2. 找出与代码不一致的文档注释
3. 找出超过 200 行的文件,建议拆分
4. 找出重复的代码片段
对每个发现创建一个修复 PR"Pre-commit 钩子配置
yaml
# .pre-commit-config.yaml
repos:
# 后端 Python 检查
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.0
hooks:
- id: ruff
args: [--fix]
- id: ruff-format
# 通用检查
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v5.0.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
args: [--maxkb=500]
# 前端检查
- repo: local
hooks:
- id: eslint-frontend
name: ESLint(前端)
entry: sh -c 'cd frontend && pnpm lint'
language: system
types: [file]
files: ^frontend/.*\.js$
- id: import-lint-backend
name: 架构约束检查(后端)
entry: sh -c 'cd backend && uv run lint-imports'
language: system
types: [file]
files: ^backend/.*\.py$安装方式:
bash
pip install pre-commit
pre-commit install # 安装 Git 钩子
pre-commit run --all-files # 手动全量检查最后
工程师的高价值不再只是 "把功能写出来",而是 "搭出一个让 Agent 能持续、可靠、低摩擦产出的环境"。这就是 Harness Engineering 的真正意义。