六.提示词
6.1 定义
Prompt是引导Al模型生成特定输出的输入格式,Prompt的设计和措辞会显著影响模型的响应。
我们平常的输入是:

Prompt > Message>String 简单的文本字符串提问
6.2 Prompt中的四大角色(Role)

| 角色 (Role) | 直观比喻 | 核心任务 | 实际开发中的典型内容 |
|---|---|---|---|
| SYSTEM | 导演 | 设定规则与人设。它在对话最开始运行,AI 不会直接回答它,但会全程遵守。 | "你是一个 Java 高级架构师"、"请务必用中文回答"、"禁止讨论政治"。 |
| USER | 甲方 | 下达指令。代表真实用户的提问或操作请求。 | "帮我写一个快速排序"、"总结一下这段文档"。 |
| ASSISTANT | 演员 | 提供答案 。由 AI 生成的消息。存入历史记录后,它能让 AI 记得自己之前说过什么。 | "好的,这是为您生成的排序代码..."、"根据上下文,我的看法是..."。 |
| TOOL | 外部专家 | 返回执行结果 。当 AI 需要调用外部函数(如查天气、搜数据库)后,反馈回来的原始数据。 | "查询结果:2026-03-24 长沙天气晴"、"数据库返回:用户 ID 为 123"。 |
6.3 案例实现
和之前一样,仍然是新建子模块module,改pom,写yml,写启动,配置类接着来看Controller:
提示词之四大角色编码第一版:
java
@RestController
public class PromptController
{
//V2 通过ChatClient实现stream实现流式输出
@Resource(name = "deepseekChatClient")
private ChatClient deepseekChatClient;
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
// http://localhost:8005/prompt/chat?question=火锅介绍下
@GetMapping(value = "/prompt/chat")
public Flux<String> chat(@RequestParam("question") String question)
{
return deepseekChatClient.prompt()
//ai能力边界
.system("你是一个法律助手,只回答法律问题,其它问题回复,我只能回答法律相关问题,其它无可奉告")
.user(question)
.stream().content();
}
}
提示词之四大角色编码第二版:
记忆对话,累计回答

java
@GetMapping("/prompt/chat4")
public String chat4(String question)
{
AssistantMessage assistantMessage = deepseekChatClient.prompt()
.user(question)
.call()
.chatResponse()
.getResult()
.getOutput();
return assistantMessage.getText();
}提示词之四大角色编码第三版:
java
/**
* http://localhost:8005/prompt/chat5?city=北京
* 近似理解Tool后面章节讲解......
* @param city
* @return
*/
@GetMapping("/prompt/chat5")
public String chat5(String city)
{
String answer = deepseekChatClient.prompt()
.user(city + "未来3天天气情况如何?")
.call()
.chatResponse()
.getResult()
.getOutput()
.getText();
ToolResponseMessage toolResponseMessage =
new ToolResponseMessage(
List.of(new ToolResponseMessage.ToolResponse("1","获得天气",city)
)
);
String toolResponse = toolResponseMessage.getText();
String result = answer + toolResponse;
return result;
}七.提示词模板Prompt Template
简单理解Prompt Template,即为构建词写死,提示词配置。所以提示词模板意为引入占位符(如{占位符变量名})以动态插入内容
7.1 基本开发步骤
前面的基本步骤和以往一致: 建子模块,改pom,写yml,主启动,写config类,接下来主要对业务类的重点步骤介绍:
转化流程 (三步走)
New:创建
PromptTemplate实例。Create:传入
Map填充数据,产生Prompt对象。Chat :将
Prompt喂给客户端执行。
java
package com.alibaba.controller;
import jakarta.annotation.Resource;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.chat.prompt.SystemPromptTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import org.springframework.beans.factory.annotation.Value;
import java.util.List;
import java.util.Map;
@RestController
public class PromptTemplateController
{
@Resource(name = "deepseek")
private ChatModel deepseekChatModel;
@Resource(name = "qwen")
private ChatModel qwenChatModel;
@Resource(name = "deepseekChatClient")
private ChatClient deepseekChatClient;
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
/**
* 测试地址
* http://localhost:8006/prompttemplate/chat?topic=java&output_format=html&wordCount=200
*/
@GetMapping("/prompttemplate/chat")
public Flux<String> chat(String topic, String output_format, String wordCount)
{
PromptTemplate promptTemplate = new PromptTemplate("" +
"讲一个关于{topic}的故事" +
"并以{output_format}格式输出," +
"字数在{wordCount}左右");
// PromptTempate -> Prompt
//得到提示词模板之后,需要转化为提示词
Prompt prompt = promptTemplate.create(Map.of(
"topic", topic,
"output_format",output_format,
"wordCount",wordCount));
return deepseekChatClient.prompt(prompt).stream().content();
}
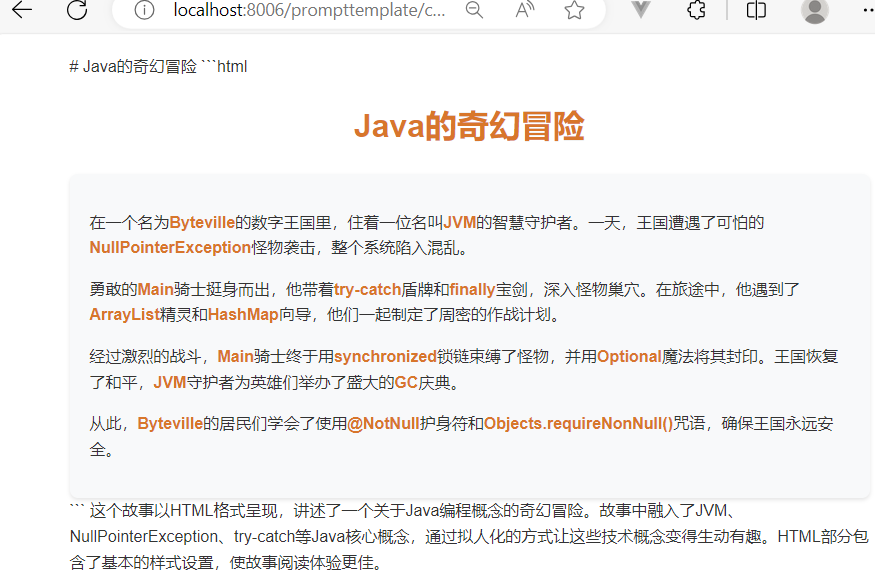
}测试结果:
7.2 读取配置文件构成模板
在代码中写死模板并不常用,因此需要像图示一样改变:
此时Controller新增部分:
java
@Value("classpath:/prompttemplate/atguigu-template.txt")
private org.springframework.core.io.Resource userTemplate;
@GetMapping("/prompttemplate/chat2")
public String chat2(@RequestParam("topic") String topic, @RequestParam("output_format") String output_format)
{
PromptTemplate promptTemplate = new PromptTemplate(userTemplate);
Prompt prompt = promptTemplate.create(Map.of("topic", topic, "output_format", output_format));
return deepseekChatClient.prompt(prompt).call().content();
}测试结果如下:

7.3 角色设定和边界划分
java
/**
* @Description:
* 系统消息(SystemMessage):设定AI的行为规则和功能边界(xxx助手/什么格式返回/字数控制多少)。
* 用户消息(UserMessage):用户的提问/主题
* http://localhost:8006/prompttemplate/chat3?sysTopic=法律&userTopic=知识产权法
*
* http://localhost:8006/prompttemplate/chat3?sysTopic=法律&userTopic=夫妻肺片
*/
@GetMapping("/prompttemplate/chat3")
public String chat3(String sysTopic, String userTopic)
{
// 1.SystemPromptTemplate
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是{systemTopic}助手,只回答{systemTopic}其它无可奉告,以HTML格式的结果。");
Message sysMessage = systemPromptTemplate.createMessage(Map.of("systemTopic", sysTopic));
// 2.PromptTemplate
PromptTemplate userPromptTemplate = new PromptTemplate("解释一下{userTopic}");
Message userMessage = userPromptTemplate.createMessage(Map.of("userTopic", userTopic));
// 3.组合【关键】 多个 Message -> Prompt
Prompt prompt = new Prompt(List.of(sysMessage, userMessage));
// 4.调用 LLM
return deepseekChatClient.prompt(prompt).call().content();
}八.格式化输出
在 Spring AI 或大模型开发语境下,格式化输出 (Output Parsing / Structured Output) 是指:将 AI 生成的非结构化文本(如一段散乱的话)转化为程序可直接解析的结构化数据(如 JSON、XML、HTML 或特定的 Java Bean)。
现在我们进行代码实战:假设我们期望将模型输出转换为Record纪录类结构体,不再是传统的String.那么和以往的一样,我们先新建子模块,然后改pom,写yml,主启动,配置类。接下来是重点步骤:
1. 新建纪录类StudentRecord
java
package ai.alibaba.records;
/**
* @Description jdk14后的新特性,记录类替代lombok
*/
public record StudentRecord(String id,String sname,String major,String email) { }2. Controller
java
@RestController
public class StructuredOutputController
{
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
/**
* http://localhost:8007/structuredoutput/chat?sname=李四&email=zzyybs@126.com
* @param sname
* @return
*/
@GetMapping("/structuredoutput/chat")
public StudentRecord chat(String sname,String email)
{
return qwenChatClient.prompt()
.user(new Consumer<ChatClient.PromptUserSpec>() {
@Override
public void accept(ChatClient.PromptUserSpec promptUserSpec)
{
promptUserSpec.text("学号1001,我叫{sname},大学专业是计算机科学与技术,邮箱{email}")
.param("sname",sname)
.param("email",email);
}
}).call().entity(StudentRecord.class);
}
/**
*简化
* http://localhost:8007/structuredoutput/chat2?sname=孙伟&email=zzyybs@126.com
* @param sname
* @return
*/
@GetMapping("/structuredoutput/chat2")
public StudentRecord chat2(@RequestParam(name = "sname") String sname,
@RequestParam(name = "email") String email)
{
String stringTemplate = """
学号1002,我叫{sname},大学专业是软件工程,邮箱{email}
""";
return qwenChatClient.prompt()
.user(promptUserSpec -> promptUserSpec.text(stringTemplate)
.param("sname",sname)
.param("email",email))
.call()
.entity(StudentRecord.class);
}
}九.Chat Memory连续对话保存和持久化
9.1 ChatMemory是什么
对话记忆:这种记忆机制使得模型能够在对话中持续跟踪和理解用户的意图和上下文,从而实现更自然和连贯的对话。而SpringAI Alibaba中的聊天记忆提供了维护AI聊天应用程序的对话上下文和历史的机制。
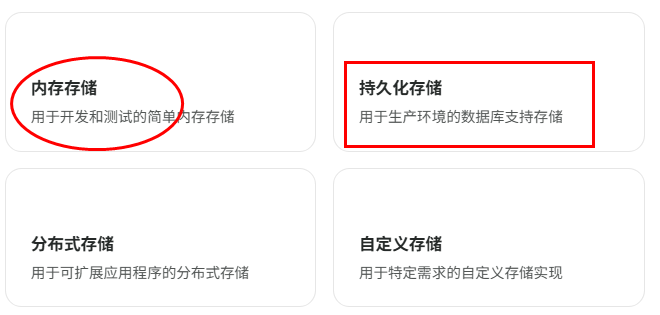
记忆类型分为下述几个:
但是因为大模型本身不存储数据,需将历史对话信息一次性提供给它以实现连续对话,不然服务一重启就什么都没了......所以必须要持久化。
在此有两个痛点,分别是持久化媒介和消息对话窗口,聊天记录上限;
9.2 持久化开发
在 Spring AI Alibaba 中,我们不需要手动写 List 来存消息,它提供了一个优雅的组件叫做ChatMemory。
持久化
如果你希望服务器重启后,AI 依然记得以往的聊天记录,你就需要持久化。Spring AI Alibaba 支持将记忆存入 Redis、JDBC 或其他数据库。
以Redis为例: 只需要引入对应的 ChatMemory 实现,并注入你的数据源即可。
1. 添加依赖
首先,确保你的 pom.xml 中引入了 Redis 的相关依赖。由于 Spring AI Alibaba 是基于 Spring Boot 的,它能完美利用 Spring Data Redis。
XML
<!--spring-ai-alibaba memory-redis-->
<!--这是阿里巴巴专门为 ChatMemory 封装的 Starter-->
<!--你只要引入它,Spring 容器就会自动识别并准备好 Redis 存储环境。-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
</dependency>
<!--redis客户端-->
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>2. 配置 Redis 版 ChatMemory(此处可省略)
在 Spring AI 中,提供了一个专门的RedisChatMemory实现。你只需要把 RedisTemplate 传给它即可。
但是引入了上述的依赖starter后,甚至不需要自己去 new RedisChatMemory,配置会变得非常自动化。在 application.yml 中配置连接只需要告诉程序 Redis 在哪,剩下的交给 Starter
java
//@Configuration
//public class AIConfig {
// @Bean
// public ChatMemory chatMemory(RedisConnectionFactory connectionFactory) {
// 使用 Redis 来存储对话,这样即使应用重启,记忆依然存在
// return new RedisChatMemory(connectionFactory);
// }
//}
java
# ==========redis config ===============
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.database=0
spring.data.redis.connect-timeout=3
spring.data.redis.timeout=2但是,如果你不想要用系统的默认配置,你可以进行自定义配置:
1.
RedisChatMemoryRepository(存redis)
ChatMemoryRepository的具体实现类它负责具体的"苦力活"------把 Java 的消息对象序列化成 JSON,然后塞进 Redis 的 List 结构里。
2.
MessageWindowChatMemory(能存多少)
它决定了 AI 应该记得"多少"。它维护一个"滑动窗口",比如只保留最近 10 条消息。
它不负责存,只负责计算:"根据当前配置,我该从仓库里拿哪几条消息给 AI?"
举例:
3.
MessageChatMemoryAdvisor
它像一个"自动补全插件"。在你发消息给 AI 的一瞬间,它自动去 Redis 拿历史记录;在 AI 回复后,它自动把回复存回 Redis。
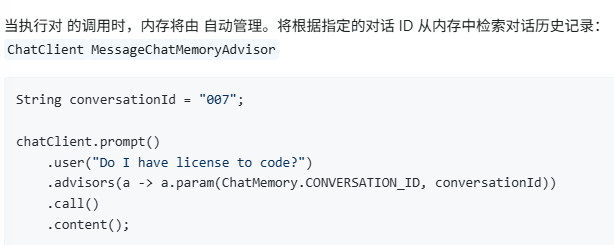
笔记要点 :它是执行层 。它是让
ChatClient具备"记忆力"的最后一道工序。eg:

java
package ai.alibaba.config;
@Configuration
public class RedisMemoryConfig
{
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository()
{
return RedisChatMemoryRepository.builder()
.host(host)//告诉它redis的host和port在哪里
.port(port)
.build();
}
}3. 在业务逻辑中使用
- 修改****配置类SaaLLMConfig
以往我们的配置如下所示
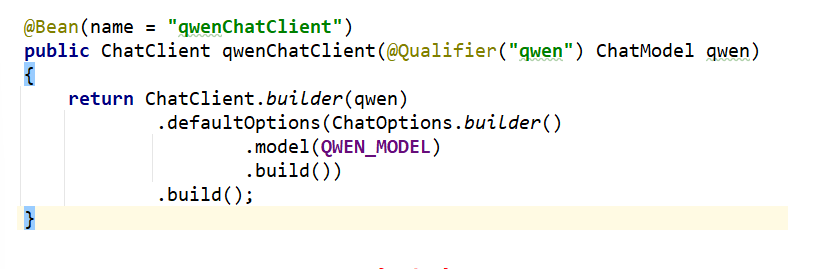
对比一下修改之后的大模型
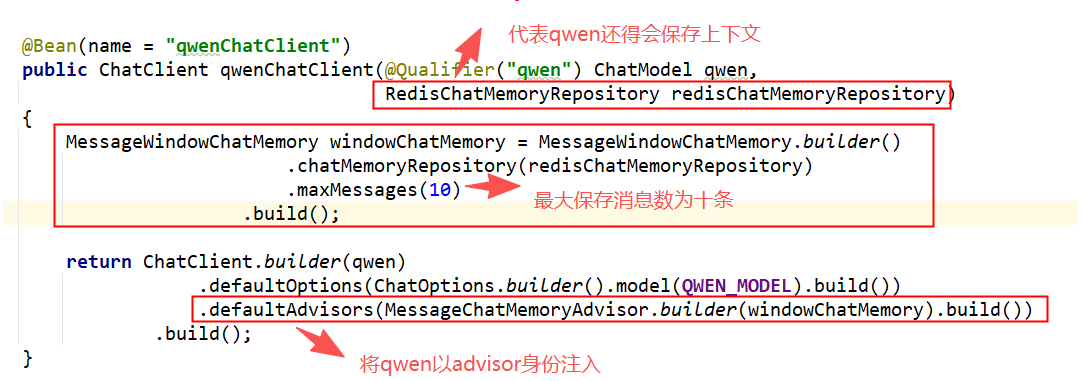
java
@Configuration
public class LLMConfig {
//deepseek同理
private final String QWEN_MODEL = "qwen3-max";
@Bean(name = "qwen")
public ChatModel qwen(){
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(System.getenv("aliQwen-api")).build())
.defaultOptions(DashScopeChatOptions.builder().withModel(QWEN_MODEL).build())
.build();
}
@Bean(name = "qwenChatClient")
public ChatClient qwenChatClient(@Qualifier("qwen") ChatModel qwen,
RedisChatMemoryRepository redisChatMemoryRepository)
{
MessageWindowChatMemory windowChatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(redisChatMemoryRepository)
.maxMessages(10)
.build();
return ChatClient.builder(qwen)
.defaultOptions(ChatOptions.builder().model(QWEN_MODEL).build())
.defaultAdvisors(MessageChatMemoryAdvisor.builder(windowChatMemory).build())
.build();
}
}在实际开发中,我们通常会遇到多个用户 同时在线的情况。为了不让张三的记忆跑到李四那里,我们需要在调用时传入一个唯一的 chatId(比如用户 ID 或 Session ID)。
java
package ai.alibaba.controller;
@RestController
public class ChatMemory4RedisController
{
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
@GetMapping("/chatmemory/chat")
public String chat(String msg, String userId)
{
/*return qwenChatClient.prompt(msg).advisors(new Consumer<ChatClient.AdvisorSpec>()
{
@Override
public void accept(ChatClient.AdvisorSpec advisorSpec)
{
advisorSpec.param(CONVERSATION_ID, cid);
}
}).call().content();*/
return qwenChatClient.prompt(msg)//"嘿,通义千问(Qwen),这是用户刚发的消息:msg。"
.advisors(advisorSpec -> advisorSpec.param(CONVERSATION_ID, userId))//"在发送之前,请先去咨询一下我的'记忆顾问'(Advisor)。"
.call()
.content();//"最后,把综合了历史记录的回答告诉我。"
}
}十.文生图
文生图相关参考官方文档:
现在先来动手实例:
和以往一样,先建立子模块Module,改pom,写yml,主启动,注意不用再写config类了;
然后是controller类:
java
@RestController
@RequestMapping("/ai")
public class ImageController {
private final ImageModel imageModel;
// 自动注入通义万相模型
public ImageController(ImageModel imageModel) {
this.imageModel = imageModel;
}
@GetMapping("/draw")
public String draw(@RequestParam String prompt) {
// 1. 创建绘画请求,指定提示词和参数
ImagePrompt imagePrompt = new ImagePrompt(prompt,
TongyiImagesOptions.builder()
.withN(1) // 生成 1 张图
.withHeight(1024) // 高度
.withWidth(1024) // 宽度
.build());
// 2. 调用模型生成图片
ImageResponse response = imageModel.call(imagePrompt);
// 3. 返回图片的 URL 地址
return response.getResult().getOutput().getUrl();
}
}-
在 Spring AI 中,ImageModel 是一个通用的标准接口。
-
在聊天里我们直接传
String,但在绘图里,需求更复杂,所以需要用ImagePrompt对象进行封装。
- 组成部分 :它由 文字描述(String prompt) + 配置参数(ImageOptions) 组成。
十一.向量化和向量数据库
什么是向量 : 向量是用于表示具有大小和方向的量;向量又可以描述为矢量
11.2 文本向量化
什么是文本向量化呢?
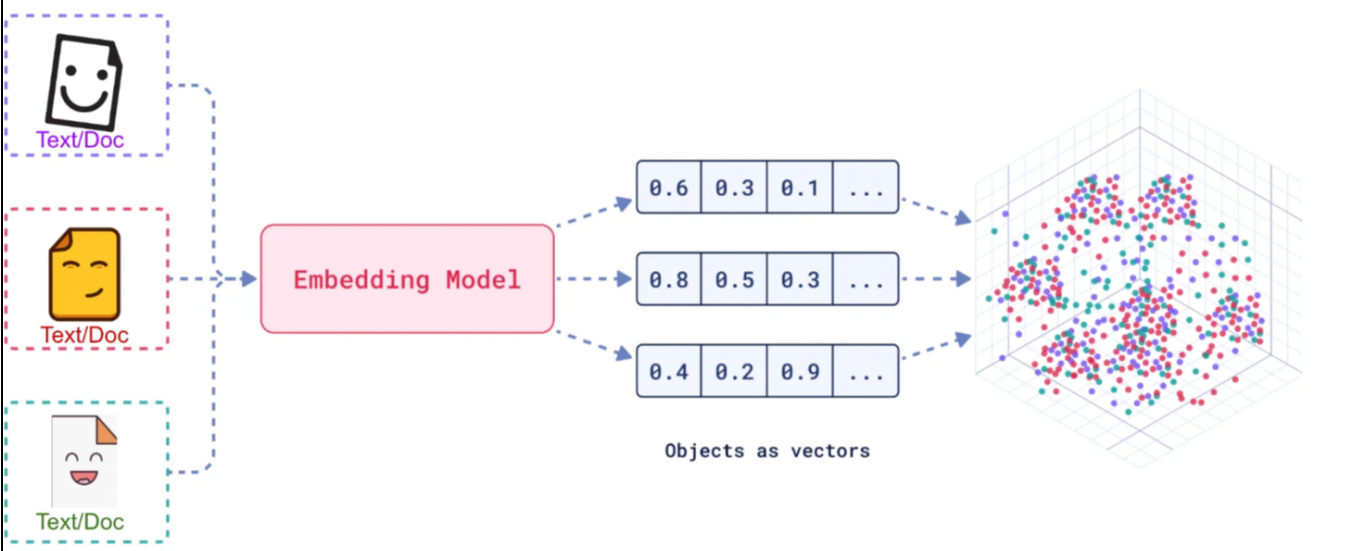
嵌入(Embedding)的工作原理是将文本,图像和视频转换为向量(Vectors)的浮点型数组。所以文本向量化就是将文本,图像和视频转化为浮点型数组,然后在打到一个高维的坐标系上。
举个例子:
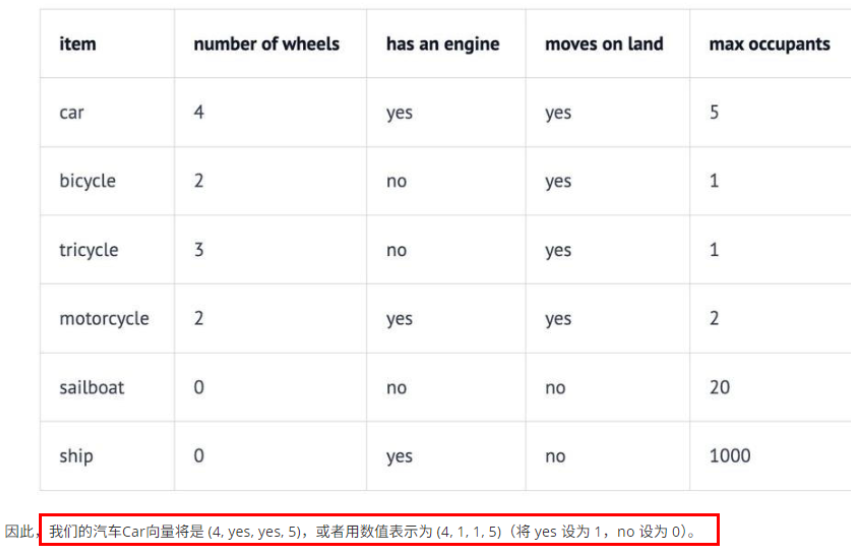
总结一下,嵌入模型是一种机器学习模型,旨在在连续的低维向量空间中表示数据(例如文本,图像或者其它形式的信息)。这些切入可以捕获数据之间的语义或者上下文的相似性,使机器能够高效地执行比较,聚合或分类等任务。
假设你想描述不同的水果。你不用长篇大论,而是用数字来描述甜度、大小和颜色等特征。例如,苹果可能是8,5,7,而香蕉是9,7,4。这些数字使比较或对相似的水果进行分组变得更容易。
11.3 向量数据库
向量存储 是一种用于存储和检索高维向量数据的数据库或者存储解决方案 。他特别适用于处理那些经过嵌入模型转化后的数据。注意的是,它们执行相似性搜索,而不是精准匹配。VectorStore用于您的数据和AI模型集成。向量数据库维度越高,查询的精准度也就越高,查询的效果也会越好。(比如淘宝搜索完想要的商品之后,会有猜你喜欢的功能)
总结:

11.4 代码开发
1.首先就是还是建module
2.在原来的pom.xml的基础上加入--->此处使用RedisStack当向量数据库
XML
<!-- 添加 Redis 向量数据库依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>3.写yml
bash
server.port=8011
server.servlet.encoding.enabled=true
server.servlet.encoding.force=true
server.servlet.encoding.charset=UTF-8
spring.application.name=SAA-11Embed2vector
# ====SpringAIAlibaba Config=============
spring.ai.dashscope.api-key=${aliQwen-api}
spring.ai.dashscope.chat.options.model=qwen-plus
spring.ai.dashscope.embedding.options.model=text-embedding-v3
# =======Redis Stack==========
spring.data.redis.host=localhost
spring.data.redis.port=6380
spring.data.redis.username=default
spring.ai.vectorstore.redis.initialize-schema=true
spring.ai.vectorstore.redis.index-name=custom-index
spring.ai.vectorstore.redis.prefix=custom-prefix
4.还是写主启动
接下来就是重点内容:
用redisStack作为向量存储
- RedisStack是什么:Redis Stack是Redis Labs推出的一个**"增强版 Redis"** ,不是 Redis 的替代品,而是在原生 Redis 基础上的功能扩展包,专为构建现代实时应用而设计
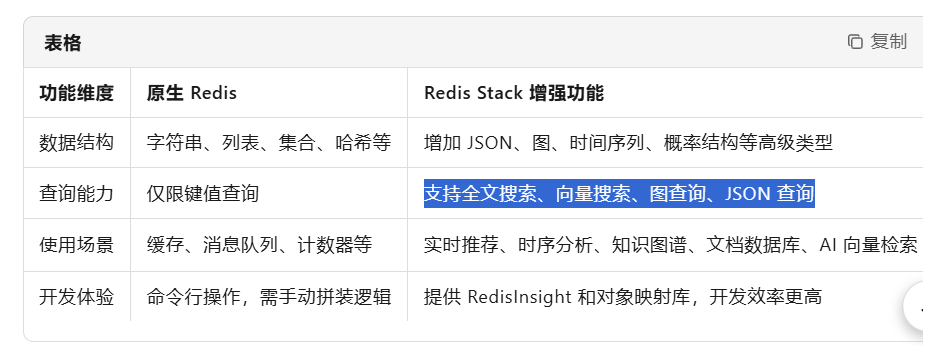
一句话: RedisStack=原生Redis+搜索+图+时间序列+JSON+概率结构+可视化工具+开发框架支持
redisstack在docker中安装
bash
ubuntu@hhhhhh:~$ docker run -d --name redis-stack-server \
-p 6380:6379 \
-p 8001:8001 \
redis/redis-stack:latest接下来就是具体业务类:
要进行文本向量化,向量化存储以及向量化查询
| 组件名称 | 核心接口 | 角色定位 |
|---|---|---|
| 嵌入模型 | EmbeddingModel | 特征提取器 |
| 向量数据库 | VectorStore | 空间索引器 |
java
package ai.study.controller;
import com.alibaba.cloud.ai.dashscope.embedding.DashScopeEmbeddingOptions;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingRequest;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Arrays;
import java.util.List;
@RestController
@Slf4j
public class Embed2VectorController
{
//文本向量化
@Resource
private EmbeddingModel embeddingModel;
//管存储
@Resource
private VectorStore vectorStore;
/**
* 文本向量化
* http://localhost:8011/text2embed?msg=射雕英雄传
*
* @param msg
* @return
*/
@GetMapping("/text2embed")
public EmbeddingResponse text2Embed(@RequestParam("msg") String msg)
{
//EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg), null));
EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg),
DashScopeEmbeddingOptions.builder().withModel("text-embedding-v3").build()));//配置文件里的模型全局公用,但是想要单粒度使用,则需要单独配置,可在此配置
System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));
return embeddingResponse;
}
/**
文本向量化,后存入向量数据哭RedisStack**/
@GetMapping("/embed2vector/add")
public void add()
{
List<Document> documents = List.of(
new Document("i study LLM"),
new Document("i love java")
);
vectorStore.add(documents);
}
/**
*从向量数据库RedisStack查找,进行相似度查找
*http://localhost:8011/embed2vector/get?msg=LLM
*/
@GetMapping("/embed2vector/get")
public List getAll(@RequestParam(name = "msg") String msg)
{
SearchRequest searchRequest = SearchRequest.builder()
.query(msg)
.topK(2)
.build();
List<Document> list = vectorStore.similaritySearch(searchRequest);
System.out.println(list);
return list;
}
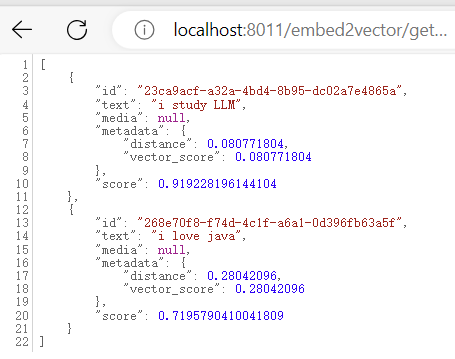
}此时文本向量化的结果如下所示:

查询结果