作为一个非科班出身的开发者,过去几个月我用TRAE/codex/claude/cursor等工具 搭建了一个集成多模态AIGC能力的创作工具箱------**飙算工具箱 **。
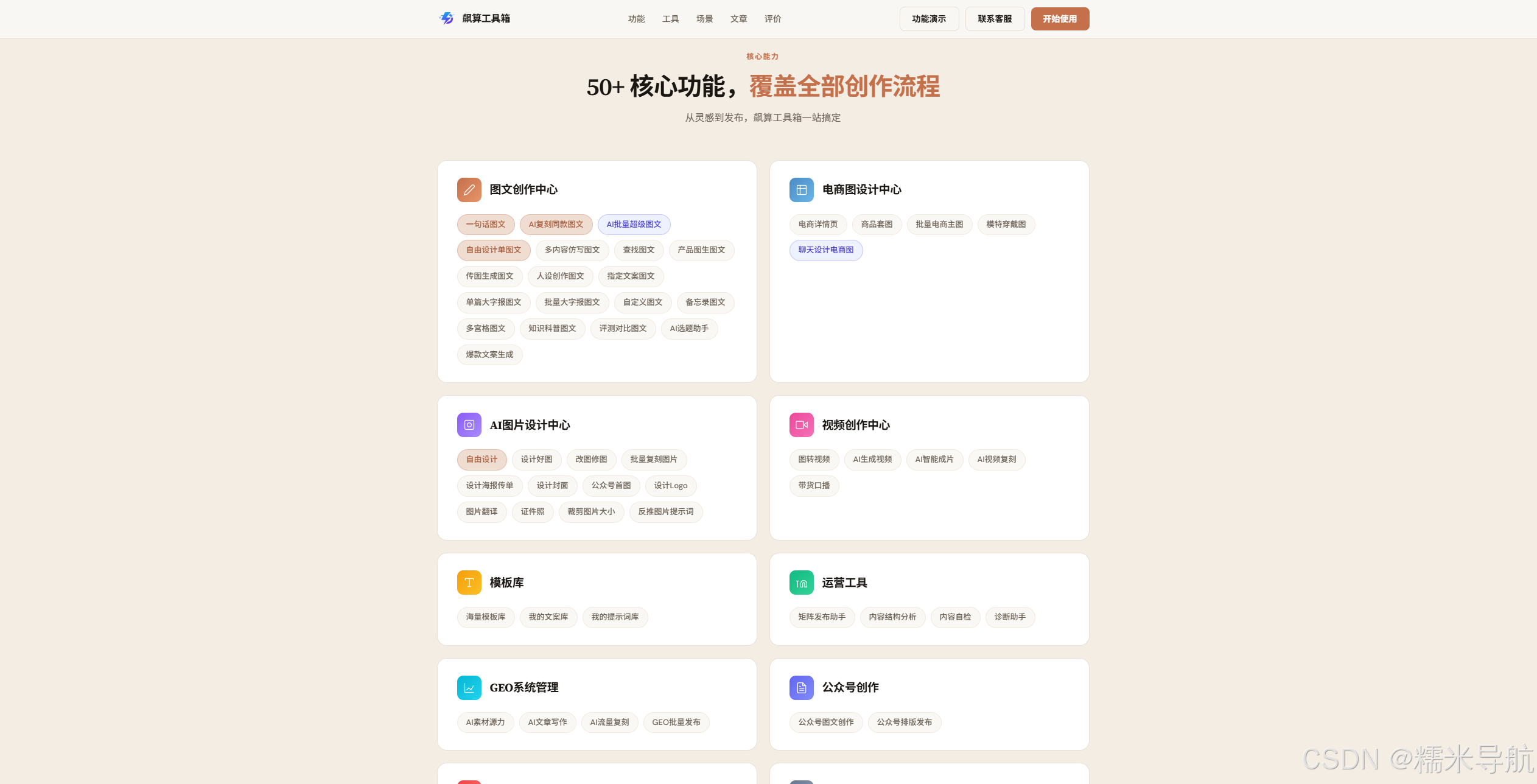
本文将从技术架构、模块设计、API编排、性能优化等角度,分享这个系统的实现思路。
技术栈选型
| 层级 | 技术选型 | 说明 |
| 前端 | React + TypeScript | 类型安全,组件化开发 |
| 后端 | Node.js + Express / Python FastAPI | 混合架构,AI推理用Python |
| AI能力层 | OpenAI API / 文心一言 / 通义千问 | 多模型适配层 |
| 图像生成 | Stable Diffusion API / ComfyUI | 本地+云端混合推理 |
| 视频生成 | 自研Pipeline + FFmpeg | 图转视频、AI成片 |
| 数据存储 | MongoDB + Redis | 非结构化数据+缓存 |
| 部署 | Docker + Nginx | 容器化部署 |
系统架构设计
┌─────────────────────────────────────────┐
│ 前端 Layer (React) │
│ 图文创作 / 电商设计 / 视频创作 / 运营 │
└────────────────┬────────────────────────┘
│ REST API + WebSocket
┌────────────────┴────────────────────────┐
│ API Gateway (Express) │
│ 认证 / 限流 / 路由 / 日志 / 监控 │
└──────┬──────────┬──────────┬───────────┘
│ │ │
┌──────┴───┐ ┌───┴──────┐ ┌┴──────────┐
│ 图文模块 │ │ 图像模块 │ │ 视频模块 │
│ (Node.js)│ │(Python ASGI)│ │(Python Celery)│
└──────────┘ └───────────┘ └────────────┘
│ │ │
┌──────┴──────────┴──────────┴───────────┐
│ AIGC能力编排层 (Orchestration) │
│ Prompt Engine / Model Router / Fallback │
└──────────────────┬──────────────────────┘
│
┌──────────────────┴──────────────────────┐
│ AI模型层 (Multi-Model) │
│ GPT-4V / FLUX / SD3 / Kling / 自研Lora │
└─────────────────────────────────────────┘
核心模块技术实现
1. 图文创作中心(10+子模块)
技术难点:如何实现"AI复刻同款图文"?
cpp
# 核心思路:视觉理解 + 风格提取 + 重新生成
async def replicate_graphic(image_url: str, new_content: str):
# Step 1: 视觉理解 - 提取原图布局结构
layout = await vision_model.analyze_layout(image_url)
# Step 2: 风格提取 - 颜色、字体、装饰元素
style = await style_extractor.extract(image_url)
# Step 3: 内容替换 - 保持布局,替换文案
result = await graphic_generator.generate(
layout=layout,
style=style,
content=new_content
)
return result批量超级图文采用任务队列(Bull.js + Redis)实现异步批量处理,支持100+并发任务。
- 电商图设计中心
技术方案:
商品套图:ComfyUI工作流 + 批量节点
模特穿戴图:IDM-VTON 虚拟试衣模型(本地部署)
批量主图:模板引擎 + 变量替换 + SD批量出图
cpp
// 电商详情页自动生成 Pipeline
const generateDetailPage = async (productInfo) => {
const { title, features, price, images } = productInfo;
// 并行生成:主图、详情图、卖点图
const [mainImage, detailImages, sellingPoints] = await Promise.all([
generateMainImage(images[0], title),
generateDetailImages(images, features),
extractSellingPoints(features, title)
]);
// 拼装详情页HTML模板
return assembleHTML({ mainImage, detailImages, sellingPoints, price });
};- AI图片设计中心
反推图片提示词功能实现:
cpp
# 使用CLIP + BLIP-2 双模型反推
async def reverse_prompt(image_path: str) -> str:
# BLIP-2: 图像描述
caption = blip2.generate_caption(image_path)
# CLIP: 提取视觉特征,匹配提示词空间
visual_features = clip_encoder.encode_image(image_path)
# 结合两者,生成高质量提示词
prompt = prompt_refiner.refine(caption, visual_features)
return prompt图片翻译:PaddleOCR + GPT-4V(保留版式,只替换文字)
- 视频创作中心
图转视频技术路线:
方案A:AnimateDiff(本地,成本低,质量中等)
方案B:Kling API / 可灵(云端,质量高,成本高)
智能路由:根据用户等级 + 内容类型自动选择
cpp
def route_video_generation(request):
user_tier = request.user.tier
content_type = request.content_type
if user_tier == 'premium':
return 'kling_api' # 高质量
elif content_type == 'ecommerce':
return 'animatediff_local' # 成本敏感
else:
return 'auto' # 智能选择AI智能成片:脚本生成 → 分镜规划 → 素材匹配 → 配音合成 → 视频渲染(FFmpeg)
- GEO系统(生成引擎编排)
这是整个工具箱的"大脑",负责模型路由、降级策略、成本控制:
cpp
class ModelRouter {
async route(request: AIRequest): Promise<AIResponse> {
const candidates = this.getCandidateModels(request.type);
for (const model of candidates) {
try {
const result = await model.invoke(request);
if (result.quality > request.minQuality) {
return result;
}
} catch (err) {
logger.warn(`Model ${model.name} failed, fallback...`);
continue; // 降级到下一个模型
}
}
throw new Error('All models failed');
}
}性能优化实践
- 并发控制
cpp
// 使用p-limit控制并发,避免API限流
import pLimit from 'p-limit';
const limit = pLimit(5); // 最多5个并发
const results = await Promise.all(
tasks.map(task => limit(() => processTask(task)))
);- 缓存策略
Redis缓存:相同提示词 + 相同参数的生成结果缓存24小时
CDN缓存:生成的图片/视频资源,Cache-Control: max-age=604800 - 流式输出
长文本生成(如AI文章写作)采用Streaming API,前端边生成边展示,提升用户体验:
cpp
const stream = await openai.chat.completions.create({
model: 'gpt-4',
messages: [...],
stream: true,
});
for await (const chunk of stream) {
res.write(chunk.choices[0]?.delta?.content || '');
}部署架构
cpp
[用户]
↓ HTTPS
[Nginx 反向代理]
↓
[前端容器] [后端API容器] [AI推理容器]
↓ ↓ ↓
[Redis] [MongoDB] [本地模型 / 云端API]Docker Compose 一键部署:
cpp
services:
frontend:
build: ./frontend
ports: ["3000:3000"]
backend:
build: ./backend
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
depends_on: [redis, mongodb]
redis:
image: redis:7-alpine
mongodb:
image: mongo:7踩过的坑
Token消耗失控:早期没有做内容长度限制,一次生成消耗了50万token... 现在加了内容截断 + 预估token数的前置检查
并发API调用超时:批量任务没有做超时控制,导致队列堆积。现在用Promise.race + 超时中断
图片生成质量不稳定:不同模型的输出差异很大,现在做了多模型投票机制(生成3张,选最好的一张)
总结
这个项目让我深刻体会到:AI时代,全栈开发的边界在模糊。前端工程师可以借助TRAE快速搭建后端能力,后端工程师也能通过AIGC快速实现以前需要专业设计师才能完成的任务。
欢迎各位开发者交流指正!