上一篇你已经会造子代理了。但用过几次就会发现一个问题:子代理直接改你的工作区,改崩了没有后悔药。
你让一个子代理"试试用策略模式重构这段 switch-case",它要是改崩了,你的代码也崩了。你得盯着它每一步操作,随时准备撤销。想让它放手大胆试?你不敢。
isolation: worktree 解决的就是这件事,给子代理一个沙盒,改坏了扔掉就行,你的主工作区纹丝不动。
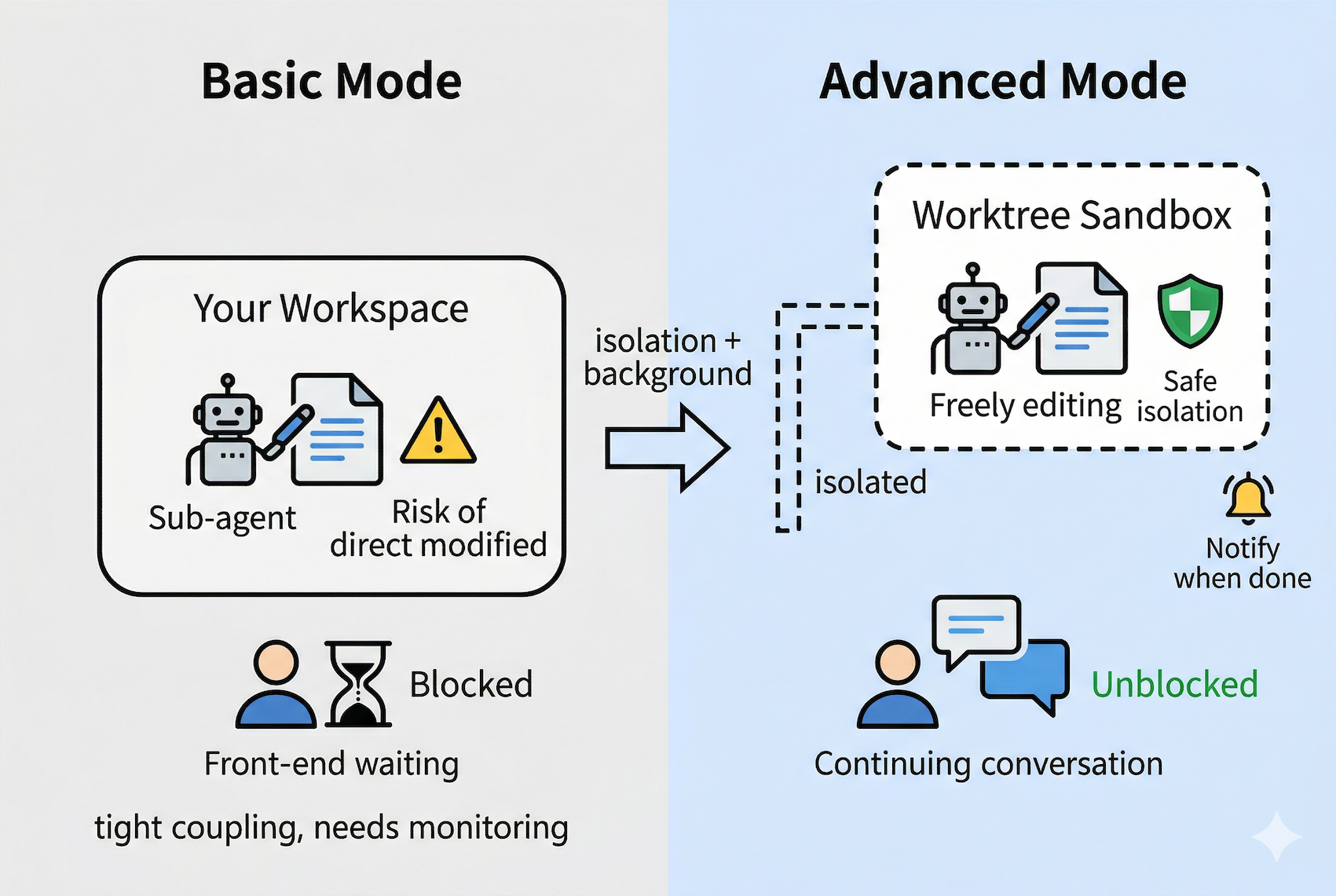
上图是整篇文章的核心对比。左边是基础模式:子代理直接在你的工作区里改文件,你得盯着,改崩了就是你的事。右边是进阶模式:子代理在隔离的沙盒里工作,你不用等也不用担心,完成后收到通知再决定要不要合并。
一、沙盒模式:isolation: worktree
1.1 为什么需要沙盒
先看一个真实场景。你在做一次性能优化,数据库查询层有两个方案可选:方案 A 是给现有查询加缓存,方案 B 是换用批量查询重写整个模块。你不确定哪个更好,想让 Claude 两个都试一下,跑跑基准测试再决定。
如果没有沙盒,你只能串行试:先让 Claude 改成方案 A,跑测试,看结果,然后 git stash 或 git checkout 恢复现场,再试方案 B。更糟的情况是方案 A 改到一半你发现思路不对,现在代码处于一个"半成品"状态,回退都不利索。
沙盒模式让每个子代理在独立的 Git Worktree 中工作。 它有自己的工作目录、自己的分支,和你当前的代码物理隔离。子代理可以大刀阔斧地改,改成什么样都不影响你的主工作区。满意了就合并,不满意就丢弃。就像在草稿纸上画方案,不满意揉了扔掉,正稿纹丝不动。
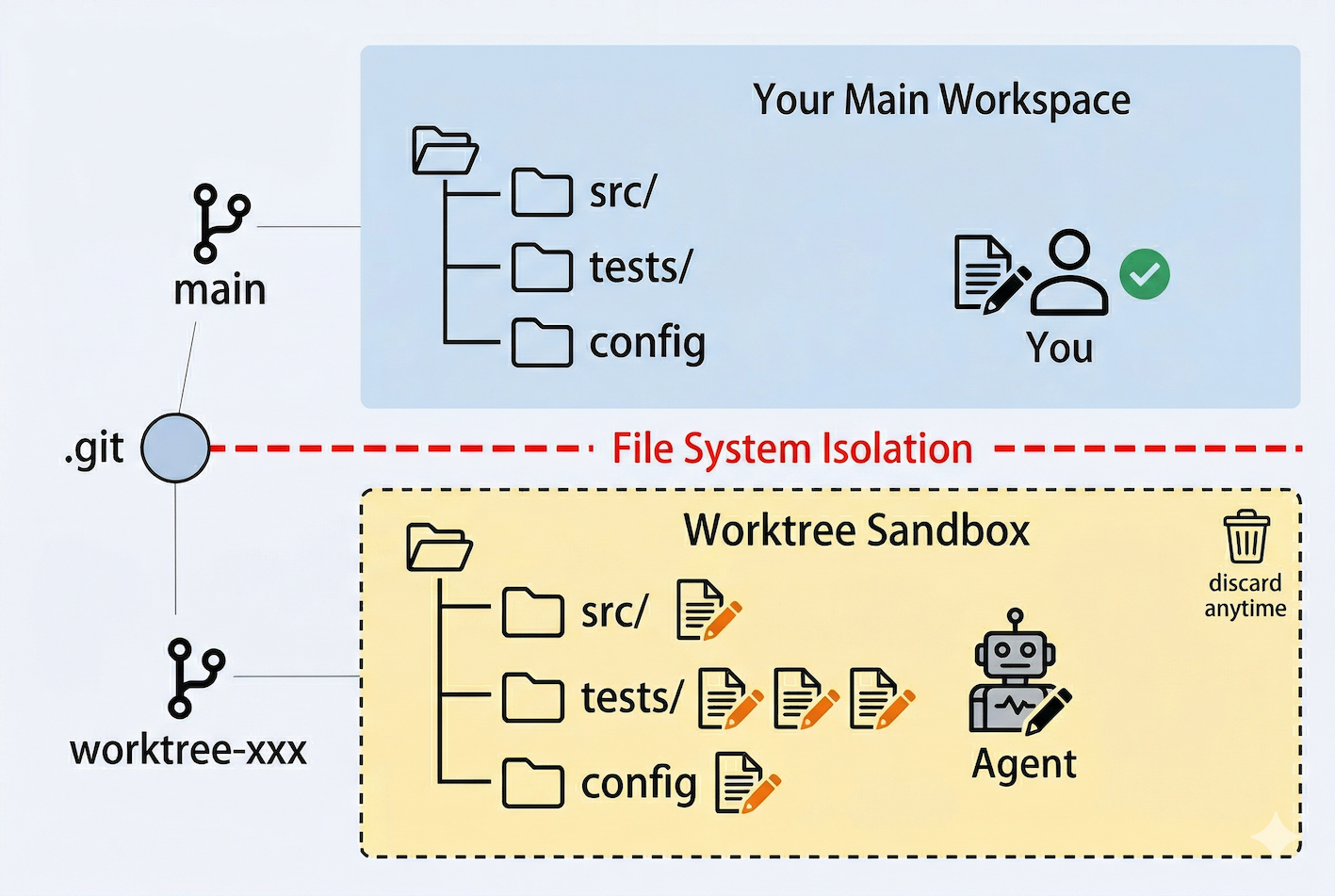
上图展示了沙盒隔离的核心结构。上层是你的主工作区(main 分支),下层是子代理的沙盒(worktree 分支)。两者拥有相同的文件结构,但物理上是不同的目录,子代理在下层怎么改都不影响上层。它们共享同一个 .git 对象库,所以磁盘开销很小,不是完整 clone。
1.2 怎么配置
在项目根目录的.claude/agents目录下创建refactor-explorer.md文件,只需要在子代理的 frontmatter 中加一行:
markdown
---
name: refactor-explorer
description: 探索性重构方案,在沙盒中独立尝试不改动主工作区
model: sonnet
isolation: worktree
tools:
- Read
- Glob
- Grep
- Edit
- Bash
---
你是一个重构探索员。收到重构需求后:
1. 先分析当前代码结构和依赖关系
2. 提出重构方案并直接实施
3. 修改完成后运行现有测试,确保不破坏功能
4. 如果测试失败,分析原因并修复
5. 最后给出改动摘要:改了哪些文件、为什么这么改、测试结果
大胆尝试,不需要保守------你在沙盒中工作,不会影响主工作区。 关键就是 isolation: worktree 这一行。有了它,这个子代理每次被调用时,都会自动在独立的 Git Worktree 中运行。
前置条件:项目必须是 Git 仓库。 沙盒模式基于
git worktree,如果你的项目还没有初始化 Git(没有.git目录),子代理启动时会直接报错。确保至少执行过git init并有一次提交。另外,worktree 要求当前不能处于 rebase 或 merge 冲突状态,Git 需要一个干净的基点来创建新的工作树。
二、生命周期:从创建到清理
当主对话调用一个 worktree 隔离的子代理时,背后会经历五个阶段:
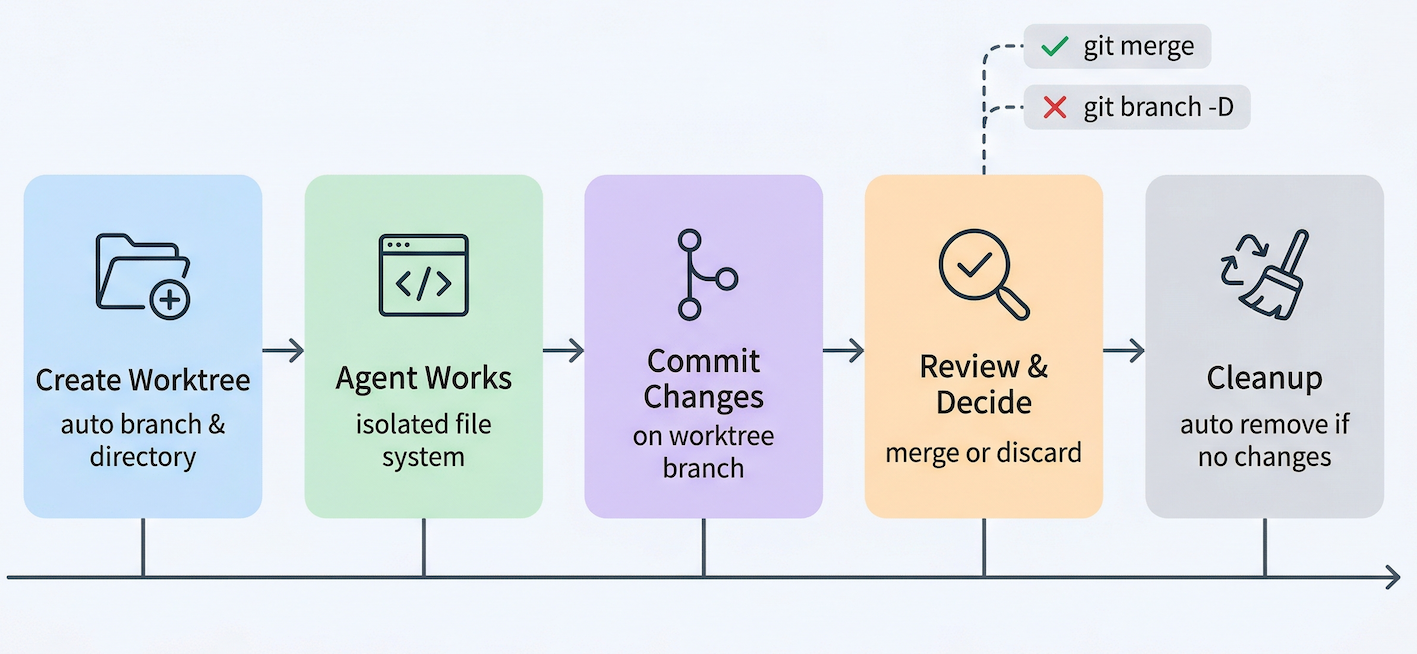
上图展示了 worktree 隔离子代理从创建到清理的完整过程。
2.1 创建 Worktree
子代理启动时,Claude Code 自动执行 git worktree add,在 .claude/worktrees/ 下创建一个新的工作目录,并从当前分支(通常是 main)拉出一个新分支。整个过程对你完全透明------你不需要手动操作任何 Git 命令。
新创建的 worktree 是当前仓库的完整副本 ,但和主工作区物理隔离。它们共享同一个 .git 对象库,所以磁盘开销很小,不是 git clone,不会复制历史记录。
2.2 子代理在沙盒中工作
子代理的所有文件操作,例如Read、Edit、Bash都发生在 worktree 目录中。它看到的文件树和你的主工作区一模一样(因为是从同一个 commit checkout 出来的),但它做的任何修改都不会影响你的主目录。
这意味着你可以在提示词里写"大胆尝试",因为试错成本为零。子代理可以删文件、重写模块、改配置,怎么折腾都行。
2.3 提交改动
子代理完成工作后,把改动提交到 worktree 分支上。这个提交只存在于 worktree 的分支里,不会出现在你的主分支上。
2.4 你来决定:合并还是丢弃
这是整个流程中唯一需要你决策的环节。子代理完成后会返回一个摘要,告诉你它做了什么改动、测试结果如何。同时你会拿到 worktree 的路径和分支名。
你有三个选择:
bash
# 方案满意,合并到主分支
git merge worktree-refactor-explorer-abc123
# 想看看具体改了什么再决定
git diff main...worktree-refactor-explorer-abc123
# 方案不行,直接丢弃
git branch -D worktree-refactor-explorer-abc1232.5 自动清理
如果子代理工作过程中没有产生任何改动(比如它分析完发现不需要改),worktree 会被自动清理,目录删除、分支移除,不留任何痕迹。
如果有改动,worktree 会保留,等你 merge 或手动删除后再清理。
三、实战:A/B 方案对比
回到开头的性能优化场景。有了沙盒模式,你可以同时让两个子代理探索两个方案:
同时启动两个 refactor-explorer:
方案 A:@refactor-explorer 给 UserRepository 的 findByIds 方法加 Redis 缓存,
缓存 key 用 user:{id},TTL 5 分钟。改完跑 benchmark。
方案 B:@refactor-explorer 把 UserRepository 里所有逐条查询改成批量查询,
用 WHERE id IN (...) 替代循环中的 WHERE id = ?。改完跑 benchmark。 两个子代理各自在独立的 worktree 中动手改代码、跑测试。你不用等,也不用担心它们互相干扰。等两个都完成后,对比 benchmark 结果,选一个合并,丢掉另一个。
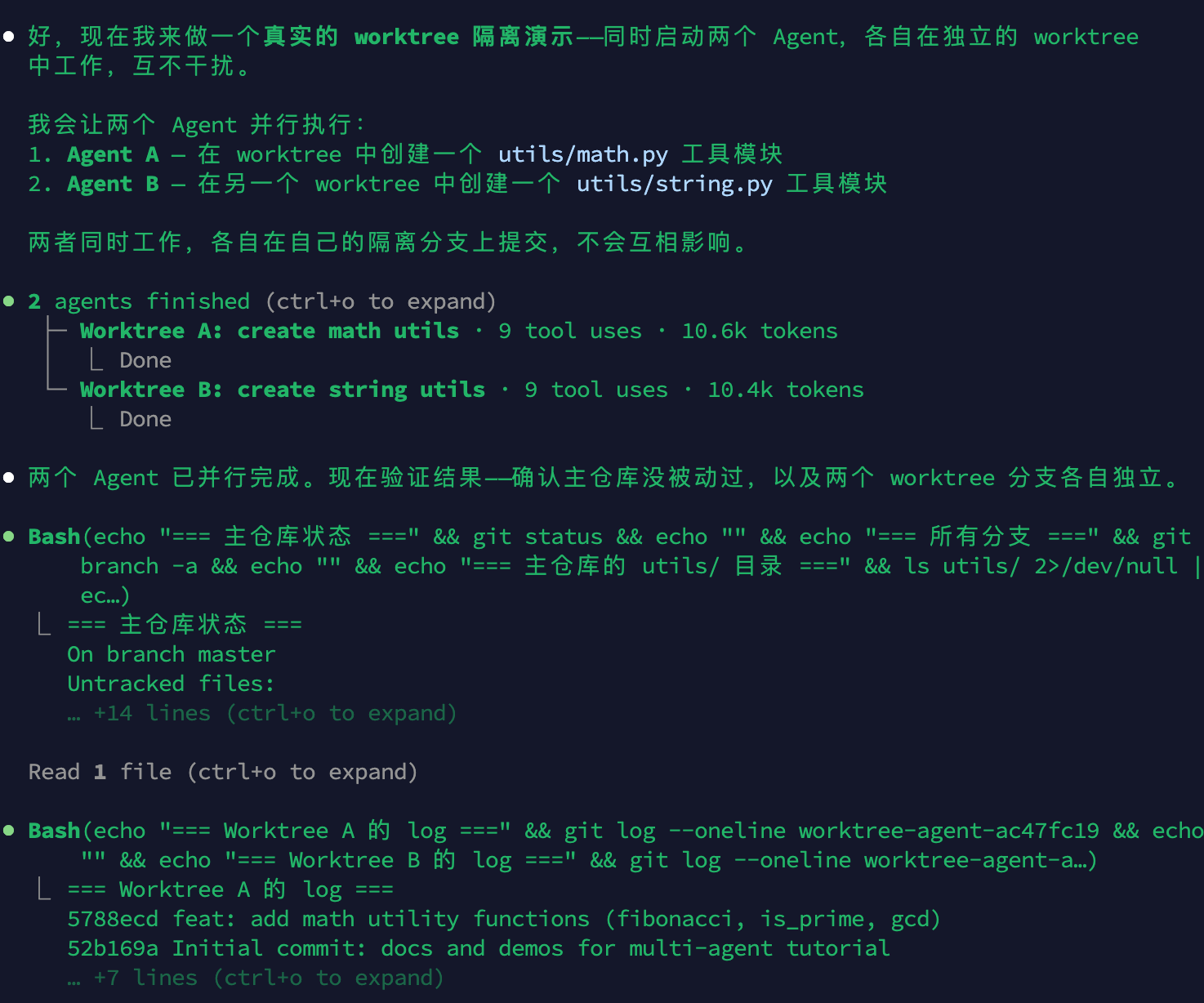
3.1 基线代码
演示用的基线文件是 test-repo/user_repository.py,核心结构如下:
python
class UserRepository:
def find_by_id(self, user_id):
"""单条查询------每次都新建连接、执行一条 SELECT。"""
conn = self._get_conn()
try:
row = conn.execute(
"SELECT id, name, email, department FROM users WHERE id = ?",
(user_id,),
).fetchone()
...
finally:
conn.close()
def find_by_ids(self, user_ids):
"""⚠️ N+1 问题:循环调用 find_by_id,200 个 ID = 200 次建连 + 200 次查询。"""
results = []
for uid in user_ids:
user = self.find_by_id(uid) # 每个 ID 独立建连 + 查询
if user:
results.append(user)
return results 文件还包含一个 init_db() 函数(初始化 1000 条测试数据)和 benchmark_find_by_ids() 函数(多轮计时 + 统计),两个子代理都会复用这套基础设施来跑 benchmark。
两个子代理拿到的是同一份基线文件,但各自在独立的 worktree 中修改,互不可见。下面是实际跑出来的结果,基线查询 200 个用户 ID,平均耗时约 18ms。
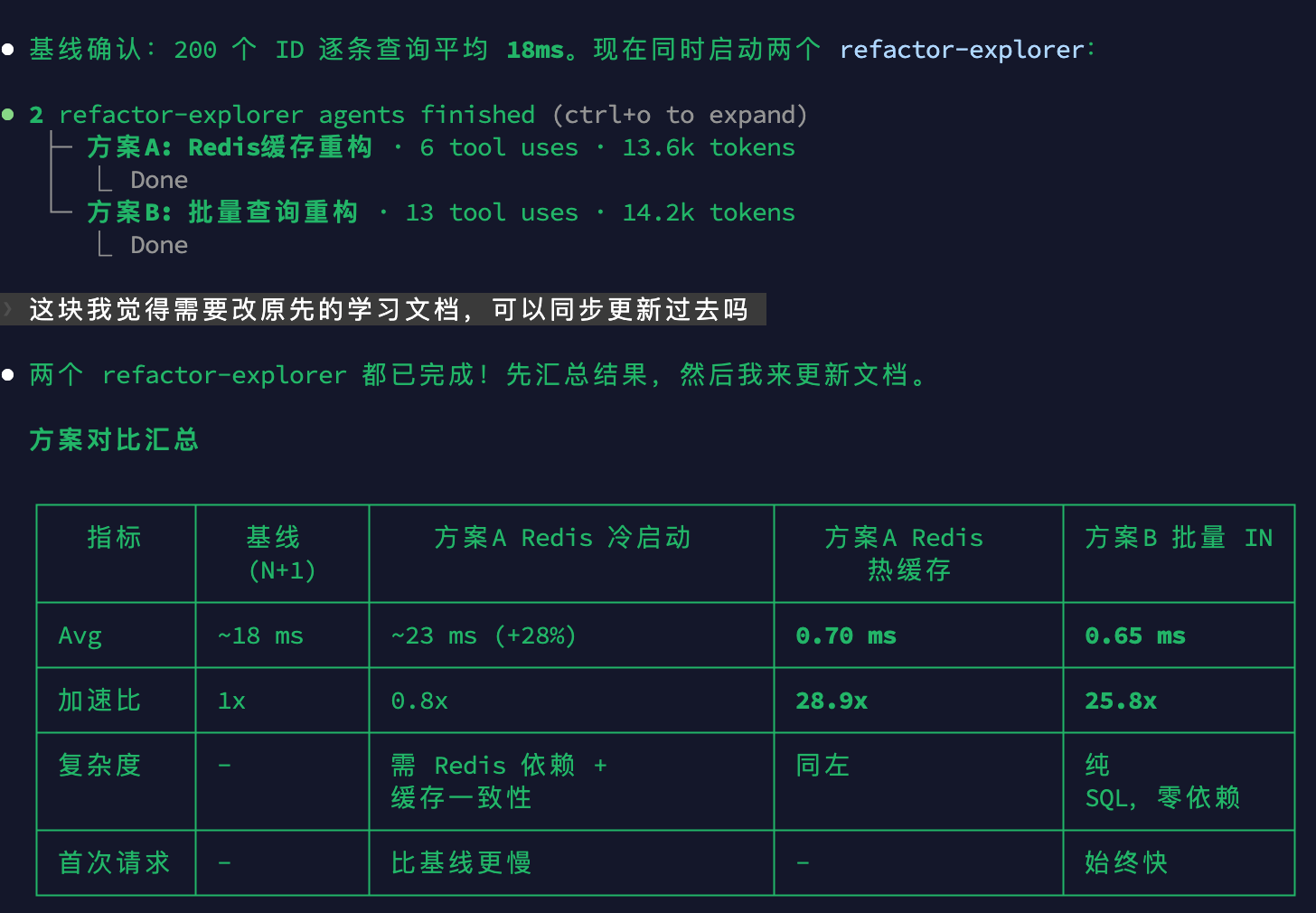
3.2 方案 A 结果:Redis 缓存
子代理 A 的 worktree 路径为 .claude/worktrees/agent-ac47fc19/,分支名 worktree-agent-ac47fc19。它对 user_repository.py 做了以下改动:
-
新增
FakeRedis/FakePipeline类(用 dict 模拟 Redis,接口兼容redis-py,生产环境可直接替换为真实 Redis) -
给
UserRepository.__init__新增可选参数redis_client,为None时退化为原始 N+1(向后兼容) -
重写
find_by_ids:MGET 批量查缓存 → 未命中的查 DB → pipeline 批量写缓存(keyuser:{id},TTL 300s) -
更新
__main__块:分别跑基线、冷启动、热缓存三组 benchmarkBenchmark: BASELINE (N+1 逐条查询,无缓存)
Avg time : 20.28 msBenchmark: 方案A 冷启动(首次,缓存未命中)
Avg time : 23.42 ms ← 比基线略慢,额外做了 MGET + JSON 序列化 + pipeline SETBenchmark: 方案A 热缓存(后续轮次,全命中)
Avg time : 0.70 ms ← 28.9x 加速
3.3 方案 B 结果:批量查询 WHERE id IN
子代理 B 的 worktree 路径为 .claude/worktrees/agent-a4f8ac9d/,分支名 worktree-agent-a4f8ac9d。它对 user_repository.py 做了以下改动:
-
重写
find_by_ids:用一条SELECT ... WHERE id IN (?, ?, ...)替代循环,单连接单查询 -
新增分批逻辑:IDs 超过 500 个时按
_BATCH_SIZE = 500分批,防止 SQL 参数超限 -
提取
_rows_to_dicts辅助方法,消除find_by_department中的重复转换逻辑 -
更新
__main__块:先用原始 N+1 跑基线,再用新实现跑对比Benchmark: BASELINE (N+1 逐条查询)
Avg time : 16.87 msBenchmark: 方案B (WHERE id IN 批量查询)
Avg time : 0.65 ms ← 25.8x 加速
3.4 对比总结
| 指标 | 基线 (N+1) | 方案A 冷启动 | 方案A 热缓存 | 方案B 批量 IN |
|---|---|---|---|---|
| 平均耗时 | ~18 ms | ~23 ms | 0.70 ms | 0.65 ms |
| 加速比 | 1x | 0.8x | 28.9x | 25.8x |
| 额外依赖 | 无 | Redis | Redis | 无 |
| 首次请求 | --- | 比基线更慢 | --- | 始终快 |
两个方案的热路径性能接近,但方案 B 零依赖且首次请求就快,适合大多数场景;方案 A 更适合跨服务共享缓存或读写比极端的场景。
最终选方案 B 的话:
bash
git merge worktree-agent-a002bc72 # 合入方案 B
git branch -D worktree-agent-a6e1b7 # 丢弃方案 A 这就是沙盒模式的核心价值:把"要不要试试"的心理负担降到零。
四、和手动 --worktree 的区别
区别在于谁来管理 worktree 的生命周期:
手动 --worktree |
isolation: worktree |
|
|---|---|---|
| 创建方式 | 你手动在终端执行 claude --worktree name |
子代理被调用时自动创建 |
| 使用场景 | 你知道要并行做什么,主动开多个终端 | 写进 agent 定义,每次调用自动隔离 |
| 生命周期 | 你管理(手动 merge、手动清理) | 半自动(无改动时自动清理,有改动时等你决定) |
| 适合谁 | 开发者主动规划并行任务 | 探索性、破坏性任务,或团队标准化流程 |
简单说:--worktree 是你主动开沙盒 ,isolation: worktree 是让子代理自带沙盒。后者的好处是你不需要每次都想着"这个任务要不要隔离",定义好的子代理天生就是隔离的。
五、总结
沙盒隔离解决的是信任问题 ,你不用再盯着子代理的每一步操作,不用担心它改坏你的代码。isolation: worktree 一行配置,子代理就有了自己的独立工作空间。
- 核心要点:
- 沙盒基于 Git Worktree,物理隔离文件系统,共享
.git对象库,磁盘开销小 - 子代理在沙盒里可以大胆试错,改崩了扔掉就行
- 生命周期半自动:无改动自动清理,有改动等你决定合并或丢弃
- 特别适合 A/B 方案对比、探索性重构这类"试试看"的场景
- 沙盒基于 Git Worktree,物理隔离文件系统,共享
- 但你可能还有另一个痛点:子代理跑着的时候你只能干等,没法继续对话。之后会介绍
background: true让子代理在后台跑,你该干嘛干嘛,再加上沙盒 + 后台的组合玩法。