
◆ 博主名称: 晓此方-CSDN博客 大家好,欢迎来到晓此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)

文章目录
- 概要&序論
- [一,编译与链接的基本原理及 gcc/g++ 使用](#一,编译与链接的基本原理及 gcc/g++ 使用)
-
- [1.1 程序编译的四个阶段](#1.1 程序编译的四个阶段)
-
- [1.1.1 预处理](#1.1.1 预处理)
- [1.1.2 编译](#1.1.2 编译)
- [1.1.3 汇编](#1.1.3 汇编)
- [1.1.4 链接](#1.1.4 链接)
- 1.2gcc/g++的常用用法
-
- 1.2.1合并以上步骤直接生成可执行程序
- [1.2 多个源文件生成可执行程序](#1.2 多个源文件生成可执行程序)
- [1.2.1 简单一步到位](#1.2.1 简单一步到位)
- [1.2.2 分步增量编译](#1.2.2 分步增量编译)
- [1.2 gcc/g++ 的常用选项与快速记忆](#1.2 gcc/g++ 的常用选项与快速记忆)
- 1.3不重要但是你知道会更好的一些编译器常识(了解)
- 二,深入理解编译原理与条件编译
-
- [2.1 条件编译的深度解析](#2.1 条件编译的深度解析)
-
- [2.1.1 预处理本质与命令行宏定义](#2.1.1 预处理本质与命令行宏定义)
- [2.1.2 条件编译的实际意义](#2.1.2 条件编译的实际意义)
- 2.1.3条件编译示例
- [2.2 编程语言的发展历程](#2.2 编程语言的发展历程)
-
- [2.2.1 从打孔编程到高级语言](#2.2.1 从打孔编程到高级语言)
- [2.2.2 为什么要先变成汇编?](#2.2.2 为什么要先变成汇编?)
- [2.3 编译器的自举](#2.3 编译器的自举)
-
- [2.3.1 "先有鸡还是先有蛋"](#2.3.1 “先有鸡还是先有蛋”)
- 三,初步认识动静态库与链接机制
-
- [3.1 什么是库?](#3.1 什么是库?)
- [3.2 动态链接和静态链接](#3.2 动态链接和静态链接)
- 3.3静态库和动态库
- 3.4对比总结
- [四、 Linux 链接技术实战验证](#四、 Linux 链接技术实战验证)
-
- [4.1 实验环境准备与源代码](#4.1 实验环境准备与源代码)
-
- [4.1.1 加入一个源代码 code.c](#4.1.1 加入一个源代码 code.c)
- [4.2 动态链接验证](#4.2 动态链接验证)
-
- [4.2.1 使用ldd查看库依赖](#4.2.1 使用ldd查看库依赖)
- [4.2.2 使用file查看文件属性](#4.2.2 使用file查看文件属性)
- [4.3 静态链接验证](#4.3 静态链接验证)
-
- [4.3.1 强制静态链接编译](#4.3.1 强制静态链接编译)
- [4.3.2 静态链接的结果对比](#4.3.2 静态链接的结果对比)
- [4.4 周边问题探讨:C++ 与标准库](#4.4 周边问题探讨:C++ 与标准库)
-
- [4.4.1 C++ 的动态链接特点](#4.4.1 C++ 的动态链接特点)
- [4.4.2 C++ 静态链接同理](#4.4.2 C++ 静态链接同理)
- [五、 补充------动态库的真相](#五、 补充——动态库的真相)
-
- [5.1 核心本质------内存中只存在一份](#5.1 核心本质——内存中只存在一份)
- [六、附录:gcc/g++ 常用选项参考](#六、附录:gcc/g++ 常用选项参考)
概要&序論
Hello 大家好,我是此方。 搞定了 Vim 编辑器,我们已经能顺畅地在 Linux 下敲代码了。但想要让代码跑起来,离不开编译器。本文,快速上手 gcc/g++ 的基本操作,学会怎么编译、深入底层,重温代码从预处理到链接的完整过程。同时,初步认识 Linux 下的动静态库 好,正式开始。
一,编译与链接的基本原理及 gcc/g++ 使用
1.1 程序编译的四个阶段
在 Linux 环境下,使用 gcc(编译 C 语言)或 g++(编译 C++ 语言)将源代码转化为可执行程序,主要经过预处理、编译、汇编和链接四个过程。
1.1.1 预处理
预处理阶段主要处理源代码中以 # 开头的预编译指令,包括宏替换、头文件展开(递归展开)、去注释、条件编译等。
- 指令选项 :
-E(开始进行翻译,在预处理完成后停止) - 生成文件 :
.i文件。 - 示例 :
gcc -E code.c -o code.i
这个目录里面包含了C语言的很多头文件。
1.1.2 编译
编译阶段将预处理后的代码转换为汇编语言 。此时编译器会检查语法的规范性及是否有语法错误。
- 指令选项 :
-S(开始进行翻译,在编译完成后停止) - 生成文件 :
.s文件。 - 示例 :
gcc -S code.i -o code.s
你这个时候入如果: gcc -S code.c -o code.s ,它会自动把预处理重新给你做一遍。后面同理。
1.1.3 汇编
汇编阶段将编译生成的汇编代码转化为二进制机器指令,生成"目标文件"。
- 指令选项 :
-c(开始进行翻译,在汇编完成后停止) - 注意 :生成的
.o文件已经是二进制格式,但尚不能直接执行。 - 生成文件 :
.o文件(对应 Windows 下的.obj)。 - 示例 :
gcc -c code.s -o code.o
1.1.4 链接
链接阶段将生成的各个目标文件(.o)与系统库文件、函数库等链接在一起,生成最终的可执行程序。(啥玩意儿我们后面讲)
- 示例 :
gcc code.o -o code
库文件和头文件不是一回事。头文件里面装的是声明,库文件里面是这个头文件,指向的功能的实现。我们在链接的时候是将我们的程序和这个库文件进行链接
1.2gcc/g++的常用用法
1.2.1合并以上步骤直接生成可执行程序
bash
[whb@bite-alicloud lesson7]$ gcc code.c
[whb@bite-alicloud lesson7]$ ll
total 20
-rwxrwxr-x 1 whb whb 8480 Oct 14 21:12 a.out
[whb@bite-alicloud lesson7]$ ./a.out
bash
[whb@bite-alicloud lesson7]$ gcc code.c -o mycode
[whb@bite-alicloud lesson7]$ ll
total 16
-rw-rw-r-- 1 whb whb 314 Oct 14 21:15 code.c
-rwxrwxr-x 1 whb whb 8536 Oct 14 21:15 mycode
[whb@bite-alicloud lesson7]$ ./mycode如上,我们可以直接用gcc编译源文件生成可执行程序 ,没有指定目标文件名称就默认为a.out 。
这个过程中需要注意的是:-o后面必须紧紧跟着目标文件,后面的源文件和目标文件位置可以互换。
bash
[whb@bite-alicloud lesson7]$ gcc -o mycode code.c
[whb@bite-alicloud lesson7]$ ll
total 16
-rw-rw-r-- 1 whb whb 314 Oct 14 21:15 code.c
-rwxrwxr-x 1 whb whb 8536 Oct 14 21:15 mycode
[whb@bite-alicloud lesson7]$ ./mycode1.2 多个源文件生成可执行程序
在处理包含多个源文件的项目时,我们通常有两种编译方式。
1.2.1 简单一步到位
日常我们的小代码可以直接这么写:将多个源文件一次性交给 GCC 编译并链接。
bash
[whb@bite-alicloud lesson7]$ gcc main.c tool.c -o myapp原理:GCC 会在幕后自动完成编译每个源文件并将其链接成一个最终的可执行程序。
1.2.2 分步增量编译
在大型项目中,为了提高效率(即"增量编译"),我们会先将每个源文件编译为二进制的目标文件,最后再统一链接。
bash
# 1. 分别编译每个源文件,生成 .o 文件(使用 -c 选项表示只编译不链接)
[whb@bite-alicloud lesson7]$ gcc -c main.c -o main.o
[whb@bite-alicloud lesson7]$ gcc -c tool.c -o tool.o
# 2. 将生成的多个 .o 文件链接在一起,生成最终的可执行程序
[whb@bite-alicloud lesson7]$ gcc main.o tool.o -o myapp- 优势 :如果项目有 1000 个文件,你只改动了
main.c,那么你只需要重新执行第一步生成新的main.o,然后直接执行第二步链接即可,无需重新编译另外 999 个文件。这正是以后学习 Makefile 的核心逻辑。
1.2 gcc/g++ 的常用选项与快速记忆
为了方便记忆这四个阶段对应的选项和文件后缀,可以结合键盘左上角的 ESC 键以及常见的 ISO 镜像后缀进行记忆:(我找个图给大家看看)
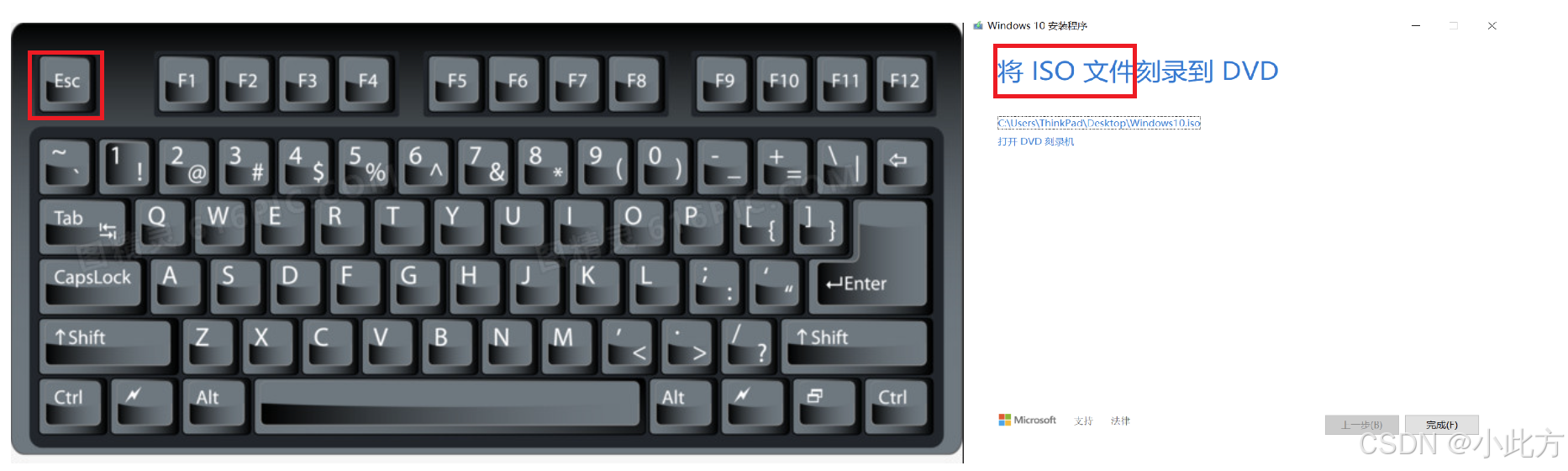
- 选项顺序 :
-E->-S->-c(对应键盘左上角的Esc键)。 - 后缀顺序 :
.i->.s->.o(对应iso镜像后缀)。
多文件同时编译示例:
在实际开发中,经常需要将多个源文件分别编译成目标文件,最后统一链接:
bash
#分别编译生成目标文件
gcc -c code1.c -o code1.o
gcc -c code2.c -o code2.o
#将多个目标文件链接生成一个可执行程序
gcc code.o code1.o code2.o -o code1.3不重要但是你知道会更好的一些编译器常识(了解)
(以下都是让Gemini帮我整理的)
1.3.1常见的编译优化技术
- 死代码删除 (Dead Code Elimination): 移除对程序结果无影响的不可达代码。
- 函数内联 (Function Inlining): 将函数体直接插入调用处,消除函数调用时的栈帧压栈、跳转和退栈开销。
- 寄存器调度: 将频繁访问的变量(如循环控制变量)放入寄存器,减少内存访问。
- 强度削弱 (Strength Reduction): 用更快的指令代替慢指令(例如:用 x << 1 代替 x * 2)。
1.3.2编译器的典型分析阶段过程
- 词法分析 (Lexical Analysis): 扫描源代码,识别关键字、标识符,输出 Token 流。
- 语法分析 (Syntax Analysis): 验证 Token 流是否符合语法规则,构建 Parse Tree (分析树)。
- 语义分析 (Semantic Analysis): 检查类型匹配、变量是否声明等逻辑错误,生成标注语法树。
二,深入理解编译原理与条件编译
2.1 条件编译的深度解析
2.1.1 预处理本质与命令行宏定义
预处理的本质是编译器在正式编译前,对文本代码进行修改和裁剪。除了在代码中使用 #define,我们还可以通过 gcc 命令行直接注入宏定义。
- 动态定义 :使用
-D选项可以在编译时定义宏,无需修改源代码。 - 示例 :
gcc code.c -o code -DVALUE=100 这就是等价于将宏#define VALUE=100直接插入到我们的代码中。
后面一定要紧紧跟着我们要定义的宏,不要有空格。
2.1.2 条件编译的实际意义
条件编译在工业级开发中有核心用途:
- 版本区分 :通过宏过滤,同一套代码可以生成 "社区版(免费)"和"专业版(收费)",将高级功能接口维护起来。
公司里总不能有两套产品吧,这样我维护他们就需要两班人,效率太低。于是两套产品合并成一套,用条件编译来控制,就蛮好。
- 环境适配:针对不同的操作系统(Linux vs Windows)或内核版本进行代码适配。
华为的鸿蒙OS上线以来,多家游戏公司推出了鸿蒙OS适配的版本。
- 开发调试 :在开发阶段开启 DEBUG 宏输出日志,发布正式版时一键关闭,保证程序运行效率。
2.1.3条件编译示例
你不会把条件编译是什么都忘记了吧,我举个例子让你回忆一下。
c
#include <stdio.h>
// 如果取消下面这行的注释,则编译为专业版;否则默认为家庭版
// #define PROFESSIONAL 1
int main() {
#ifdef PROFESSIONAL
printf("这是软件的专业版\n");
#else
printf("这是软件的家庭版\n");
#endif
return 0;
}或者可以在编译的时候做区分,使用命令行宏定义,不需要改动任何代码:
- 编译为家庭版(默认):
bash
[whb@bite-alicloud lesson7]$ gcc code.c -o family_version
[whb@bite-alicloud lesson7]$ ./family_version - 编译为专业版(命令行定义宏):
bash
[whb@bite-alicloud lesson7]$ gcc code.c -o pro_version -D PROFESSIONAL
[whb@bite-alicloud lesson7]$ ./pro_version 2.2 编程语言的发展历程
2.2.1 从打孔编程到高级语言
编程语言的进化是一个 从"反人类"到"人类友好" 的过程:
-
二进制编程 :最初使用纸带打孔,通过开关和二进制序列直接与硬件交互。

-
汇编语言:引入助记符,虽然比二进制直观,但依然严重依赖硬件。
-
高级语言 :C/C++、Java、Python 等语言出现,实现了跨平台和高度抽象。(大面向对象时代)
2.2.2 为什么要先变成汇编?
C/C++ 编译过程之所以要先生成汇编代码,是为了解耦。编译器后端只需要将高级语法翻译成对应的汇编指令 ,再由汇编器处理不同 CPU 架构的二进制细节。这种分层设计大大降低了编译器开发的复杂度。
2.3 编译器的自举
2.3.1 "先有鸡还是先有蛋"
先有C语言还是先有编译C语言的编译器?(你有没有这么想过doge)实际上这是一种递归的进化。
- 过程解析 :
- 最初,古人用汇编手写一个最简单的 C 语言编译器。
- 使用这个编译器,编译用 C 语言写的 0.2 版本编译器源码,得到用C语言写的编译器。
- 循环往复,直到编译器能够完全由本语言编写并实现自我编译。
三,初步认识动静态库与链接机制
3.1 什么是库?
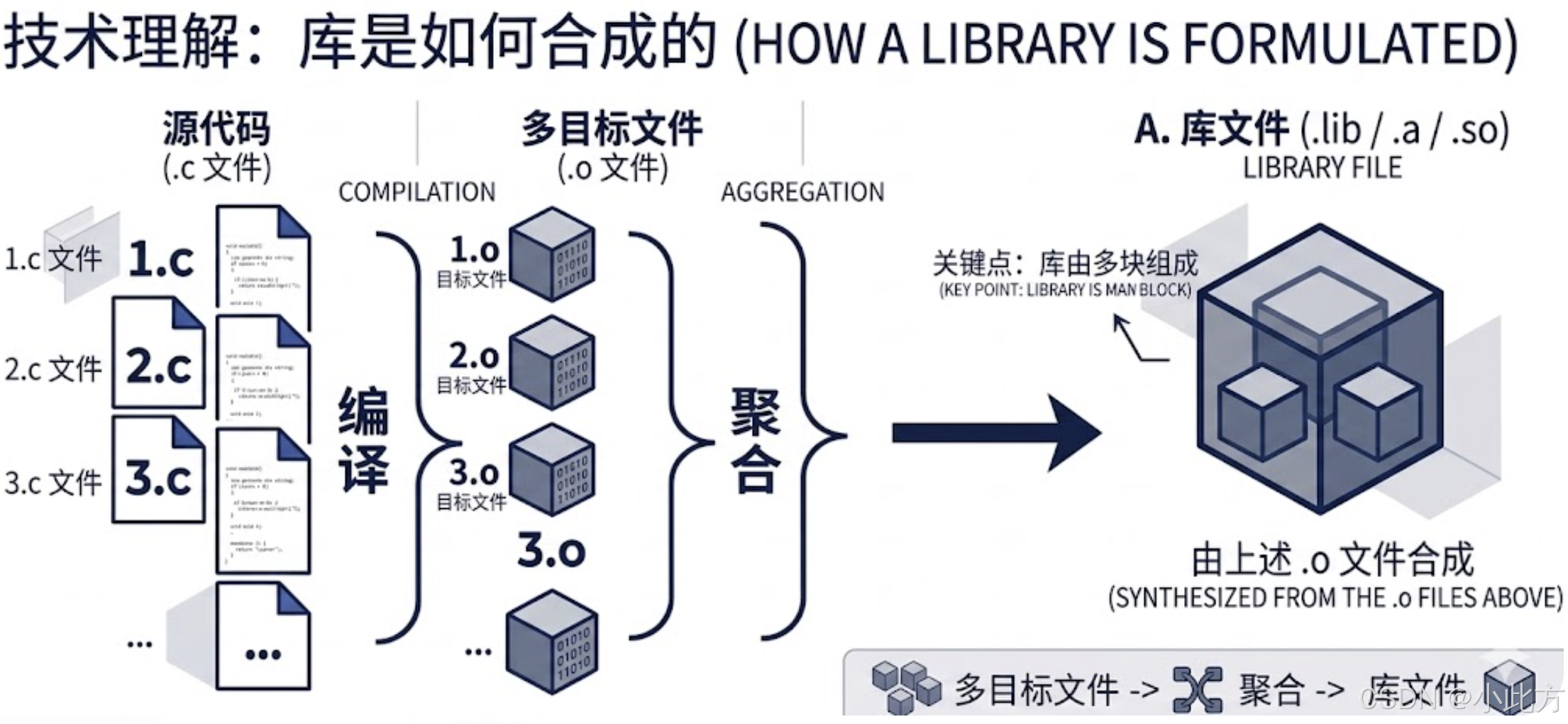
在 Linux 中,库本质上是编译好的可执行代码集合。 (很多的.o文件打包生成.so)
- 动态库 :Linux 下后缀为
.so,Windows 下为.dll。 - 静态库 :Linux 下后缀为
.a,Windows 下为.lib。 - C语言的动静态库:libc.so,libc.a
也许你已经发现了动静态库的命名规则,是的,lib + name +.so/.a。
科普一下前缀 lib 的重要性:在 Linux 中,链接器在查找库时,默认会自动寻找以 lib 开头的文件。
库是一套方法和数据集,为我们的开发提供最基本的保证(基本的接口,加速我们的二次开发。)
- 我们的 C 程序中,并没有定义
printf的函数实现,且在预编译中包含的stdio.h中也只有该函数的声明,而没有定义函数的实现。那么,是在哪里实现printf函数的呢? - 最后的答案是:系统把这些函数实现都做到了名为
libc.so.6(C标准库 )的库文件中去了,在没有特别指定时,gcc会到系统默认的搜索路径/usr/lib下进行查找,也就是链接到libc.so.6库函数中去,这样就能实现函数printf了,而这也就是链接的作用。
3.2 动态链接和静态链接
在我们的实际开发中,不可能将所有代码放在一个源文件中,所以会出现多个源文件。
而且多个源文件之间不是独立的,而是存在多种依赖关系, 如一个源文件可能会调用另一个源文件中定义的函数,但是每个源文件都是独立编译的,即每个 *.c 文件会形成一个 *.o 文件。
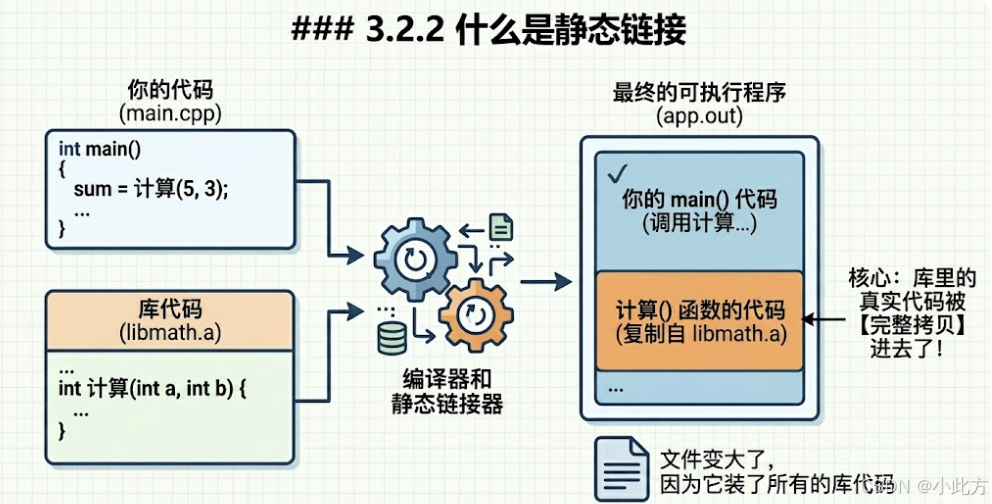
为了满足前面说的依赖关系,则需要将这些源文件产生的目标文件进行链接 ,从而形成一个可以执行的程序。这个链接的过程就是静态链接。
3.2.1什么是动态链接
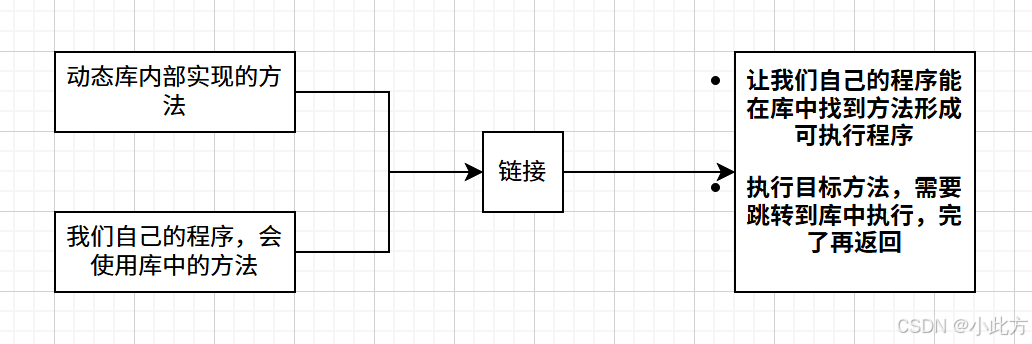
cpp
#include<stdio.h>
int main(){
printf("Ciallo~(∠·ω< )⌒☆!");
return 0;
}printf 到底是怎么跳过去的?
很多初学者以为 printf 的地址在编译时就定死了,其实不然。
- 头文件
<stdio.h>:它只是一个"说明书",告诉编译器printf怎么用,但它不提供地址。 - 编译阶段(预留空位) :
编译器发现你用了libc.so里的函数,它会把printf替换成一个地址存根。你可以理解为编译器在代码里挖了个坑,并贴了个标签叫"printf 的地址"。 - 运行阶段(填入地址) :
程序启动时,系统会将libc.so加载到内存。此时printf的真正地址确定了,系统会把这个地址回填到刚才那个"坑"里。 - 调用过程 :
程序执行到printf时,会先去那个"坑"里取地址,然后根据地址直接跳转 到libc.so内部执行。
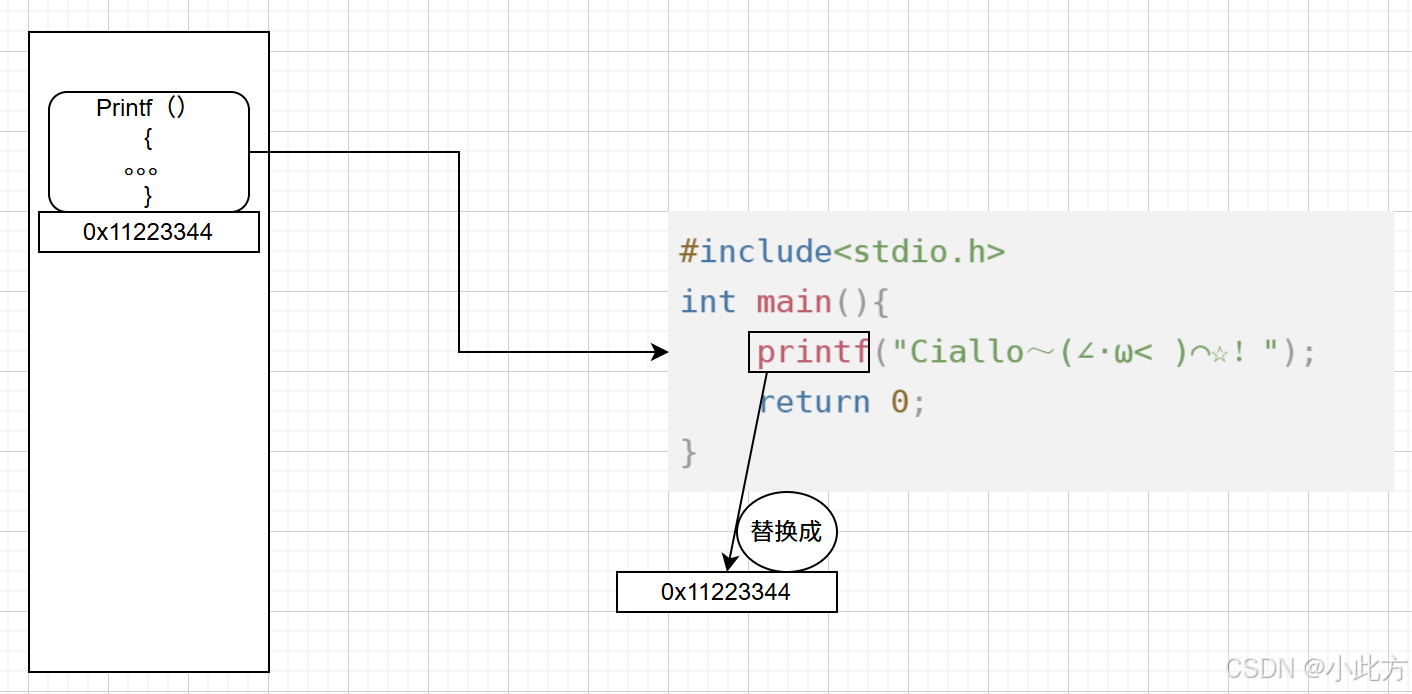
3.2.2什么是静态链接
讲完了动态链接,静态链接就显得非常"简单粗暴"了。
- 核心本质 :
静态链接就是在编译阶段,直接把库里面的代码拷贝一份,塞进我们的可执行程序里。 - 调用逻辑 :
拷贝过来之后,程序在运行期间不再依赖外部的.a文件。调用函数时,直接在自己的代码段里就能找到实现,原地跳转。
通俗理解 :
动态链接像是点外卖,吃饭(运行)的时候得等外卖员(系统)把菜(库函数)送过来;
静态链接则是自己在家囤货,吃的时候直接从冰箱里拿,虽然占地方(程序体积大),但随时随地都能吃,还不怕外卖员罢工。
静态库在形成可执行程序的时候,代码就已经被完整拷贝进去了。所以,静态链接生成的程序不依赖第三方库,走到哪都能跑!
3.2.1静态链接的缺点
- 浪费空间 :因为每个可执行程序中对所有需要的目标文件都要有一份副本,所以如果多个程序对同一个目标文件都有依赖 ,如多个程序中都调用了
printf()函数,则多个程序中都含有printf.o,所以同一个目标文件都在内存中存在多个副本。 - 更新比较困难:因为每当库函数的代码修改了,这个时候就需要重新进行编译链接形成可执行程序。
3.2.2静态链接的优点
- 在可执行程序中已经具备了所有执行程序所需要的任何东西,在执行的时候运行速度快。
但是你这个代码膨胀问题太严重了 (后文有演示),还是缺点大于优点。
3.2.3动态链接的优点
动态链接 的出现解决了静态链接中提到的问题。其基本思想是把程序按照模块拆分成各个相对独立部分 ,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
动态链接其实远比静态链接要常用得多 。比如我们查看 hello 这个可执行程序依赖的动态库,会发现它就用到了一个 C 动态链接库:
bash
$ ldd hello
linux-vdso.so.1 => (0x00007fffeblab000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)
# ldd 命令用于打印程序或者库文件所依赖的共享库列表。3.3静态库和动态库
3.3.1静态库和动态库的概念
- 静态库 :指编译链接时,把库文件的代码全部加入到可执行文件中。生成的文件比较大,但在运行时也不再需要库文件了。其后缀名一般为
.a。 - 动态库 :与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为
.so,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。完成了链接之后,gcc就可以生成可执行文件,如下所示:
gcc hello.o -o hello gcc默认生成的二进制程序,是动态链接的,这点可以通过file命令验证。
3.3.2静态库和动态库的形象演示
(以下内容纯属瞎编)
浙江省长兴县里最好的高中,List是你们学校的美国交换生,他的成绩非常好,但是一直有一个上网的需求。于是List就去找你们学校的学长,"网吧啊,出东门左拐400m就到了有一个红树林网吧。"于是List就记住了这个地址。"东门左拐400m。"。
List每天的课表是语文,数学,英语,政治。。。。(巴拉巴拉),下午一点他要出去上网,于是就按照这个地址找到了红树林网吧。并选择的最喜欢的100号机器。
慢慢的,List的室友认识到了不对劲,当他们得知了List每天都会趁着下午一点的空挡溜出去上网,于是也纷纷效仿。
但是终于有一天,校长发现了端倪,把出去上网吧的人都教训了一顿,然后向派出所举报,把红树林网吧干掉了。网吧老板于是就被拘留了,电脑也被没收。List和同学们发现,这下完蛋了,没有上网,每天都学不下去了。
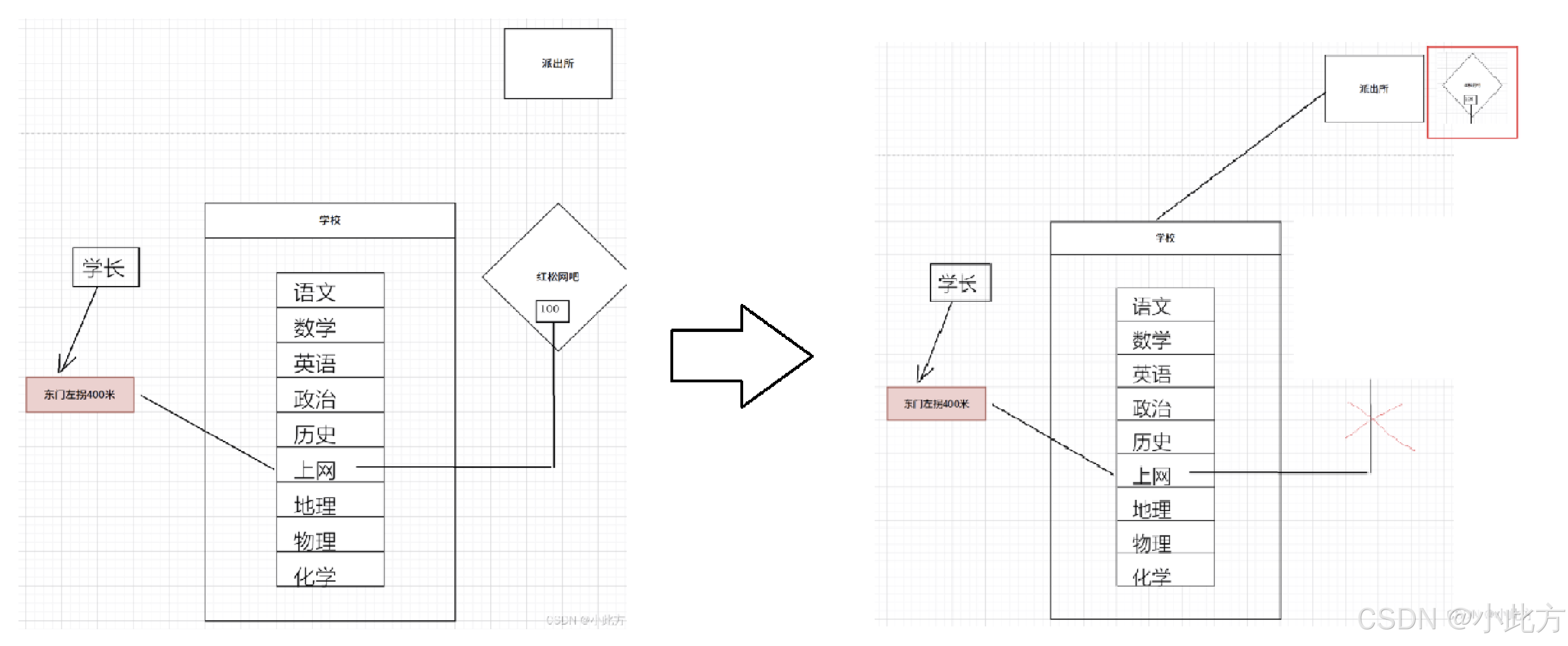
好!我得把你从这个瞎编的故事里扯回来。回顾刚才讲的,我们来介绍一下参演名单:
- 学长:就是头文件。
- List从学长那里获得了红树林网吧的地址:建立动态链接。
- List的课表:要执行的代码。
- 上网:调用的库函数的代码。
- 红树林网吧:动态库。(被多个程序共享可以称之为共享库)
- 红树林网吧的100号机器:List的程序调用的方法。
- 长兴高中:内存。
- 红树林网吧被取缔:库依赖瓦解,程序运行错误。
- 所以我们这个动态库,就是要在运行的时候跳转到指定的库的位置运行。(下午一点去上网)
- 同学们都去这个网吧上网(共享性)
- 没有了网吧我们的日常就无法进行了(依赖性强)
有没有听懂?(第一次这么讲,其实还蛮有意思的doge)
故事完了吗?没有。List把这件事告诉了他的父亲,于是他的父亲就来学校和校长沟通,于是允许了List带电脑来学校。然后呢List的老爸就去派出所,"你就是红树林网吧的老板吧"看着眼前的老头。"我儿子很喜欢你们这里的100号机器,告诉我这台机器的配置"。。。。巴拉巴拉。。。。。于是List的宿舍多了一台和100号机器一模一样的电脑。这样List又可以上网了。同学们看到后,又纷纷效仿,于是每一个学生都在宿舍有了一台电脑。
好,回来回来回来。我们再谈谈刚才发生了什么,List的宿舍多了一台电脑(把我们程序中使用的库方法,拷贝给我自己 ),他再也不用去网吧打游戏了(静态库只有在链接的时候有用,一旦形成可执行程序,静态库可以不再需要 ),那么这就是静态链接 ,被调用的库直接在你的代码里面含了一份。这样调用就更快了,也不需要"红树林网吧的地址"。但是每一个学生都去在自己的宿舍里按了一台电脑,(每个进程都把静态库含一份 )那么这个内存,重复代码是不是就太多了。这就是静态库的缺点。
到这里,你有没有彻底说:我明白了!好,那我们总结一下:
3.4对比总结
| 特性 | 动态链接 | 静态链接 |
|---|---|---|
| 原理 | 运行时跳转到库地址执行,代码共享 | 将库代码完整拷贝进程序中 |
| 可执行程序体积 | 小 | 大 |
| 依赖性 | 强(运行时必须有库文件) | 弱(编译后不再需要库文件) |
| 内存/磁盘利用率 | 高(多进程共享) | 低(重复代码多) |
四、 Linux 链接技术实战验证
4.1 实验环境准备与源代码
4.1.1 加入一个源代码 code.c
为了验证链接过程,我们可以使用一段最经典的 C 语言代码,它调用了标准库中的 printf 函数。
c
#include <stdio.h>
int main() {
printf("Hello, Linux\n");
return 0;
}编译生成默认可执行文件
bash
gcc code.c -o code4.2 动态链接验证
4.2.1 使用ldd查看库依赖
通过 ldd 命令可以清晰地看到程序在运行时需要加载的动态共享库:

- 执行命令 :
ldd code - 关键输出 :
libc.so.6 => /lib64/libc.so.6 - 现象分析 :这证明了程序并没有把
printf的实现直接打包,而是在运行时去/lib64路径下寻找libc.so.6。
4.2.2 使用file查看文件属性
file 命令可以识别文件的链接类型:

- 识别结果 :
ELF 64-bit LSB executable, ..., dynamically linked (uses shared libs) - 文件大小 :由于不包含库代码,文件体积非常小(约 8480 字节 )。

你的动态库的确在你的机器里面:
查看所有的动态库的家:/usr/lib64


4.3 静态链接验证
4.3.1 强制静态链接编译
使用 -static 参数要求编译器将所有依赖的库代码直接整合进可执行文件中(就是说强制静态链接吗? )

- 编译命令 :
gcc code.c -o code-static -static - 常见报错 :若系统未安装静态库(如
glibc-static),会出现cannot find -lc错误。
好,我们装一下:sudo yum install -y glibc-static
4.3.2 静态链接的结果对比

-
文件体积暴增 :静态链接后的
code-static大小约为 861288 字节 (相比动态链接增长了约 100 倍,当然我不是说一定是100倍,而是只有一个printf就增加了100倍在工程中可想而知,这是非常恐怖的 )。

-
独立性验证 :再次运行
ldd code-static会提示not a dynamic executable,表明其已不再依赖外部库文件。 -
属性确认 :
file命令显示为statically linked。

4.4 周边问题探讨:C++ 与标准库
4.4.1 C++ 的动态链接特点
对于 C++ 程序(如 codecpp),其链接过程更为复杂:


- 多库依赖 :除了 C 库
libc.so.6,还必须链接 C++ 标准库libstdc++.so.6。 - 路径解析 :在某些定制环境中,
libstdc++.so.6可能会指向特定的工具链 目录(如VimForCpp路径下)。
4.4.2 C++ 静态链接同理

同理,执行 g++ -static 时,若系统缺少 libstdc++.a,会触发 cannot find -lstdc++ 的报错 ,

五、 补充------动态库的真相
文章结束前,我最后不得不重新讲一讲动态库的真实。实际上它并非你们所想象的那样。
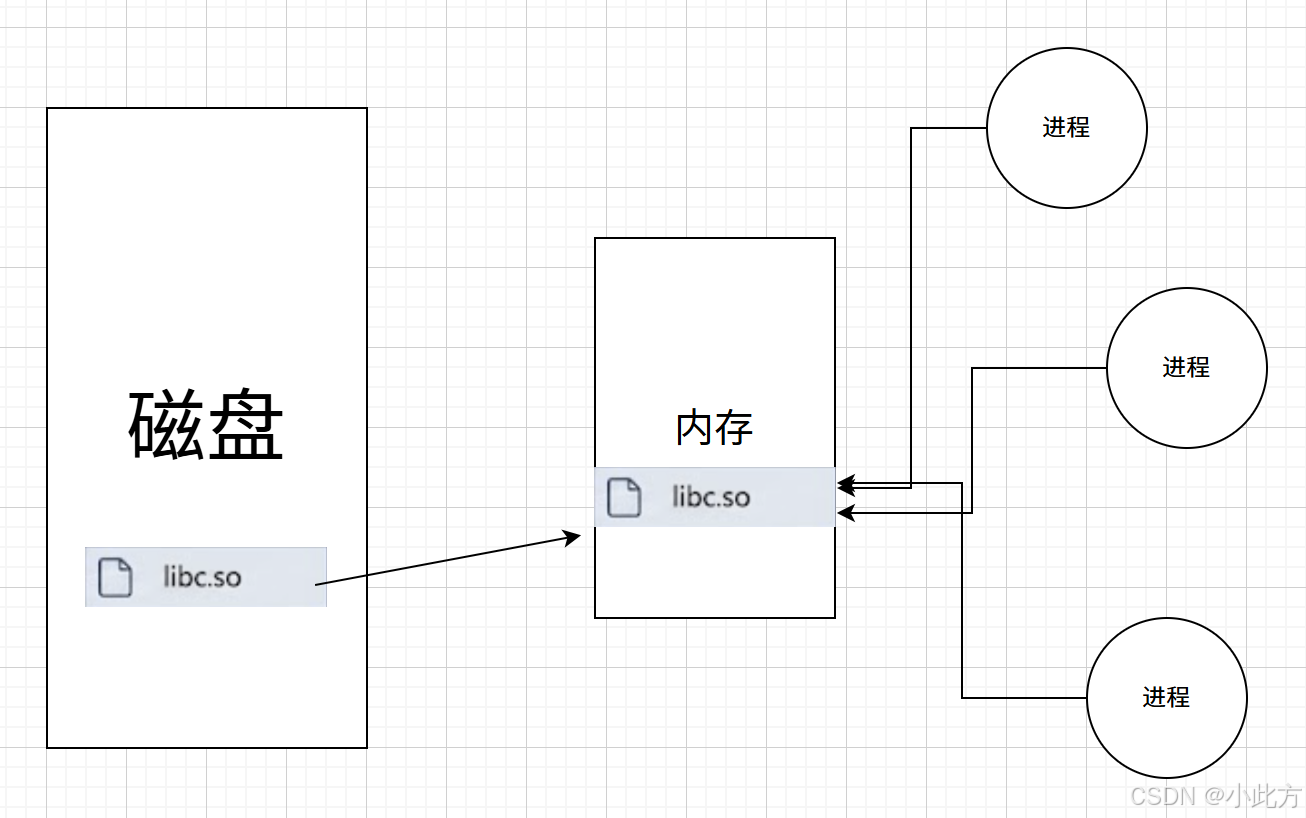
5.1 核心本质------内存中只存在一份
动态库最核心的真相在于:把语言层面公共的代码,在内存中未来只出现一份! (这句话太重要了 )
通过对比静态库,我们可以更清晰地看到动态库的优势:
- 静态库的弊端(浪费资源) :
静态库不需要单独加载到内存中,因为在形成可执行程序时,库代码就已经被拷贝到可执行文件内部了。这样会导致静态库在内存中存在多份,造成极大的内存浪费。 - 动态库的共享机制 :
动态库需要在首次执行的时候加载【一次】到内存中。一旦加载完成,它就成为了"共享库"。 - 高效的多进程调用 :
第一次加载后,后续运行的其他程序只需要加载可执行程序本身就可以了。不同的运行进程并不需要在自己的代码里包含库的副本,它们直接指向内存中那块唯一的库区域即可。
Linux 上 90% 的指令都依赖 C 动态库。在系统运行第一个指令的时候,就把库加载进内存。这样以后运行就不需要再次加载了。 (当然指令也有 Python 写的,也有 Shell 脚本写的。)
六、附录:gcc/g++ 常用选项参考
(以下内容由Gemini提供)
6.1编译流程控制
-E:仅进行预处理。不生成文件,需重定向输出。-S:编译到汇编语言。不进行汇编和链接。-c:编译到目标代码。-o [file]:指定输出文件名。
6.2链接与库相关
-static:采用静态链接方式生成文件。-shared:尽量使用动态库,生成的执行文件较小,但运行时依赖系统动态库。
6.3调试与优化
-g:生成调试信息,供 GNU 调试器(GDB)使用。- 优化级别 (
-O) :-O0:无优化。-O1:默认优化级别。-O3:最高优化级别,提升运行效率但可能增加编译时间。
6.4警告信息控制
-w:关闭所有警告信息。-Wall:开启所有常用警告信息(工程实践中强烈建议开启)。
好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!