
◆ 博主名称: 晓此方-CSDN博客 大家好,欢迎来到晓此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)

文章目录
- 概要&序論
- 一、背景与基本概念
- [二. 了解Make和Makefile](#二. 了解Make和Makefile)
-
- 2.1基本语法
-
- 2.1.1整体结构
- 2.2.2依赖关系与依赖方法
-
- [1. 依赖关系](#1. 依赖关系)
- [2. 依赖方法](#2. 依赖方法)
- 2.2.3项目清理
- 2.2优先级问题
- [2.3 执行原理:为什么有时候 make 会失败?](#2.3 执行原理:为什么有时候 make 会失败?)
-
- [2.3.1 扫描策略](#2.3.1 扫描策略)
- [2.3.2 为什么重复 make 会报错 "up to date"?](#2.3.2 为什么重复 make 会报错 "up to date"?)
-
- [2.3.2.1关键机制:Modify 时间](#2.3.2.1关键机制:Modify 时间)
- 2.3.2.2修改时间的细节(了解)
- [2.4 伪目标:.PHONY 的作用](#2.4 伪目标:.PHONY 的作用)
- [2.5 进阶:变量自动化与通用模板](#2.5 进阶:变量自动化与通用模板)
-
- [2.5.1 变量与特殊符号基础](#2.5.1 变量与特殊符号基础)
-
- [1. 定义与引用变量](#1. 定义与引用变量)
- [2. 特殊符号:隐藏回显(@)](#2. 特殊符号:隐藏回显(@))
- [3. 自动化变量](#3. 自动化变量)
- [4. 高级自动识别:wildcard 与模式替换](#4. 高级自动识别:wildcard 与模式替换)
- [5. 模式规则:%.o:%.c](#5. 模式规则:%.o:%.c)
- 6.include包含内容
- [2.5.4 一个超级全的Makefile参考](#2.5.4 一个超级全的Makefile参考)
- 2.5.5最后重新理一下make的完整工作过程
概要&序論
Hello 大家好,我是此方。 > 继上一篇对
g++编译指令的讲解,直接切入实战,重点解析makefile的编写规范与应用技巧。我们将从最基础的显式规则出发,逐步引入隐式模式与变量自动化,带你从头构建一套通用、可靠的自动化编译模板,提升 Linux 下的开发效率。 Well------正式开始。
一、背景与基本概念
1.1什么是make什么是makefile
先说结论,make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
1.1.1makefile是一个规范文件
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中 ,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
1.1.2make是一个命令工具
make是一个命令工具,是一个解释makefile中指令的命令工具 ,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一种在工程方面的编译方法。
1.2它们的意义
-
会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
-
makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
二. 了解Make和Makefile
2.1基本语法
2.1.1整体结构
Makefile 的核心规则由 目标 、依赖 和 命令 组成:
bash
target: prerequisites
command- 目标:通常是要生成的执行文件名或伪目标(别急,我们后面讲)。
- 依赖:生成该目标所需的文件(源码或中间文件)。
- 命令 :实际执行的编译指令。注意:命令前必须以
Tab键开头。
2.2.2依赖关系与依赖方法
我找个例子解释给大家听,
bash
myproc:myproc.c
gcc -o myproc myproc.c
.PHONY:clean
clean:
rm -f myproc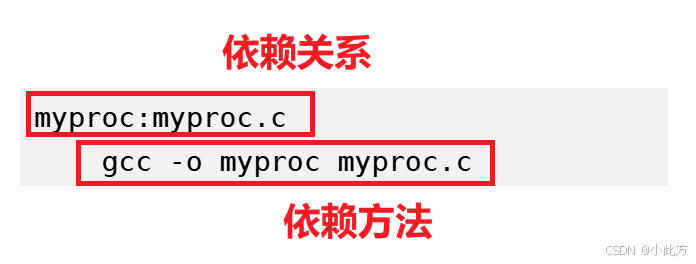
1. 依赖关系
在代码 myproc:myproc.c 中,冒号左边是结果 ,右边是原料。
- 本质 :它回答了"你是谁的儿子 "或者"你从哪里来"的问题。
- 举例 :就像你对你爸说:"爸,我是你儿子"。这确立了一个合法的血缘/逻辑关系。
- 错误示例 :如果你对着你叔叔说"爸,我是你儿子",这就是错误的依赖关系 。在 Makefile 中,如果你明明需要
main.c却写成了test.c,编译器就找不到正确的源头。
2. 依赖方法
在代码 gcc -o myproc myproc.c 中,这是具体的执行动作。
- 本质 :它回答了"要怎么做"的问题。光有关系是不够的,还得有具体的行动。
- 举例 :确立了父子关系后,你对你爸说:"爸,请给我打钱 "。"打钱"就是实现你生存目标的具体方法。
- 错误示例:你对你爸说"爸,请帮我考试"。虽然关系是对的,但这个方法(要求)是不合理的,现实中行不通,Makefile 里的命令写错了(比如语法错误)也会导致失败。
2.2.3项目清理
- 工程是需要被清理的
- 像 clean 这种,没有被第一个目标(你的Makefile写的第一个依赖)直接或间接关联,那么它后面所定义的命令将不会被自动执行,不过,我们可以显示要 make 执行。即命令------"make clean",以此来清除所有的目标文件,以便重编译。
- 但是一般我们这种 clean 的目标文件,我们将它设置为伪目标 ,用
.PHONY修饰,伪目标的特性是,总是被执行的。(后面讲)
2.2优先级问题
当你在终端输入 make 且不带任何参数时,make 解释器会按照以下顺序在当前目录下匹配文件。匹配到高优先级文件后将忽略后续文件。
| 优先级 | 文件名 | 推荐程度 | 使用场景建议 |
|---|---|---|---|
| 1 | GNUmakefile |
不推荐 | 仅在包含 GNU Make 特有扩展语法且不考虑跨平台时使用。 |
| 2 | makefile |
一般 | 较少见,通常是个人习惯或旧项目遗留。 |
| 3 | Makefile |
强烈推荐 | 工程实践标准。首字母大写使其在文件列表中置顶,易于识别。 |
2.3 执行原理:为什么有时候 make 会失败?
当我们执行 make 命令时,它并不是盲目运行的,而是有一套逻辑。
执行make命令直接走第一条,执行make xxx执行对应的一条。
2.3.1 扫描策略
- 默认目标 :
make会从Makefile的第一行开始扫描,默认执行遇到的第一个目标文件。 - 递归查找(入栈与出栈) :如果第一个目标的依赖项不存在,
make会向下搜索有没有生成该依赖项的规则。这就像一个入栈 的过程,直到找到最底层的源文件,再层层向上返回(出栈 )完成编译。这个过程中的步骤链接起来我们称之为------依赖链
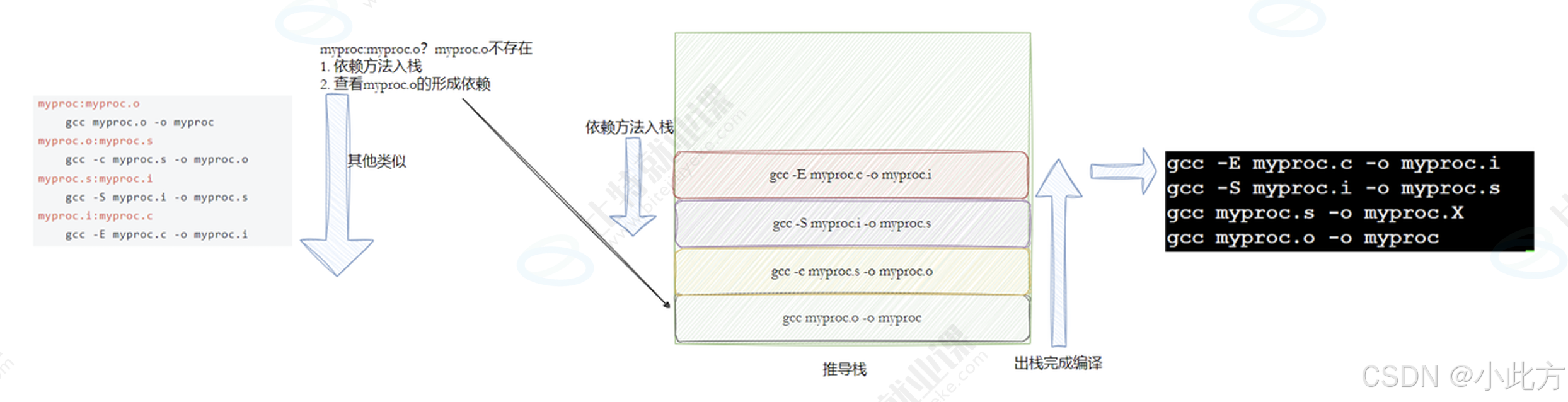
-
如果你人为的将这个调用链的一段删除掉,
makefile类似有一种缺省操作。任然可以执行。 -
如果你认为的将这个调用链的一段修改成错误的。
makefile则无法执行。
2.3.2 为什么重复 make 会报错 "up to date"?
你可能会发现,如果不修改代码,连续输入两次 make,第二次会提示:make: 'myproc' is up to date.。这是因为 make 非常"聪明",它会自动对比目标文件 和源文件的新旧。
2.3.2.1关键机制:Modify 时间
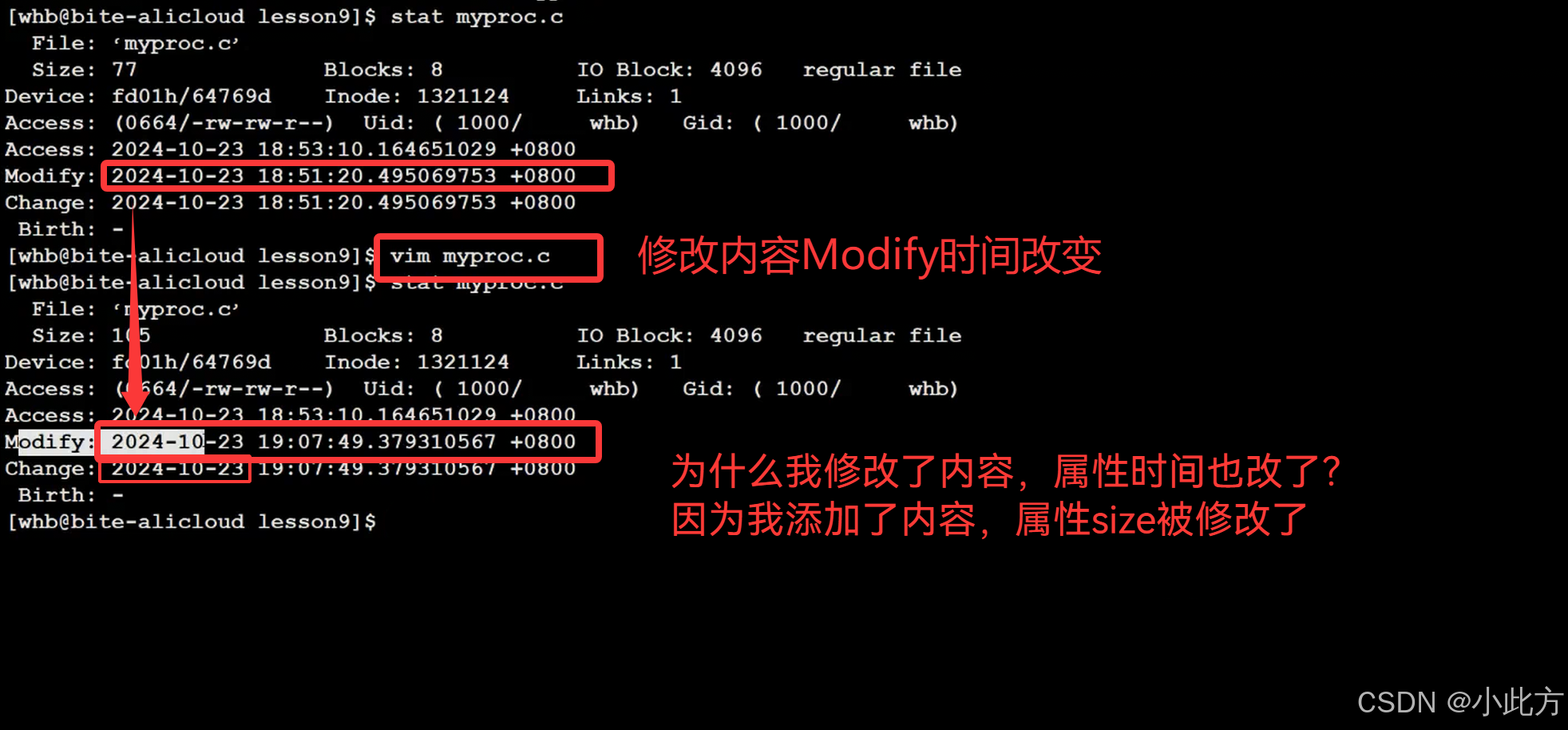
我们可以通过 stat [文件名] 指令查看文件的三个重要属性:
- Access :最后一次查看文件内容的时间。
- Modify :最后一次修改文件内容的时间。
- Change :最后一次修改文件属性的时间(如权限、所有者)。
判定标准:
- 如果 源文件.c 的 Modify 时间 < 目标文件.bin 的 Modify 时间 → \rightarrow → 代码没改,不执行编译。
- 如果 源文件.c 的 Modify 时间 > 目标文件.bin 的 Modify 时间 → \rightarrow → 代码更新了,重新执行 编译。
每一次修改都是重置.c的时间, 到可执行程序前面的时候就知道, 需要修改

这个时候,我们发现,以前讲的touch是不是就有了新的用途了?它可以让我们重新编译某些文件。
2.3.2.2修改时间的细节(了解)
修改Modify时间和change时间:
修改access时间:
因为查看文件在所有文件操作中占比最大,如果每查看一次时间就修改一次:会产生大量的隐形成本。于是可能修改n次后这个access时间才可能修改一次。
2.4 伪目标:.PHONY 的作用
2.4.1什么是伪目标
在 Makefile 中,我们经常会看到 .PHONY 这个关键字。
bash
.PHONY: clean
clean:
rm -f myproc- 什么是伪目标? 伪目标不代表一个真实生成的文件。
- 核心作用 :总是被执行。
- 为什么需要? 即使目录下恰好有一个叫
clean的文件,make clean依然会强制执行删除命令,而不会因为时间戳对比而失效。
2.4.2为什么不建议给编译生成可执行程序设置伪目标
简单来说:伪目标会破坏 make 的核心价值------"按需编译"。一个项目中有1000个文件,我只修改了一两个,理论上我没有必要对所有的文件都重新编译
- 非伪目标(正常情况) :
make会对比Modify时间。如果源文件没改,make就不执行编译。这在大型项目中能节省海量的编译时间。 - 伪目标 :一旦声明为
.PHONY,make将不再检查时间戳 。无论你的代码改没改,每次输入make都会重新编译一遍。对于只有几个文件的小作业没感觉,但对于有成千上万个文件的工程,这简直是灾难。
2.5 进阶:变量自动化与通用模板
在编写大型工程的 Makefile 时,如果每次增加源文件都要手动修改规则,那太痛苦了。为此,我们需要引入变量和自动化符号。
2.5.1 变量与特殊符号基础
1. 定义与引用变量
- 定义变量 :通常使用
变量名=值的形式。 注意 :在 Makefile 中,:=和=效果基本一致,但在处理复杂引用时有细微差别。建议初学者统一使用=。 - 引用变量 :使用
$(变量名)来取值。这就像 C 语言里的宏替换,修改一处,全局生效。- 好处:只需修改顶部的变量定义(如可执行程序名),后续所有的调用都会自动跟着修改。
2. 特殊符号:隐藏回显(@)
- 在 Makefile 的命令前加上
@符号,执行时终端不会回显这条原始指令,只会输出命令运行的结果。 - 这样可以让你的编译输出界面更干净。
3. 自动化变量
这是 Makefile 最精妙的地方,能让你少写很多重复代码:
$@:代表规则中的目标文件(冒号左边的东西)。$^:代表规则中所有的依赖文件列表(冒号右边所有的东西)。
bash
# 例子:
$(BIN):$(SRC)
$(CC) $(FLAGS) $@ $^
# 这里 $@ 自动替换为 $(BIN) 的值,$^ 自动替换为 $(SRC) 的值4. 高级自动识别:wildcard 与模式替换
如果项目里有 100 个 .c 文件,手动写变量名会累死。这时候我们需要两个"自动扫货"的神器:
wildcard(自动扫货) :- 写法 :
SRC=$(wildcard *.c) - 作用 :它会把当前目录下所有的
.c文件名全部抓取出来,存进SRC变量里。
- 写法 :
- 模式替换 (批量改名) :
- 写法 :
OBJ=$(SRC:.c=.o) - 作用 :它会把
SRC变量里所有以.c结尾的文件名,统统替换成.o。这样我们就自动得到了目标文件列表。
- 写法 :
5. 模式规则:%.o:%.c
有了文件列表,我们还需要告诉 make 怎么把每一个 .c 生成 .o。
-
写法 :
bash%.o:%.c $(CC) $(CFLAGS) $< -
含义 :
%是通配符。这句话的意思是:所有的.o文件,都依赖于同名的.c文件。 -
新变量
$<:$<:代表依赖文件列表中的第一个。- 为什么用它? 因为编译单个
.o时,我们只需要那一个对应的.c,用$<最精准。
6.include包含内容
- 功能:类似于 C 语言的 #include,它会把指定文件的内容原地展开到当前 Makefile 中。
- 用途:实现模块化管理。你可以把公共的变量定义或复杂的规则提取到独立文件中,让主 Makefile 保持简洁。
bash
# 1. 瞬间将 config.mk 里的变量(如 CC=gcc) 拷贝到这里
include config.mk
target: main.c
$(CC) $(CFLAGS) main.c -o target
clean:
rm -f target2.5.4 一个超级全的Makefile参考
bash
BIN=proc.exe # 定义生成的目标程序名,'=='和'='效果一致,但是建议使用'=',具体原因不讲,我放在加餐
CC=gcc # 定义编译器
#SRC=$(shell ls *.c) # 采⽤shell命令⾏⽅式,获取当前所有.c⽂件名
SRC=$(wildcard *.c) # 自动获取当前目录下所有 .c 文件
OBJ=$(SRC:.c=.o) # 将所有的 .c 结尾替换为 .o
LFLAGS=-o # 链接选项
CFLAGS=-c # 编译选项
# 生成可执行程序
$(BIN):$(OBJ)
@$(CC) $(LFLAGS) $@ $^
@echo "linking ... $^ to $@"
# 模式规则:把所有的 .c 编译成 .o
%.o:%.c
@$(CC) $(CFLAGS) $<
@echo "compling ... $< to $@"
.PHONY:clean
clean:
rm -f $(OBJ) $(BIN)
@echo "clean project ... done"
.PHONY:test
test:
@echo "Source files: $(SRC)"
@echo "Object files: $(OBJ)"2.5.5最后重新理一下make的完整工作过程
make 是如何工作的, 在默认的方式下, 也就是我们只输入 make 命令。那么:
- make 会在当前目录下找名字叫 "Makefile" 或 "makefile" 的文件。
- 如果找到, 它会找文件中的第一个目标文件 (target), 在上面的例子中, 他会找到
myproc这个文件, 并把这个文件作为最终的目标文件。 - 如果
myproc文件不存在, 或是myproc所依赖的后面的myproc.o文件的文件修改时间要比myproc这个文件新 (可以用touch测试), 那么, 他就会执行后面所定义的命令来生成myproc这个文件。 - 如果
myproc所依赖的myproc.o文件不存在, 那么make会在当前文件中找目标为myproc.o文件的依赖性, 如果找到则再根据那一个规则生成myproc.o文件。(这有点像一个堆栈的过程) - 当然, 你的 C 文件和 H 文件是存在的啦, 于是
make会生成myproc.o文件, 然后再用myproc.o文件声明make的终极任务, 也就是执行文件hello了。 - 这就是整个 make 的依赖性, make 会一层又一层地去找文件的依赖关系, 直到最终编译出第一个目标文件。
- 在找寻的过程中, 如果出现错误, 比如最后被依赖的文件找不到, 那么 make 就会直接退出, 并报错, 而对于所定义的命令的错误, 或是编译不成功, make 根本不理。
- make 只管文件的依赖性, 即, 如果在我找了依赖关系之后, 冒号后面的文件还是不在, 那么对不起, 我就不工作啦。
好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!