在大数据时代,亿级数据的查询速度是衡量数据库性能的重要指标。MySQL之所以能在海量数据中快速查找,核心功臣之一就是Buffer Pool(缓冲池)。本文将以实战风格,深入剖析Buffer Pool的工作原理,并手把手带你理解其优化策略。
一、Buffer Pool是什么?
Buffer Pool是MySQL InnoDB引擎内存中的一块核心区域,用于缓存磁盘上的数据页(Page) 和索引页 。InnoDB以页(默认16KB)为最小存储单位,当查询数据时,MySQL会优先从Buffer Pool中读取,避免直接访问磁盘(磁盘I/O是内存I/O的100-200倍),从而大幅提升查询速度。
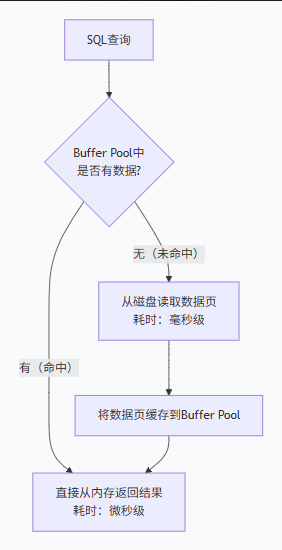
二、Buffer Pool核心原理深度解析
2.1 数据页管理机制:链表结构
Buffer Pool内部通过三种链表管理数据页:
| 链表类型 | 作用 | 存储内容 |
|---|---|---|
| Free List | 管理空闲页 | 未被使用的空白页 |
| LRU List | 管理热数据 | 已使用的页,按访问热度排序 |
| Flush List | 管理脏页 | 被修改过但未写入磁盘的页 |
工作流程:
-
当需要加载新数据页时,从Free List获取空闲页
-
若Free List为空,从LRU List末尾淘汰冷数据页
-
被淘汰的页若在Flush List中(脏页),需先刷回磁盘
2.2 核心淘汰策略:改进版LRU算法
传统LRU(Least Recently Used,最近最少使用)算法存在预读失效 和缓冲池污染 两大问题。InnoDB采用分代LRU(Midpoint Insertion Strategy)进行优化:
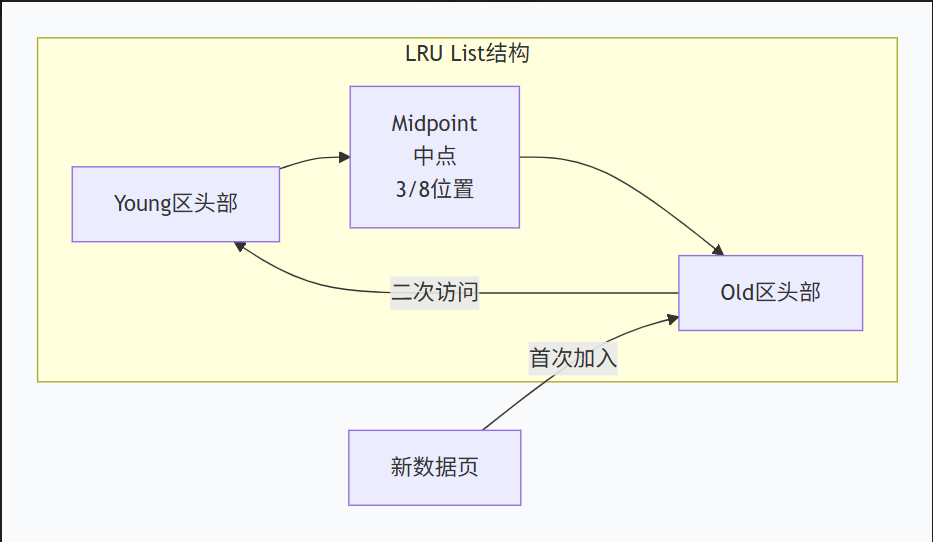
关键参数:
-
innodb_old_blocks_pct:Old区占比,默认37%(约3/8) -
innodb_old_blocks_time:数据页在Old区的停留时间阈值,默认1000ms
分代LRU的优势:
-
防止预读失效:预读的数据页先进入Old区,若不再被访问则快速淘汰
-
防止缓冲池污染:全表扫描的大批量数据仅在Old区停留1秒,不影响Young区的热数据
2.3 预读机制:提前加载未来可能访问的数据
InnoDB会智能预测并提前加载数据页到Buffer Pool,减少随机I/O:
| 预读类型 | 触发条件 | 预读范围 |
|---|---|---|
| 线性预读 | 顺序访问超过innodb_read_ahead_threshold(默认56)个页 |
异步读取下一个extent(64页) |
| 随机预读 | 一个extent中随机访问超过innodb_random_read_ahead阈值 |
同步读取整个extent |
2.4 脏页刷新机制:Checkpoint技术
当数据页被修改时,只更新Buffer Pool中的副本,产生脏页 。脏页必须通过Checkpoint机制异步刷回磁盘:
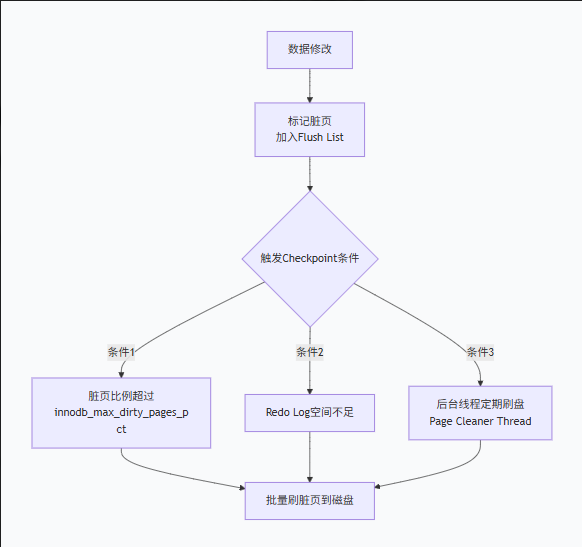
关键参数:
-
innodb_max_dirty_pages_pct:脏页比例上限,默认75% -
innodb_io_capacity:脏页刷新IO能力,默认200(SSD可调至2000+)
三、Buffer Pool的关键配置与优化
3.1 配置缓冲池大小
合理设置innodb_buffer_pool_size是性能优化的基石。
ini
# my.cnf配置文件
[mysqld]
# 专用数据库服务器:设置为物理内存的70%-80%
innodb_buffer_pool_size = 8G
# 云数据库或混合部署:设置为物理内存的50%-60%
innodb_buffer_pool_size = 4G配置建议:
-
小于1GB内存:使用默认值(128MB)
-
1GB-4GB内存:设置为内存的50%-60%
-
4GB以上内存:设置为内存的70%-80%
3.2 多实例缓冲池
对于大内存服务器(≥32GB),启用多实例缓冲池减少锁竞争。
ini
# 每个实例至少1GB,实例数通常设置为CPU核心数
innodb_buffer_pool_instances = 43.3 实时监控命中率
sql
-- 查询Buffer Pool命中率(理想值 > 99%)
select total_requests, disk_reads,
ROUND((1 - (disk_reads / total_requests)) * 100, 2) AS hit_rate_percent
from (
SELECT
(SELECT variable_value
FROM performance_schema.global_status
WHERE variable_name = 'Innodb_buffer_pool_read_requests') AS total_requests,
(SELECT variable_value
FROM performance_schema.global_status
WHERE variable_name = 'Innodb_buffer_pool_reads') AS disk_reads
) a3.4 查看Buffer Pool内存分布
sql
-- 查看各实例的详细状态(MySQL 5.7+)
SELECT
POOL_ID,
POOL_SIZE,
FREE_BUFFERS,
DATABASE_PAGES,
OLD_DATABASE_PAGES,
MODIFIED_DATABASE_PAGES
FROM information_schema.INNODB_BUFFER_POOL_STATS;四、实战:Buffer Pool如何加速亿级数据查询
假设有一张orders订单表,数据量达2亿行,主键为order_id。
4.1 无Buffer Pool的查询(首次查询)
sql
-- 首次查询,数据需从磁盘加载
SELECT * FROM orders WHERE order_id = 12345678;
-- 执行时间:约1200ms(磁盘I/O主导)4.2 有Buffer Pool的查询(再次查询)
sql
-- 再次查询相同数据,直接从Buffer Pool读取
SELECT * FROM orders WHERE order_id = 12345678;
-- 执行时间:约5ms(内存读取)性能对比 :Buffer Pool将查询速度提升了240倍。
4.3 批量数据加载时的缓冲池保护
sql
javascript
-- 执行大批量数据操作前,建议临时调整old区比例
SET GLOBAL innodb_old_blocks_pct = 80;
-- 执行全表扫描操作
SELECT COUNT(*) FROM orders WHERE create_time > '2024-01-01';
-- 操作完成后恢复
SET GLOBAL innodb_old_blocks_pct = 37;五、常见问题与解决方案
| 问题现象 | 可能原因 | 解决方案 | 监控指标 |
|---|---|---|---|
| 查询越来越慢 | Buffer Pool过小,频繁淘汰热数据 | 增加innodb_buffer_pool_size |
命中率 < 95% |
| 服务器内存不足 | Buffer Pool占用过大 | 降低缓冲池大小,或升级内存 | Swap使用率 > 10% |
| 写入性能下降 | 脏页刷新不及时 | 调整innodb_max_dirty_pages_pct和innodb_io_capacity |
脏页比例 > 70% |
| 数据库启动慢 | 缓冲池预热缺失 | 启用innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup |
加载时间 > 30分钟 |
六、总结与进阶建议
6.1 核心要点回顾
-
分代LRU算法:通过Young区和Old区分离,防止预读失效和缓冲池污染
-
脏页异步刷新:通过Checkpoint机制平衡性能与数据安全
-
智能预读:线性预读和随机预读减少磁盘I/O次数
6.2 优化优先级路线图
text
第一步:设置合适的innodb_buffer_pool_size(70%-80%物理内存)
↓
第二步:大内存服务器开启多实例缓冲池(innodb_buffer_pool_instances)
↓
第三步:根据存储介质调整innodb_io_capacity(HDD:200,SSD:2000+)
↓
第四步:定期监控命中率,确保持续 > 99%
↓
第五步:启用缓冲池预热机制,加速故障恢复6.3 进阶学习方向
-
深入研究 :MySQL 8.0的缓冲池并行刷脏机制
-
监控工具:使用Prometheus + Grafana可视化监控缓冲池指标
-
源码级别 :阅读InnoDB的
buf0buf.cc源码,理解LRU算法的底层实现