1:事物基础,为什么我们需要事物
1:并发操作带来的问题
没有事物控制的并发CURD会引发严重的数据一致性问题,最经典的就是火车票超卖问题
sql
-- 测试表初始化
CREATE TABLE tickets (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
nums INT NOT NULL DEFAULT 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO tickets VALUES (10, '西安<->兰州', 1);问题场景:
- 客户端 A 执行
SELECT nums FROM tickets WHERE id=10,得到nums=1 - 客户端 B 同时执行
SELECT nums FROM tickets WHERE id=10,也得到nums=1 - 客户端 A 执行
UPDATE tickets SET nums=nums-1 WHERE id=10,卖票成功 - 客户端 B 执行
UPDATE tickets SET nums=nums-1 WHERE id=10,导致同一张票被卖两次,最终nums=-1
2:事物的定义与ACID四大特性
事物是一组逻辑相关的DML语句的集合,这组语句要么全部执行成功,要么全部执行失败,是一个不可分割的整体。
事物必须满足ACID四大特性,这是解决并发问题的基础:
| 特性 | 英文 | 核心含义 | 对应案例 |
|---|---|---|---|
| 原子性 | Atomicity | 事务中的所有操作要么全部完成,要么全部回滚,不会停留在中间状态 | 银行转账:A 扣钱和 B 加钱必须同时成功或失败 |
| 一致性 | Consistency | 事务执行前后,数据库的完整性约束没有被破坏 | 转账前后,A 和 B 的总金额保持不变 |
| 隔离性 | Isolation | 多个并发事务之间相互隔离,互不干扰 | 一个事务的未提交修改,不应该被其他事务看到 |
| 持久性 | Durability | 事务一旦提交,对数据的修改就是永久的,即使系统崩溃也不会丢失 | 买票成功后,即使服务器宕机,购票记录也不会消失 |
关键补充:
- 原子性是手段 ,一致性是目的 ,隔离性是保障 ,持久性是结果
- 一致性分为数据库层面的一致性 (主键、外键、唯一约束等)和业务层面的一致性(如总金额不变),后者需要开发者自己保证
- MySQL 中只有InnoDB 引擎支持事务,MyISAM、MEMORY 等引擎均不支持
3:验证InnoDB对事物的支持
sql
-- 查看所有数据库引擎
SHOW ENGINES;
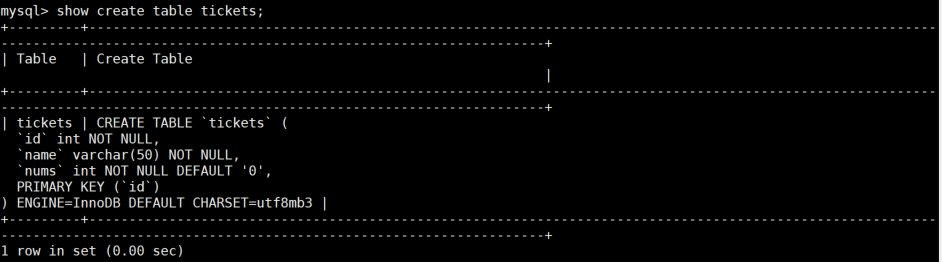
-- 查看当前表的引擎
SHOW CREATE TABLE tickets;
-- 尝试将表改为MyISAM引擎(不支持事务)
ALTER TABLE tickets ENGINE=MyISAM;
-- 测试MyISAM是否支持回滚
BEGIN;
UPDATE tickets SET nums=0 WHERE id=10;
ROLLBACK; -- 执行后数据不会回滚,MyISAM忽略ROLLBACK语句
-- 改回InnoDB引擎
ALTER TABLE tickets ENGINE=InnoDB;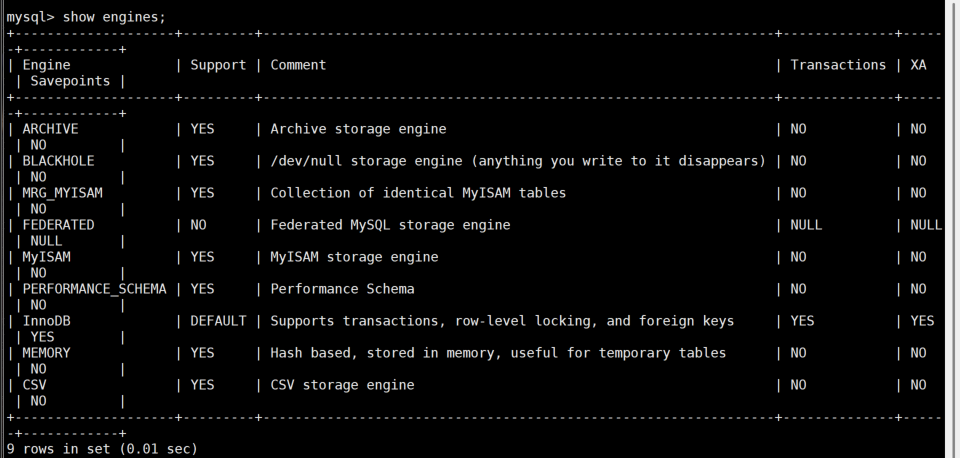
- InnoDB 引擎的
Transactions列显示为YES,支持事务 - MyISAM 引擎的
Transactions列显示为NO,不支持事务,执行 ROLLBACK 无效
2:事物的基本操作与提交方式
1:事物的提交方式
MySQL 支持两种事务提交方式:
- 自动提交(默认):每条 SQL 语句都是一个独立的事务,执行完成后自动提交
- 手动提交 :需要显式使用
BEGIN/START TRANSACTION开启事务,COMMIT提交,ROLLBACK回滚
2:自动提交和手动提交的区别
sql
-- 步骤1:查看当前自动提交状态
SHOW VARIABLES LIKE 'autocommit'; -- 默认值为ON
-- 步骤2:自动提交模式下的修改
UPDATE tickets SET nums=1 WHERE id=10;
-- 新开终端查询,数据已经更新(自动提交生效)
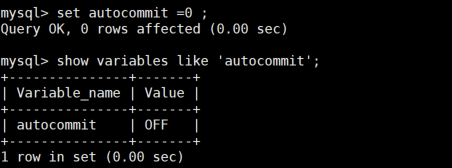
-- 步骤3:关闭自动提交
SET AUTOCOMMIT=0;
SHOW VARIABLES LIKE 'autocommit'; -- 显示OFF
-- 步骤4:关闭自动提交后的修改
UPDATE tickets SET nums=0 WHERE id=10;
-- 新开终端查询,数据还是1(未提交)
-- 步骤5:提交事务
COMMIT;
-- 新开终端查询,数据变为0(提交生效)
-- 步骤6:恢复自动提交
SET AUTOCOMMIT=1;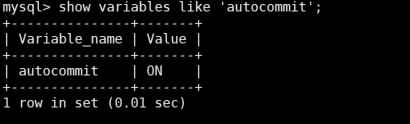


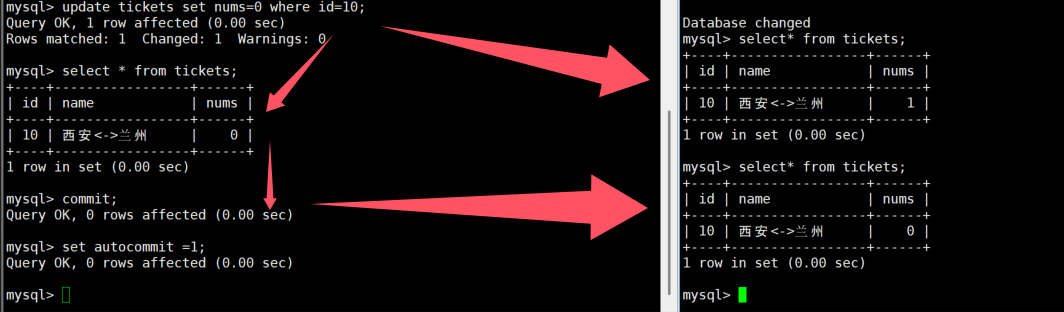
- 自动提交模式下,每条 SQL 执行后自动 COMMIT
- 关闭自动提交后,所有 SQL 都在同一个事务中,直到显式 COMMIT 或 ROLLBACK
- 注意:
SET AUTOCOMMIT=0只对当前会话有效,不影响其他会话
3:事物的保存点与部分回滚
sql
-- 初始化测试表
CREATE TABLE IF NOT EXISTS account (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL DEFAULT '',
balance DECIMAL(10,2) NOT NULL DEFAULT 0.0
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 步骤1:开启事务
BEGIN;
-- 步骤2:插入第一条记录,创建保存点save1
INSERT INTO account VALUES (1, '张三', 100.00);
SAVEPOINT save1;
-- 步骤3:插入第二条记录,创建保存点save2
INSERT INTO account VALUES (2, '李四', 10000.00);
SAVEPOINT save2;
-- 步骤4:插入第三条记录
INSERT INTO account VALUES (3, '王五', 5000.00);
-- 步骤5:查询当前数据(3条记录)
SELECT * FROM account;
-- 步骤6:回滚到保存点save2(删除第三条记录)
ROLLBACK TO save2;
SELECT * FROM account; -- 只剩张三和李四
-- 步骤7:回滚到保存点save1(删除第二条记录)
ROLLBACK TO save1;
SELECT * FROM account; -- 只剩张三
-- 步骤8:全回滚(删除所有记录)
ROLLBACK;
SELECT * FROM account; -- 空表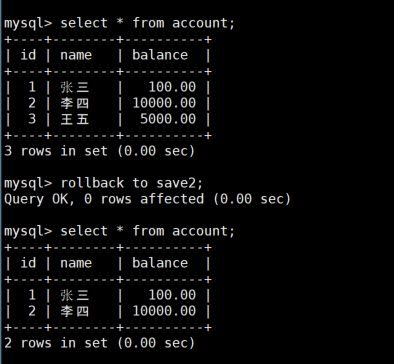
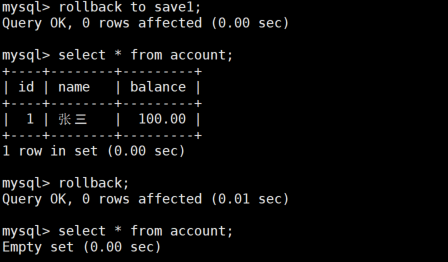
- 保存点允许我们在事务中设置多个回滚点,实现部分回滚
- 回滚到某个保存点后,该保存点之后的所有操作都会被撤销
- 保存点只在当前事务中有效,事务提交或回滚后自动失效
4:异常情况下的自动回滚
1:终端A
sql
BEGIN;
INSERT INTO account VALUES (1, '张三', 100.00);
SELECT * FROM account; -- 显示有1条记录
-- 不要COMMIT,直接按Ctrl+\强制终止MySQL客户端2:终端B
sql
-- 终端A崩溃前查询,可能看到未提交的数据(取决于隔离级别)
SELECT * FROM account;
-- 等待几秒后再次查询,数据消失(MySQL自动回滚)
SELECT * FROM account;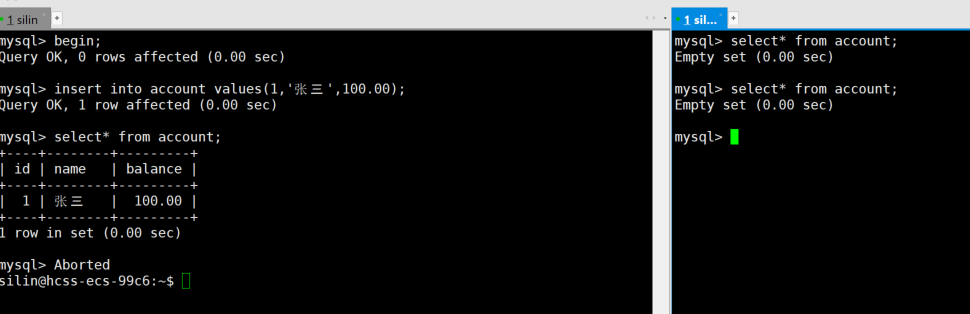
- 事务未提交时,如果客户端异常崩溃,MySQL 会自动回滚该事务
- 事务一旦提交,即使客户端崩溃,数据也会永久保存(持久性)
3:事物隔离级别
1:事物并发可能引发的三个问题
| 问题 | 定义 | 发生场景 |
|---|---|---|
| 脏读 | 一个事务读取了另一个事务未提交的修改 | 事务 A 修改了数据但未提交,事务 B 读取了这个修改,然后事务 A 回滚,导致事务 B 读到的数据无效 |
| 不可重复读 | 同一个事务中,多次读取同一数据,得到的结果不同 | 事务 A 第一次读取数据后,事务 B 修改并提交了该数据,事务 A 第二次读取得到不同的结果 |
| 幻读 | 同一个事务中,多次执行相同的查询,得到的记录数不同 | 事务 A 第一次查询得到 N 条记录,事务 B 插入了一条新记录并提交,事务 A 第二次查询得到 N+1 条记录 |
关键区别:
- 不可重复读的重点是修改和删除
- 幻读的重点是新增
2:MySQL的四种隔离级别
MySQL 提供了四种隔离级别,从低到高依次为:
- 读未提交(Read Uncommitted):最低级别,所有事务都能看到其他事务未提交的修改
- 读提交(Read Committed):只能看到其他事务已经提交的修改(大多数数据库的默认级别)
- 可重复读(Repeatable Read):MySQL 的默认级别,同一个事务中多次读取同一数据结果一致
- 串行化(Serializable):最高级别,强制事务串行执行,完全避免并发问题
不同隔离级别对并发问题的解决程度:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 |
|---|---|---|---|---|
| 读未提交 | ✅ | ✅ | ✅ | 最高 |
| 读提交 | ❌ | ✅ | ✅ | 较高 |
| 可重复读 | ❌ | ❌ | ❌(MySQL 特殊实现) | 一般 |
| 串行化 | ❌ | ❌ | ❌ | 最低 |
注意:标准 SQL 中,可重复读级别仍然会出现幻读,但 MySQL 的 InnoDB 引擎通过 **Next-Key Lock(间隙锁 + 行锁)** 解决了幻读问题。
3:读未提交级别和脏读
序号为实验步骤
1:设置全局隔离级别为读未提交
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 重启MySQL客户端后验证
SELECT @@tx_isolation; -- MySQL 5.7
-- SELECT @@transaction_isolation; -- MySQL 8.0+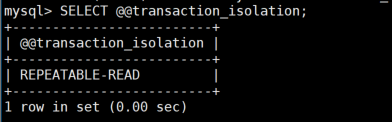
2:终端A
sql
BEGIN;
UPDATE account SET balance=123.00 WHERE id=1;
-- 不要COMMIT3:终端B
sql
BEGIN;
SELECT * FROM account WHERE id=1; -- 读到balance=123.00(脏读)4:终端A
sql
ROLLBACK;5:终端B
sql
SELECT * FROM account WHERE id=1; -- 读到balance=100.00,之前的123.00是脏数据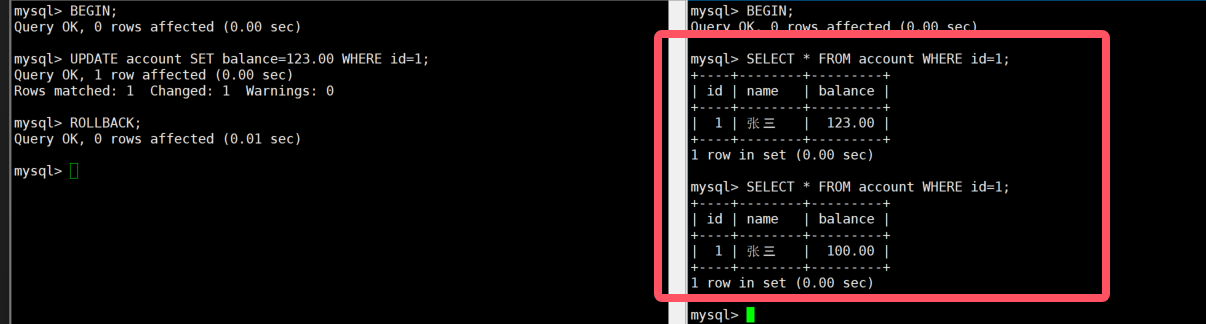
- 读未提交级别下,事务可以读取到其他事务未提交的修改,出现脏读
- 该级别几乎没有加锁,性能最高,但实际生产中绝对不会使用
4:读提交级别与不可重复读
1:设置全局隔离级别为读提交
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 重启客户端后验证
SELECT @@tx_isolation;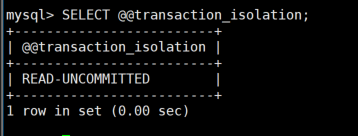
2:终端A
sql
BEGIN;
SELECT * FROM account WHERE id=1; -- balance=100.003:终端B
sql
BEGIN;
UPDATE account SET balance=321.00 WHERE id=1;
COMMIT;4:终端A
sql
SELECT * FROM account WHERE id=1; -- balance=321.00(不可重复读)
COMMIT;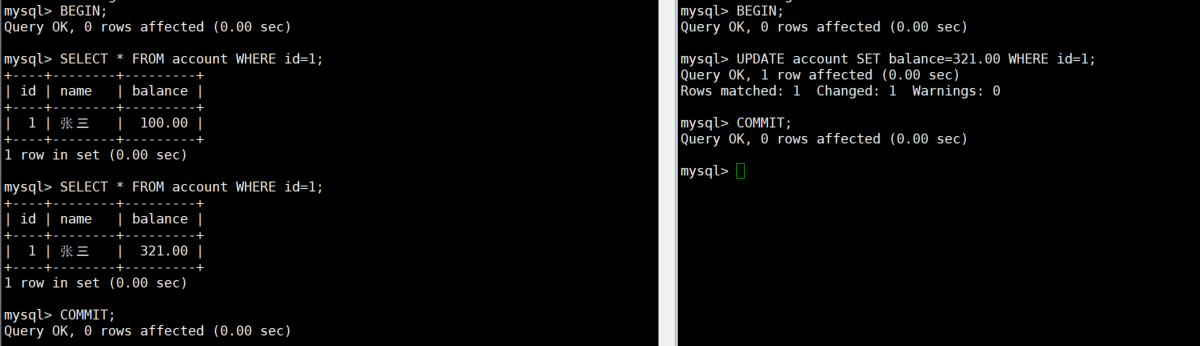
- 读提交级别下,事务只能看到其他事务已经提交的修改,解决了脏读
- 同一个事务中,多次读取同一数据可能得到不同的结果,出现不可重复读
5:可重复读级别与幻读验证
1:设置全局隔离级别为可重复读
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 重启客户端后验证
SELECT @@tx_isolation;2:验证不可重复读已解决(懒得敲终端两字了)
A:
sql
BEGIN;
SELECT * FROM account WHERE id=1; -- balance=321.00B:
sql
BEGIN;
UPDATE account SET balance=4321.00 WHERE id=1;
COMMIT;A:
sql
SELECT * FROM account WHERE id=1; -- 仍然是321.00(可重复读)
COMMIT;
SELECT * FROM account WHERE id=1; -- 提交后看到4321.00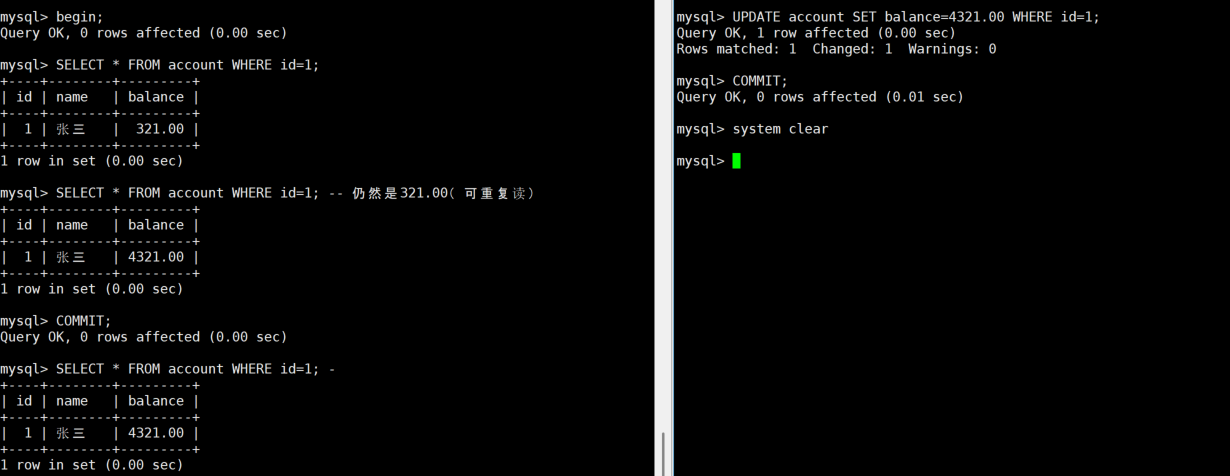
3:验证幻读已解决
A:
sql
BEGIN;
SELECT * FROM account; -- 只有1条记录(id=1)B:
sql
BEGIN;
INSERT INTO account VALUES (2, '李四', 10000.00);
COMMIT;A:
sql
SELECT * FROM account; -- 仍然只有1条记录(没有幻读)
COMMIT;
SELECT * FROM account; -- 提交后看到2条记录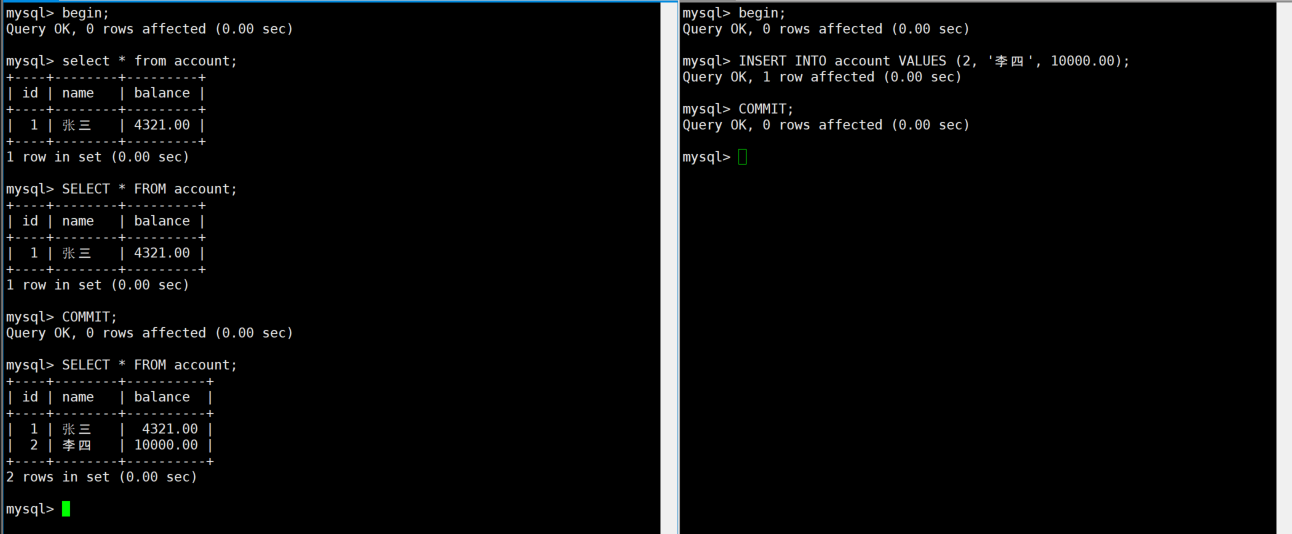
- MySQL 的可重复读级别解决了不可重复读问题
- MySQL 通过 Next-Key Lock 解决了幻读问题,这是 MySQL 优于其他数据库的地方
6:串行化级别与锁等待
1:设置全局隔离级别与串行化
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 重启客户端后验证
SELECT @@tx_isolation;
2:终端A
sql
BEGIN;
SELECT * FROM account; -- 加共享锁3:终端B
sql
BEGIN;
UPDATE account SET balance=1.00 WHERE id=1; -- 会被阻塞,直到终端A提交或回滚4:终端A
sql
COMMIT; -- 终端B的UPDATE会立即执行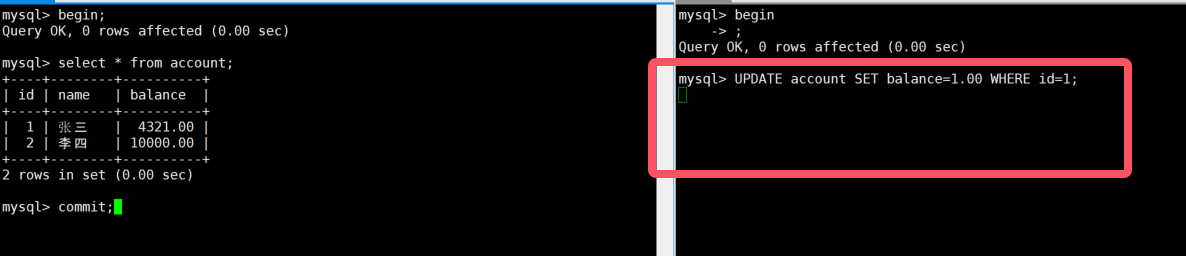
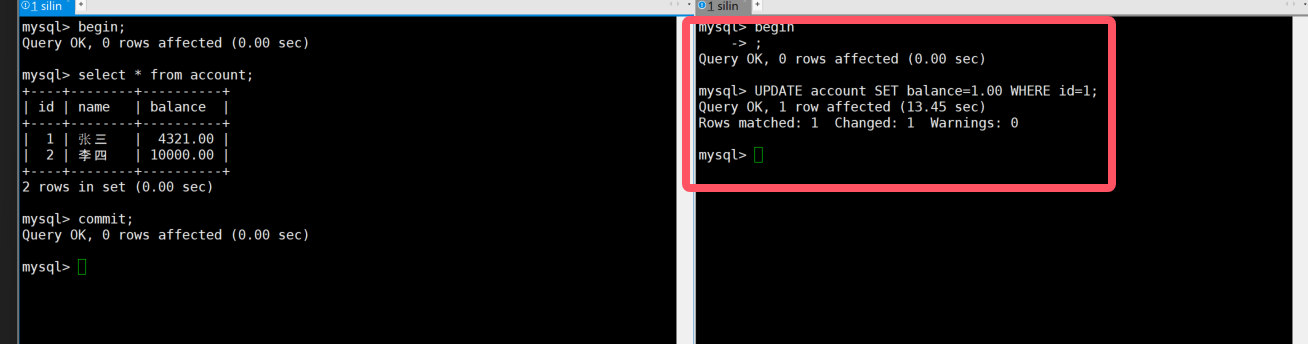
- 串行化级别下,所有读操作都会加共享锁,写操作都会加排他锁
- 读写操作之间会互相阻塞,强制事务串行执行
- 该级别性能极低,实际生产中几乎不会使用
4:MVCC底层原理:无锁并发控制的核心
1:什么是MVCC
MVCC(多版本并发控制)是InnoDB是西安隔离性的核心机制,他通过保存数据的多个历史版本,让读操作不需要加锁,从而实现读写不阻塞,大大提高了数据库的并发性。
MVCC 主要解决了读 - 写冲突问题:
- 读操作(快照读)不需要加锁,不会阻塞写操作
- 写操作也不会阻塞读操作
2:MVCC的三个核心组件
1:隐藏字段
InnoDB 会为每一行数据添加三个隐藏字段:
- DB_TRX_ID(6 字节):最近一次修改(插入 / 更新)该行数据的事务 ID
- DB_ROLL_PTR(7 字节):回滚指针,指向该行数据的上一个版本(存储在 undo log 中)
- DB_ROW_ID(6 字节):隐藏主键,如果表没有定义主键,InnoDB 会自动生成
2:Undo Log
Undo Log 是 InnoDB 用于实现事务回滚和 MVCC 的日志,它保存了数据的历史版本。当执行 UPDATE/DELETE 操作时,InnoDB 会先将原始数据拷贝到 Undo Log 中,形成一个历史版本。
多个历史版本通过DB_ROLL_PTR 指针连接成一个版本链。
3:Read VIew
Read View 是事务进行快照读时生成的读视图,它记录了当前系统中活跃的事务 ID,用于判断数据版本的可见性。
Read View 包含四个核心字段:
m_ids:当前系统中活跃的事务 ID 列表up_limit_id:活跃事务中最小的 IDlow_limit_id:系统下一个要分配的事务 ID(当前最大事务 ID+1)creator_trx_id:创建该 Read View 的事务 ID
3:数据版本可见性判断规则
当事务读取某行数据时,会从版本链的最新版本开始,依次判断每个版本是否可见:
- 如果版本的
DB_TRX_ID < up_limit_id:该版本的事务已经提交,可见 - 如果版本的
DB_TRX_ID >= low_limit_id:该版本的事务是在 Read View 生成之后才启动的,不可见 - 如果版本的
DB_TRX_ID在up_limit_id和low_limit_id之间:- 如果
DB_TRX_ID在m_ids列表中:该版本的事务还在活跃,不可见 - 如果
DB_TRX_ID不在m_ids列表中:该版本的事务已经提交,可见
- 如果
- 如果当前版本不可见,就通过
DB_ROLL_PTR找到上一个版本,继续判断,直到找到可见的版本或遍历完整个版本链
4:RR与RC的本质区别
RR 和 RC 隔离级别的本质区别在于Read View 的生成时机不同:
- RC 级别:每次快照读都会生成一个新的 Read View,所以能看到其他事务已经提交的最新修改,导致不可重复读
- RR 级别:同一个事务中,只有第一次快照读会生成 Read View,之后的所有快照读都使用同一个 Read View,所以能保证可重复读
5:当前读与快照读的区别
1:设置隔离级别为RR
sql
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 重启客户端2:初始化数据
sql
TRUNCATE TABLE account;
INSERT INTO account VALUES (1, '张三', 100.00);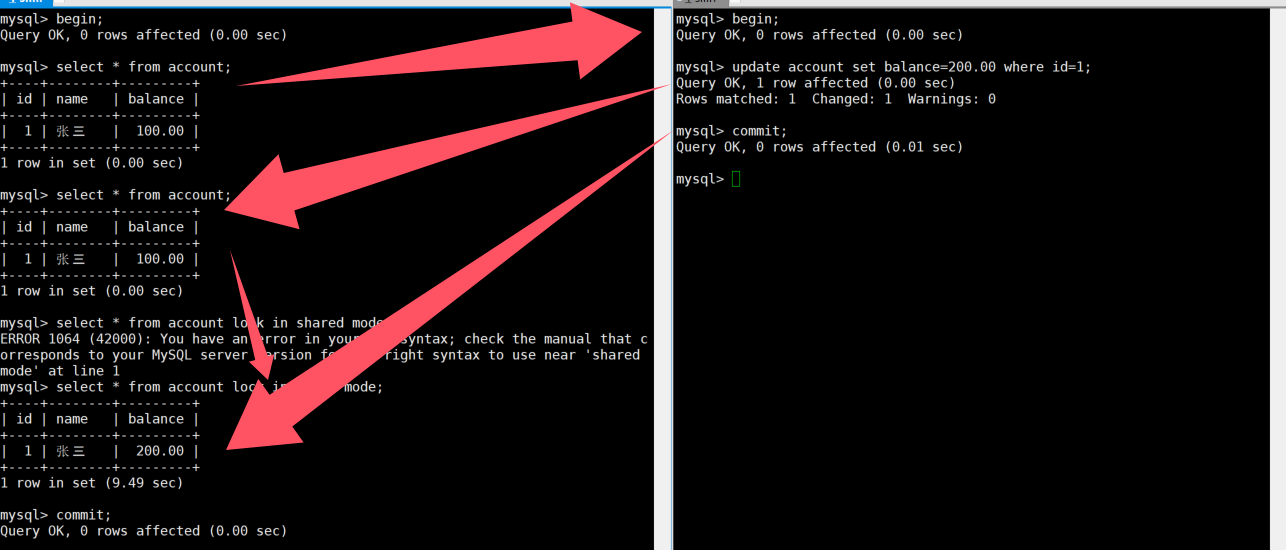
- 快照读:普通的 SELECT 语句,读取的是历史版本,不需要加锁
- 当前读:SELECT ... LOCK IN SHARE MODE、SELECT ... FOR UPDATE、INSERT、UPDATE、DELETE,读取的是最新版本,需要加锁
- RR 级别下,快照读使用同一个 Read View,当前读总是读取最新版本
5:事务进阶
1:事务的额分类
根据事务的复杂程度,事务可以分为以下几类:
- 扁平事务:最基本的事务类型,所有操作都在同一个层次,要么全部成功,要么全部失败
- 带保存点的扁平事务:在扁平事务的基础上增加了保存点,支持部分回滚
- 链式事务:一个事务提交后自动开启下一个事务,事务之间通过上下文传递
- 嵌套事务:事务中包含子事务,子事务的提交依赖于父事务的提交
- 分布式事务:涉及多个数据库或资源的事务,需要保证跨资源的原子性
2:InnoDB事务的底层实现:Redo Log与Undo Log
InnoDB 通过Redo Log 和Undo Log共同实现事务的 ACID 特性:
- Undo Log:实现原子性和 MVCC,保存数据的历史版本,用于回滚和快照读
- Redo Log:实现持久性,记录对数据页的修改,当系统崩溃时,通过 Redo Log 恢复未刷盘的数据
两阶段提交:为了保证 Redo Log 和 Binlog 的一致性,InnoDB 采用了两阶段提交机制:
- 准备阶段:将 Redo Log 写入磁盘,标记事务为准备状态
- 提交阶段:将 Binlog 写入磁盘,然后标记 Redo Log 为提交状态
3:更新丢失的问题与解决方案
MVCC 解决了读 - 写冲突,但无法解决写 - 写冲突,即更新丢失问题。更新丢失分为两类:
- 第一类更新丢失:一个事务的回滚覆盖了另一个事务已经提交的修改(已被数据库解决)
- 第二类更新丢失:一个事务的提交覆盖了另一个事务已经提交的修改(需要开发者解决)
解决方案:
- 悲观锁:使用 SELECT ... FOR UPDATE 加排他锁,确保同一时间只有一个事务能修改数据
- 乐观锁:使用版本号或时间戳机制,在更新时检查版本号是否一致,如果不一致则重试
4:事务最佳实践
- 避免长事务:长事务会占用大量资源,导致锁等待和回滚段膨胀
- 合理设置隔离级别:大多数场景下使用 MySQL 默认的 RR 级别即可,不需要盲目提高隔离级别
- 避免大事务:将大事务拆分成多个小事务,减少锁持有时间
- 正确使用保存点:在复杂事务中使用保存点,避免全回滚带来的性能损失
- 不要在事务中执行耗时操作:如网络请求、文件 IO 等,会延长事务执行时间
- 及时提交或回滚事务:事务执行完成后立即提交或回滚,释放资源
5:常见事务坑
- 自动提交的坑:忘记关闭自动提交,导致每条 SQL 都是一个独立的事务
- 死锁问题:多个事务互相等待对方持有的锁,导致死锁
- 幻读的误区:认为所有隔离级别下的幻读都被解决了,实际上只有 MySQL 的 RR 级别解决了快照读的幻读
- 长事务导致的回滚段膨胀:长事务会导致 Undo Log 无法被清理,占用大量磁盘空间