
开篇
Agent 的"记忆"并非黑箱。它由多个独立环节组成------工作记忆管理、情景记忆提取、长期记忆存储、跨 Session 一致性保障、记忆置信度评估。任意一环断裂,都会表现为同一个症状:失忆。
但"失忆"只是表象。真正的问题在于:哪个环节断了?为什么断?断之后如何感知和修复?
本文从工程实践出发,系统梳理 Agent 记忆失效的 5 种典型模式。每一种都有真实的故障现象、可操作的排查步骤、以及经过验证的解法。不讲故事,只讲原理和工程。
5 种失效模式一览
| # | 失效环节 | 典型症状 | 本质问题 |
|---|---|---|---|
| 1 | 工作记忆 | 单次对话中答非所问 | 上下文窗口被污染 |
| 2 | 情景记忆 | 摘要保存后关键细节丢失 | 提取时机错误 |
| 3 | 长期记忆 | 向量检索命中了但答错了 | 语义漂移 |
| 4 | 跨 Session 一致性 | 多 session 后记忆被覆盖 | 写入冲突 |
| 5 | 记忆评分机制 | 检索到了但 Agent 主动跳过 | 边界情况下过度保守 |
第一种失效:工作记忆的上下文窗口污染
现象
单次对话进行到中后段时,Agent 开始出现明显的"失准"------回答与前文内容不连贯,对用户的追问答非所问,甚至重复之前已经明确否定过的结论。
根因
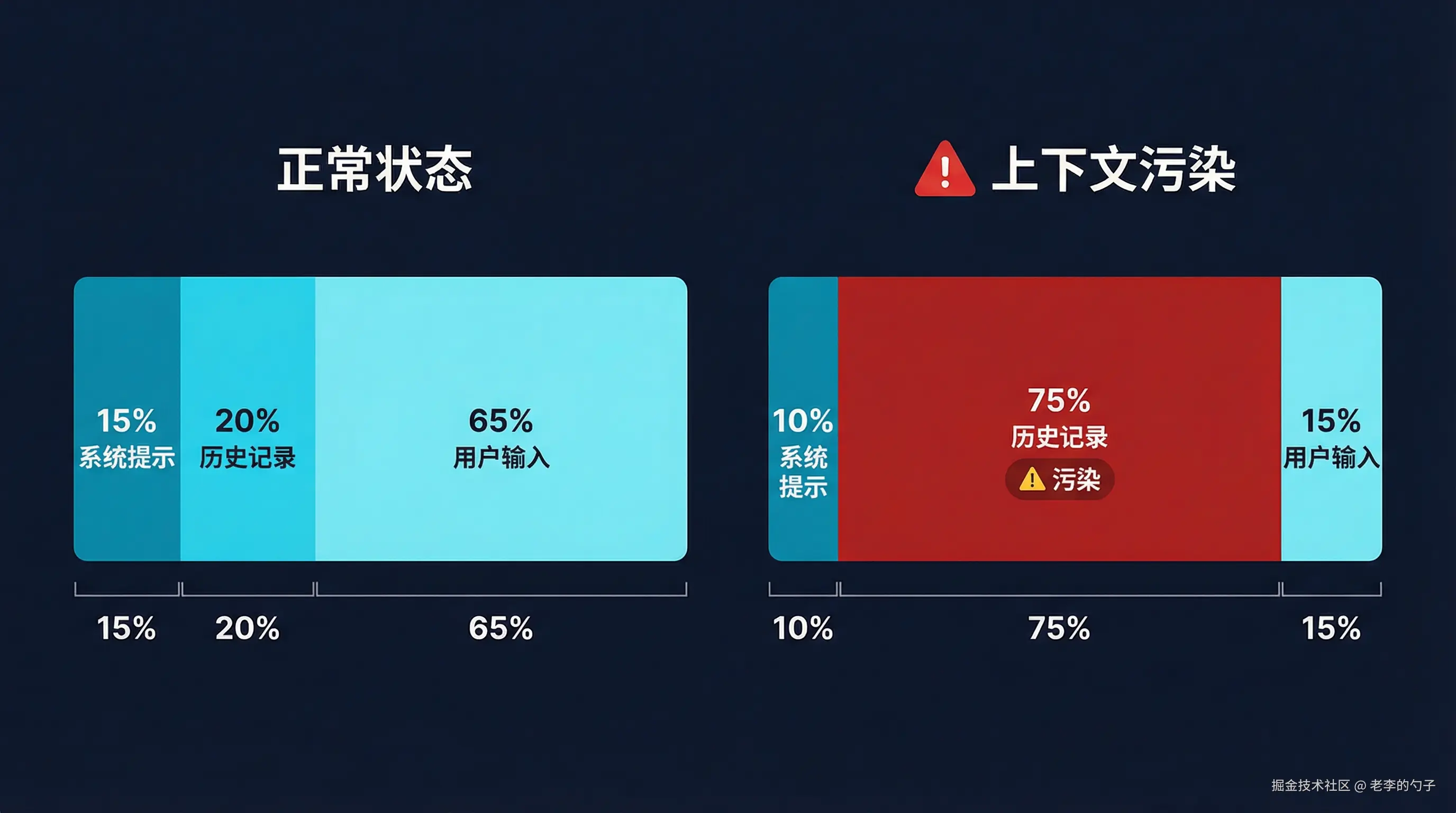
上下文窗口(Context Window)是工作记忆的物理边界。当对话历史积累到一定程度,窗口内的空间被大量历史消息占据,system prompt 中的角色定义、可用工具说明等关键静态信息被"挤"到了窗口边缘,Token 分布比例严重失衡:
csharp
[System Prompt] ████░░░░░░░░░░ 15%
[History] ████████████████████ 70%
[User Input] ████░░░░░░░░░░░░░ 15%在这个比例下,模型实际上是在"和自己的历史对话"而不是"服务用户"。这不是模型能力问题,是上下文内容质量的坍塌。
排查方法
在每次 LLM 调用时打印详细的 Token 分布:
python
def log_token_distribution(messages, model="gpt-4o"):
"""打印每次调用的 token 分布,定位上下文污染"""
# 估算各部分 token 数量
system_tokens = count_tokens(messages[0]["content"]) # system prompt
history_tokens = sum(count_tokens(m["content"]) for m in messages[1:-1])
user_tokens = count_tokens(messages[-1]["content"])
total = system_tokens + history_tokens + user_tokens
print(f"[Token Distribution]")
print(f" System: {system_tokens:>5} ({100*system_tokens/total:>5.1f}%)")
print(f" History: {history_tokens:>5} ({100*history_tokens/total:>5.1f}%)")
print(f" User: {user_tokens:>5} ({100*user_tokens/total:>5.1f}%)")
print(f" Total: {total:>5} / {get_model_context_limit(model)}")
# 危险信号:history 占比超过 60%
if history_tokens / total > 0.6:
print(" ⚠️ WARNING: History占比过高,上下文污染风险")当发现 History 占比持续超过 60% 时,就是需要干预的信号。
解法
动态上下文压缩:不是删除历史,而是让模型自行判断哪些历史片段值得保留:
python
def compress_context(messages, threshold=0.6):
"""
当 history 占比超过阈值时,自动触发压缩
注意:threshold=0.6 是经验值,需根据实际场景调整
"""
# 1. 识别"可压缩段落":双方确认的事实性结论
# 2. 将其压缩为一句摘要,替换掉多轮对话
# 3. 保留最近的 N 轮完整对话作为"最近记忆"
user_turns = count_user_turns(messages)
recent_rounds = min(3, max(1, user_turns)) # 至少保留1轮,防止边界条件下取到全部消息
summary = generate_compression_summary(messages[:-recent_rounds*2])
return [
messages[0], # system prompt 完整保留
{"role": "system", "content": f"[已压缩历史] {summary}"},
*messages[-recent_rounds*2:] # 保留最近 N 轮
]关键原则:压缩的是"已解决"的讨论,保留的是"正在进行的"上下文。
第二种失效:情景记忆的提取时机错误
现象
对话结束时 Agent 正确生成了摘要,并将其写入了长期记忆文件。但下一次对话开始时,发现之前明确讨论过的某个关键细节(比如"这个项目用 PostgreSQL 而不是 MySQL")在摘要中找不到,Agent 再次问出了同样的问题。
根因
问题的根源不是"没保存",而是"保存的时机不对"。常见的错误模式是定时摘要------每隔 N 轮对话或 N 分钟执行一次摘要写入。
makefile
用户: 我们项目用 PostgreSQL
用户: 库名叫 app_production
Agent: 好的已记住
[此时触发定时摘要,写入了 "项目使用 PostgreSQL,库名 app_production"]
用户: 字符集用 utf8mb4
用户: 排序规则用 utf8mb4_unicode_ci
[对话结束,摘要写入,但只写了"字符集 utf8mb4,排序规则 utf8mb4_unicode_ci"]
------ PostgreSQL 和库名的信息没有被包含在最后一次摘要中在最后一次摘要之前插入的关键信息,如果恰好在摘要触发之后出现,就会被漏掉。
排查方法
打印每次摘要写入前后的内容对比:
python
def diagnose_summary_extraction(session_history):
"""诊断摘要提取是否完整"""
summaries_written = []
for entry in session_history:
if entry["event"] == "summary_written":
# 对比:摘要写入前最后一条用户发言
# find_last_user_message_before: 示意函数,从会话历史中查找指定时间戳前的最后一条用户消息
last_user_msg = find_last_user_message_before(entry["timestamp"])
summary_content = entry["content"]
# 检查摘要是否覆盖了最后一条用户消息
key_entities = extract_key_entities(last_user_msg)
missing = [e for e in key_entities if e not in summary_content]
if missing:
print(f"[摘要遗漏 @ {entry['timestamp']}]")
print(f" 最后用户消息: {last_user_msg}")
print(f" 摘要内容: {summary_content}")
print(f" 遗漏实体: {missing}")
summaries_written.append(entry)
return summaries_written解法
放弃定时摘要,改用触发式摘要------让 LLM 自行判断"现在是否有关键信息需要记住":
python
def should_write_memory(messages) -> bool:
"""
由模型判断当前上下文是否包含需要持久化的关键信息
而不是由时间或轮数决定
"""
recent = messages[-6:] # 最近 3 轮对话
prompt = f"""
判断以下对话是否包含需要写入长期记忆的关键信息:
- 用户明确要求记住的结论(选型、配置、路径等)
- 多次重复出现的背景事实
- 与之前记忆可能冲突的新结论
对话片段:
{format_conversation(recent)}
回答格式:
WRITE: <一句话总结需要记住的内容>
SKIP: 无需记住
"""
response = call_llm(prompt)
return response.startswith("WRITE:")这个判断本身消耗 Token,但远小于因摘要时机错误导致的信息丢失成本。
第三种失效:长期记忆的向量检索"语义漂移"
现象
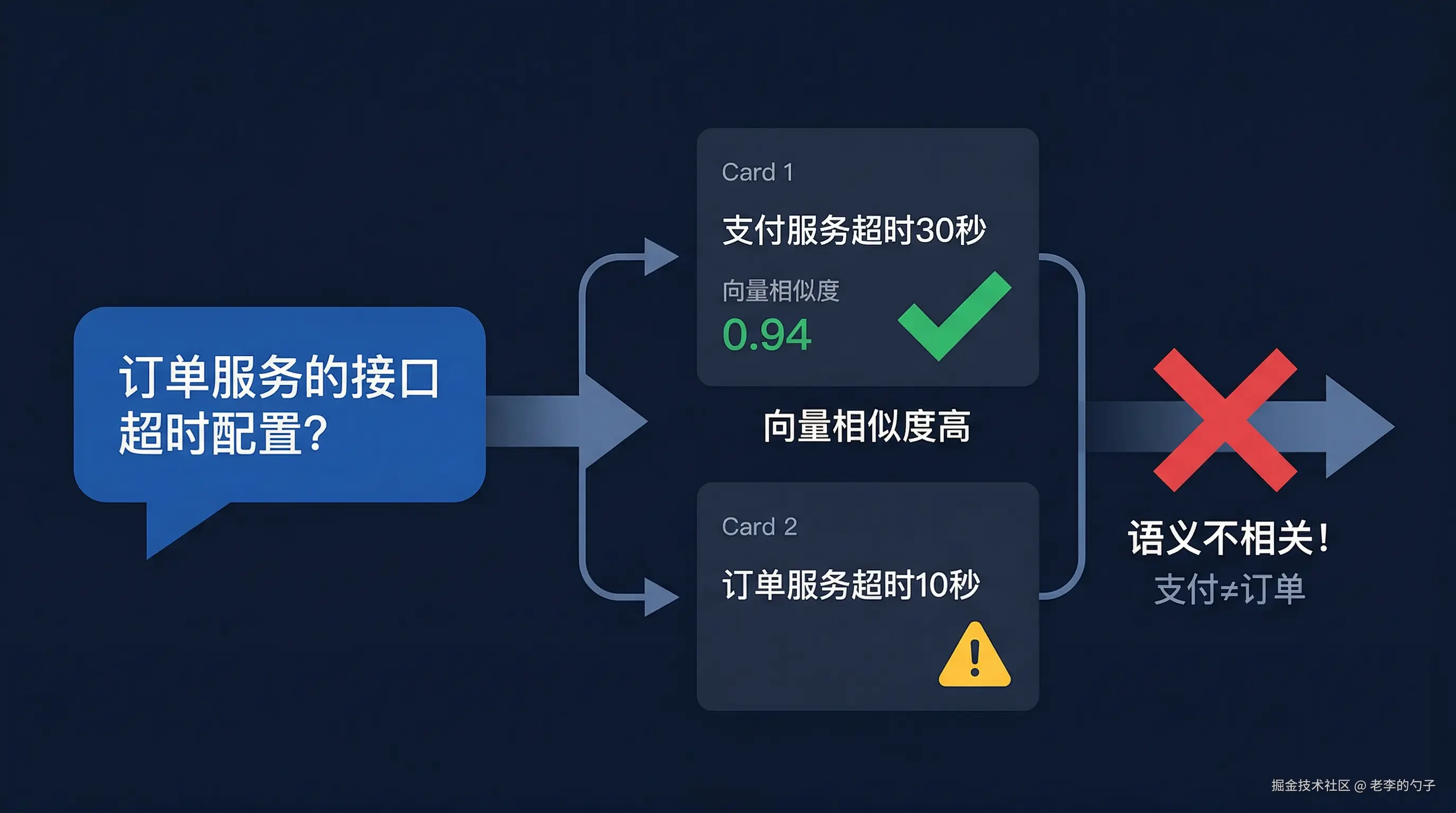
用户问了一个问题,向量检索命中了一条记忆------相似度 0.94,看起来高度相关。Agent 把这条记忆用进了回答,结果答错了。检查后发现,检索出来的记忆谈的是另一个项目的情况,只是恰好用了相同的关键词。
根因
向量相似度(cosine similarity)反映的是词汇层面和浅层语义的接近程度,它不等于语义相关性:
arduino
用户问题: "这个接口的超时配置是多少"
检索结果 top-1:
记忆内容: "接口超时统一配置为 30 秒,采用指数退避"
向量相似度: 0.94
问题在于:这条记忆描述的是"支付服务"的超时配置,
而用户问的是"订单服务"的超时配置。两个服务用了相同的
关键词"接口超时",向量距离很近,但语义完全不是一回事。向量检索解决的是"哪些记忆的字面意思最像这个问题",不是"哪些记忆真正能回答这个问题"。
排查方法
打印向量检索的 top-5 结果,不只看相似度分数,还要逐条核对语义相关性:
python
def diagnose_vector_retrieval(query, top_k=5):
"""诊断向量检索是否存在语义漂移"""
results = vector_index.search(query, top_k=top_k)
print(f"[向量检索诊断] 查询: {query}")
print(f"{'Rank':<6} {'相似度':<10} {'内容摘要':<40}")
print("-" * 60)
for i, result in enumerate(results, 1):
print(f"{i:<6} {result['score']:<10.4f} {result['content'][:40]:<40}")
# 语义相关性人工复核(生产环境可用轻量 LLM 替代)
print("\n[语义相关性检查]")
for result in results:
relevance = judge_semantic_relevance(query, result['content'])
status = "✅" if relevance == "high" else "⚠️" if relevance == "medium" else "❌"
print(f" {status} {result['content'][:50]}")解法
双层检索 + Rerank:向量检索负责召回,语义模型负责重排:
python
def retrieve_memory_with_rerank(query, top_k=20):
"""
第一层:向量检索,召回 top-20(宽召回)
第二层:语义模型做相关性打分
第三层:取 top-3 作为最终输入
"""
# Layer 1: 宽召回
candidates = vector_index.search(query, top_k=20)
# Layer 2: 语义重排
# 生产环境建议使用专用 Rerank 模型(如 Cohere Rerank、Jina Rerank),
# 效果优于直接调用通用 LLM 做 relevance scoring
reranked = []
for candidate in candidates:
score = llm_judge_relevance(
query=query,
memory=candidate["content"]
)
reranked.append((candidate, score))
# Layer 3: 取 top-3
reranked.sort(key=lambda x: x[1], reverse=True)
final = [r[0] for r in reranked[:3]]
return final这个方案比单纯提高向量检索的相似度阈值更可靠------阈值只能过滤明显不相关的,而 rerank 能识别"字面相近但语义偏离"的情况。
第四种失效:跨 Session 的记忆一致性冲突
现象
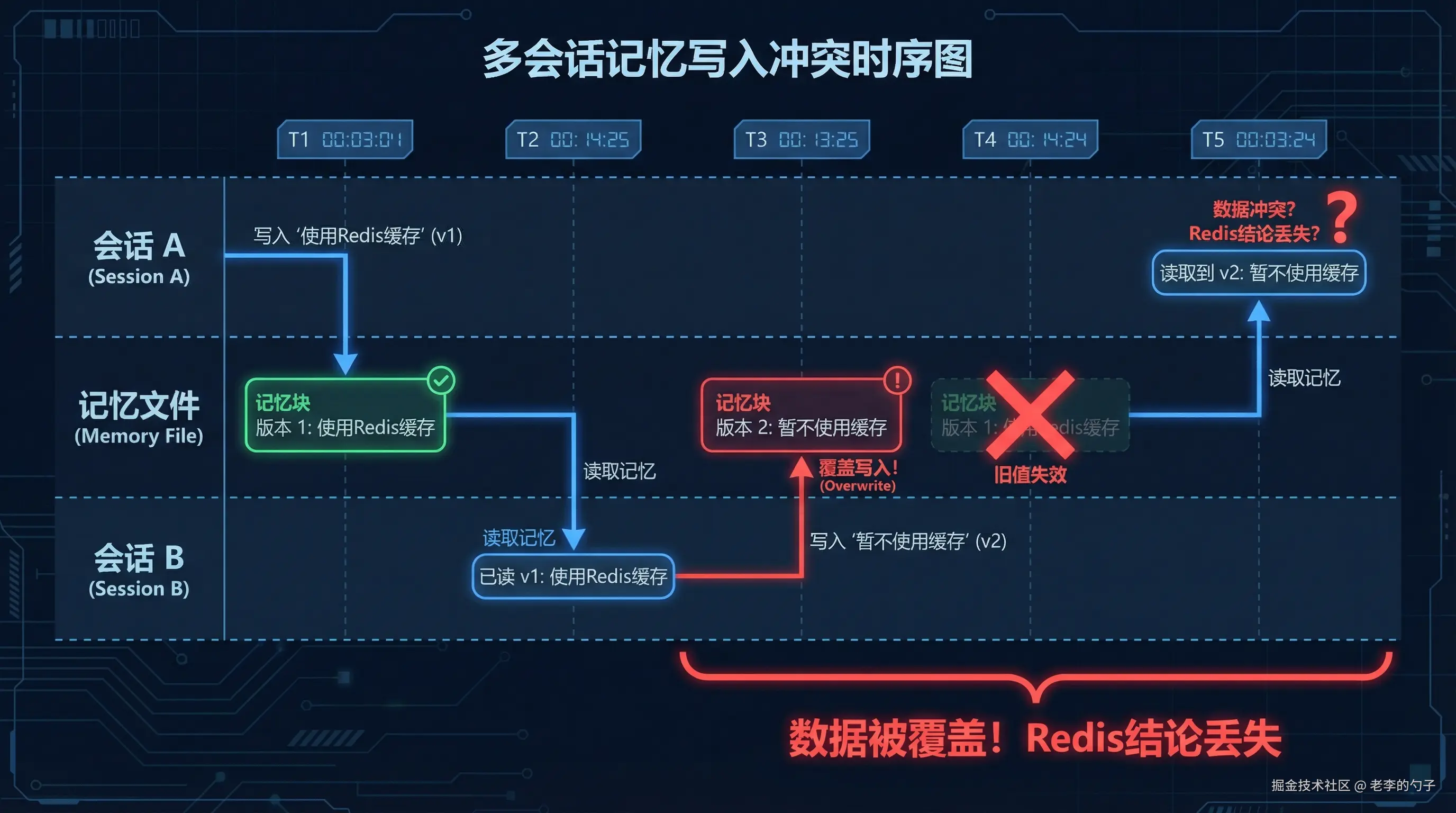
用户在不同时间打开了两个对话 session,都在与同一个 Agent 讨论同一个项目。session A 中 Agent 学到了"使用 Redis 缓存";session B 中 Agent 学到了"暂时不用缓存"。再次打开新 session 时,Agent 给出的结论在两者之间摇摆,有时说用缓存,有时说不用的。
根因
多个 session 并发向同一份长期记忆文件写入,没有冲突解决机制。常见的错误实现是"最后写入优先":
css
Session A @ T1: 写入 "项目使用 Redis 缓存" → 文件内容: "项目使用 Redis 缓存"
Session B @ T2: 读取文件,得到 "Redis 缓存"
Session B @ T3: 判定"不需要缓存",写入 "暂不使用缓存" → 文件被覆盖
Session A @ T4: 下次读取,得到 "暂不使用缓存" → Redis 的结论被抹掉了这不是"遗忘",是写入冲突导致的数据破坏。
排查方法
检查长期记忆文件的修改时间戳序列:
python
def diagnose_write_conflicts(memory_file):
"""检查长期记忆文件的写入冲突"""
with open(memory_file, "r") as f:
entries = parse_memory_entries(f)
print(f"[记忆文件写入记录] 共 {len(entries)} 条")
print(f"{'时间戳':<28} {'来源':<12} {'内容摘要':<40}")
print("-" * 85)
for entry in entries:
print(f"{entry['timestamp']:<28} {entry['source']:<12} {entry['content'][:40]:<40}")
# 检测覆盖:同一 key 是否被多次写入且后者推翻了前者
key_overwrites = find_key_overwrites(entries)
if key_overwrites:
print(f"\n⚠️ 检测到 {len(key_overwrites)} 次关键覆盖:")
for ow in key_overwrites:
print(f" [{ow['key']}] 旧值: {ow['old']} → 新值: {ow['new']}")解法
记忆版本号 + 冲突合并:
python
MEMORY_SCHEMA = {
"version": 1,
"entries": {
"cache_strategy": {
"value": "redis",
"version": 3,
"last_updated": "2026-04-01T10:23:00Z",
"sources": ["session_a", "session_b"]
}
}
}
def write_memory_with_version(key, new_value, session_id):
"""写入记忆时做版本检测和冲突合并"""
entry = get_memory_entry(key)
if entry is None:
# 首次写入,直接写入
create_entry(key, new_value, session_id)
elif entry["version"] == get_latest_version(key):
# 无并发冲突,直接写入,版本 +1
# ⚠️ 注意:这里是典型的 TOCTOU 竞态------get_memory_entry 和 get_latest_version
# 之间存在时间窗口,多 session 并发时另一方可能已写入新版本。
# 生产环境需要数据库 CAS(compare-and-swap)操作或文件锁保证原子性。
entry["value"] = new_value
entry["version"] += 1
entry["last_updated"] = now()
entry["sources"].append(session_id)
else:
# 检测到并发写入,需要合并
print(f"[冲突检测] key={key}, 两个 session 同时写入了不同值")
resolved = resolve_conflict(
current=entry["value"],
incoming=new_value,
context=get_conflict_context(key)
)
entry["value"] = resolved
entry["version"] += 1核心原则:后写入不直接覆盖,而是触发合并流程,由 LLM 判断"哪个结论更准确"。
第五种失效:记忆评分机制的边界误判
现象
某条被用户多次确认、在历史上表现稳定的记忆,在某次对话中被 Agent 完全忽略了------不是因为检索失败,而是 Agent 主动选择不采纳这条记忆。更奇怪的是,这段记忆在检索结果中排在前列,Agent 也"看到"了它,但就是没用。
根因
当 Agent 从长期记忆向工作记忆注入信息时,会经历一个**记忆评分(relevance scoring)**过程------判断"这条记忆和当前问题有多相关、是否值得用"。这个评分不是简单的向量相似度,而是综合考虑了:
markdown
评分维度:
- 记忆内容与当前上下文的语义匹配度
- 记忆的产生时间(越老越容易被降权)
- 记忆被成功使用的历史次数(用得越多越可信)
- 当前对话中是否存在与该记忆矛盾的新信息
- 记忆来源的权威性(用户明确说过 > LLM 自行推断)问题在于:当上述维度在边界情况下出现冲突时,评分机制会倾向于"保守"------宁可不用,不要用错。
一个典型场景:
makefile
记忆内容: "数据库连接池大小固定为 20,不要动"
记忆评分: 0.72
当前上下文:
- 用户正在讨论"运维想要调大连接池"
- 运维人员被认为是当前对话中的权威信息源
评分重新计算:
- 新信息的权威信号 > 历史记忆的权威信号
- 最终评分: 0.31(低于采纳阈值 0.5)
→ 决策: 不采纳该记忆,按当前上下文回答这不是"遗忘",是评分机制在保守策略下主动降权。但问题是:这条"连接池不改动"的记忆本应是用户明确给出的高权威记忆,不应该被轻易覆盖。
排查方法
查看 Agent 每次使用记忆前的评分决策过程:
python
def diagnose_memory_relevance_scoring(query, memory_entries):
"""诊断记忆评分机制是否存在过度保守的问题"""
for memory in memory_entries:
# 模拟 Agent 的评分过程
dimensions = {
"semantic_match": compute_semantic_match(query, memory["content"]),
"recency_score": compute_recency_decay(memory["last_used"]),
"historical_accuracy": memory["success_count"] / max(memory["total_use"], 1),
"authority_score": get_authority_weight(memory["source"]),
"contradiction_penalty": compute_contradiction(query, memory["content"])
}
# 综合评分(权重之和 = 1.0)
raw_score = (
dimensions["semantic_match"] * 0.30 +
dimensions["recency_score"] * 0.20 +
dimensions["historical_accuracy"] * 0.20 +
dimensions["authority_score"] * 0.20 +
dimensions["contradiction_penalty"]* 0.10
)
# 将原始分数映射到 [0, 1],解决矛盾惩罚导致上限不足的问题
final_score = max(0.0, min(1.0, raw_score + 0.1))
print(f"[记忆评分] {memory['content'][:40]}")
for k, v in dimensions.items():
print(f" {k}: {v:.3f}")
print(f" → 最终评分: {final_score:.3f}")
if final_score < 0.5:
print(f" ⚠️ 低于采纳阈值,可能被跳过")解法
分层采纳策略 + 信任等级:用 trust multiplier 代替 threshold,消除逻辑混淆:
python
# 信任等级:越高越难被推翻
TRUST_LEVEL = {
"user_explicit": 1.0, # 用户亲口说的,完全信任
"documented": 0.8, # 从文档/代码提取的,高信任
"llm_inferred": 0.5, # LLM 自行推断的,标准信任
"heuristic": 0.2, # 启发式猜测的,低信任
}
def compute_trust_adjusted_score(memory, current_context):
"""
计算记忆的信任调整后评分
信任等级越高的记忆,对矛盾惩罚的抗干扰能力越强
"""
base_score = compute_memory_score(memory, current_context)
trust = TRUST_LEVEL.get(memory["source"], 0.5)
# 信任加成:user_explicit 的记忆(trust=1.0),矛盾惩罚项 = 0,完全免疫
# heuristic 的记忆(trust=0.2),矛盾惩罚被放大 0.8 倍,更容易被推翻
# 信任中等的记忆(trust=0.5),矛盾惩罚不起不加成也不削弱
contradiction = compute_contradiction(current_context, memory["content"])
adjusted = base_score + (trust - 0.5) * 0.4 - contradiction * (1 - trust) * 0.3
return max(0, min(1, adjusted)) # 限制在 [0, 1] 范围内
def should_adopt_memory(memory, current_context):
"""判断一条记忆是否应该被采纳"""
score = compute_trust_adjusted_score(memory, current_context)
# 受保护的记忆直接采纳
if memory.get("protected"):
return True, "protected memory, bypass scoring"
return score >= 0.5, f"adjusted_score={score:.3f}"高权威记忆的保护标记:
python
def protect_high_value_memory(memory_id, reason):
"""保护高价值记忆不被评分机制误伤"""
entry = get_memory_entry(memory_id)
entry["protected"] = True
entry["protection_reason"] = reason
entry["source"] = "user_explicit" # 强制提升信任等级快速诊断流程图
当 Agent 出现"失忆"症状时,先用这个流程快速定位是哪种失效:
markdown
Agent 失忆了?
├─ 单次对话内答非所问?
│ └─ 检查上下文窗口(Token 比例是否失衡)
├─ 摘要保存了但细节丢了?
│ └─ 检查情景记忆(摘要时机是否在关键信息前)
├─ 检索命中了但答错了?
│ └─ 检查向量检索(是否存在语义漂移)
├─ 多 Session 后记忆被覆盖?
│ └─ 检查跨 Session 写入(是否有并发冲突)
└─ 检索到了但 Agent 主动跳过?
└─ 检查记忆评分(分值是否被矛盾惩罚拉低)总结:记忆失效全链路自查清单
当 Agent 出现"失忆"症状时,按以下顺序排查:
| 顺序 | 失效类型 | 典型症状 | 必查日志 | 解决方向 |
|---|---|---|---|---|
| 1 | 工作记忆 | 单次对话中段开始答非所问 | Token 分布比例 | 上下文压缩 |
| 2 | 情景记忆 | 摘要保存了但关键细节丢了 | 最后一次摘要 vs 最后用户发言 | 触发式摘要 |
| 3 | 长期记忆 | 检索命中了但答错了 | 向量 top-5 结果语义核对 | 双层检索 + Rerank |
| 4 | 跨 Session | 多 session 后记忆被覆盖 | 记忆文件写入时间戳 | 版本号 + 冲突合并 |
| 5 | 记忆评分 | 检索到了但 Agent 主动跳过 | 记忆采纳决策日志 | 分层阈值 + 保护标记 |
一句话结论
Agent 的记忆不是"存了就能用"的黑箱。每个环节都有独立的失效路径------上下文窗口污染、摘要时机错误、语义漂移、写入冲突、评分误判。理解这 5 种失效模式,才能真正设计出可靠的记忆系统。
