随着 DALL·E、Imagen、Midjourney 和 Stable Diffusion 等文生图(text-to-image, T2I)生成模型的发展,一个全新的逼真图像创作时代已经开启。这些模型能够根据文本输入生成高度细致、上下文准确的图像与艺术作品,使艺术家、设计师,乃至原本并不擅长创作的人,都能以前所未有的轻松方式把自己的想法变成现实。
这些模型的核心构件是扩散(diffusion)。在物理学中,扩散描述的是分子如何从高浓度区域移动到低浓度区域。而在图像生成的语境里,扩散模型借用了这一思想:通过一系列迭代式精修,逐步把随机噪声变成连贯、细致的图像。
这种基于扩散的方法,已经成为当前 SOTA 模型的主干,取代了此前在图像生成领域占主导地位的方法,例如生成对抗网络(GAN)。之所以发生这种转变,是因为扩散模型已经被证明在生成高质量且多样化输出方面更有效。值得注意的是,虽然最初的 DALL·E 是自回归模型,但 DALL·E 2 和 DALL·E 3 后来都转向了基于扩散的方法。
考虑到当前学术界对扩散模型的研究热度,本章将重点讨论用于图像生成任务的扩散模型,例如首个 diffusion transformer(DiT)、PIXART-α、PixArt-Σ 和 DiffiT。此外,我也会重点关注开源模型,以及如何高效地用它们生成图像,或用你自己的图像数据对这些模型进行微调。
生成式图像模型简介
去噪扩散概率模型(DDPM)和基于 score 的生成模型,已经在图像生成领域取得了尤其显著的成功,而卷积 U-Net 一直是这些方法事实上的默认骨干架构。不过,这并不是生成式图像建模中唯一使用的方法。除此之外,还有两类重要路线:GAN 和自回归模型,它们各自都有独特的优势与挑战。下面这一节会概括这些生成建模技术之间的主要特征与差异。
GAN 运行在一个博弈论框架之中,其中有两个神经网络协同作用:生成器(generator)和判别器(discriminator)。生成器负责生成图像,而判别器则尝试区分哪些图像是真实的,哪些是生成的。随着训练推进,生成器会不断改进输出,直到判别器再也无法区分真假。不过,GAN 非常难训练,因为它容易遇到 mode collapse 等问题,也就是生成器只能输出非常有限的一小类结果,缺乏多样性。
自回归模型,比如最初的 DALL·E,会以顺序方式生成图像:基于前面已经生成的像素,逐步预测后续的每个像素,或每个像素 patch。这类模型通常建立在 Transformer 架构之上,在建模数据依赖关系方面非常强大。但它们的计算成本也很高,尤其是在生成高分辨率图像时,因为要完成整张图像,模型需要做海量预测。除此之外,这种逐像素的方式速度较慢,而且在处理复杂图像时,往往不太擅长捕捉全局结构或整体一致性。
扩散模型则代表了一种较新的方法:它们通过一个迭代去噪过程来合成图像。模型从随机噪声开始,通过反向执行扩散过程,逐步把噪声精炼为一张连贯的图像。与 GAN 和自回归模型相比,扩散模型具有多个优势。首先,它们训练更稳定,因为不依赖对抗训练;其次,它们对潜在空间的覆盖更完整;此外,扩散模型更容易做反演,因此在图像编辑这类任务中也更加灵活。
扩散模型:这些噪声到底是什么?
扩散模型会在正向过程中加入噪声,通常是高斯噪声,然后训练模型去反转这些扰动,本质上也就是学习如何恢复原始数据。更具体地说,扩散概率模型是一个通过变分推断训练得到的参数化马尔可夫链,它在有限步数之后生成的样本,会尽可能贴近真实数据。模型学习的是这条链中的转移过程,而这个转移过程正好反转了一个扩散过程:在扩散过程中,噪声会沿着与采样相反的方向,逐渐被加入到数据中,直到原始信号(图像)被完全淹没。下面这个方程展示了噪声是如何逐步加到原始数据上的:
x0:q(xt∣x0)=N(xt;αˉt x0,(1−αˉt)I)
这里, x0 是未被污染的原始数据点, xt 是时间步 t 上的数据,也就是 x0 的一个更嘈杂的版本。 αˉt 是一个超参数,用来控制每一步加入多少噪声。而 N 表示高斯分布,也就是说 xt 会围绕某个均值,以指定方差服从正态分布。
这个过程被设计成:随着 t 增加,加入的数据噪声越来越多,直到数据被完全破坏。也就是说,当 (t=T) 时, xT 几乎就是纯噪声。模型的目标,则是学习这个过程的反向版本:从纯噪声出发,逐步对数据去噪,恢复出一个与原始数据分布相似的样本。图 4-1 展示了这一过程。

图 4-1. 扩散模型中反向过程的马尔可夫链。图片改编自 Jonathan Ho 等人(2020)。
为了实现这一点,反向过程模型会基于原始数据 x0 的对数似然的变分下界进行训练。重参数化技巧允许我们在每个时间步 t 上高效采样,其形式如下:
xt=αˉt x0+1−αˉt ϵt
这里, ϵt 从标准正态分布 N(0,I) 中采样。
重参数化技巧的好处
重参数化技巧的一个关键优势,是它让你可以避免使用 Monte Carlo 方法去计算关于模型参数 θ 的期望梯度。Monte Carlo 估计会把随机噪声引入梯度估计中,这往往效率较低,而且会让梯度方差很高。重参数化技巧通过重新表达这个期望,把随机性隔离到一个与模型参数 θ 无关的变量中。这样一来,你就可以直接对 θ 使用标准反向传播来计算梯度,而不需要依赖 Monte Carlo 式的随机梯度估计。Diederik Kingma 和 Max Welling 在 2013 年的论文《Auto-Encoding Variational Bayes》中提出了这一技巧。
在这个过程中,有一个关键组成部分是 Kullback-Leibler(KL)散度。KL 散度用来衡量一个概率分布与另一个期望概率分布之间的偏离程度。在这里,它表示模型中数据真实转移过程,与模型在反向过程中预测出来的转移过程之间的差异。本质上,KL 散度提供了一种数学手段,让我们能够评估模型的预测是否和数据在扩散过程不同阶段中真实发生的变化保持一致。通过最小化这些散度,模型就能更准确地反转噪声,并生成高质量样本。
由于正向过程 ( q(xt∣xt−1)) 和反向过程 pθ(xt−1∣xt) 都是高斯分布,因此 KL 散度可以直接用闭式表达式解析计算,而不需要借助高方差的 Monte Carlo 估计,这大大提升了训练效率与稳定性。两个高斯分布之间 KL 散度的闭式形式如下:
DKL(N(μ1,σ12)∥N(μ2,σ22))=21(σ22σ12+σ22(μ2−μ1)2−1+2logσ1σ2)
这个看起来相当复杂的数学公式,其实非常容易高效地翻译成简单代码,如示例 4-1 所示。
示例 4-1. 使用闭式公式计算 KL 散度
scss
kl_divergence = 0.5 * (
(th.exp(logvar1 - logvar2)) 1
+ ((mean1 - mean2) ** 2) * th.exp(-logvar2) 2
- 1.0 3
+ logvar2 4
- logvar1 5
)- 这一项对应公式中的 σ12/σ22
- 这一项对应公式中的 (μ2−μ1)2/σ22
- 这就是公式里的 −1
- 对应 2⋅log(σ2/σ1) 的前半部分
- 对应 2⋅log(σ2/σ1) 的后半部分
这种"先逐步加噪,再逐步反转噪声"的框架,使扩散模型能够捕捉复杂数据分布,并且与 GAN 等其他生成模型相比,在训练稳定性和生成伪影控制方面都更好,从而生成高质量样本。
扩散模型中的 Classifier-Free Guidance
在条件扩散模型中,额外信息,例如类别标签 c,会被用来引导生成过程。这意味着在反向过程中,模型不仅要根据时间步 t 上的噪声数据来生成样本 xt−1,还要在类别标签 c 的条件下完成这一生成。数学上可以表示为:
pθ(xt−1∣xt,c)
不过,classifier-free guidance 并不是单纯地严格遵循这个条件,而是引入了一种机制,让采样过程更强地朝着生成"高度属于某一特定类别"的样本方向偏移。实现方式是:在反向过程里,在条件模型和非条件模型的输出之间做平衡。
这个方法的核心思想,是计算一个由条件预测和无条件预测加权组合而成的结果。如果把条件模型的 score(或梯度)记为 s(xt;c),无条件模型记为 s(xt;∅),那么 classifier-free guidance 会把采样步骤修改为:
s^(xt;c)=s(xt;∅)+α⋅(s(xt;c)−s(xt;∅))
这里, α 是 guidance scale,当 α>1 时,模型会更加偏向条件模型的输出。当 α=1 时,就退化回标准采样。
为了让模型能够支持 classifier-free guidance,训练时会随机丢弃类别标签 c,并用一个可学习的"空"嵌入 ∅ 替换它。这样一来,模型就学会了既能在显式条件下生成样本,也能在没有条件的情况下生成样本,从而在采样阶段具备灵活的 guidance 能力。
Classifier-free guidance 能够提升生成样本的质量,也能让模型生成的图像在类别上更加一致、更符合条件,相比不使用这种技术的模型效果更好。
用 Transformer 扩展扩散模型
Diffusion Transformers(DiTs)成功地用 Transformer 替代了 U-Net 骨干。DiT 论文合著者、纽约大学 Courant 计算机科学助理教授 Saining Xie 在 2024 年 2 月接受 TechCrunch 采访时说过一句话:"Transformer 给扩散过程带来的作用,差不多就像是给发动机升级了一样。"
DiT 的训练流程起始于输入图像,例如一张尺寸为 (256\times256\times3) 的图像。图像首先会通过一个带 KL loss 的预训练变分自编码器(VAE),VAE 编码器会把它下采样 8 倍,得到一个大小为 32×32×4 的潜在表示 z,也就是 I×I×C,对应图像尺寸 × 图像尺寸 × 通道数。注意,这里的通道是潜在空间中的通道,噪声正是在这个空间中被加入进去的,因此这些通道编码的是同时包含内容和噪声信息的特征。
当图像经过 VAE 被编码到潜在空间 z 之后,它会被切分成更小的 p×p patch,然后 patchify 成一个 token 序列,token 数量 T 的计算方式为:
T=(I/p)2
这一过程如图 4-2 所示。
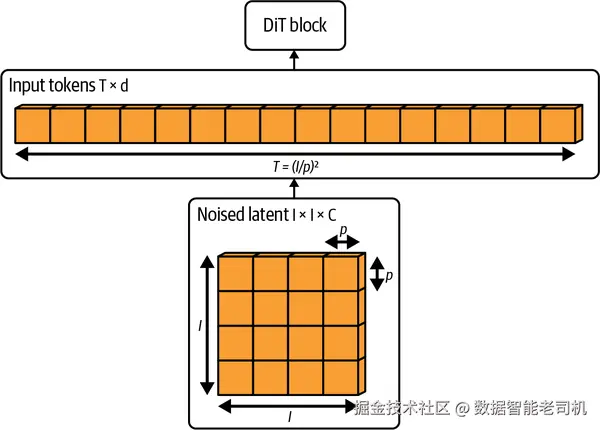
图 4-2. 在 DiT 的 patchify 过程中,空间输入被转换成 T 个 token。图片改编自 William Peebles 和 Saining Xie(2023)。
这些 patch 现在已经变成 token 了,接下来会在 token 序列上加上位置嵌入,然后送入 DiT 的 Transformer 骨干。这个 Transformer block 由多层注意力层和前馈网络组成,用于学习 token 表示。DiT 建立在你在第 3 章学过的 ViT 架构之上。它保留了 ViT 中很多最佳实践,但也对标准 ViT 做了一些小修改。这些修改主要是为了引入额外的条件输入,例如噪声时间步和类别标签:
In-context conditioning
In-context conditioning 会把条件输入作为额外 token 拼接进序列中,因此只需要对 Transformer 结构做极少改动。Transformer 可以高效处理这些额外 token,而且几乎不会带来额外开销。
Cross-attention blocks
这种方式会增加一个独立的多头 cross-attention 层来处理条件输入,会让模型的计算复杂度增加大约 15%,但也让它在处理多样化数据类型时更加灵活。
Adaptive Layer Normalization(adaLN)blocks
adaLN 层借鉴了 GAN 和基于 U-Net 骨干的扩散模型中的一些技术,它会根据条件输入动态调整归一化参数。
adaLN-Zero blocks
这是 adaLN 的一个变体,它会在训练一开始把 block 初始化成一个恒等映射,这种做法借鉴自 ResNet。它能通过稳定早期学习动态来加速训练,而且几乎不增加额外计算开销。
整个架构如图 4-3 所示。
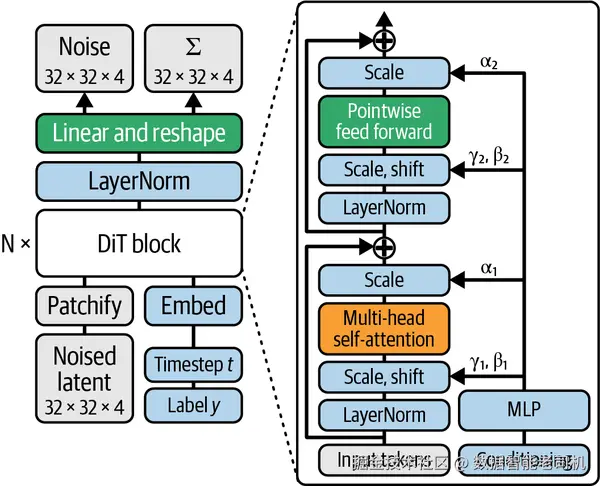
图 4-3. 左边是 latent diffusion transformer 的整体架构,右边是其 Transformer block。图片改编自 William Peebles 和 Saining Xie(2023)。
原始论文代码中的 DiT block(使用 adaLN-Zero conditioning)的实现见示例 4-2。
示例 4-2. DiT Block
ini
class DiTBlock(nn.Module):
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads,
qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size,
elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size,
hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp =
self.adaLN_modulation(c).chunk(6, dim=1)
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x),
shift_msa, scale_msa))
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x),
shift_mlp, scale_mlp))
return x这个 DiTBlock 包含两个主要组件:多头 self-attention 和一个 MLP。它们都会受到 adaLN-Zero 的调制,也就是根据条件向量 (c) 来调整归一化参数(shift 和 scale)。
Block 的第一部分是 self-attention 机制(self.attn)。在执行 attention 之前,输入张量 (x) 会先经过 LayerNorm(但没有学习到的仿射参数),然后再利用从条件向量中得到的 shift_msa 和 scale_msa 对归一化结果做调制。
Block 的第二部分是一个 MLP,它同样作用于归一化后的输入。和 attention 一样,MLP 的输入在送入 MLP 之前,也会先通过 shift_mlp 和 scale_mlp 做调制。
这段代码会作为 DiT 模型 forward pass 的一部分,被嵌入到整个 Transformer 架构中。每个 DiTBlock 都会接收输入张量 (x) 和条件向量 (c),而 (c) 本身是时间步嵌入和类别标签嵌入的组合。此外,DiT 模型内部还会使用 classifier-free guidance,在不需要显式类别标签的情况下,将生成过程引导向更理想的输出,从而提升生成质量。
DiT 提供了多个配置版本,包括 DiT-S、DiT-B、DiT-L 和 DiT-XL,因此可以根据不同应用需求灵活选择。下一节中,你将使用 DiT-XL 来生成一些图像。
使用 DiT 生成图像
DiT 模型是在 ImageNet 数据集上,按 256×256 和 512×512 两种图像分辨率训练的。因此,你可以从这些图像类别中任选一个类别来生成图像。为了简化操作,我写了一个 Python 函数,把类别名称映射成对应的数值类标。这里我省略具体代码,不过你可以在本章配套 notebook 中找到它。首先,先按示例 4-3 设置模型所需变量。
示例 4-3. 配置模型变量
ini
IMAGE_SIZE = 512
VAE_MODEL = "stabilityai/sd-vae-ft-ema" 1
LATENT_SIZE = IMAGE_SIZE // 8
SEED = 42
NUM_SAMPLING_STEPS = 200
CFG_SCALE = 4.0
CLASS_LABELS = get_label_ids()
SAMPLES_PER_ROW = 4
OUTPUT_IMAGE = "sample.png"
MODEL_NAME = f"DiT-XL-2-{IMAGE_SIZE}x{IMAGE_SIZE}.pt"- 可选项有
stabilityai/sd-vae-ft-mse或stabilityai/sd-vae-ft-ema
接下来,加载 VAE 模型和 DiT checkpoint,如示例 4-4 所示。
示例 4-4. 加载 DiT 与 VAE
scss
def load_models(device, MODEL_NAME):
model = DiT_XL_2(input_size=LATENT_SIZE).to(device)
state_dict = download_model(MODEL_NAME)
model.load_state_dict(state_dict)
model.eval()
vae = AutoencoderKL.from_pretrained(VAE_MODEL).to(device)
return model, vae然后,你需要创建 diffusion 对象、采样噪声,以及 classifier-free guidance 所需的设置,以便生成样本图像,如示例 4-5 所示。
示例 4-5. 生成图像样本
ini
def generate_samples(model, vae, device):
torch.manual_seed(SEED)
diffusion = create_diffusion(str(NUM_SAMPLING_STEPS)) 1
n = len(CLASS_LABELS) 2
z = torch.randn(n, 4, LATENT_SIZE, LATENT_SIZE, device=device)
y = torch.tensor(CLASS_LABELS, device=device)
z = torch.cat([z, z], 0) 3
y_null = torch.tensor([1000] * n, device=device)
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=CFG_SCALE) 4
samples = diffusion.p_sample_loop(
model.forward_with_cfg, z.shape, z, clip_denoised=False,
model_kwargs=model_kwargs, progress=True, device=device
)
samples, _ = samples.chunk(2, dim=0) 5
samples = vae.decode(samples / 0.18215).sample
return samples- 创建 diffusion 对象
- 创建采样噪声
- 设置 classifier-free guidance
- 设置 classifier-free guidance scale
- 移除 null class 样本
现在你就可以调用这些函数来加载模型并生成样本了,如示例 4-6 所示。
示例 4-6. 初始化模型与函数
scss
model, vae = load_models(device, MODEL_NAME)
samples = generate_samples(model, vae, device)
save_and_display_samples(samples)save_and_display_samples 函数会保存并展示图像,效果如图 4-4 所示。

图 4-4. DiT 生成的图像。
虽然 DiT 是图像生成模型中的一个重要进展,但它也确实存在一些局限。不过,我们仍然要看到,DiT 为之后更先进的模型打下了基础,而你在后面几节中将会看到这些模型。那些更新的模型已经可以不局限于单一类别来生成图像,从而进一步拓展了图像生成的可能性。
PIXART-α
PIXART-α 是一个基于 Transformer 的 T2I 扩散模型,它能够生成与 Imagen 这类顶级模型相媲美的高质量图像,同时显著降低训练成本和环境影响。相比其他 SOTA T2I 模型,PIXART-α 的财务成本和生态成本都更低。它支持最高 1024×1024 分辨率的图像合成,同时训练效率超过现有的大规模模型。
为了实现这一点,模型把训练过程拆成了三个不同阶段,每个阶段都针对图像合成中的不同方面做优化。
第一阶段是像素依赖学习(pixel dependency learning),它借助一个在 ImageNet 上预训练好的类条件模型,以此提升初始训练效率。
第二阶段专注于文本---图像对齐(text-image alignment),它会在基础 DiT 架构的 self-attention 层和前馈层之间插入一个 cross-attention 层,使模型能够灵活地与文本 embedding 交互(见图 4-5)。
最后一个阶段则使用高分辨率、审美质量更强的数据对模型进行微调。由于前面阶段已经建立起较强先验,这一适配过程会更快收敛。
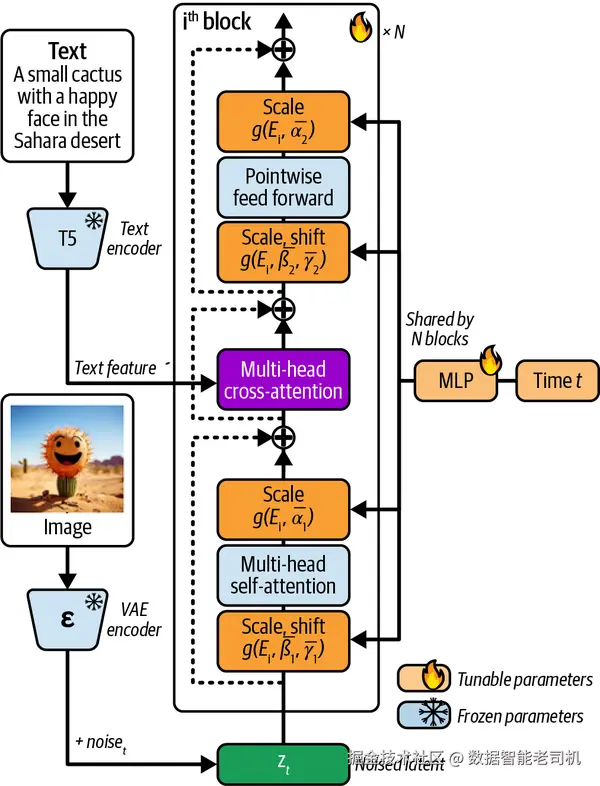
图 4-5. PIXART-α 的架构在每个 block 中都加入了 cross-attention 模块,以无缝整合文本条件。图片改编自 Junsong Chen 等人(2023)。
PIXART-α 以 DiT 为基础架构,但做了如下设计改动:
PIXART-α 中的 Cross-attention
Cross-attention 层被放置在 self-attention 和前馈层之间,使模型能够有效整合文本条件。这个层让模型能够把文本条件注入图像生成过程,因此可以在处理多样化文本---图像配对时,保持很高的语义准确性。为了效率,输出投影层会被初始化为 0,这样在训练早期它会维持输入恒等映射。
AdaLN-single
PIXART-α 引入了 adaLN-single 模块,以减少相较于 DiT 中标准 adaLN 模块的计算复杂度和参数量。在 DiT 中,自适应归一化层会同时利用类别条件和时间嵌入来计算 scale 和 shift,因此参数量很大;而 adaLN-single 不再使用类别条件。它只用时间嵌入,在第一个 block 中计算一组全局的 shift 与 scale 参数,并把这组参数共享给所有 Transformer block。之后,每个 block 再通过自己特定的可训练 embedding 去调整这些全局参数,从而在效率和训练一致性之间取得平衡。
重参数化
为了更好地复用预训练权重,adaLN-single 中每一层的可训练 embedding 会被初始化成一种特殊方式:当没有类别条件时(论文中使用的是 (t=500)),它能复现原始 DiT 模型的 scale 和 shift 参数,并且只关注所选时间嵌入。这种设计把原来 block-specific 的 MLP 替换成一个全局 MLP 加每层特定 embedding,从而让 PIXART-α 的架构更加精简。
此外,PIXART-α 还通过使用视觉---语言模型 LLaVA,对图文对进行自动标注,以解决现有数据集概念密度和质量不足的问题。通过把 LLaVA 应用到 SAM 数据集(其中包含丰富、多样的对象图像),PIXART-α 能够获得高度的图文对齐性,从而减少为了达到稳定模型表现所需的大量训练迭代。此外,在最终微调阶段,模型还引入了 JourneyDB 和一个内部数据集,进一步提升其生成高审美、高分辨率图像的能力。
PixArt-Σ
PIXART-α 是更强版本 PixArt-Σ 的基础。这个升级过程被称为 weak-to-strong training,也就是通过高效训练方法,把一个相对较弱的基线模型提升为更强模型。
这一增强流程的第一步,是收集一个新的高质量数据集。这个数据集主要关注两个方面:图像本身的质量,以及 caption 的准确性。整个数据集包含 3300 万张高分辨率图像,全部都超过 1K 分辨率,其中还有 230 万张大约 4K 分辨率的图像。这些图像之所以被选中,是因为它们具有较高的审美价值,并且艺术风格多样。
与此同时,为了进一步提升图文对齐,PIXART-α 中使用的 LLaVA 图像 captioner,被更强大的 Share-Captioner 所取代。后者能够生成更细致、更准确的 caption,从而减少 hallucination 的发生。此外,caption 的平均长度也提高到了 180 个词,这让文本描述能力更强,也进一步改善了图文对齐效果。
由于超高分辨率图像生成会带来更多 token,因此也会带来更高的计算挑战。为了缓解这一问题,模型在 DiT 框架中加入了一个支持 key/value token compression 的 self-attention 模块。图 4-6 展示了这个过程。这个设计在保持模型性能的同时,把高分辨率图像生成的训练与推理时间降低了大约 34%。为了支持从低分辨率扩展到高分辨率,VAE 也升级成了更强版本,从原来不带 KV token compression 的模型,演进为带有这项能力的模型。
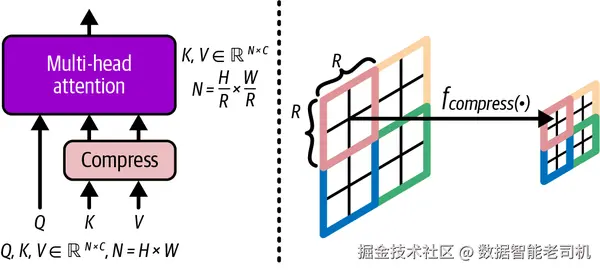
图 4-6. Key-value token compression 架构。图片改编自 Junsong Chen 等人(2024)。
示例 4-7 展示了 PixArt-Σ 中一个简化版的 AttentionKVCompress 类。函数 downsample_2d 演示了如何通过对输入张量进行 reshape 与 permute,来降低张量维度。
示例 4-7. Key-value 压缩代码示例
python
class AttentionKVCompress(nn.Module):
def __init__(self, dim, sr_ratio):
super(ExampleModel, self).__init__()
self.sr = nn.Conv2d(dim, dim, groups=dim,
kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def downsample_2d(self, tensor, H, W, scale_factor, sampling=None):
if sampling is None or scale_factor == 1:
return tensor, tensor.shape[1]
B, N, C = tensor.shape
print(f"Original Tensor Shape: {tensor.shape}")
if sampling == 'uniform_every':
tensor = tensor[:, ::scale_factor]
print(f"Shape after 'uniform_every': {tensor.shape}")
return tensor, int(N // scale_factor)
tensor = tensor.reshape(B, H, W, C).permute(0, 3, 1, 2)
print(f"Shape after Reshape and Permute: {tensor.shape}")
new_H, new_W = int(H / scale_factor), int(W / scale_factor)
new_N = new_H * new_W
if sampling == 'ave':
tensor = F.interpolate(
tensor, scale_factor=1 / scale_factor, mode='nearest'
).permute(0, 2, 3, 1)
elif sampling == 'uniform':
tensor = tensor[:, :, ::scale_factor, ::scale_factor].permute(0, 2, 3, 1)
print(f"Shape after 'uniform' downsampling: {tensor.shape}")
elif sampling == 'conv':
tensor = self.sr(tensor).reshape(B, C, -1).permute(0, 2, 1)
tensor = self.norm(tensor)
print(f"Shape after 'conv' downsampling: {tensor.shape}")
else:
raise ValueError
tensor = tensor.reshape(B, new_N, C).contiguous()
print(f"Final Shape after Reshape: {tensor.shape}")
return tensor, new_N根据指定的采样方式,也就是 'conv'、'ave'、'uniform' 或 'uniform_every',这个函数会降低张量的空间维度,从而实现 token 压缩。张量初始形状为 ((B, N, C)),其中 (B) 是 batch size,(N) 是 token 数量,可以视作空间位置数,(C) 是通道维度。不同压缩方式的工作原理如下:
conv
通过卷积层(self.sr)进行下采样,之后再做归一化。
ave
使用平均池化(这里通过 F.interpolate)对张量下采样。
uniform
每隔 (n) 个元素取一个元素,以降低空间分辨率。
uniform_every
按照 scale_factor 规定的间隔,从展平后的 token 序列中直接均匀抽样,因此是模型中一种很直接的 token 压缩方式。
为了直观看到这种压缩如何影响 attention 中张量的形状,你可以像示例 4-8 那样,创建一个示例输入张量,并把它送入这个类。
示例 4-8. 对示例张量应用压缩
scss
B, H, W, C = 1, 4, 4, 1 1
input_tensor = torch.arange(1, 17).view(B, H * W, C).float() 2
compressed_KV = AttentionKVCompress(dim=C, sr_ratio=2)
print("=== Uniform Every Downsampling ===")
output_tensor, new_N = model.downsample_2d(input_tensor, H, W,
scale_factor=2, sampling='uniform_every')
print(f"New number of tokens: {new_N}\n")
print("=== Average Pooling Downsampling ===")
output_tensor, new_N = model.downsample_2d(input_tensor, H, W,
scale_factor=2, sampling='ave')
print(f"New number of tokens: {new_N}\n")
print("=== Uniform Downsampling ===")
output_tensor, new_N = model.downsample_2d(input_tensor, H, W,
scale_factor=2, sampling='uniform')
print(f"New number of tokens: {new_N}\n")
print("=== Convolution Downsampling ===")
output_tensor, new_N = model.downsample_2d(input_tensor, H, W,
scale_factor=2, sampling='conv')
print(f"New number of tokens: {new_N}\n")- Batch size、高度、宽度、通道数
- 创建一个形状为 1,16,1 的张量
对于上面的代码,它会输出如下新的张量形状:
ini
=== Uniform Every Downsampling ===
Original Tensor Shape: torch.Size([1, 16, 1])
Shape after 'uniform_every': torch.Size([1, 8, 1])
New number of tokens: 8
=== Average Pooling Downsampling ===
Original Tensor Shape: torch.Size([1, 16, 1])
Shape after Reshape and Permute: torch.Size([1, 1, 4, 4])
Final Shape after Reshape: torch.Size([1, 4, 1])
New number of tokens: 4
=== Uniform Downsampling ===
Original Tensor Shape: torch.Size([1, 16, 1])
Shape after Reshape and Permute: torch.Size([1, 1, 4, 4])
Shape after 'uniform' downsampling: torch.Size([1, 2, 2, 1])
Final Shape after Reshape: torch.Size([1, 4, 1])
New number of tokens: 4
=== Convolution Downsampling ===
Original Tensor Shape: torch.Size([1, 16, 1])
Shape after Reshape and Permute: torch.Size([1, 1, 4, 4])
Shape after 'conv' downsampling: torch.Size([1, 4, 1])
Final Shape after Reshape: torch.Size([1, 4, 1])
New number of tokens: 4示例 4-9 展示了这种压缩是如何被整合进模型 forward 过程中的。
示例 4-9. 在 forward 函数中执行 KV 压缩
php
# Rest of code omitted
k, new_N = self.downsample_2d(k, H, W, self.sr_ratio, sampling=self.sampling)
v, new_N = self.downsample_2d(v, H, W, self.sr_ratio, sampling=self.sampling)正是这些优化,使得 PixArt-Σ 能够以极低的训练成本和参数规模,实现高质量的 4K 分辨率图像生成。更重要的是,如果你想在自己的图像数据上微调 PixArt-Σ,它只需要其他顶级模型一小部分 GPU 资源,因为它使用的参数显著更少,却依然能提供可比的审美质量和同等级别的图文对齐能力。
使用 PixArt-Σ 生成图像
用 PixArt-Σ 生成图像非常直接。你只需要使用 Hugging Face 的 diffusers 库,如示例 4-10 所示。
示例 4-10. 使用 Diffusers 库生成图像
ini
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS", torch_dtype=torch.float16
).to(device)
prompt = "Cute animated tabby with big eyes"
image = pipe(prompt).images[0]
image.save("./tabby.png")对我来说,这个 prompt 生成了图 4-7 所示的图像。

图 4-7. 使用 PixArt-Σ 生成的图像。
不过,如果你想一次生成多张图,或者 GPU 资源有限,那你可能会希望进一步优化它。下一节就会解释怎么做。
使用推理引擎做图像生成
在应用里高效接入图像生成的另一种方式,是使用云厂商提供的推理服务。它的好处在于,你不需要自己搭建基础设施,而且是按使用量付费------对于图像任务,这通常意味着按生成图像张数计费。价格也会随着你所使用的模型不同而变化。
此外,热门模型通常部署在所谓的 warm boot 上。简单说,warm boot 表示模型已经在运行;而 cold boot 则表示模型在一段时间没人使用后会被服务商自动关闭。这类服务商有 Replicate 和 FireworksAi 等。
更高内存效率的图像生成
随着模型规模越来越大,它们的内存需求也在持续增长。这个问题会更加突出,是因为一个 diffusion pipeline 通常包含多个组件:文本编码器、扩散骨干,以及图像解码器。如此高的内存需求,会让这些模型很难运行在消费级 GPU 上,从而拖慢落地应用和实验速度。本节你将看到,如何通过量化(quantization)来提升基于 Transformer 的 diffusion pipeline 的内存效率。
首先,启用 memory history,这会把 traceback 和事件历史写进内存快照中:
scss
torch.cuda.memory._record_memory_history()接下来,像示例 4-11 那样配置模型。
示例 4-11. 配置与模型下载
ini
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
text_encoder = T5EncoderModel.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
subfolder="text_encoder",
quantization_config=quant_config,
device_map="balanced",
)
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
text_encoder=text_encoder,
transformer=None,
device_map="balanced"
)
with torch.no_grad():
prompt = "Cute animated tabby with big eyes"
prompt_embeds, prompt_attention_mask, negative_embeds,
negative_prompt_attention_mask = pipe.encode_prompt(prompt)现在,embedding 已经算出来了。你可以直接删除 text encoder 模型和 pipeline:
css
del text_encoder
del pipe
gc.collect()
torch.cuda.empty_cache()之后,你就可以使用这些 embedding 来计算 latent,如示例 4-12 所示。
示例 4-12. 计算 latent
ini
pipe = PixArtSigmaPipeline.from_pretrained(
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
text_encoder=None,
torch_dtype=torch.float16,
).to("cuda")
quantize(pipe.transformer, weights=qint8, exclude="proj_out")
freeze(pipe.transformer)
latents = pipe(
negative_prompt=None,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
prompt_attention_mask=prompt_attention_mask,
negative_prompt_attention_mask=negative_prompt_attention_mask,
num_images_per_prompt=1,
output_type="latent",
).images然后,你又可以通过 del pipe.transformer、gc.collect() 和 torch.cuda.empty_cache() 再清理一遍显存。之后,就可以像示例 4-13 那样生成图像。
示例 4-13. 优化后的图像生成
ini
with torch.no_grad():
image = pipe.vae.decode(latents / pipe.vae.config.scaling_factor,
return_dict=False)[0]
image = pipe.image_processor.postprocess(image, output_type="pil")
image[0].save("tabby.png")最后一步,如果你想查看内存使用情况,可以运行下面这条命令:
arduino
torch.cuda.memory._dump_snapshot("PixArtSigma_quant.pickle")它会生成一个 pickle 文件,你随后可以把它上传到 PyTorch visualizer 中,以可视化你的内存使用历史。这会得到一个类似图 4-8 的图。

图 4-8. 量化版 PixArt-Σ 的内存历史,不同条纹表示不同 tensor 分配;条纹越细,说明分配的 tensor 越小。
如果再把它和未优化前模型的内存使用情况(如图 4-9)对比,你就能很清楚地看到这种优化对整个推理过程中的内存分配带来的影响。
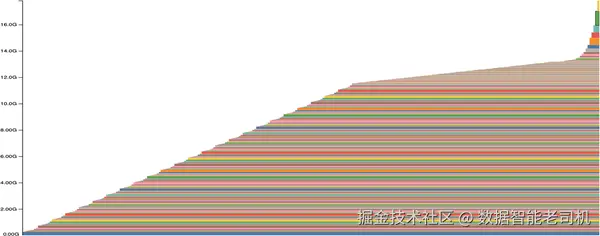
图 4-9. 未量化 PixArt-Σ 的内存历史。同样,不同条纹表示不同 tensor 分配;条纹越细,说明分配的 tensor 越小。
这两张图清楚说明,量化能把内存使用量减少一半以上。为了进一步理解应用的内存消耗,你也可以运行 torch.cuda.memory_summary() 来查看内存使用摘要。
训练 Diffusion Transformer
微调 diffusion transformer 并不是一件容易的事,通常需要大量资源和较高的技术门槛。不过,SimpleTuner 仓库大大简化了这一复杂过程,它提供了一系列强大能力,使训练过程更加易用、高效。
SimpleTuner 支持单 GPU 和多 GPU 训练,能让模型开发更快、更高效。它还会提前把图像和 caption 特征(embedding)缓存到硬盘上,从而在减少内存占用的同时加快训练。仓库还支持 aspect bucketing,可以同时处理不同图像尺寸和宽高比,因此更适合宽屏图像和竖版图像的训练。
SimpleTuner 提供了 Stable Diffusion XL(SDXL)模型的多种训练选项。它支持 Refiner LoRA 或完整训练,这样大多数模型都可以在 24G GPU 上训练。它还支持 PixArt、SDXL、Stable Diffusion 3 和 Stable Diffusion 2.x 的 LoRA/LyCORIS 训练。
如果资源更紧张,DeepSpeed 集成甚至允许你只用 12G VRAM 就能完成 SDXL 的完整 U-Net 训练。此外,SimpleTuner 还支持量化 LoRA 训练,它通过使用低精度的 base model 或 text encoder 权重,进一步降低 VRAM 占用。为了提升训练稳定性,它还提供了一个可选的 EMA 权重网络,不过这个功能不适用于 LoRA 训练。
另外,SimpleTuner 还允许你直接把模型部署到 Hugging Face Hub,实现无缝上传,并自动生成 model card。
用于图像生成的 Diffusion Vision Transformers
DiffiT 引入了 time-dependent multi-head self-attention(TMSA),这是一种能够对空间依赖、时间依赖及其在去噪过程中的相互作用做更细粒度控制的方法。它主要是为了解决 DiT 中 adaLN 的局限:在去噪的初始阶段,图像中的高频内容会被完全扰乱,因为这时去噪网络主要专注于预测低频内容。
在 TMSA 中,key、query 和 value 的权重会在去噪过程的每一个时间步上进行调整。下面这个方程展示了如何在共享空间中,通过对空间嵌入和时间嵌入(分别记作 xs和 xt)做线性投影,来计算时间相关的 query、key 和 value:
qs=xsWqs+xtWqt
ks=xsWks+xtWkt
vs=xsWvs+xtWvt
这里, Wqs,Wqt,Wks,Wkt,Wvs,Wvt分别表示 query、key 和 value 的空间投影权重与时间投影权重。
时间 token 是这样得到的:先取位置时间嵌入,再把它送入一个带 Swish 激活的小 MLP 中。Swish 的形式是:
f(x)=x⋅σ(x)
其中
σ(x)=(1+exp(−x))−1
也就是 sigmoid 函数。与 ReLU 不同,Swish 是平滑且非单调的。正是这种非单调性,让 Swish 与大多数常见激活函数区分开来。
由于 key、query 和 value 都同时是时间 token 和空间 token 的线性函数,它们就能够针对不同时间步自适应地改变 attention 的行为。之后,自注意力计算如下:
Attention(Q,K,V)=Softmax(d QK⊤+B)V
其中,query、key 和 value 分别定义为
Q:={qs}、K:={ks}、V:={vs}。
这里的 d 是 key 的缩放因子, B 是相对位置偏置。需要注意的是,若直接把相对位置偏置和时间嵌入耦合在一起,往往会导致效果不佳,因为它必须同时表示空间和时间信息。Transformer block 的定义如下:
x^s=TMSA(LN(xs),xt)+xs
xs=MLP(LN(x^s))+x^s
这里, LN 表示 layer norm。图 4-10 展示了 DiffiT 的架构设置。
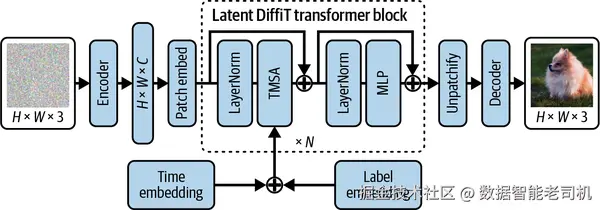
图 4-10. DiffiT 的模型架构。图片改编自 Ali Hatamizadeh 等人(2024)。
DiffiT 采用 encoder-decoder 结构,具有收缩路径和扩张路径,并且在每个分辨率层级之间都通过 skip connection 相连。图 4-11 展示了 DiffiT 在图像空间部分的架构。
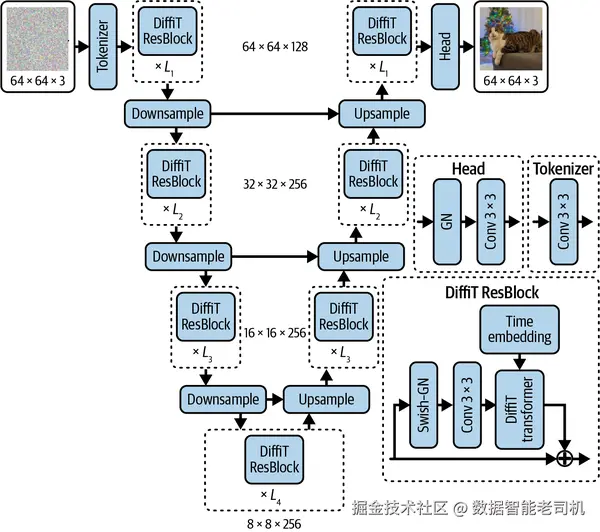
图 4-11. 图像空间版 DiffiT 模型概览。图中的 Downsample 和 Upsample 分别表示用于下采样和上采样的卷积层。图片改编自 Ali Hatamizadeh 等人(2024)。
在 encoder 或 decoder 路径中的每个分辨率层级上,都包含 L 个 DiffiT block,这些 block 内部都带有 time-dependent self-attention 模块。每条路径开始时,都会用一个卷积层调整特征图数量,而分辨率之间的切换则通过上采样或下采样层完成。这些卷积层相当于引入了图像先验偏置(inductive image bias),以提升模型性能。
最终,图像空间 diffusion model 中的残差单元定义如下:
x^s=Conv3×3(Swish(GN(xs)))
xs=DiffiT-Block(x^s,xt)+xs
这里, GN 表示 group normalization。GN 会把通道划分成多个 group,并分别在每个组内计算均值和方差来完成归一化。与其他归一化方法不同,GN 的计算不依赖 batch size,因此能在不同 batch size 范围下保持一致精度。
DiffiT 的 Transformer block 作为残差单元使用,它解决了 attention 的二次复杂度问题------这种复杂度在大特征图上扩展得很差。做法是:把 self-attention 限制在不重叠的局部窗口内进行,而 U-Net 式结构则通过 bottleneck 层,让不同区域之间仍然可以交换信息。最终的残差单元把 DiffiT transformer block 与一个额外卷积层结合起来,同时引入了 group normalization 和 Swish 激活函数。
在 ImageNet-256 数据集上,DiffiT 在 Fréchet Inception Distance(FID)指标上达到了 SOTA 表现。FID 是一个用来评估生成图像质量的指标,它通过衡量真实图像和生成图像之间分布差异来判断生成效果。
用于图像描述的扩散模型
虽然本章不会系统讲图像描述模型,但我仍然想告诉你,已经存在一个基于扩散的图像描述模型,叫作 Latent Diffusion-based Captioner(LaDiC)。它在不依赖额外辅助模块的前提下,表现优于基于自回归的方法。这个模型的代码已经通过论文对应的 GitHub 仓库开源。
用 Diffusion Transformer 获取可解释特征
虽然这一节讲的不是某一个具体模型,但我认为你依然会觉得很有启发,因为它会帮助你更好地解释和理解 T2I diffusion transformer 的内部动态。
为了实现这种可解释性,ConceptAttention 会重新利用 DiT 注意力层中的参数,生成上下文化的文本 embedding,每个 embedding 都对应一个视觉概念(例如 "dragon""sun")。而且,ConceptAttention 不需要额外训练。它只需要对这些概念 embedding 和图像做线性投影,就可以生成高质量 saliency map。Saliency map 会把图像中最强影响模型预测的区域可视化出来,从而帮助我们理解模型的决策过程。它会突出那些对分类或其他输出最重要的图像区域。
使用 ConceptAttention 时,你只需要指定一组 r 个单 token 概念,例如 "cat""sky"等。然后这些概念会被送入 T5 编码器,生成每个概念的初始 embedding ( c0)。
PIXART-α 和 PixArt-Σ 都属于 multimodal DiT,也就是使用 multimodal attention(MMATTN)层同时处理文本 token 和图像 patch 的模型。换句话说,MMATTN 把 prompt 与图像 token 之间的 cross-attention 和 self-attention 操作结合了起来。
ConceptAttention 会在每个 MMATTN 层 L 上,对输入的概念 embedding cL 做归一化,然后重用文本 prompt 的投影矩阵 Kp、Qp和Vp,生成对应的 key、query 和 value:
kc=Kpc1,...,Kpck
qc=Qpc1,...,Qpck
vc=Vpc1,...,Vpck
它们都位于 Rr×d 中。
为了在兼容后续层的同时更新概念 embedding,又避免概念 embedding 反向影响图像 token,ConceptAttention 会把图像的 key 和 value 与概念的 key 和 value 拼接起来。设 kx 和 vx分别表示图像 patch x 的 key 和 value,则有:
kxc=Kxx1,...,Kxxn,Kpc1,...,Kpcr
vxc=Vxx1,...,Vxxn,Vpc1,...,Vpcr
然后,概念输出 embedding 通过如下方式计算:
oc=Softmax(qckxcT)vxc
这个 attention 操作同时包含两部分:图像 patch 到概念的 cross-attention,以及概念之间的 self-attention。这样的设计使概念 embedding 之间能够互相"排斥",从而减少冗余;与此同时,图像 patch 和 prompt token 仍然只彼此关注,如下式所示:
ox,op=Softmax(qxpkxpT)vxp
这里, ox 和 op 分别表示图像 patch ( x) 和 prompt token ( p) 的输出 embedding。
这些操作的可视化见图 4-12。
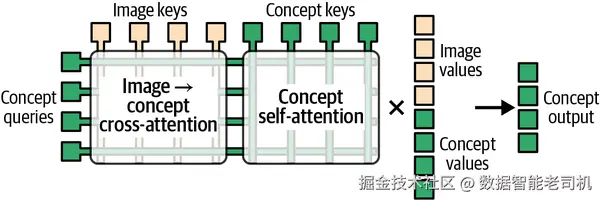
图 4-12. ConceptAttention 允许 concept token 同时整合来自其他 concept token 和 image token 的信息,同时又阻止 image token 访问 concept token 信息。图片改编自 Alec Helbling 等人(2025)。
上述操作形成了一条独立于图像与 prompt token 流之外的 concept embedding residual stream。与预训练 Transformer 的架构一致,MMATTN 层之后还会接一个投影矩阵 P 和一个 MLP,然后再以残差方式加回到 cL 上。
此外,还会施加一个 adaptive layer normalization,生成 scale γ、shift β,以及 gating factors α1 和 α2。于是 residual stream 会更新为:
cL+1←cL+α1(Poc)
cL+1←cL+1+α2MLP((1+γ)lnorm(cL+1)+β)
这里用到的 projection、modulation 和 MLP 层,与处理文本 prompt 时使用的是同一套参数。
前面提到的 concept embedding,还可以和图像 patch embedding 结合起来,在每一层 L 上生成 saliency map。更具体地说,如果你计算图像输出向量 ox 与概念输出向量 oc 之间的点积相似度,就能得到高质量的 saliency map:
ϕ(ox,oc)=Softmax(oxocT)
这与传统 cross-attention map 不同,后者是基于图像 key kx 和 prompt query qp 的。
为了在不同层之间聚合信息,之后会对各层的 saliency map 做平均:
∣L∣1L=1∑∣L∣ϕ(oxL,ocL)
其中, ∣L∣ 表示 MMATTN 层的数量。这种在注意力输出空间中构造出来的 map,是 MM-DiT 架构的一个独特特征,因为它直接利用了与文本语义绑定的 concept embedding。
如果你想亲自试一下,这个项目仓库已经在 GitHub 上公开。现有代码允许你直接运行 ConceptAttention,并为图像中的文本概念生成 saliency map,效果如图 4-13 所示。
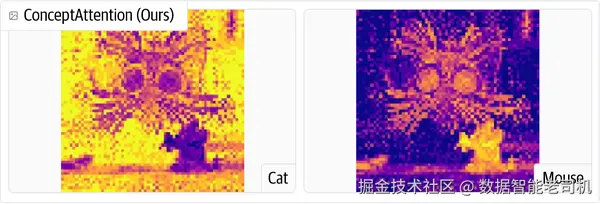
图 4-13. ConceptAttention 能够同时为多个概念生成高质量的 saliency map。
ConceptAttention 也可以非常容易地集成到开源模型中,尤其是那些基于 DiT 架构的模型,因为它完全是一种 post hoc 的可解释性方法,不需要重训练,也不需要修改核心模型权重。
总结
在这一章中,你了解了扩散模型在图像生成,尤其是 T2I 应用中的最新进展。你学习了为什么扩散模型能超越 GAN 和自回归模型:它们训练更稳定、对潜在空间覆盖更好,而且图像质量也更高。
你理解了扩散模型的基本机制,也建立起了这样一个认知:它们是如何通过迭代去噪,把随机噪声一步步精炼成连贯图像的。classifier-free guidance 和 DiT 这类可扩展扩散模型的引入,则进一步展示了图像生成中的重要增强能力,使模型更准确、更灵活。
此外,你还学习了 PIXART-α、PixArt-Σ 和 DiffiT 等模型,它们通过 cross-attention 层、自适应 layer normalization,以及 time-dependent multi-head self-attention 等创新,把 T2I 模型能力进一步推向边界。这些改进不仅提升了图像生成质量和效率,还降低了计算成本和环境影响。
你还接触到了 ConceptAttention,这是一种无需额外训练、却能增强 diffusion transformer 可解释性的方法。它复用了 DiT 架构中已有的注意力层,生成与特定文本概念对齐的高质量 saliency map。这让我们能够更深入地理解:图像中的哪些部分影响了模型输出,以及单个 concept token 是如何与图像 patch 发生交互的。
这一章也给你提供了大量可动手实践的例子,从 diffusion transformer 的搭建,到高质量图像的高效生成。它还涵盖了如何在你自己的数据上训练扩散模型,以及如何可视化和解释这些模型的底层机制。
在第 5 章中,你将学习如何把 Transformer 模型用于音频任务。