前言
大模型帮我们处理了海量文档,但知识依然困在模型的参数里,很难真正"生长"。RAG 技术把文档切片存入向量数据库,提问时快速检索相关片段,看似解决了知识持续注入的难题,可忽高忽低的效果却暴露了一个扎心的事实:知识明明"存"在那里,却好像从未真正"属于"过你。
日常工作中笔者经常碰到这样的场景:上传了20篇同一领域的论文,问它"这些研究形成了哪几条技术路线?彼此的分歧在哪里?"它仍旧只会临时拼凑检索到的片段,而不是从一份自动梳理好的"技术路线全景图"里直接给出答案。哪怕存了100篇文档、查了100次,知识库依然像第一天那样"笨"------新材料不断涌入,理解却没有变深,关联也没有建立。知识只是以碎片形态堆积在库里,缺少交叉引用、矛盾标注和一张持续生长的理解网络。
近几年的技术演进,从 RAG 到 GraphRAG 再到 Agentic RAG,本质上都是在"检索侧"做优化------让翻书更快更准,却始终共享同一个天花板:知识一直停留在"被检索",从未进入"被理解并沉淀"的层面。
近期,OpenAI 高级研究员 Andrej Karpathy 分享的 LLM Wiki,让笔者看到了一条全新路径:像编译器一样,把知识编译成一套持续更新的结构化笔记,模型不再需要每次临时"翻书"。 这不只是检索技术的升级,更是知识存在形态的根本变革------从碎片化的向量存储,走向结构化的知识编译。
本文将沿着这条演进脉络,为你完整梳理:RAG 系列在检索之路上走了多远、撞上了什么墙;LLM Wiki 如何用"编译器模式"开启新范式;面对不同场景又该如何选型;最后,还会手把手带你搭建自己的第一个 LLM Wiki。干货满满,跟着"大模型真好玩"一起深入探索吧!
一、RAG演进史:从基础到智能
1.1 传统RAG技术:给大模型配本参考书
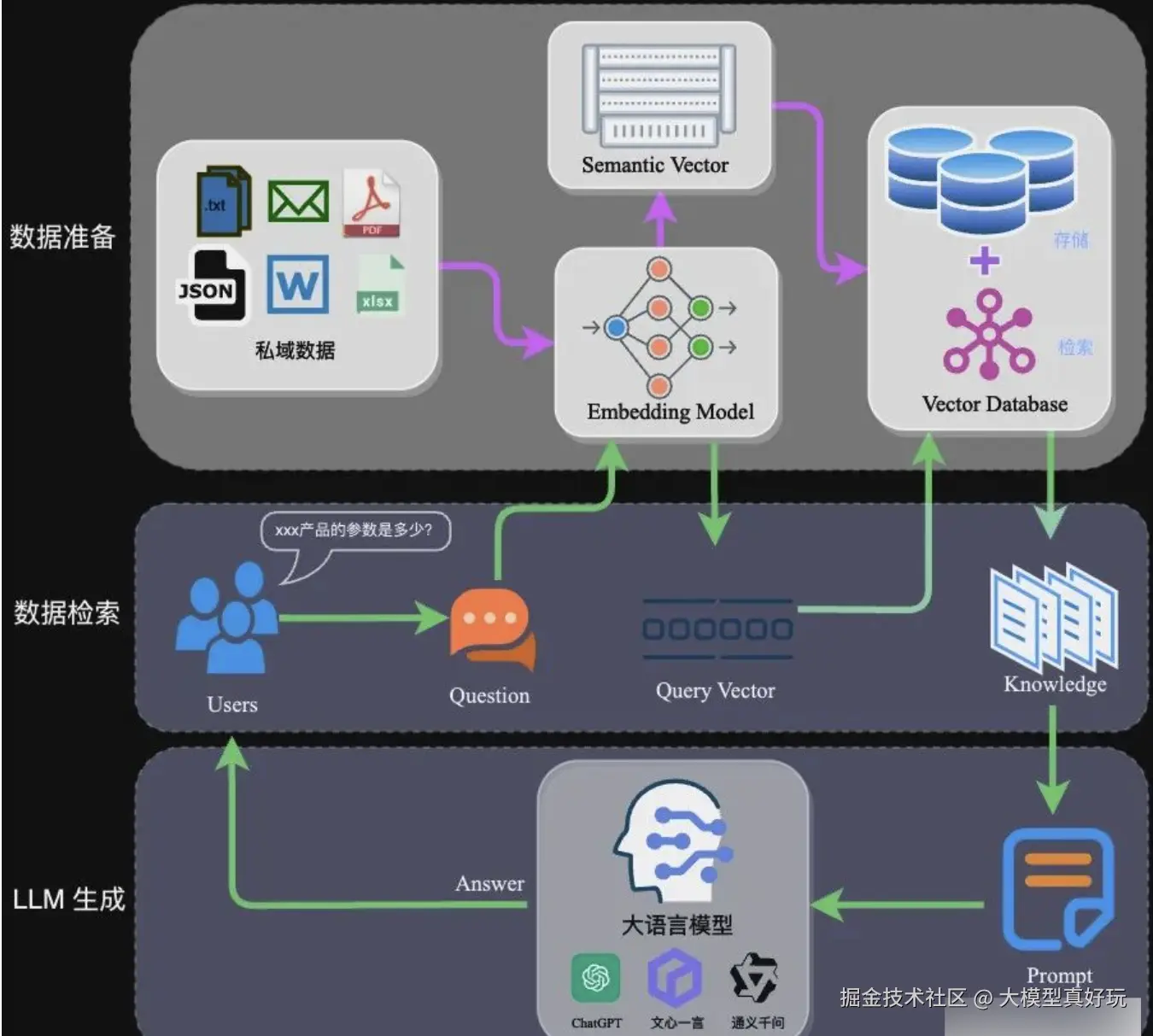
大模型的知识储备虽强,但受训练数据截止时间的限制,同时所有知识都被固化为模型参数,缺乏对私有领域数据的覆盖。为了让大模型也能"读懂"最新信息或企业私域文档,Meta 提出了 RAG(Retrieval-Augmented Generation,检索增强生成) 技术。
RAG 的工作方式,就像给模型配了一本随用随翻的参考书。首先,把用户上传的文档切成片段,转成向量存入向量数据库;当用户提问时,根据问题从数据库中检索出最相关的文本片段,拼接到提示词里作为参考信息,让模型据此作答。(想深入了解 RAG 核心原理,可阅读笔者的文章 一文带你了解RAG核心原理!不再只是文档的搬运工)
这套流程简单有效,但背后藏着三个致命局限:
- 每次查询从零开始------模型问完即忘,没有任何积累;
- 检索精度随文档量增加而下降------碎片化的向量匹配很难捕捉深层语义关联;
- 难以处理跨文档的复杂关联------当答案需要综合多份材料中的矛盾观点时,传统 RAG 就有些力不从心了。
本质上,RAG 就是"临时抱佛脚"------每次都重新翻书、临时拼凑答案
1.2 GraphRAG: 用知识图谱增强关联
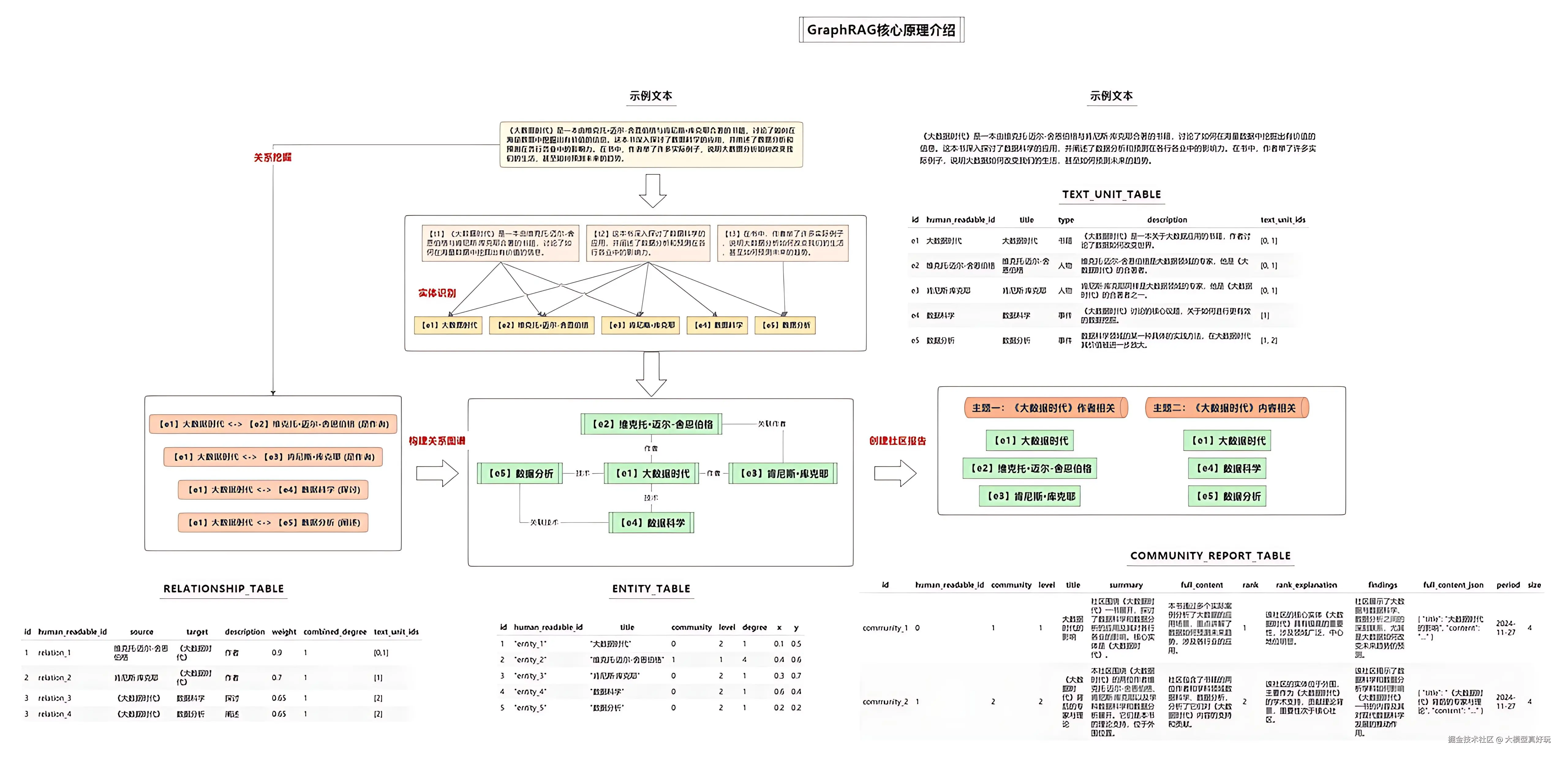
为了突破传统 RAG 的瓶颈,微软研究院提出了 GraphRAG。它的核心思路是:不直接检索原始文本块,而是先用大模型从文档中构建知识图谱(实体+关系),再基于图谱进行检索。 这样一来,它解决了传统 RAG 的一大痛点------跨文档的实体关联与复杂推理。当多份文档提到同一个人、同一个概念时,知识图谱能把它们链接起来,让模型"看见"文本碎片背后的整体图景。(想全面了解 GraphRAG,推荐阅读笔者的文章 准确率飙升!Graph RAG如何利用知识图谱提升RAG答案质量(一)------GraphRAG是什么?)
但 GraphRAG 也付出了显著代价:
- Token 消耗巨大------构建图谱需要反复调用大模型处理全文;
- 部署复杂度高------需要引入图数据库和额外的处理链路;
- 对模型能力依赖强------一旦实体或关系提取错误,会直接污染整个知识库。
最关键的是,GraphRAG 虽然提升了检索精度,却没能改变那个根本事实------每次查询依然是从零开始。图谱虽然可以被复用,但最终生成答案时,模型仍然是在运行时临时拼凑信息。
1.3 AgenticRAG: 让Agent自主决策搜索
Agentic RAG 则更进一步,将检索能力包装为 Agent 可以自主调用的"工具"。不同于传统 RAG 那种"一开始就检索,然后一问一答"的固定流水线,Agentic RAG 构建了一个自主决策循环:Agent 可以基于中间结果动态调整检索策略------如果第一次检索结果不够充分,它会自动更换关键词再搜;如果发现需要跨文档对比,它会主动发起多次查询。
这让检索变得更加智能,但范式并未改变:知识仍然是在运行时临时拼凑,没有任何持久化的积累。说得更直白些,Agent 只是更聪明地在"翻书",但本质上还是在"翻书"。
1.4 小结:RAG路线上的"共同天花板"
回看这三种方案,无论检索环节怎样优化,RAG 系列都共享一个本质特征:大模型在每次查询时都在重新"发现"知识。就像一个学生,每次考试都直接翻参考书,从不做笔记,也从不复习。
这引出了一个关键问题:有没有一种方案,能让知识被"编译"一次就沉淀下来,后续所有查询都基于这份沉淀,而不是反复从原始材料中重新提取?
答案正是------LLM Wiki。
二、LLM Wiki:Karpathy的"知识编译器"
2.1 源头:一条千万阅读推文引爆的新技术
2026年4月4日,Andrej Karpathy(OpenAI 联合创始人、前特斯拉 AI 总监)在社交平台上分享了自己用大模型构建个人知识库的工作流,迅速引发技术圈的广泛讨论。
他的核心理念出人意料地朴素:别让模型每次临时翻书,让它替你维护一套持续更新的笔记。 把资料逐步"编译"成一组互相链接的 Markdown 文件(即 Wiki),像程序员维护代码库一样管理你的知识。原始材料一经摄入就永不修改,所有的理解、关联和提炼,都由大模型自动写入 Wiki 页面。
这套方法没有复杂的向量数据库,也没有精巧的检索算法------只有原始素材、一组 Markdown 文件,以及一个持续运转的"编译器"(大模型智能体)。
2.2 RAG是解释器,LLM Wiki是编译器
为了更好地理解这一范式的根本差异,笔者借用编程语言中的一个经典类比。
学过编程的读者都知道,语言大致分为编译型 和解释型两类。编译型语言(如 C / C++)会一次性将源码转换成机器码,生成可执行文件,执行速度快,但需要完整编译;解释型语言(如 Python)则逐行翻译执行,依赖解释器实时运行,灵活但速度较慢。简单来说,编译型是"事前生成可执行文件",解释型是"边解释边运行"。
带入到知识处理的场景中,RAG 就是典型的解释型模式 ------每次查询都在运行时重新检索、拼凑片段,问完即忘。而 LLM Wiki 是编译型模式------预先将用户上传的文档处理成结构化的中间表示(即 Wiki 页面),后续所有工作都直接基于编译产物展开,不再反复阅读原始材料。

2.3 LLM Wiki 的核心架构
LLM Wiki 的架构简洁而清晰,由三个层级构成:
数据层(raw/):
所有原始素材统一放入 raw/ 目录:论文 PDF、网页剪藏、会议记录、随手笔记。这些文件一旦放入,永远不被修改。它们是整个知识库的事实基准,任何 Wiki 页面的内容都可以追溯到对应的原始素材。
知识层(wiki/):
这是编译产物的存放地。大模型根据原始素材创建并维护各类页面:
- 实体页面:人名、公司、技术术语的专属词条
- 概念页面:抽象概念的详细解释与关联
- 主题摘要:跨文档的主题综合与观点提炼
- 对比表格:不同方案、不同观点的结构化对比
所有页面以 Markdown 格式存储,通过 Wiki 链接([[页面名]])互相引用,形成网状知识结构。
编译层(大模型智能体)------持续运转的"编译器":
当新资料加入时,编译流程自动触发:
- 阅读:大模型通读新素材,理解核心内容
- 关联:比对现有 Wiki,找出相关页面
- 更新:更新已有页面,补充新信息,标注矛盾
- 创建:为新材料中出现的新实体/新概念创建独立页面
- 交叉引用:在所有相关页面之间建立链接
如果用计算机科学的概念来精准映射,LLM Wiki 的每个组件都能找到对应:
| 计算机科学概念 | LLM Wiki 对应 | 说明 |
|---|---|---|
| 源代码 | raw/ 目录 |
原始素材,不可变,事实基准可追溯 |
| 编译器 | 大模型智能体 | 驱动整个编译过程:读取源材料、理解上下文、更新 Wiki |
| 中间表示 | wiki/ 目录 |
结构化 Markdown 文件集合,包含实体页、概念页、主题摘要、对比表格 |
| 符号表 | index.md |
所有实体和概念的索引目录,快速定位知识入口 |
| 构建日志 | wiki-log.md |
记录每次编译的详细日志,包括新增、修改、矛盾标记等 |
理解了这个表格,也就理解了 LLM Wiki 的全部设计哲学:它不是一种检索技术,而是一种知识编译技术。
三、实操体验:快速搭建你的第一个LLM Wiki
理论说得再多,不如亲手试一次。目前 LLM Wiki 已推出桌面客户端,安装过程非常简单。
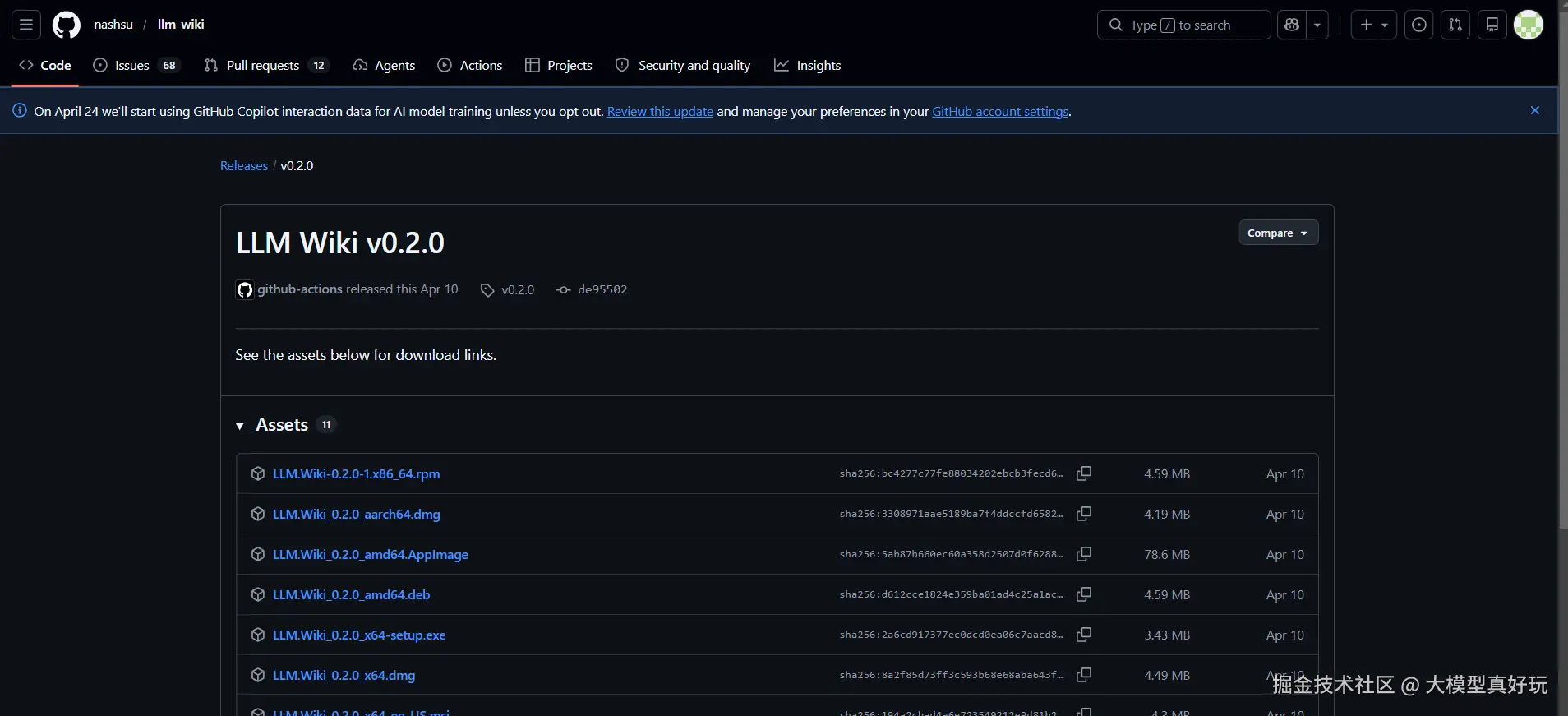
- 下载安装包
在 GitHub Releases 页面 选择对应系统的版本下载。
- 安装并创建项目
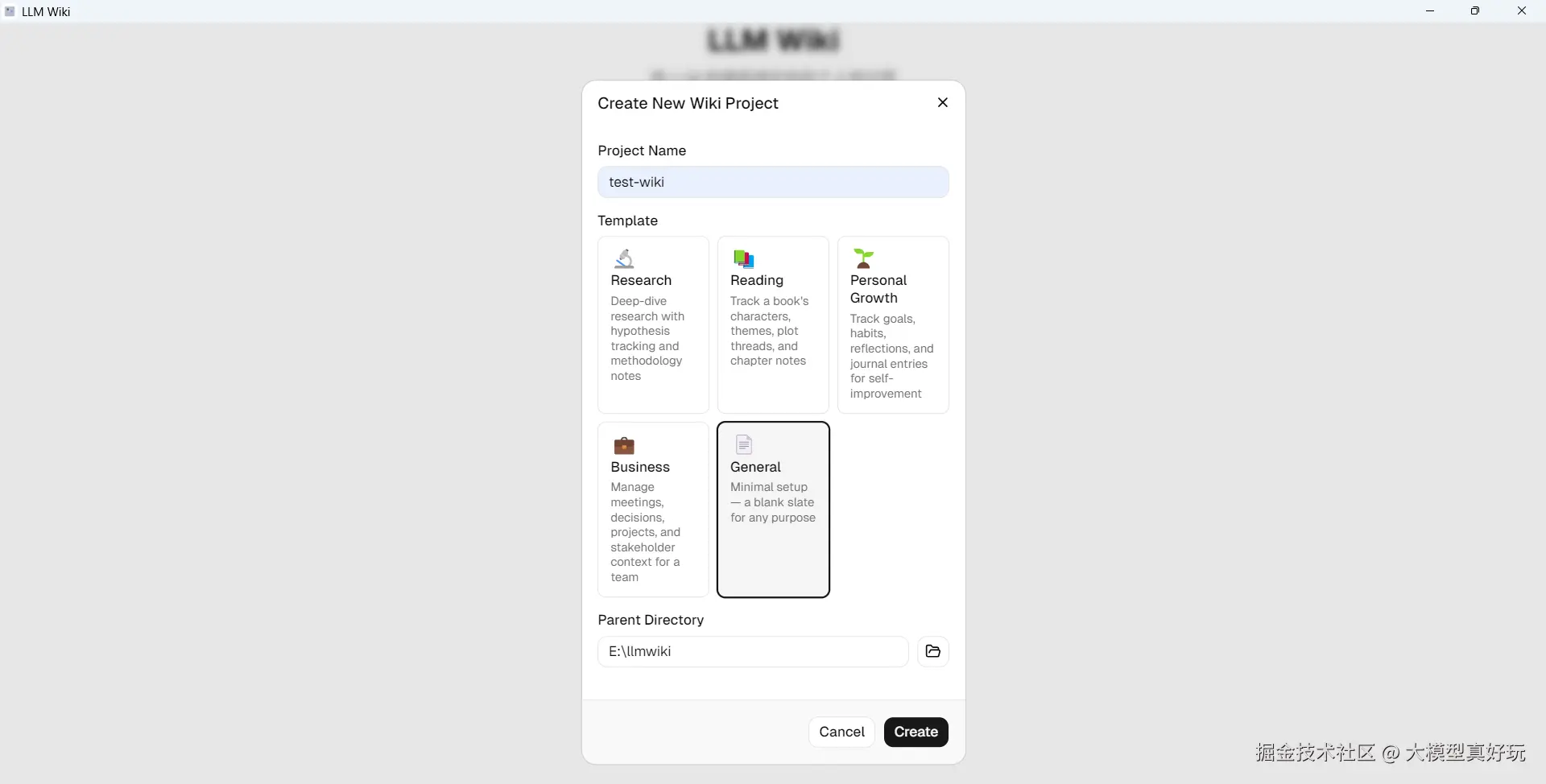
安装时指定目录,一路点击"Next"即可。打开后界面如下,这里我们新建一个名为test-wiki的项目。
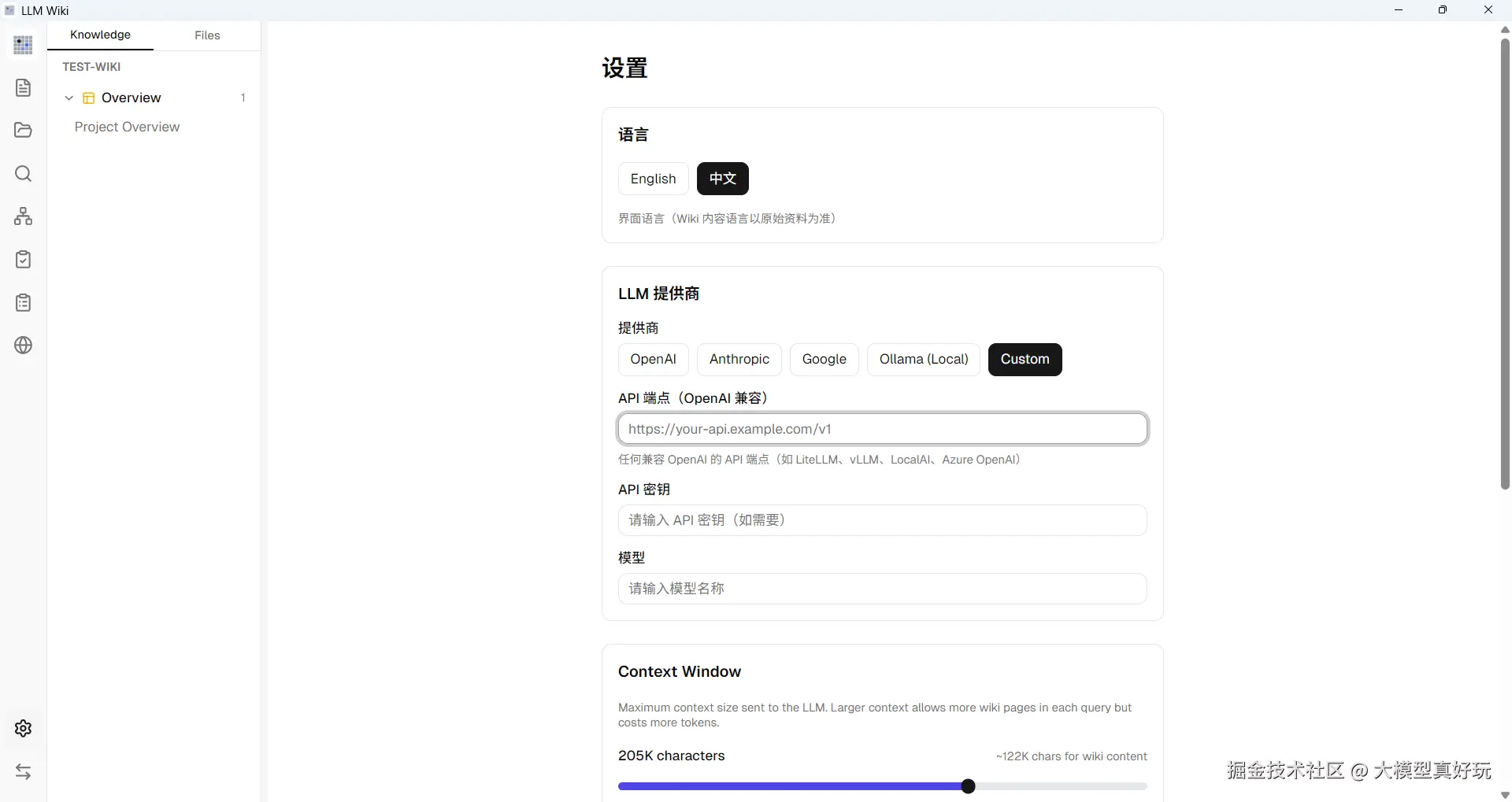
- 配置大模型
启动前先点击左下角的设置按钮配置模型。这里笔者使用的是 DeepSeek-V4-Flash。
- 摄入原始资料(Ingest)
LLM Wiki 的第一步是摄入(Ingest) 原始文档。点击左侧的文件夹图标,上传需要处理的文件------这里笔者上传了一份 Python 学习 PDF 做演示。上传后,完整的编译流程自动触发:大模型阅读 PDF → 提取要点 → 比对现有 Wiki → 更新相关页面 → 创建新页面 → 补充交叉引用。一次摄入,整个知识网络便自动更新。左下角可以实时看到处理阶段。
- 基于 Wiki 问答
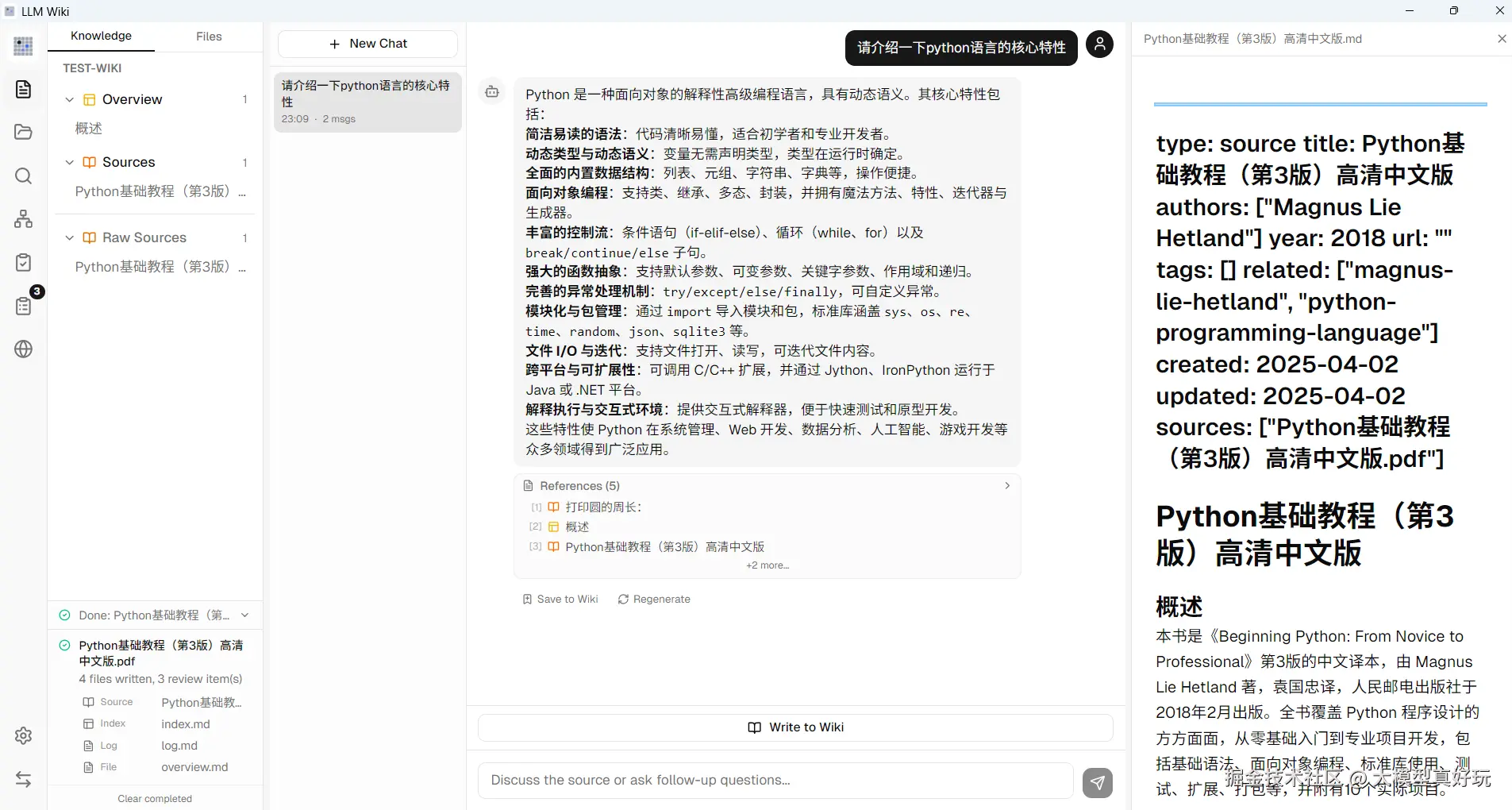
构建完成后,点击左侧栏的"Wiki",就能直接对已编译的知识库提问。比如问:"请介绍 Python 的核心特性。"模型基于 Wiki 索引给出回答,并且还可以一键将回答继续写入 Wiki,让知识库持续优化。
- 查看知识网络
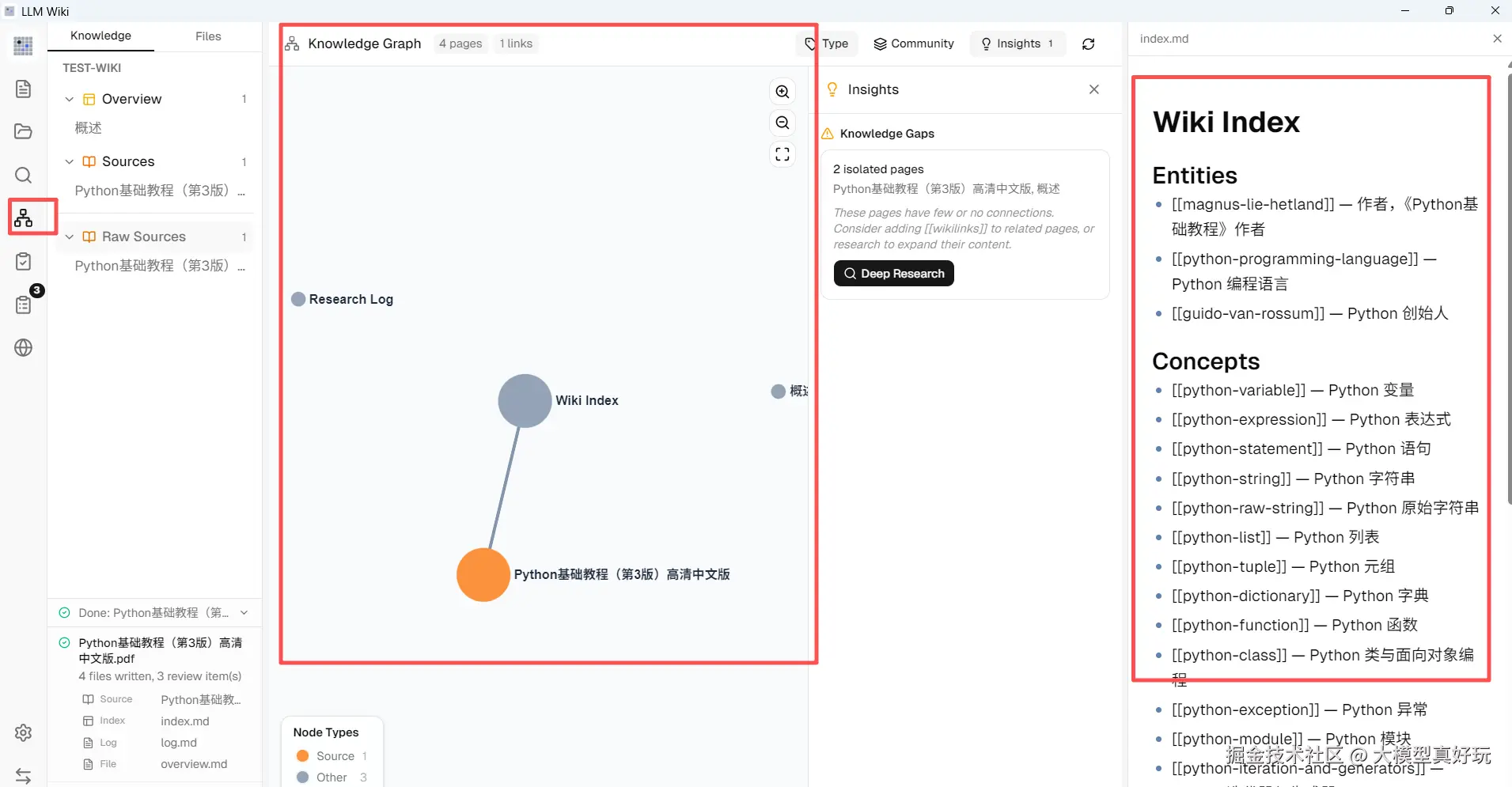
点击左侧栏的"关系图",可以直观看到 Wiki 构建的知识网络以及核心的index.md索引文件。它不是 RAG 那样的片段切分,也不同于 GraphRAG 的细粒度实体抽取,而是基于大模型整理的结构化知识------文章被真正"沉淀"为有机整体。
- Lint 健康检测
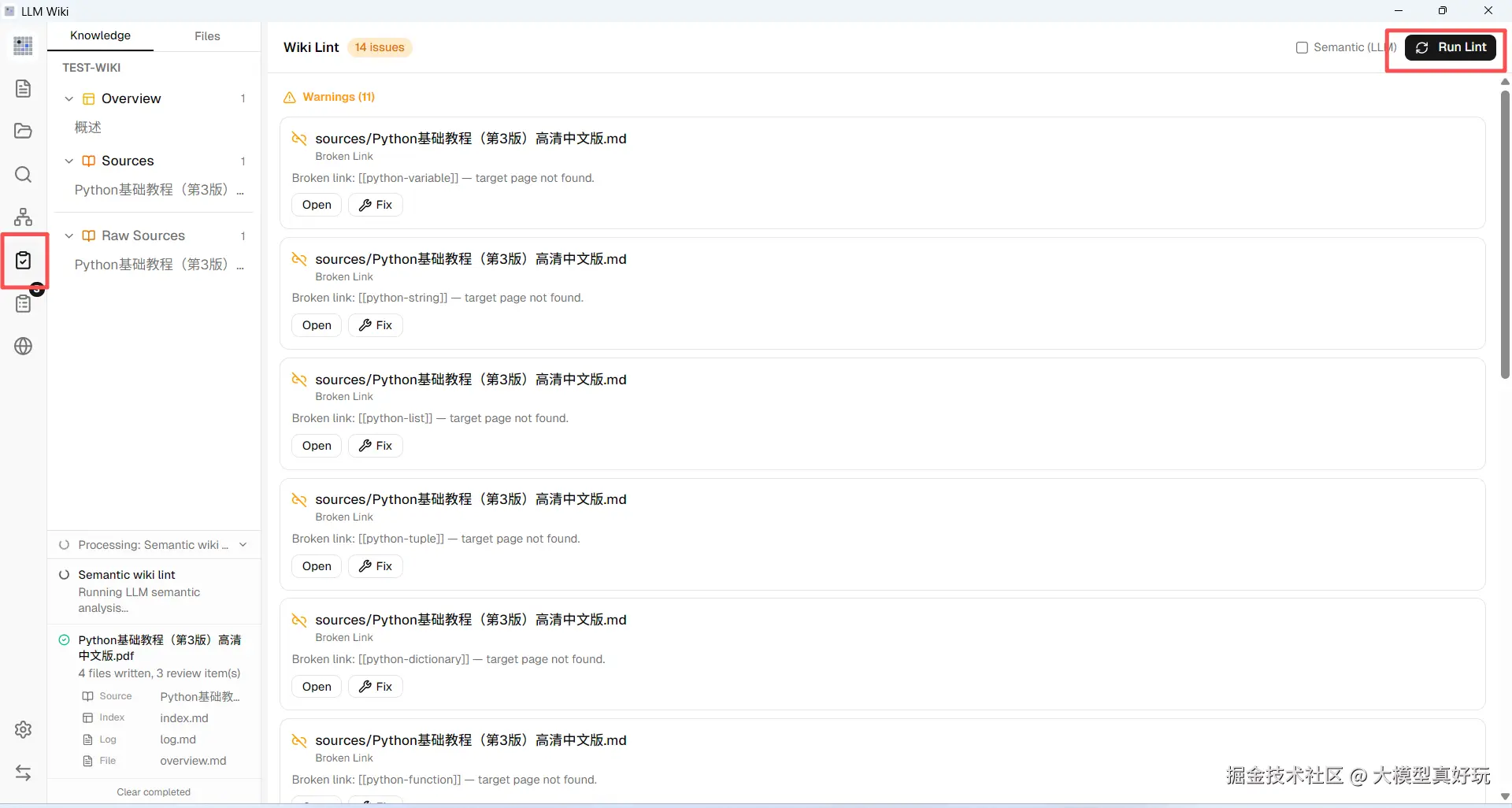
还有一个实用功能:点击左侧栏的"Lint"按钮,系统会自动检测死链、孤立页面、矛盾标记、未引用实体等问题,确保 Wiki 的质量与一致性。当然,你也可以随时手动编辑 Wiki 页面进行修正。
限于篇幅,上面只展示了基本操作。接下来分享一个笔者实际构建知识库的流程------"顺便猜猜看,这篇文章的编写有没有 LLM Wiki 的助力?"
第一步 ,笔者添加了第一份文档------一篇关于 RAG 的综述论文。大模型 阅读后,Wiki 中自动生成了 RAG.md、向量检索.md、大语言模型.md 等页面,index.md 也出现了相应的索引条目。
第二步 ,笔者添加了第二份文档------一篇关于知识图谱的技术博客。大模型 发现这篇新内容与已有的 RAG.md 相关,于是更新了 RAG.md,加入知识图谱的关联,同时创建了 知识图谱.md 新页面,并在两个页面之间建立了双向链接。
第三步,笔者添加了第十份文档。此时 大模型 面对的不再是孤立的十篇文章,而是一个已经蒸馏了前九篇知识精华的 Wiki 网络。新内容被精准地编织进已有知识结构,矛盾被标记,关联被补全,观点被综合。
第四步,笔者提问:"对比 RAG 和知识图谱方案在跨文档推理上的优劣。"模型基于已经结构化整理好的 Wiki,给出了精准、全面、有明确出处的回答。
最直观的感受是:Wiki 越用越聪明,积累越多越有价值。 这不是心理暗示,而是复利效应的真实体现------每一次摄入,都在为下一次查询铺垫更好的上下文。
四、选型指南:特性对比与决策建议
LLM Wiki 的出现,并不意味着传统知识库方案就此作废。这四种方法本质上是为不同阶段、不同规模的知识管理需求而设计的,LLM Wiki 也有其明确的适用边界:
- 不擅长大规模、低延迟的企业级检索:当文档量达到百万级别时,传统 RAG 基于向量数据库的检索方案在工程成熟度、成本和响应速度上更具优势。LLM Wiki 的编译模式更适合高价值、需深度理解的中小型知识库。
- 知识编译质量依赖底层 LLM 的能力:编译器模式的"双刃剑"在于,如果在编译环节出现理解偏差,这个错误会被永久固化为 Wiki 页面的内容,并传递给后续所有查询。因此,用于编译的模型选择和人工校验变得至关重要。
- 对临时、一次性查询过重:如果你只是想快速对一份刚收到的 PDF 提几个问题,完整的"摄入---编译---更新---交叉引用"流程就显得笨重了。此时直接使用 RAG 的"即问即翻"模式反而更高效。
综合来看,笔者的最佳实践建议是分层组合使用 :将 LLM Wiki 作为核心知识沉淀层 ,负责把高价值文档持续编译成结构化、互联的知识网络;同时,将 RAG 作为外围海量文档的补充检索通道,用于快速扫描尚未编入 Wiki 的历史文档或边缘资料。两者互补,既能获得知识沉淀带来的深层理解与复利效应,又保留了检索的广度与灵活性,共同构成一套完整的知识管理栈。
五、趋势展望:知识编译时代已然到来
5.1 从"检索"到"编译"是确定性趋势
信息增长的速度,早已超过了人类手动整理信息的速度。单纯的"检索-拼凑"模式,可以让你瞬间找到100篇论文的相关片段,却很难帮你从中提炼出一个真正连贯的知识框架------快速翻书和深度理解之间,始终隔着一道鸿沟。
而 LLM Wiki 所代表的"编译"思路,正在被越来越多的项目和产品采纳。它的本质,是把 LLM 的理解能力前置:将"理解成本"从每次查询的时刻,转移到内容摄入的那一刻。每多摄入一份材料,知识不是被塞进数据库,而是被编织进一张不断生长的网------这正是知识积累的复利效应。
5.2 技术融合方向
这个领域仍在快速演进,三个融合方向尤其值得关注:
LLM Wiki + 知识库 + 知识图谱:动态沉淀与严谨关联的结合。
既有知识图谱严谨的实体关联,又保留了 Wiki 灵活的表达力。可以想象:你的 Wiki 页面自动与知识图谱中的实体对齐,当你更新一个概念的解释时,图谱中的关联关系同步更新,所有引用该概念的页面也一并刷新------知识不再是孤立的碎片,而是一个会呼吸的有机体。
LLM Wiki + Agent:让 Wiki 成为 Agent 的长期记忆层。
Agent 不再每次从零开始了解你的业务背景,而是直接基于持续维护的 Wiki 进行决策和行动。一个客服 Agent 可以通过 Wiki 持续学习产品知识的演变,一个研究助理 Agent 可以通过 Wiki 跟踪学术观点的演变脉络------Wiki 就是它们的"大脑皮层"。
多模态 LLM Wiki:从纯文本走向多模态知识的统一编译。
将图片、视频字幕、音频转写等也纳入编译范围。一张产品原型图、一段会议录音、一个技术演示视频------所有模态的信息,最终都被编译成统一、可查询的知识结构。你的 Wiki 不再只是文字的笔记,而是一个多感官的"数字外脑"。
六、总结
以上就是今天大模型真好玩要与大家分享的全部内容啦,本篇文章分享了从 RAG 到 GraphRAG 再到 Agentic RAG的检索技术的精进历史,同时指明RAG始终困在"临时翻书、问完即忘"的循环的痛点。LLM Wiki 的出现,将范式从"检索"扭转为"编译"------知识不再止于向量碎片,而是沉淀为一张持续生长的结构化理解之网。就像编译器让源码可执行,LLM Wiki 让资料可理解、可关联、可积累,让知识真正"属于"你。每一次摄入都在为下一次理解铺路,知识积累的复利效应由此启动。当编译思维与知识图谱、Agent、多模态深度融合,一个属于每个人的"数字外脑"时代已然到来。现在,就动手编译大家的第一个 Wiki,让知识开始生长吧~ 以上就是我今天的分享,欢迎大家关注我的掘金账号,更多的精彩内容大家也可关注我的同名微信公众号:大模型真好玩,免费分享工作生活中大模型开发教程和资料,有什么需要都可通过公众号私信我~