OpenClaw最严厉的父亲- Windows 使用优化建议(mac流程基本相似)

好久不见大家👋。距离上次撰写文档已经过了快一个月了,最近工作比较忙,接下来会更新的比较频繁 后续会跟新训练和推理相关的内容感兴趣的筒子们可以关注我,关注后续的内容。
引言:
你是否也遇到过本地使用 OpenClaw 长时间运行后迟迟没有结果,甚至出现重启、重复操作、突然"变傻"等情况?(这个时候心里全是MDFUCK。。。)
很多时候,这并不是模型性能不足,而是 Agent 上下文在长时间运行中经历了多次 Context Compaction(上下文压缩)。随着历史信息被反复摘要与压缩,关键任务状态、工具调用结构以及早期约束会逐渐丢失,最终导致推理质量下降、行为漂移,甚至整个 Agent 进入"失忆"状态。
接下来,跟着我一起,从 Prompt、Memory、Context、推理链到推理框架层层优化,成为 OpenClaw 最严厉的父亲👨。
适用场景: 本地部署 OpenClaw + Ollama(方便但是事多),显卡显存有限(24-32GB),希望 Agent 能稳定完成复杂任务。
本文档基于 RTX 5090 (32GB) + Qwen3.6:35b-a3b 的实战调优经验总结,所有日志均来自真实生产环境。
一、问题全景:为什么你的 OpenClaw 总是完成不了任务?
二、真实案例:从 23 次压缩到 0 次的调优过程
2.1 初始状态:疯狂压缩,任务永远完不成
以下是未优化时的真实日志:
log
02:39:45 [agent/embedded] [context-overflow-diag]
sessionKey=agent:main:main
provider=custom-127-0-0-1-11434/qwen3.6:35b-a3b
messages=23
compactionAttempts=0
observedTokens=unknown
error=Context overflow: estimated context size exceeds safe threshold during tool loop.
02:39:45 [agent/embedded] context overflow detected (attempt 1/3);
attempting auto-compaction for custom-127-0-0-1-11434/qwen3.6:35b-a3b
02:40:10 [agent/embedded] auto-compaction succeeded; retrying prompt
02:40:51 [agent/embedded] context overflow detected (attempt 2/3); attempting auto-compaction
02:41:22 [agent/embedded] auto-compaction succeeded; retrying prompt
02:46:14 [agent/embedded] context overflow detected (attempt 3/3); attempting auto-compaction
02:47:34 [agent/embedded] [tool-result-truncation]
Truncated 34 tool result(s) in session
(contextWindow=65536 maxChars=16000 aggregateBudgetChars=16000 oversized=0 aggregate=34)
02:48:51 Auto-compaction failed. Restarting session agent:main:main
-> 90e382d0-8840-4916-8a07-799e322a3ade and retrying.Session 状态:compaction 次数 23 次,上下文窗口 66k tokens。

2.2 根本原因分析
通过查看 Ollama 模型的 Modelfile,发现问题:
log
# ollama show qwen3.6:35b-a3b --modelfile 输出:
FROM G:\ollama\blobs\sha256-f5ee307a...
TEMPLATE {{ .Prompt }}
RENDERER qwen3.5
PARSER qwen3.5
PARAMETER temperature 1
PARAMETER top_k 20
PARAMETER top_p 0.95
PARAMETER min_p 0
PARAMETER presence_penalty 1.5
PARAMETER repeat_penalty 1没有 num_ctx 参数! Ollama 使用默认值,而 OpenClaw 以为有 65536。两侧不对齐就是反复溢出的根源。
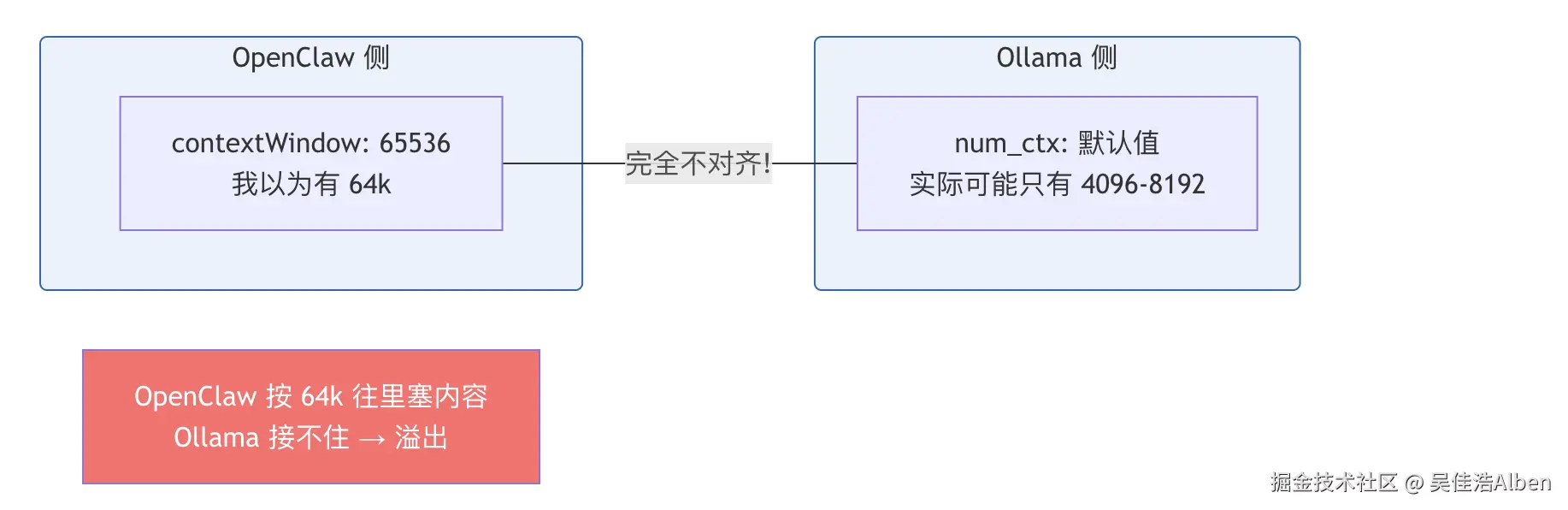
三、第一步修复:Ollama 侧配置对齐
3.1 创建指定上下文的模型
Ollama 新版不支持 --num-ctx 运行时参数:
log
PS C:\WINDOWS\system32> ollama run qwen3.6:35b-a3b --num-ctx 131072
Error: unknown flag: --num-ctx必须通过 Modelfile 创建新模型:
powershell
# 创建 96k 上下文版本(32GB 显存甜点配置)
"FROM qwen3.6:35b-a3b`nPARAMETER num_ctx 98304" | Out-File -Encoding utf8 C:\temp\Modelfile
ollama create qwen3.6-96k -f C:\temp\Modelfile验证:
powershell
ollama show qwen3.6-96k --modelfile确认输出中包含:
bash
PARAMETER num_ctx 983043.2 开启 Flash Attention 和 KV Cache 量化
推理速度提升 30-50%,强烈建议开启:
powershell
[System.Environment]::SetEnvironmentVariable("OLLAMA_FLASH_ATTENTION", "1", "User")
[System.Environment]::SetEnvironmentVariable("OLLAMA_KV_CACHE_TYPE", "q8_0", "User")设完必须重启 Ollama(退出托盘图标 → 重新打开)。
验证:
powershell
PS C:\Users\Alben> [System.Environment]::GetEnvironmentVariable("OLLAMA_FLASH_ATTENTION", "User")
1
PS C:\Users\Alben> [System.Environment]::GetEnvironmentVariable("OLLAMA_KV_CACHE_TYPE", "User")
q8_03.3 注意 Windows PowerShell 的坑
Windows 下 curl 是 Invoke-WebRequest 的别名,不是 Linux 的 curl,很多命令会报错:
log
PS C:\WINDOWS\system32> curl http://127.0.0.1:11434/api/show -d '{"name":"qwen3:35b-a3b"}' | grep num_ctx
grep : 无法将"grep"项识别为 cmdlet、函数、脚本文件或可运行程序的名称。正确的 PowerShell 写法:
powershell
# 查看模型信息
Invoke-RestMethod -Uri "http://127.0.0.1:11434/api/show" -Method Post -Body '{"name":"qwen3.6-96k"}' -ContentType "application/json"
# 或者直接用 ollama 命令
ollama show qwen3.6-96k --modelfile四、第二步修复:OpenClaw 侧配置
4.1 模型配置要点
| 参数 | 推荐值 | 说明 |
|---|---|---|
| 模型名 | qwen3.6-96k |
与 Ollama 创建的模型名一致 |
| contextWindow | 98304 |
与 Ollama num_ctx 必须一致 |
| maxTokens | 8192 |
单次输出上限 |
| API 模式 | ollama |
本地 Ollama 用原生模式 |
| reasoning | true (low) |
开启思维链但用低级别 |
4.2 API 模式选择
可用模式:openai-completions | openai-responses | ollama | anthropic-messages 等
连接本地 Ollama 必须用 ollama 模式 ,不要用 openai-completions(工具调用支持差)。
4.3 maxTokens 为什么不能太大
真实踩坑:一开始 maxTokens 设成了 96k (98304),后来又设成 48k (49152)。
Agent 单次回复通常只有 1-4k token,maxTokens 设 8192 足够。剩下 90k 全给对话历史才是正解。
五、第三步修复:Thinking 模式的取舍
5.1 为什么必须开 Thinking
未开 thinking 时的真实表现------模型疯狂调用工具,204 条消息撑爆上下文:
log
02:48:51 [agent/embedded] [context-overflow-diag]
sessionKey=agent:main:main
messages=204
error=Context overflow: estimated context size exceeds safe threshold during tool loop.204 条消息中大部分是 tool output(工具返回结果)。 模型不思考就行动,反复试错,每次工具返回都堆积在上下文里。
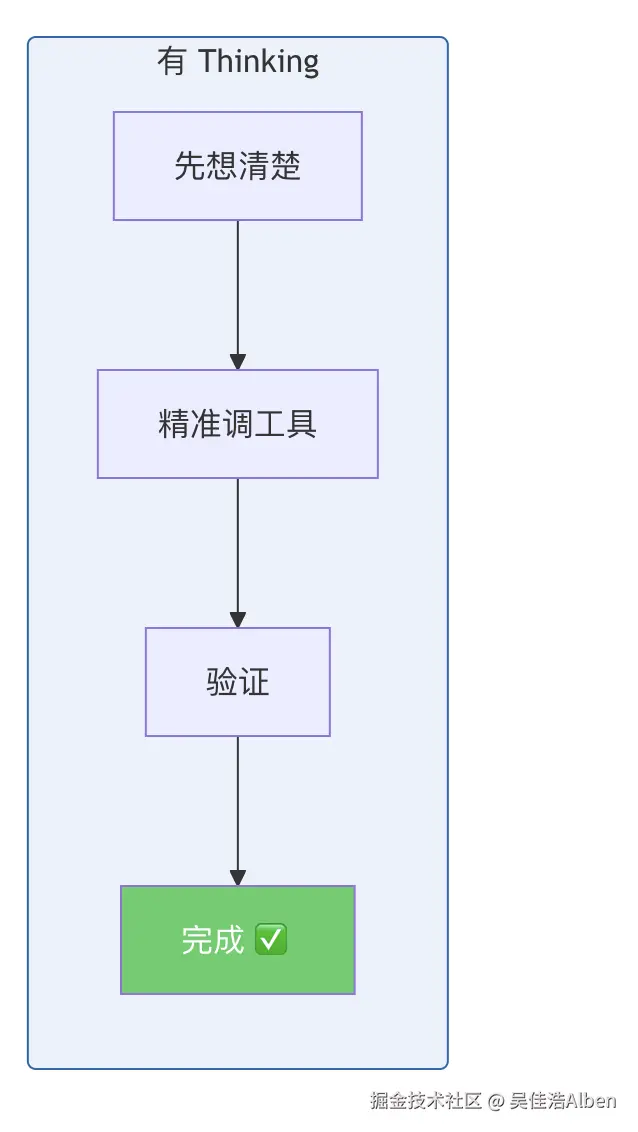
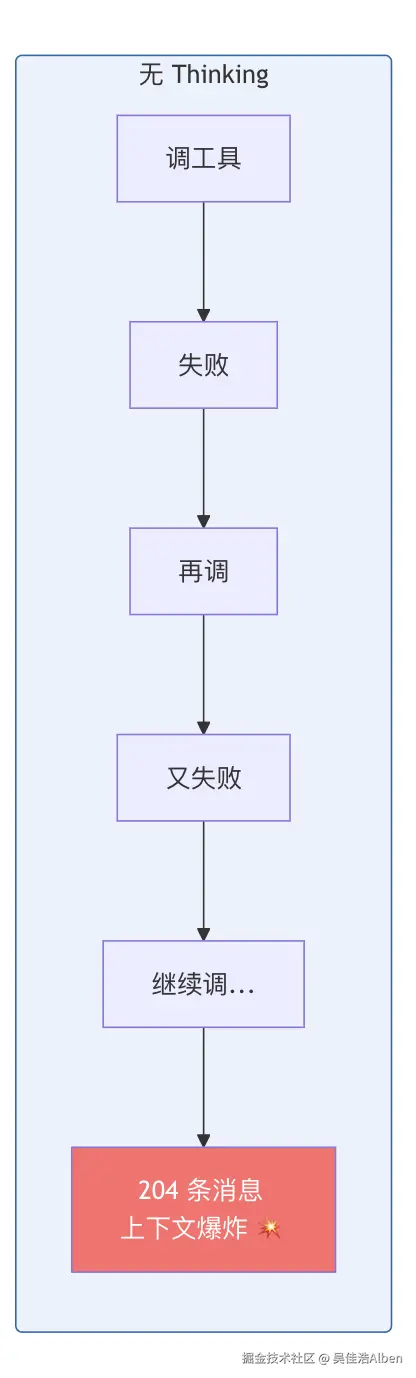
5.2 Thinking 级别对推理时间的影响
| 级别 | 推理时间增加 | 适用场景 |
|---|---|---|
| high | +60-200% | 极复杂推理,容易超时 |
| medium | +30-80% | 复杂任务 |
| low | +10-30% | ** 推荐,平衡速度和质量** |
| off | 0% | 简单任务,但容易陷入工具循环 |
5.3 Thinking 导致超时的真实日志
log
14:36:18 [agent/embedded] embedded run failover decision:
runId=ec47c199-151e-47fe-bde5-b8d1d872c236
stage=assistant
decision=surface_error
reason=timeout
from=custom-127-0-0-1-11434/qwen3.6-128k128k 上下文 + thinking = 推理太慢,超过 OpenClaw 的 timeoutSeconds(protected path,无法修改)。
解决方案:降低上下文大小(128k → 96k)+ thinking 用 low 级别。
六、第四步修复:Prompt 约束(SOUL.md)
在工作区的 SOUL.md 文件中添加以下规则:
markdown
## 工具使用规则(必须严格遵守)
1. **先思考再行动** --- 每次调用工具前,先说清楚为什么要调用、期望得到什么
2. **读文件只读需要的部分** --- 用行号范围,不要读整个大文件
3. **不要重复执行相同的命令** --- 如果一个命令失败了,分析原因再换方法,不要原样重试
4. **编辑文件前先确认内容** --- 先读目标区域,确认 oldText 完全匹配后再编辑
5. **单次任务工具调用不超过 15 次** --- 超过说明方向错了,停下来重新规划
6. **每 5 次工具调用后做一次总结** --- 回顾进度,确认是否在正确的方向上
7. **复杂任务先列计划** --- 动手之前先列出 1-2-3 步骤,再按步骤执行
8. **上下文管理** --- 当任务复杂时,把中间结果和进度写入 memory/ 文件,不要依赖对话记忆为什么规则 4 特别重要
真实日志中 edit 工具反复失败:
log
[tools] edit failed: Could not find the exact text in
G:\openclaw\DocMind\backend\app\routers\models.py.
The old text must match exactly including all whitespace and newlines.模型不先读文件确认内容就直接编辑,oldText 匹配不上 → 失败 → 重试 → 每次重试都把完整文件内容塞进上下文 → 加速上下文爆炸。
七、第五步优化:子代理隔离上下文
7.1 为什么需要子代理
上下文一定会用完 ,这是物理限制。子代理的作用是隔离上下文消耗。
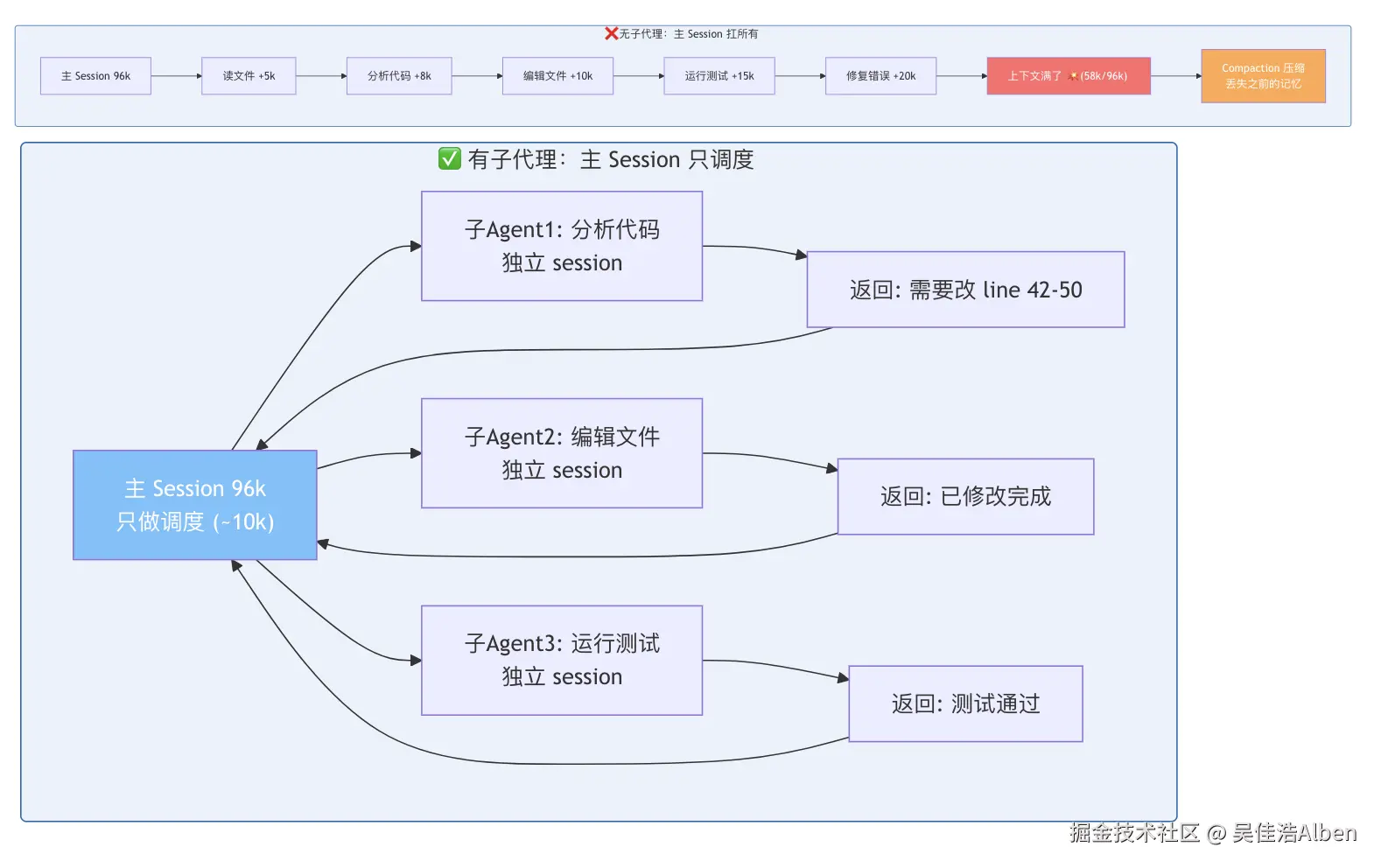
7.2 配合文件记忆
八、优化效果对比
真实数据
| 指标 | 优化前 | 优化后 |
|---|---|---|
| Compaction 次数 | 23 次 | 0-3 次 |
| Context Overflow 错误 | 频繁 | 无 |
| 工具调用次数(单任务) | 204 条消息 | 可控 |
| 任务完成率 | 极低 | 大幅提升 |
优化后的测试日志(子任务 session):
log
# 测试:读取 5 个核心文件 + 列目录 + 汇总报告
📚 Context: 43k/66k (65%)
🧹 Compactions: 0 ✅
Context Overflow: 0 ✅九、完整配置清单
一次性设置流程
PowerShell 命令汇总
powershell
# ===== Step 1: Ollama 环境变量 =====
[System.Environment]::SetEnvironmentVariable("OLLAMA_FLASH_ATTENTION", "1", "User")
[System.Environment]::SetEnvironmentVariable("OLLAMA_KV_CACHE_TYPE", "q8_0", "User")
# 然后右下角退出 Ollama → 重新打开
# ===== Step 2: 创建 96k 上下文模型 =====
"FROM qwen3.6:35b-a3b`nPARAMETER num_ctx 98304" | Out-File -Encoding utf8 C:\temp\Modelfile
ollama create qwen3.6-96k -f C:\temp\Modelfile
# 如果有第二个模型也一起创建
"FROM nemotron3:33b`nPARAMETER num_ctx 98304" | Out-File -Encoding utf8 C:\temp\Modelfile2
ollama create nemotron3-96k -f C:\temp\Modelfile2
# ===== Step 3: 验证 =====
ollama show qwen3.6-96k --modelfile
# 确认包含: PARAMETER num_ctx 98304
[System.Environment]::GetEnvironmentVariable("OLLAMA_FLASH_ATTENTION", "User")
# 应返回: 1
[System.Environment]::GetEnvironmentVariable("OLLAMA_KV_CACHE_TYPE", "User")
# 应返回: q8_0OpenClaw 配置汇总
| 参数 | 值 |
|---|---|
| 模型名 | qwen3.6-96k |
| contextWindow | 98304 |
| maxTokens | 8192 |
| API 模式 | ollama |
| API 地址 | 127.0.0.1:11434 |
| reasoning | true (low) |
| 子代理 | 开启 |
十、使用习惯建议
| ✅ 做 | ❌ 不做 |
|---|---|
| 每个任务新 session | 一个 session 干所有事 |
| 任务描述简短明确 | 写长篇大论的需求 |
| 让 Agent 按需读文件片段 | 一次让它读整个项目 |
| 复杂任务手动拆成 2-3 步 | 丢一个大任务让它自己搞 |
| 关键进度写 memory/ 文件 | 完全依赖对话记忆 |
| 定期检查 compaction 次数 | 不管不问直到任务失败 |
十一、故障排查速查表

十二、各显卡推荐配置
| 显卡 | 显存 | 推荐模型 | num_ctx | 预期表现 |
|---|---|---|---|---|
| RTX 4060 | 8GB | Qwen3:7B | 32768 | 简单任务 |
| RTX 4070 | 12GB | Qwen3:14B | 32768 | 中等任务 |
| RTX 4080 | 16GB | Qwen3:14B | 65536 | 大部分任务 |
| RTX 4090 | 24GB | Qwen3.6:35b-a3b | 65536 | 复杂任务 |
| RTX 5090 | 32GB | Qwen3.6:35b-a3b | 98304 | ⭐ 甜点配置 |
| 双卡 / 48GB+ | 48GB+ | Qwen3.6:35b-a3b | 131072 | 随意跑 |
总结
一句话总结: 上下文一定会用完,Context Compaction(上下文压缩)也无法真正避免,但真正决定 OpenClaw 上限的,从来不是"你有没有 8 卡 H100",而是你是否真正理解了 Agent 的运行本质。很多人以为本地 Agent 跑崩是因为模型太弱、显卡不够、参数太小,但实际上,大多数任务失败都发生在 Context 被反复压缩之后:历史状态开始丢失、工具调用结构逐渐污染、Memory 漂移、推理链断裂,最终整个 Agent 从"会思考"变成"会循环"。
Tips
你真正需要做的,并不是无止境堆硬件,而是学会控制整个推理系统:在 Ollama 侧正确对齐 num_ctx、开启 Flash Attention 与 KV Cache 优化、合理限制 maxTokens(8192)、减少无意义工具输出、强化 Prompt 约束、拆分子代理职责、控制 Session 生命周期,并尽可能降低上下文污染速度。因为对于 Agent 来说,稳定性远比瞬时智商更重要。
你会慢慢发现,一个真正稳定的 OpenClaw,并不是"最聪明"的那个,而是"最不容易失忆"的那个。上下文越长,不代表越强;能在有限 Context 内持续维持结构化推理能力,才是真正的核心竞争力。
所以请记住:不要让 OpenClaw 驯化你,不要被它的随机性牵着走,更不要在一次次上下文崩坏后怀疑自己的硬件。你真正要做的,是学会驾驭它、约束它、修正它、拆解它,然后一步一步建立属于你自己的 Agent 工作流。
条件有限不可怕,真正可怕的是不知道问题出在哪里。
从现在开始,跟着我一起,成为 OpenClaw 最严厉的父亲👨。