为什么要有 LSTM?
普通 RNN 有长依赖遗忘问题 :
序列很长时,梯度反向传播会梯度消失/梯度爆炸 ,RNN 记不住很早之前的信息,就像鱼的记忆只有7秒。
LSTM(长短期记忆网络) 就是为了解决:长序列记忆、梯度消失 问题,就像添加一个日记本,将记忆写到本子上。
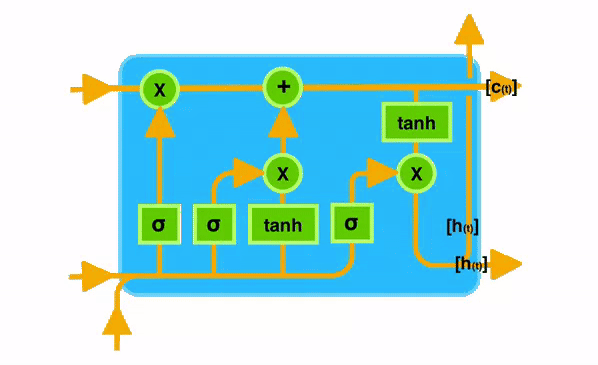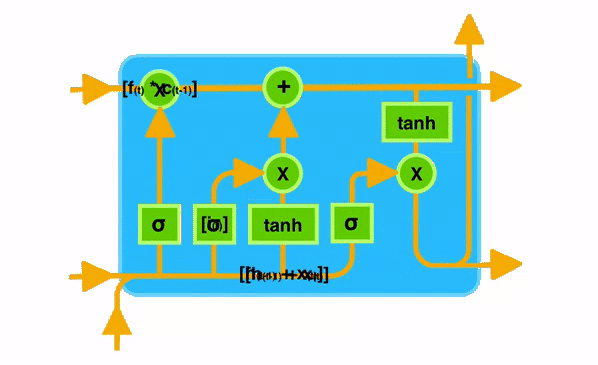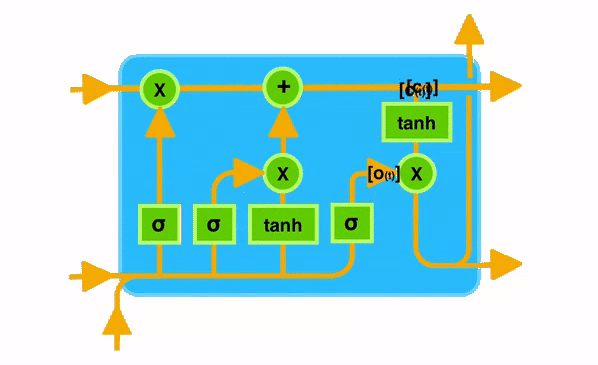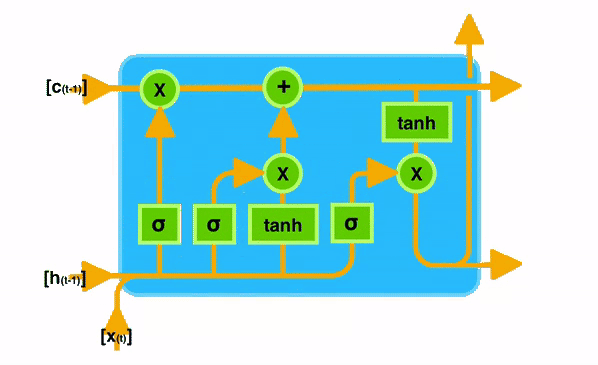
核心思想
LSTM 相比普通 RNN,多了一个细胞状态 Cell State(日记本)
- 细胞状态 C t C_t Ct:长期记忆,像一个日记本,信息改动很小
- 隐藏状态 h t h_t ht:短期记忆,当前时刻输出 或者是人的记忆
LSTM 靠三个门控制信息流动:
- 遗忘门 Forget Gate:丢掉旧记忆
- 输入门 Input Gate:存入新记忆
- 输出门 Output Gate:把记忆输出
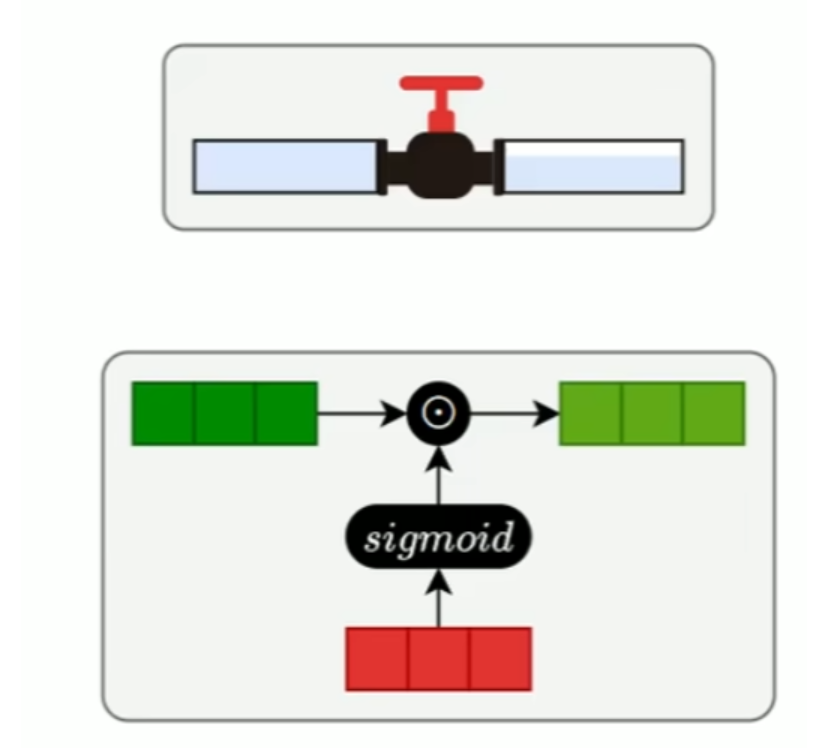
门结构
所有门都是 Sigmoid + 权重矩阵,输出 0~1:
- 1:完全保留信息
- 0:完全丢弃信息
逐模块拆解(公式+白话)
符号说明:
- x t x_t xt:当前时刻输入
- h t − 1 h_{t-1} ht−1:上一时刻隐藏状态
- C t − 1 C_{t-1} Ct−1:上一时刻细胞状态
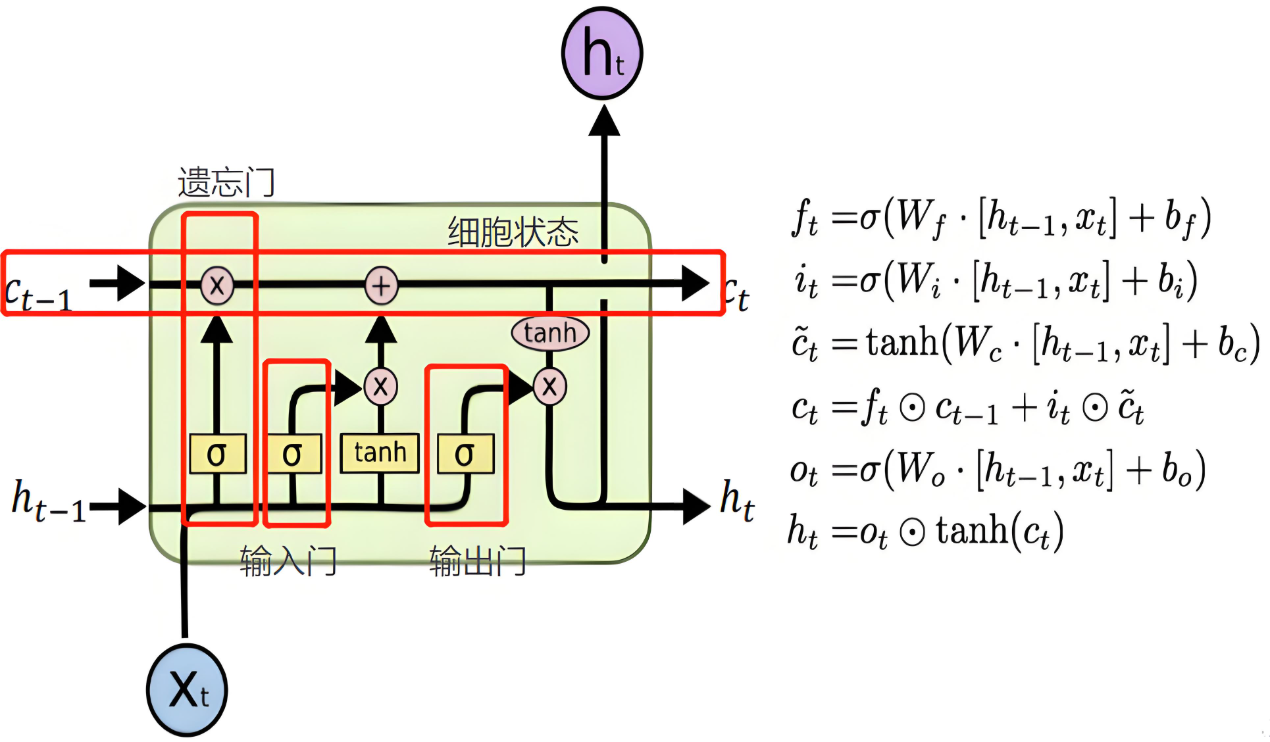
遗忘门 Forget Gate
作用:决定从上一时刻的长期记忆里丢掉哪些信息
σ \sigma σ:sigmoid 输出 0~1 和 旧细胞状态 C t − 1 C_{t-1} Ct−1 逐元素相乘,决定保留多少旧记忆
f t = σ ( W x f x t + b x f + W h f h t − 1 + b h f ) \Large f_t = \sigma(W_{xf}x_t + b_{xf} + W_{hf}h_{t-1} + b_{hf}) ft=σ(Wxfxt+bxf+Whfht−1+bhf)
输入门 Input Gate 存入新信息
输入门:决定哪些新信息要存入长期记忆
i t = σ ( W x i x t + b x i + W h i h t − 1 + b h i ) \Large i_t = \sigma(W_{xi}x_t + b_{xi} + W_{hi}h_{t-1} + b_{hi}) it=σ(Wxixt+bxi+Whiht−1+bhi)
候选记忆 C ~ t \tilde{C}t C~t:当前新生成的候选内容 用 tanh 把值缩放到 -1,1
C ~ t = tanh ( W x c x t + b x c + W h c h t − 1 + b h c ) \Large \tilde{C}t = \tanh(W{xc}x_t + b{xc} + W_{hc}h_{t-1} + b_{hc}) C~t=tanh(Wxcxt+bxc+Whcht−1+bhc)
更新细胞状态(核心传送带更新)
旧记忆过滤 + 新记忆写入
C t = f t ⊙ c t − 1 + i t ⊙ C ~ t \Large {C}t = f_t \odot c{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙ct−1+it⊙C~t
- ⊙ \odot ⊙:逐元素相乘
- 左边:保留的旧记忆
- 右边:新增的新记忆
输出门 Output Gate
作用:决定把长期记忆哪部分输出给当前隐藏状态
输出门控制
o t = σ ( W x o x t + b x o + W h o h t − 1 + b h o ) \Large o_t = \sigma(W_{xo}x_t + b_{xo} + W_{ho}h_{t-1} + b_{ho}) ot=σ(Wxoxt+bxo+Whoht−1+bho)
当前时刻隐藏状态输出
h t = o t ⊙ tanh ( C t ) \Large h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
极简流程
代码
import torch
import torch.nn as nn
# 固定随机种子,保证可复现
torch.manual_seed(42)
# 创建官方 LSTM 和自定义 LSTM
model = nn.LSTM(input_size=10, hidden_size=20, num_layers=1)
class MyLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# LSTM 权重:4*hidden_size 对应 遗忘门(f)/输入门(i)/细胞候选(g)/输出门(o)
# W_ix: (input_size, hidden_size),输入到隐藏层的权重
self.W_ix = model.weight_ih_l0 # 转置以匹配矩阵乘法维度
self.b_ix = model.bias_ih_l0 # 输入到隐藏层的偏置 (hidden_size,)
# W_hh: (hidden_size, hidden_size),隐藏层到自身的权重
self.W_hh = model.weight_hh_l0 # 转置以匹配矩阵乘法维度
self.b_hh = model.bias_hh_l0 # 隐藏层到自身的偏置 (hidden_size,)
def forward(self, x, hc):
# 获取记忆,获取笔记
h0, c0 = hc
h0 = h0.squeeze(0)
c0 = c0.squeeze(0)
# 词语一个个的循环处理
h_all = []
for i in range(x.shape[0]):
x_t = x[i]
# 输入和记忆 w 和 b
xi = x_t @ self.W_ix.t() + self.b_ix
hh = h0 @ self.W_hh.t() + self.b_hh
# 根据隐藏层,进行分割,获取四个门,获取四个门的输入
hx_h = xi + hh
i_hx, f_hx, g_hx, o_hx = torch.split(hx_h, self.hidden_size, dim=1)
# 处理4个门
# 输入门
i = torch.sigmoid(i_hx)
# 遗忘门
f = torch.sigmoid(f_hx)
# 候选细胞状态
g = torch.tanh(g_hx)
# 输出门
o = torch.sigmoid(o_hx)
# 笔记的只要一半
f0 = f * c0
# 需要记忆多少
ih = i * g
# 新笔记
c1 = f0 + ih
# 需要唤醒多少沉睡的记忆
h1 = o * torch.tanh(c1)
# 需要重新编程c0 和 h0,给下一个循环的单词使用
c0 = c1
h0 = h1
h_all.append(h1)
# 列表变张量
h_all_t = torch.stack(h_all, dim=0)
c1_t = c1.unsqueeze(0)
h1_t = h1.unsqueeze(0)
return h_all_t, (h1_t, c1_t)
mymodel = MyLSTM(input_size=10, hidden_size=20)
# 5个单词,3句话,10个维度
x = torch.randn(5, 3, 10)
# 1层,3句话 batch ,20隐藏层,,,第一个代表记忆,代表笔记本
hc = (torch.zeros(1, 3, 20), torch.zeros(1, 3, 20))
# 自己写的
mh_all, mhc = mymodel.forward(x, hc)
# 官方的结果
h_all, hc = model.forward(x, hc)
print(mh_all.shape)
print(h_all.shape)
print(mhc[0])
print(hc[0])
cha = torch.sum(torch.abs(mhc[0]- hc[0]))
print(cha)总结
LSTM 用遗忘门、输入门、输出门 三条开关,控制一条长期记忆传送带,有选择地忘记旧信息、存入新信息、输出有用信息,从而能处理长时序、记住久远依赖。