在互联网业务中,IP归属地查询已成为风控、内容本地化、广告投放等场景的基础能力。当业务流量达到每秒数千甚至数万请求时,简单的API调用方式会迅速暴露出性能瓶颈。如何设计一套高并发、低延迟的IP归属地查询架构,成为技术团队必须面对的课题。
高并发场景下的三大挑战
基于对多家互联网公司的技术调研,在日活千万级以上的业务中,IP归属地查询服务面临的核心痛点集中在三个方面:
第一,外部API调用延迟不可控 。直接调用公网API服务,单次查询耗时通常在30-80ms之间,在高并发下响应时间会进一步劣化,且依赖网络稳定性。
第二,数据一致性与更新时效的矛盾 。IP归属数据并非静态,运营商段位会定期调整,如何在保证查询性能的同时维持数据新鲜度,是架构设计的难点。
第三,突发流量下的系统稳定性 。秒杀、大促等场景下,IP查询请求可能瞬间飙升数倍,若缺乏有效的限流与降级机制,极易拖垮整个服务链路。
分层架构设计思路
解决上述问题,可以尝试"本地缓存 + 二级缓存 + 异步更新"的分层架构:
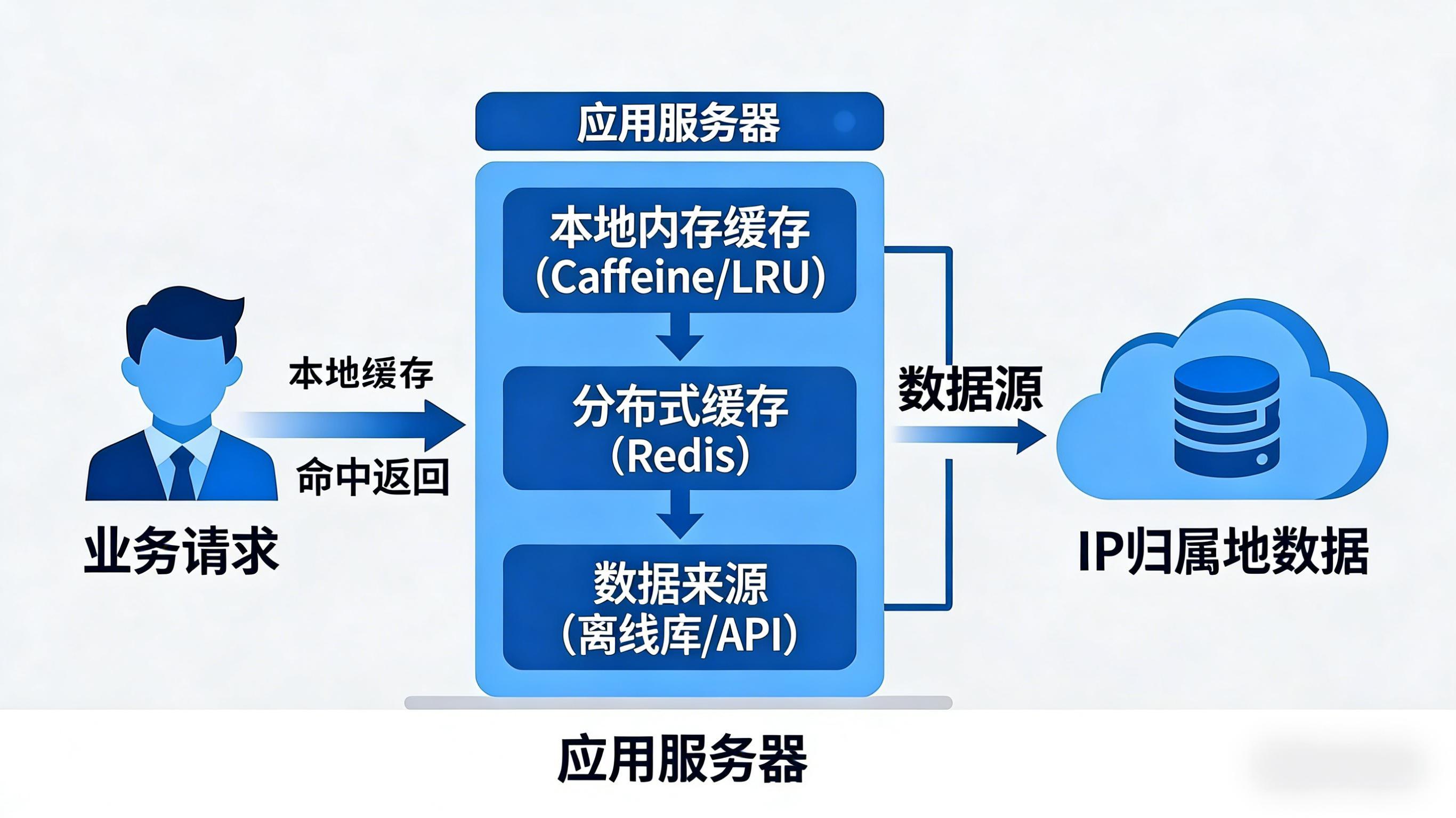
第一层:本地内存缓存 。使用Caffeine(Java)或lru_cache(Python)将热点IP的归属地信息缓存在应用服务器内存中。实测数据显示,本地缓存命中率可达70%-85%,命中后查询耗时降至0.2ms以下,直接避免了网络IO开销。
第二层:分布式缓存 。对于本地缓存未命中的请求,查询Redis集群,采用LRU淘汰策略控制内存占用。这一层的查询耗时约1-3ms,能承接剩余大部分请求。
第三层:数据源兜底 。仅当两级缓存均未命中时,才调用底层数据源。数据源可以是本地部署的离线IP库,也可以是外部的IP归属地API。
以下是一个基于Python的简单实现示例:
python
import redis
import hashlib
import json
from cachetools import LRUCache
class IPGeoService:
def __init__(self, redis_client):
self.redis = redis_client
self.local_cache = LRUCache(maxsize=10000) # 本地缓存
def get_location(self, ip: str) -> dict:
# 1. 本地缓存
result = self.local_cache.get(ip)
if result:
return result
# 2. Redis 缓存
result = self._query_from_redis(ip)
if result:
self.local_cache[ip] = result # 写入本地缓存
return result
# 3. 数据源
result = self._query_from_source(ip)
self.local_cache[ip] = result
return result
def _query_from_redis(self, ip: str) -> dict:
key = f"ipgeo:{hashlib.md5(ip.encode()).hexdigest()}"
data = self.redis.get(key)
if data:
return json.loads(data)
return None
def _query_from_source(self, ip: str) -> dict:
# 示例数据源逻辑
location = {
"country": "中国",
"province": "广东省",
"city": "深圳市"
}
key = f"ipgeo:{hashlib.md5(ip.encode()).hexdigest()}"
self.redis.setex(key, 86400, json.dumps(location))
return location限流与降级策略
在高并发场景下,必须为IP归属地查询服务设置多层防护:
令牌桶限流 :在服务入口处配置令牌桶算法,单机QPS上限根据下游承载能力设定。实测中,单机2000 QPS是本地库模式的安全阈值,超过后可通过排队或快速失败进行保护。
熔断机制 :当外部IP归属地API连续超时或返回错误超过阈值时,自动触发熔断,直接返回默认值或降级数据,避免故障扩散。
数据预热 :业务启动时,将高频IP段(如境内主要城市出口IP)预加载至本地缓存,避免启动初期的缓存击穿。
实测QPS数据与架构选型建议
在标准4核8GB云服务器环境下,我们对三种部署模式进行了压测:
|-----------|------------|-------------|----------------|
| 部署模式 | 平均响应时间 | 单机QPS上限 | 适用场景 |
| 直接调用外部API | 35-80ms | 300-500 | 低并发、对延迟不敏感 |
| 本地内存缓存 | 0.15-0.3ms | 8000+ | 热点集中、数据实时性要求不高 |
| 分层缓存架构 | 0.5-2ms | 5000+ | 高并发、兼顾性能与数据新鲜度 |
从数据可以看出,对于大多数互联网业务,分层缓存架构是是较为成熟的方案。它既利用了本地缓存的高性能,又通过分布式缓存解决了多节点数据一致性问题。
对于希望进一步降低运维复杂度的团队,可考虑集成 IP数据云 这类专业IP归属地查询平台。其提供的本地离线库支持毫秒级查询,单机QPS可达万级以上,同时具备自动更新的能力,将开发者从IP段维护和缓存设计的繁琐工作中解放出来,让业务团队更专注于核心逻辑。
写在最后
高并发场景下的IP归属地查询,核心在于平衡"性能"与"数据新鲜度"。通过分层缓存架构,配合合理的限流降级策略,可以轻松支撑万级QPS的查询需求。架构设计没有标准答案,建议根据业务的实际QPS预期和延迟容忍度,选择最适合的部署方案。