前言
在上一篇博客中,我们搭建了一个能回答问题的 RAG 系统。但你可能发现,面对复杂问题,它有时会"一本正经地胡说八道",或者检索不到关键信息。
这篇我们将深入 RAG 的核心,从最基础的 Native RAG 开始,逐步进阶到 GraphRAG 和 RAFT,看看如何把一个"半吊子"变成"专家"。
大模型系列系列目录(持续更新):
一、Native RAG:RAG 系统的标准流程
虽然我们在第一篇提到过 RAG,但为了进阶,我们需要更细致地审视 Native RAG(原生 RAG) 的每一个毛孔。它是所有高级 RAG 的基石。
以发生的"OpenAI CEO 山姆·阿尔特曼被解雇又复职"这一热点事件为例,Native RAG 的运作流程如下:
1.1 Native RAG的步骤
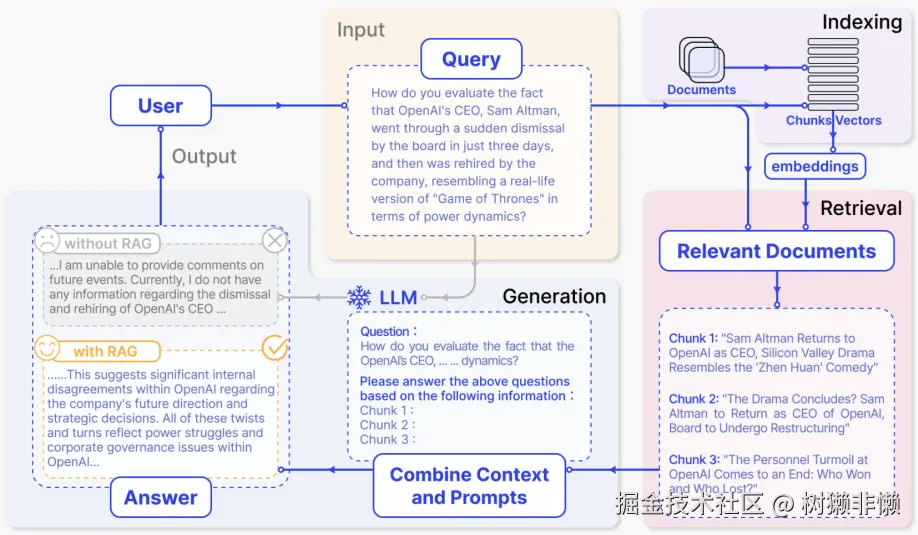
1.1.1 Input(输入)
用户提出一个问题(Query),例如:
"如何评价 OpenAI 首席执行官山姆·阿尔特曼在三天内被董事会突然解雇,随后又被公司重新聘回?这简直像现实版的《权力的游戏》。"
这个查询是整个流程的起点。
1.2.2 Indexing(索引阶段)------预处理知识库
这是系统部署前完成的离线过程,用于构建可检索的知识库。
- 文档(Documents):原始文本数据,如新闻报道、维基百科条目、公司公告、技术博客等。
- 分块(Chunking):将长文章切分成较小的语义段落。例如,一篇关于 OpenAI 人事变动的长文被切分为多个包含关键信息的段落。
- 嵌入(Embeddings):使用中文嵌入模型(如 BGE、text2vec 等)将每个段落转换为向量。
- 存储(Storage):将这些向量存入向量数据库(如 Milvus、FAISS 或阿里云 OpenSearch),支持高效语义检索。
📌 目标:建立一个结构化的中文知识库,让系统能根据语义快速找到与问题相关的资料。
1.2.3 Retrieval(检索阶段)
当用户提问时,系统执行以下操作:
- 将用户的 中文问题 转换为嵌入向量。
- 在向量数据库中查找语义最相近的几个文档片段。
- 返回最相关的若干个中文段落。
🔍 示例:
-
用户问:"阿尔特曼为何被解雇又复职?"
-
检索出的相关段落可能包括:
- "OpenAI 宣布山姆·阿尔特曼回归担任 CEO,此前他因与董事会在公司发展方向上存在分歧而被解雇。"
- "多位高管和员工联名要求董事会恢复阿尔特曼职务,否则将集体离职。"
- "微软介入协调后,双方达成和解,阿尔特曼重返 OpenAI。"
这一步确保大模型能基于真实、最新的中文信息作答。
1.2.4. Generation(生成阶段)
大语言模型(如通义千问、ChatGLM、文心一言等)接收增强后的提示进行回答。
带 RAG 的提示构造示例:
问题:如何评价 OpenAI 首席执行官山姆·阿尔特曼在三天内被董事会突然解雇,随后又被公司重新聘回? 请根据以下信息回答: 【段落1】OpenAI 宣布山姆·阿尔特曼回归担任 CEO,此前他因与董事会在公司发展方向上存在分歧而被解雇。 【段落2】多位高管和员工联名要求董事会恢复阿尔特曼职务,否则将集体离职。 【段落3】微软介入协调后,双方达成和解,阿尔特曼重返 OpenAI。
生成的回答可能为:
"这一事件反映出 OpenAI 内部在公司战略方向上存在严重分歧。董事会最初试图推动更注重安全性的路线,而阿尔特曼则主张加速产品迭代。员工的大规模抗议和微软的介入最终促使双方妥协,凸显了科技公司治理中创始人、董事会与核心团队之间的复杂权力博弈。"
1.2.5. 对比:有 RAG vs 无 RAG
| 场景 | 输出结果 |
|---|---|
| ❌ 无 RAG | "我无法评论近期事件......我的训练数据截止到 2024 年,不了解此事。" → 模型缺乏最新信息,只能回避。 |
| ✅ 有 RAG | 基于检索到的真实新闻,分析事件背后的公司治理、员工影响力和外部资本作用。 → 回答具体、有依据、时效性强。 |
二、RAG召回: 为什么你的 RAG 查不准?
在 Native RAG 中,召回(Retrieval)是第一步,也是最关键的一步。业内有一句行话:"Garbage in, Garbage out"(垃圾进,垃圾出)。
1.1 通俗理解
想象你问一个问题:"如何防止大模型产生幻觉?"
RAG系统不会直接让大模型凭空回答,而是先派一个"图书管理员"(即召回模块)去你的公司知识库、技术文档、维基百科等"图书馆"里,快速翻找和这个问题最相关的几段文字(比如"RAG原理介绍""幻觉缓解方案"等)。
这些被找出来的文字,就是"召回结果",之后才会交给大模型,让它基于这些真实资料来生成答案。
所以:
-
召回做得好 → 找到的资料准、全 → 大模型答得对;
-
召回做得差 → 找到一堆无关内容 → "垃圾进,垃圾出",哪怕大模型再强也白搭。
2.2 召回的核心目标
-
精准性:返回的内容必须和问题高度相关;
-
全面性:不能漏掉关键信息(高召回率);
-
效率:在毫秒级内完成,尤其面对百万级文档库;
-
适配生成:召回的片段要能直接用于大模型生成答案(不能太碎或太冗长)。
2.3 常见召回策略
2.3.1 多路召回(Multi-path Retrieval)
同时用多种方法找资料,比如:
- 向量检索(语义相似)
- 关键词检索(BM25)
- 图谱检索(基于实体关系)
- 假设性文档嵌入(HyDE)
2.3.2 查询优化(Query Rewriting)
用户问得模糊?系统自动改写问题,比如:
- "怎么提速?" → "如何提高深度学习模型训练速度?"
- 生成多个语义等价的查询变体,扩大搜索覆盖面。
2.3.3 Small-to-Big 召回
先用小文本块做高精度向量匹配,再映射回原始大段落,兼顾检索精度和上下文完整性。
2.3.4 重排序(Rerank)
初步召回几十条后,用更强的交叉编码模型(如 BGE-Reranker)精细打分,把最相关的前3~5条喂给大模型。
2.4 总结一句话
RAG 中的"召回",就是为大模型精准投喂"弹药"------找对了资料,答案自然靠谱;找错了,再强的模型也会"胡说八道"。
如果你正在搭建 RAG 系统,80% 的优化精力应该花在召回阶段。
三、GraphRAG: 解决复杂推理的神器
GraphRAG 是对传统 RAG(Retrieval-Augmented Generation) 的一种重要升级,其核心思想是:不仅利用原始文本片段进行检索,更通过构建知识图谱(Knowledge Graph)来捕捉实体、关系和高阶语义结构,从而实现更精准、更连贯、更具推理能力的问答与生成。
3.1 通俗理解
GraphRAG = RAG + 知识图谱(Graph-based Knowledge Representation)
它把文档中的信息"结构化"成图,用图的拓扑关系辅助检索与生成。
3.2 为什么需要 GraphRAG?
什么时候需要 GraphRAG?
Native RAG 擅长回答"是什么"(What),但面对"为什么"(Why)和复杂的关联关系时往往力不从心。
- 场景:如果用户问,"OpenAI 的这次动荡对微软的股价有什么间接影响?"
- Native RAG 的困境:文档里可能有"A 阿尔特曼被开除"和"B 微软是 OpenAI 投资者"两个片段,但它们是孤立的。模型很难把这两块孤立的碎片拼凑起来推理。
| 问题 | 传统 RAG 的短板 |
|---|---|
| 缺乏全局视角 | 只能基于局部文本片段回答,看不到跨文档的关联 |
| 难以处理复杂推理 | 比如"公司A收购了B,B的CEO是谁?"需要多跳推理 |
| 语义碎片化 | 文本块彼此孤立,无法体现"苹果(水果)" vs "Apple(公司)"的区别 |
| 召回依赖表面相似性 | 向量检索可能漏掉逻辑相关但词汇不同的内容 |
GraphRAG 的解法:
- 构建知识图谱:将文档转化为"节点"和"边"。例如:
[山姆·阿尔特曼] --(任职于)--> [OpenAI] <--(投资)--> [微软]。 - 图遍历:当用户提问时,系统不仅看文本相似度,还看图谱中的路径。它能发现"阿尔特曼"到"微软"之间隔着两跳关系。
- 生成:模型基于这张"关系网"生成答案,逻辑更连贯。
3.3 GraphRAG 的核心思想
-
从原始文档中抽取结构化知识
- 识别实体(人、组织、地点、概念等)
- 抽取关系("任职于"、"位于"、"导致"等)
- 构建知识图谱(节点=实体,边=关系)
-
在图上进行"图感知"的检索
- 不只是找相似句子,而是找相关实体及其邻居子图
- 支持多跳推理(例如:A → 关联 B → 关联 C)
-
将子图信息作为上下文输入大模型
- 把图结构(或图摘要)转换为自然语言提示
- 大模型基于结构化+非结构化信息生成答案
四、RAFT :训练一个"听话"的 AI
4.1 先理解两个关键词
1. 微调(Fine-Tuning)
- 大模型(比如你听说过的 ChatGPT、Qwen 等)一开始是在大量通用数据上训练的。
- 如果你想让它在某个特定任务(比如医疗问答、法律咨询)上表现更好,就需要用这个领域的数据对它进行"微调"------就像给一个已经会说话的学生,再专门教他医学术语一样。
2. 检索增强(Retrieval-Augmented)
-
检索 = 查找相关资料。比如你问"新冠疫苗有哪些副作用?",系统先去数据库里找出和这个问题最相关的几篇医学文章。
-
增强 = 把这些查到的信息"喂"给大模型,帮助它生成更准确、有依据的回答。
4.2 那 RAFT 是什么?
RAFT : 在微调的时候,也加入"检索到的信息"来训练模型。
传统微调:只给模型"问题 → 正确答案"这样的数据对。
RAFT 微调:给模型"问题 + 检索到的相关文档 → 正确答案"。
这样做的好处是:
-
模型学会依赖外部知识,而不是死记硬背训练数据。
-
回答更准确、可溯源(因为参考了真实文档)。
-
减少"胡说八道"(幻觉问题)。
4.3 RAG VS RAFT
RAFT 和 RAG 看起来确实很像,你的感觉很正常!
因为它们都做了"检索 + 生成"这件事。但关键区别在于:模型有没有在训练阶段"学会怎么用检索到的信息" 。
我们用一个生活化的比喻来帮你彻底搞清楚 👇
假设你要教一个孩子回答这样的问题:
问题 :企鹅会飞吗? 正确答案:不会,企鹅是鸟类但不会飞。
4.3.1 情况一:RAG(Retrieval-Augmented Generation)
-
你不专门训练孩子,只是每次他遇到问题时,你递给他一本百科全书,并说:"答案在这本书第23页,你自己看,然后回答。"
-
孩子可能:
- 能找到关键句子 → 答对 ✅
- 找错了段落、或看不懂 → 答错 ❌
- 甚至直接忽略书,凭记忆瞎猜(比如他说"鸟都会飞!")→ 幻觉 🤯
RAG 的核心 :模型本身没变,只是"临时给它查资料"。它没学过如何可靠地使用这些资料。
4.3.2 情况二:RAFT(Retrieval-Augmented Fine-Tuning)
-
你提前训练孩子很多次:每次给他一个问题 + 一段相关的百科文字,然后教他:"你要根据这段文字来回答,不能自己编!"
-
经过反复练习,孩子学会了:
- 只相信给的材料
- 忽略自己错误的常识(比如"鸟都会飞")
- 从文本中提取关键信息作答
RAFT 的核心 :模型被专门训练过,知道"我必须依据检索到的文档来回答",而不是靠内部记忆。
4.3.3 对比表
| 方面 | RAG | RAFT |
|---|---|---|
| 是否微调模型? | ❌ 不微调,用原始大模型 | ✅ 微调,教模型怎么用检索结果 |
| 模型是否"信任"检索内容? | 不一定,可能忽略或误解 | 学会了优先依赖检索内容 |
| 抗幻觉能力 | 一般(尤其当检索结果复杂时) | 更强(因为训练时就被约束) |
| 适用场景 | 快速部署、通用问答 | 高精度领域(如医疗、法律) |
| 实现成本 | 低(只需加个检索模块) | 高(需要标注数据 + 训练) |
4.3.4 举个容易出错的例子
问题:青霉素是谁发现的?
- 正确答案:亚历山大·弗莱明(1928年)
但假设检索系统不小心返回了一段错误文档,比如:
"居里夫人在1920年发现了青霉素。"
- RAG 模型:可能直接照着错误文档说"居里夫人",或者和自己记忆冲突后胡乱综合 → 容易出错。
- RAFT 模型 :虽然也会受错误文档影响,但它更倾向于忠实复述检索内容(这是训练目标),反而行为更可预测;而且如果训练数据里有"如何处理矛盾信息"的例子,它还能学会质疑。
当然,两者都依赖检索质量------垃圾进,垃圾出(GIGO)。但 RAFT 让模型"更听话、更守规矩"。
4.3.5 总结
RAG 是"边用边查",RAFT 是"先教会它怎么查、怎么用,再让它去用"。
就像一个是临时抱佛脚的考生,另一个是经过专项训练的答题高手。
五、结语:你的 RAG 进阶路线图
总结一下,构建一个强大的 RAG 应用,你可以按照以下路径升级:
-
起步:Native RAG(向量数据库 + 大模型)。
-
优化:加入 Rerank 模型,解决 80% 的查不准问题。
-
攻坚:
- 如果是复杂关系难题 →→ 上 GraphRAG。
- 如果是严肃专业领域 →→ 上 RAFT。