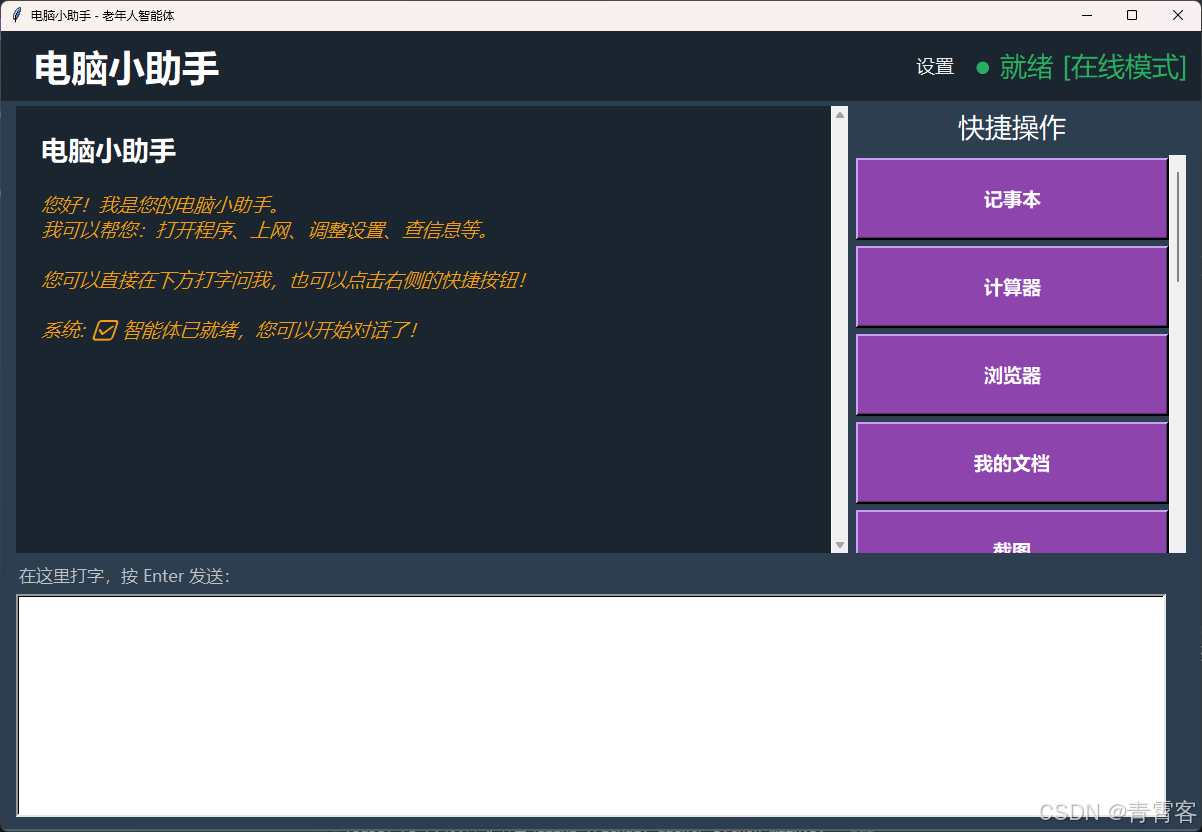
一个面向老年用户的智能体项目,从零写到能跑。不谈概念,只记过程和踩坑。
一、起因
家里老人用电脑,经常问我"怎么打开计算器"。我告诉她 Win+R,输入 calc,回车。她说找不到 Win 键。
后来我装了个 豆包 桌面版让她问,结果更糟------AI 回复"您可以按下 Windows 键加 R 键,然后输入 calc",她连 Windows 键在哪都不知道。
聊天机器人只能"说",但老年用户需要的是有人帮他们"做"。说一万遍"按 Win+R"不如直接把计算器打开。
这就是这个项目的出发点:做一个能动手的 AI。用户说"打开计算器",它直接 subprocess.Popen 把 calc.exe 启动起来,然后回一句"已为您打开计算器"。
二、架构:6 个文件,没框架
工具调用协议就是一行正则,调度逻辑不到 50 行,套一层 Chain 反而看不清数据流。
最后的项目结构:
main.py (224行) 入口,选 CLI 或 GUI 模式
main_gui.py (894行) tkinter 适老化桌面界面
agent.py (710行) 核心引擎:API 调用 + 工具调度
config.py (191行) 配置管理,三级优先级合并
prompts.py (136行) 系统提示词
tools.py (1629行) 46 个工具函数 + 注册表 + 执行引擎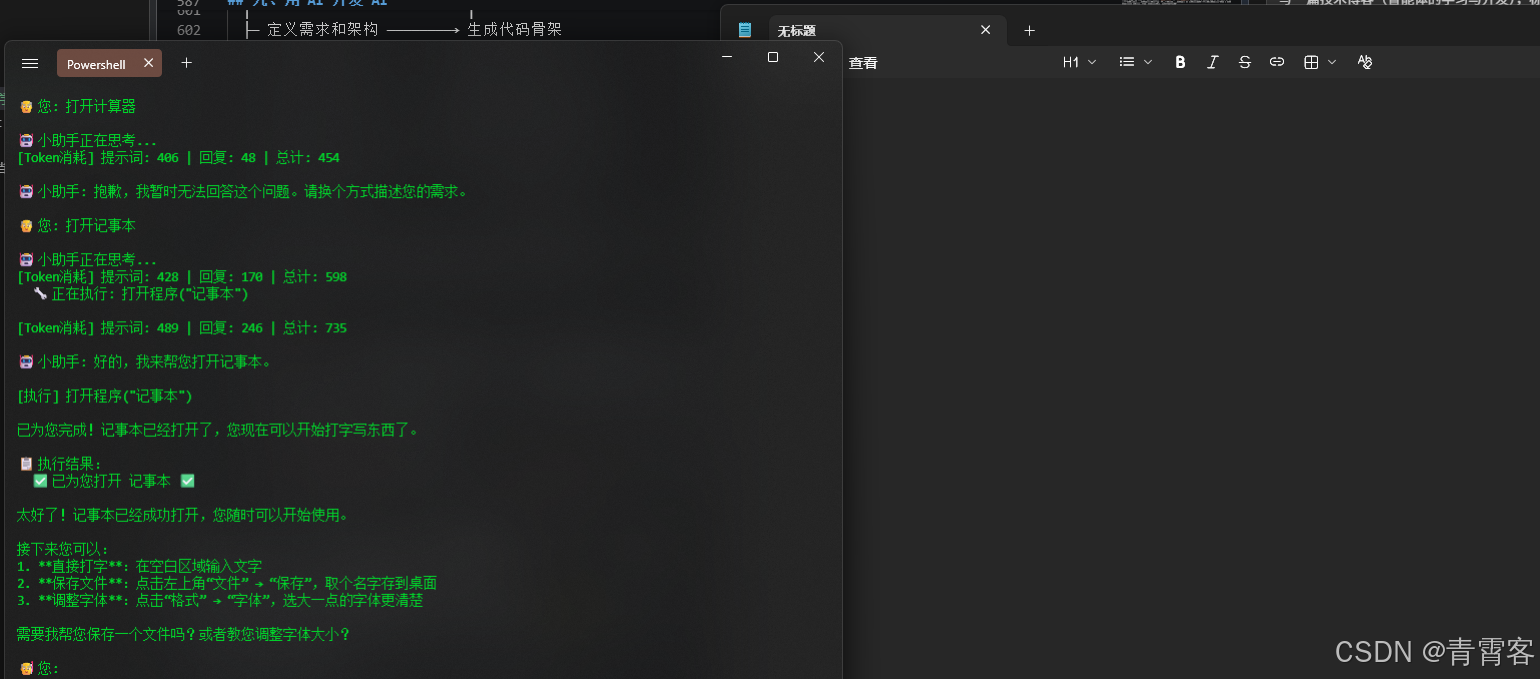
数据流:
用户输入 → agent.chat() → 远程大模型 API → AI 回复文本
↓
检测到 [执行] 标记 → tools.execute_tool()
↓
工具执行结果 → 反馈给 AI 再次推理 → 最终回复三、配置:三级优先级
config.py 191 行,处理一个问题:配置从哪来,谁说了算。
优先级:环境变量(最高) → settings.json → 代码默认值(兜底)
三级各有用处:代码默认值保证首次运行就能工作;settings.json 让用户持久化修改;环境变量给部署留口子。
核心就一个 load_settings() 函数:
python
def load_settings() -> dict:
global _settings_cache
# 懒加载
if _settings_cache is not None:
return _settings_cache
# 1. 代码默认值
defaults = {
"api_base_url": "https://api.siliconflow.cn/v1",
"api_key": _DEFAULT_API_KEY,
"model": "deepseek-ai/DeepSeek-V4-Flash",
"temperature": 0.3,
"max_tokens": 500,
"timeout_seconds": 60,
}
# 2. settings.json 覆盖(只合并已知 key,忽略无关字段)
if os.path.exists(SETTINGS_FILE):
with open(SETTINGS_FILE, "r", encoding="utf-8") as f:
file_cfg = json.load(f)
defaults.update({k: v for k, v in file_cfg.items() if k in defaults and v is not None})
# 3. 环境变量覆盖(最高优先级)
env_overrides = {
"api_key": os.getenv("API_KEY"),
"api_base_url": os.getenv("API_BASE_URL"),
"model": os.getenv("MODEL"),
"temperature": os.getenv("TEMPERATURE"),
"max_tokens": os.getenv("MAX_TOKENS"),
}
for key, val in env_overrides.items():
if val is not None:
# 类型转换:temperature→float, max_tokens/timeout→int
if key in ("temperature",):
defaults[key] = float(val)
elif key in ("max_tokens", "timeout_seconds"):
defaults[key] = int(val)
else:
defaults[key] = val
_settings_cache = defaults
return defaults几个细节:
-
_settings_cache做惰性加载,避免每次 API 调用都读磁盘。save_settings()修改配置后会清空缓存,下次load_settings()重新读取。 -
if k in defaults这行是白名单合并。settings.json 里如果混入了无关字段,不会污染运行时配置。这个坑我踩过------早期没做白名单,用户在 json 里加了个"备注": "测试用",结果运行时配置里多了个莫名其妙的 key。 -
首次运行时,如果 settings.json 不存在,
load_settings()会把默认值写进去,方便用户直接编辑文件修改。
temperature=0.3,max_tokens=500
这两个参数直接决定 token 消耗和成本。
temperature=0.3 是试出来的。0.7 的时候 AI 太"有创意","打开计算器"它能给你编一段计算器的历史。0.1 又太死板,稍微复杂点的请求就只会调工具不会解释。0.3 是个折中点------够确定,又不至于死板。
max_tokens=500 是硬性限制。老年用户不需要长篇大论,500 token 说清一件事加执行结果绰绰有余。
四、提示词:136 行,最关键的文件
prompts.py 行数最少,但改的次数最多。提示词写不好,后面所有代码都白搭。
系统提示词
python
SYSTEM_PROMPT = """你是老年电脑辅导老师,始终用中文回答。
核心原则:
1. 用最简单的话,避免术语
2. 操作拆解为步骤:1. 2. 3.
3. 保持鼓励语气,提醒防诈骗
4. 每段不超过3行,重要内容**加粗**
5. 主动帮用户操作电脑,不只给建议
你可以直接操作电脑!格式:
[执行] 工具名("参数")
常用工具:
- 打开程序("计算器|记事本|浏览器|微信|Word|Excel")
- 打开网站("网址") - 自动搜索或打开
- 系统信息() - 查看电脑配置
- 磁盘空间() - 查看剩余空间
- 截图() - 截屏保存到桌面
- 系统音量(0-100) - 调整音量
- 定时关机(分钟) / 取消关机()
- WiFi状态() / 网络诊断()
- 设置页面("显示|声音|网络|字体")
- 锁定屏幕() / 显示桌面()
- 放大镜() / 高对比度() / 字体大小(125)
- 清理垃圾() / 检查更新()
- 搜索文件("关键词") / 打开文件("路径")
- 关闭程序("程序名") / 任务管理器()
- 发送邮件() / 当前时间()
- 写脚本("文件名", "代码") / 运行脚本("文件名")
- 病毒扫描() / 紧急求助()
规则:
- 先说明要做什么,再用[执行]
- 执行后告诉用户"已为您完成"
- 危险操作先确认:"您确定吗?"
- 用户说"打开计算器"→直接执行打开程序("计算器")
- 用户说"电脑卡了"→执行任务管理器()或磁盘空间()
- 工具有结果时,基于结果给出建议"""[执行] 标记:最简陋但最可靠的协议
没用 OpenAI 的 function calling,没用 JSON Schema,让 AI 在回复文本里输出 [执行] 工具名("参数")。
为什么?这个项目用的是硅基流动的 DeepSeek-V4-Flash,走 OpenAI 兼容接口。不同模型对 function calling 的支持不尽相同,有的支持有的不支持,支持的程度也不一样。文本标记是所有模型都能理解的方式------只要提示词里写清楚格式和示例,模型就能稳定输出。
代价是解析要自己写。用正则匹配:
python
pattern = r'\[执行\]\s*([^(]+\([^)]*\))'
matches = re.findall(pattern, text)这个正则有局限------不支持嵌套括号的参数。但实际使用中 95% 的工具调用都是单参数,够用了。遇到解析失败的情况,execute_tool() 会返回错误信息,AI 下次会换个格式重试。
"规则"部分不是装饰
- 用户说"打开计算器"→直接执行打开程序("计算器")
- 用户说"电脑卡了"→执行任务管理器()或磁盘空间()精简版提示词
python
SYSTEM_PROMPT_MINI = """你是耐心细心的老年电脑辅导老师。始终使用中文回答。
规则:
- 用最简单的话,避免术语
- 操作拆解为步骤:1. 2. 3.
- 保持鼓励语气
- 提醒防诈骗
- 每段不超过3行
你能帮:打开程序、上网、邮件、系统设置、文件管理、连网、防诈骗。"""完整版约 400 token,精简版约 200 token。--mini 模式下每次 API 调用省 200 token。5 轮对话累计省 1000 token,看起来不多,但日积月累。而且精简版在弱模型上表现反而更稳定------信息密度高,模型不容易"发散"。
五、工具模块:46 个函数的注册和执行
tools.py 1629 行,是最大的文件。结构不复杂,但细节多。
统一返回格式
每个工具函数都返回三元组 (success: bool, message: str, data: any):
python
def open_application(app_name: str) -> tuple:
try:
subprocess.Popen(f'start "" "{cmd}"', shell=True)
return (True, f"已为您打开 {app_name}", None)
except Exception as e:
return (False, f"无法打开 {app_name}:{e}", None)为什么不用异常?因为工具的调用者是 execute_tool() 引擎,它需要把成功/失败统一汇报给 AI。用异常的话,每个工具的异常类型都不一样,引擎得写一堆 except。三元组让所有工具的结果处理变成一行代码。
中文名映射
python
APP_ALIASES = {
"计算器": "calc",
"记事本": "notepad",
"画图": "mspaint",
"浏览器": "msedge",
"微信": "wechat",
"此电脑": "explorer",
"谷歌浏览器": "chrome",
"word": "winword",
"excel": "excel",
"任务管理器": "taskmgr",
"放大镜": "magnify",
# ... 共 28 个
}
cmd = APP_ALIASES.get(app_name.lower(), app_name)老年用户不会说"打开 msedge",他们说"打开浏览器"。这个映射表就是自然语言到系统命令的桥梁。映射表里没有的,就直接把用户输入当命令试------兜底策略,有时候也能蒙对。
智能打开网站
python
def open_website(url: str) -> tuple:
if not url.startswith(("http://", "https://", "www.")):
if any(tld in url for tld in [".com", ".cn", ".org", ".net"]):
url = "https://" + url # "baidu.com" → "https://baidu.com"
else:
url = f"https://www.baidu.com/s?wd={quote(url)}" # "天气" → 百度搜索
webbrowser.open(url)用户可能输入三种东西:
www.baidu.com→ 直接打开baidu.com→ 补全 https 前缀后打开今天的天气→ 当搜索词,跳转百度
一个函数处理三种情况,零配置。用户不需要知道什么是 URL。
安全白名单
python
SAFE_PREFIXES = [
"dir", "ipconfig", "ping", "systeminfo", "tasklist",
"netstat", "whoami", "ver", "cls", "echo", "type",
"find", "where", "tree", "time", "date",
"chcp", "cd", "path", "prompt", "title", "color",
]
if cmd_lower not in SAFE_PREFIXES:
return (False, f"安全限制:命令 '{cmd_lower}' 不在允许列表中", None)execute_command() 是最危险的工具,直接执行 shell 命令。白名单只允许信息查询类命令。del、format、rd /s /q C:\ 这些永远不会出现在白名单里。
工具注册表
python
TOOL_REGISTRY = {
"打开程序": {
"function": open_application,
"description": "打开电脑上的应用程序",
"params": {"app_name": "程序名称,如:计算器、记事本、浏览器、微信、Word"},
"examples": ['打开程序("计算器")', '打开程序("记事本")'],
},
"系统信息": {
"function": get_system_info,
"description": "查看电脑系统信息(CPU、内存、磁盘、系统版本)",
"params": {},
"examples": ['系统信息()'],
},
# ... 46 个工具
}注册表干三件事:给提示词生成工具列表、给执行引擎查找函数对象、给 GUI 生成快捷按钮。一个字典,三个消费者。
执行引擎
这是整个工具模块最复杂的部分。AI 输出的是字符串 打开程序("计算器"),但 Python 需要调用 open_application(app_name="计算器")。中间的转换全靠 execute_tool():
python
def execute_tool(tool_call: str) -> tuple:
# 1. 解析工具名和参数
tool_match = re.match(r"^([^(]+)\(", tool_call)
tool_name = tool_match.group(1).strip() # "打开程序"
# 2. 智能括号匹配(支持嵌套括号和引号内的括号)
paren_depth = 0
in_single_quote = False
in_double_quote = False
# ... 逐字符扫描,找到匹配的右括号
# 3. 参数解析(支持多种格式)
# - JSON: {"app_name": "计算器"}
# - 位置参数: "计算器"
# - 多参数: "文件名", "内容"
# 4. 查找工具(支持模糊匹配)
if tool_name not in TOOL_REGISTRY:
matches = [name for name in TOOL_REGISTRY if tool_name in name]
if matches:
tool_name = matches[0]
# 5. 执行
result = tool_info["function"](**params)
return result参数解析是最容易出 bug 的地方。AI 可能输出 写脚本("hello.py", "print('你好')")------参数里有引号、有括号、有逗号。简单的 split(",") 会把 print('你好') 错误地分割。
六、核心引擎:对话管理 + 工具调度 + Token 控制
agent.py 的 ElderAgent 类,710 行,整个项目的心脏。
对话历史修剪
每次 API 调用都要发送完整的对话历史。10 轮对话后,光历史消息就可能消耗 2000+ token。不修剪,成本会线性增长。
python
MAX_HISTORY_ROUNDS = 5 # 超过 5 轮开始修剪
KEEP_RECENT_ROUNDS = 3 # 始终保留最近 3 轮
def _trim_history(self):
non_system_count = len(self.messages) - 1 # 排除 system 消息
max_non_system = MAX_HISTORY_ROUNDS * 2 # 每轮 = user + assistant = 2 条
if non_system_count > max_non_system:
to_remove = non_system_count - (KEEP_RECENT_ROUNDS * 2)
if to_remove > 0:
self.messages = (
[self.messages[0]] + # 保留系统提示词
self.messages[1 + to_remove:] # 保留最近的消息
)系统提示词永远保留,最早的消息优先丢弃,最近 3 轮始终保留。
工具调度流程
python
def chat(self, user_input: str) -> str:
# 1. 用户消息入队
self._add_message("user", user_input)
# 2. 调用大模型
reply = self._call_api()
self._add_message("assistant", reply)
# 3. 检测 [执行] 标记,执行工具
tool_executed = self._process_tool_calls(reply)
# 4. 如果有工具执行,把结果反馈给 AI 再次推理
if tool_executed:
tool_feedback = f"[工具执行结果]\n{tool_executed}"
self._add_message("user", tool_feedback)
follow_up = self._call_api() # 第二次 API 调用
if follow_up:
self._add_message("assistant", follow_up)
return reply + "\n\n" + tool_executed + "\n\n" + follow_up
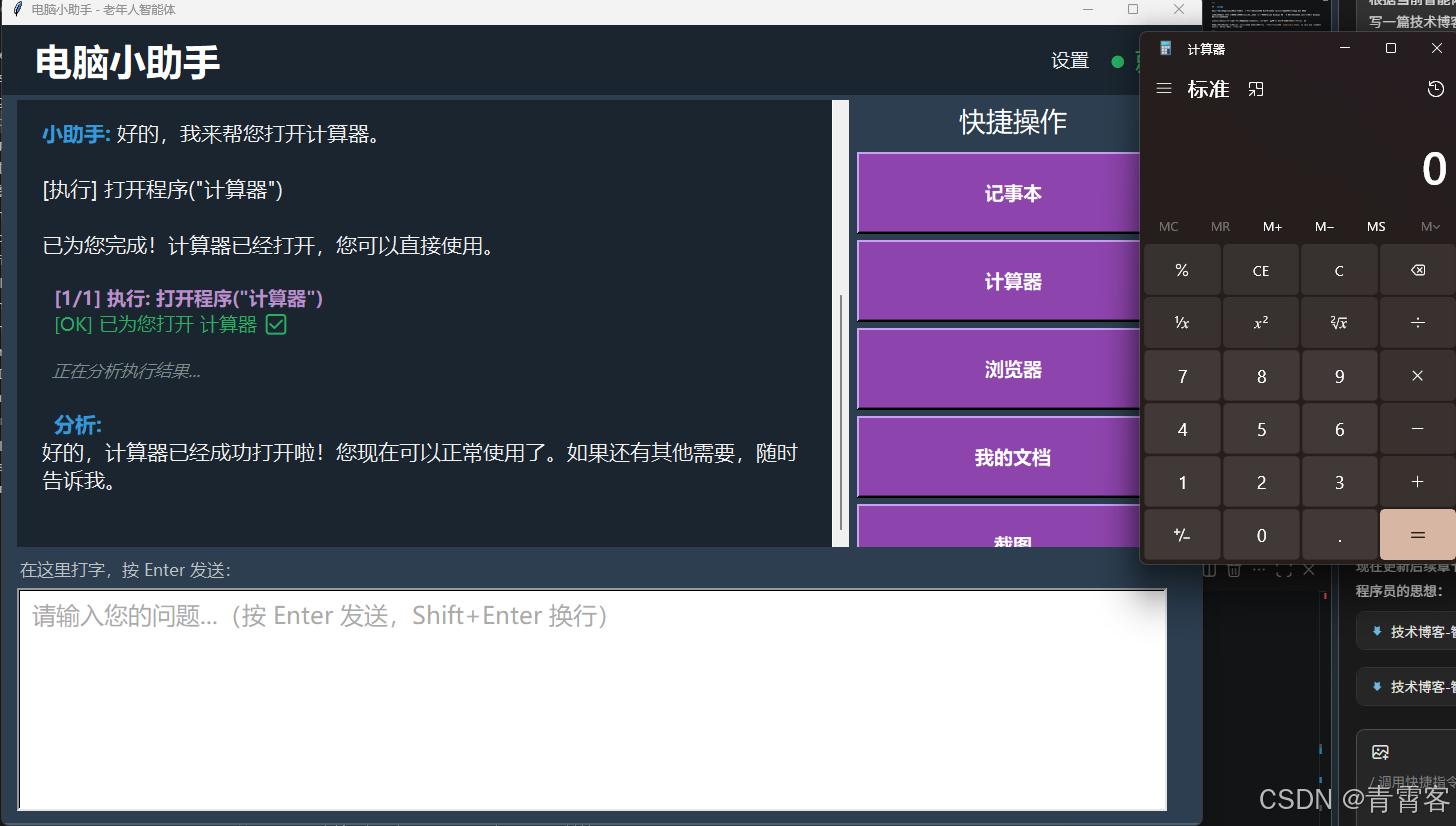
return reply第 4 步值得展开说明:工具执行后,AI 会再推理一次。这不是多余的。
用户说"电脑卡了",AI 第一次回复里调用 磁盘空间() 和 任务管理器()。工具返回"C 盘剩余 2GB"和"当前运行 87 个进程"。如果不做第二次推理,用户只看到一堆原始数据。第二次推理让 AI 把数据翻译成老年用户能懂的话:"您的 C 盘快满了,只剩 2GB,建议清理一下。我帮您打开磁盘清理工具?"
代价是多一次 API 调用。但这次调用的 prompt 很短(工具结果 + 短指令),token 消耗不大,换来的是用户体验的提升。
流式输出
chat_stream() 是 chat() 的流式版本,通过回调函数 on_event(event_type, data) 实时反馈:
python
def chat_stream(self, user_input: str, on_event=None):
# 思考阶段
on_event("thinking", {"status": "正在思考..."})
reply = self._call_api()
# 初步回复
on_event("reply", {"text": reply})
# 工具调用(逐个执行,逐个反馈)
for i, tool_call in enumerate(matches[:max_calls]):
on_event("tool_call", {"name": tool_call, "index": i + 1})
success, message, data = execute_tool(tool_call)
on_event("tool_result", {"success": success, "message": message})
# AI 基于工具结果的后续分析
on_event("thinking", {"status": "正在分析执行结果..."})
follow_up = self._call_api()
on_event("follow_up", {"text": follow_up})
# 完成
on_event("done", {"full_reply": full_reply})为什么用回调而不是生成器/async?tkinter 的线程模型决定的------所有 UI 操作必须在主线程,API 调用在后台线程。回调 + root.after() 是最简单的跨线程 UI 更新方式。用 async 固然更优雅,但 tkinter 不支持 asyncio 事件循环,硬整合反而更复杂。
一次最多执行 3 个工具
python
max_calls = 3
for i, tool_call in enumerate(matches[:max_calls]):
# ...七、适老化 GUI:tkinter 也能用
main_gui.py 894 行,纯 tkinter,零额外依赖。
选 tkinter 而不是 PyQt 或 Electron,原因:老年用户的电脑配置通常不高,PyQt 打包出来 80MB,Electron 更是 150MB 起步。tkinter 是 Python 自带的,打包后不到 20MB。
配色
python
COLORS = {
"bg": "#2C3E50", # 深蓝灰背景
"fg": "#FFFFFF", # 白色文字
"input_bg": "#34495E", # 输入框背景
"input_fg": "#FFFFFF", # 输入框文字
"button_bg": "#3498DB", # 按钮蓝色
"button_hover": "#2980B9",# 按钮悬停色
"urgent_bg": "#E74C3C", # 紧急按钮(红色)
"success_bg": "#27AE60", # 成功按钮(绿色)
"tool_bg": "#8E44AD", # 工具按钮(紫色)
"chat_bg": "#1A252F", # 聊天区域背景
"chat_user": "#2ECC71", # 用户消息标签色
"chat_ai": "#3498DB", # AI消息标签色
"header_bg": "#1A252F", # 顶部标题背景
}老年用户普遍视力下降,低对比度配色等于不可用。深色背景 + 白色文字 + 彩色按钮,每个元素都足够醒目。
字体
python
LARGE_FONT = ("微软雅黑", 28, "bold") # 标题
MEDIUM_FONT = ("微软雅黑", 20) # 副标题/标签
NORMAL_FONT = ("微软雅黑", 16) # 聊天区正文
SMALL_FONT = ("微软雅黑", 14) # 按钮
TOOL_FONT = ("微软雅黑", 14, "bold") # 工具栏微软雅黑是 Windows 预装字体中中文显示效果最好的无衬线体,不需要用户额外安装。
快捷工具栏
python
quick_tools = [
("记事本", '打开程序("记事本")'),
("计算器", '打开程序("计算器")'),
("浏览器", '打开程序("浏览器")'),
("我的文档", '打开文件("文档")'),
("截图", '截图()'),
("调大音量", '系统音量(60)'),
("调小音量", '系统音量(30)'),
("锁定屏幕", '锁定屏幕()'),
("30分后关机", '定时关机(30)'),
("取消关机", '取消关机()'),
("系统信息", '系统信息()'),
("磁盘空间", '磁盘空间()'),
("显示桌面", '显示桌面()'),
("放大镜", '放大镜()'),
("清理垃圾", '清理垃圾()'),
]这些按钮直接调用 execute_tool(),不经过大模型。用户点"计算器",1 秒内打开,零 token 消耗。只有通过输入框对话时才走 AI 推理路径。
快捷按钮适老化设计------不是所有操作都需要 AI 介入。高频操作直接做,低频操作才走对话。
线程模型
python
def _on_send(self):
self._sending = True
self.send_btn.configure(state=tk.DISABLED) # 防止重复发送
def process_stream():
# 在后台线程中调用 agent.chat_stream()
def on_event(event_type, data):
# 通过 root.after() 把 UI 更新推到主线程
if event_type == "thinking":
self.root.after(0, lambda: self._set_status("● 思考中..."))
elif event_type == "reply":
self.root.after(0, lambda: self._show_reply(data["text"]))
# ...
self.agent.chat_stream(user_input, on_event=on_event)
threading.Thread(target=process_stream, daemon=True).start()tkinter 不是线程安全的,直接在后台线程操作 UI 控件会崩溃。root.after(0, callback) 是标准做法------把回调"投递"到主线程的事件循环中执行。
八、用 AI 开发 AI
这个项目最有意思的地方是:我是用 AI 编程助手智能体来开发这个 AI 智能体的。
具体来说:
-
CodeArts Agent(华为云码道)和 AtomCode:负责代码生成、模块骨架搭建、bug 定位和修复。
tools.py里 46 个工具函数的框架,大部分是它根据我描述的功能需求逐个生成的,我再逐个审查和调整。execute_tool()的参数解析引擎最初也是它写的初版,后来重写了括号匹配逻辑来处理嵌套引号的边界情况。 -
Kimi(月之暗面 kimi-2.6):负责知识确认。写这篇博客的过程中,我让 Kimi 帮忙校验了几个技术细节------httpx 和 requests 在连接池管理上的差异、tkinter 线程安全的具体约束、DeepSeek-V4-Flash 的 token 计价方式。它的回答我没有直接采用,交叉验证后才写进来。
不是"AI 写了一切,我只是按了回车"。实际的工作模式:
我(人) AI 编程助手
│ │
├─ 定义需求和架构 ────────→ 生成代码骨架
│ │
├─ 审查代码逻辑 ←──────── 返回可运行的初版
│ │
├─ 发现边界问题 ────────→ 修复或重写特定函数
│ │
├─ 决策取舍(省token vs 完整性)← 不做这个决策
│ │
└─ 最终审查和测试 └─ 辅助但不决定人做决策,AI 做执行,人做审查以及大bug回退修改。这个循环比纯手写快了大概 3-4 倍,但比"全交给 AI"靠谱得多。AI 生成的代码 80% 可用,剩下 20% 的边界情况和架构决策必须人来把控。
工作方式的变化
| 以前 | 现在 | |
|---|---|---|
| 核心产出 | 代码量 | 架构决策 + 质量把控 |
| 工具角色 | 编辑器 | 协作者 |
| 瓶颈 | 编码速度 | 问题定义的清晰度 |
| 风险 | 写错代码 | 审查不严,让 AI 的错误混入 |
这个 3800 行的项目,纯手写可能要两周;用 AI 辅助,实际编码时间压缩到三四天。省下来的时间花在了更仔细的需求推敲、更充分的安全审查、和更完整的适老化测试上。
效率提升没有消灭工作,而是把工作推向了更高价值的环节。
九、一些数字
| 指标 | 值 |
|---|---|
| 总代码行数 | ~3800 行 |
| 工具数量 | 46 个 |
| 单次对话 token 消耗 | ~1500-1800(含工具调用) |
| 系统提示词 token | ~400(完整版)/ ~200(精简版) |
| 对话历史上限 | 5 轮(保留最近 3 轮) |
| 单次工具调用上限 | 3 个 |
| GUI 字体 | 28pt 标题 / 20pt 副标题 / 16pt 正文 / 14pt 按钮 |
| 依赖数量 | 3 个核心(httpx, rich, pyperclip) |
| AI 辅助开发工具 | CodeArts Agent + AtomCode + Kimi kimi-2.6 |
十、几点认识
技术演进史就是工具进化史。从打孔纸带到汇编,从高级语言到云原生,每一次跃迁都淘汰固步自封者,奖励拥抱新体系的人。AI 不是敌人,而是必须整合的工具。
我们不再是逐行敲代码的"打字员",而是指挥 AI 协同作战的"架构师"。学会拆解任务、审核统筹,这种思维转变比学会任何一门新语言都重要。
很多人抗拒改变------用 Vim、写 Shell、鄙视可视化操作。但 AI 已经写了很多代码,而且写得不错。坚持"纯手工编码"就像坚持手洗衣服,你花在写代码上的时间,别人用来看文档、思考架构、打磨软技能。时间久了,差距就出来了。
接纳 AI,不是当它的奴隶,而是把重复机械的工作交给它,腾出手来做只有人脑才能做的事。
AI 不会淘汰程序员,它淘汰的是不再进化的编程方式。这场抗争的核心,从来不是人与机器的对抗,而是旧自我与新自我的诀别。
别焦虑,但别躺平。别追风口,但别拒绝工具。长期投资自己,积累 AI 学不会的东西------判断力、审美、对复杂系统的理解、对人性的洞察。
本文原创,原创不易,如需转载,请联系作者授权。