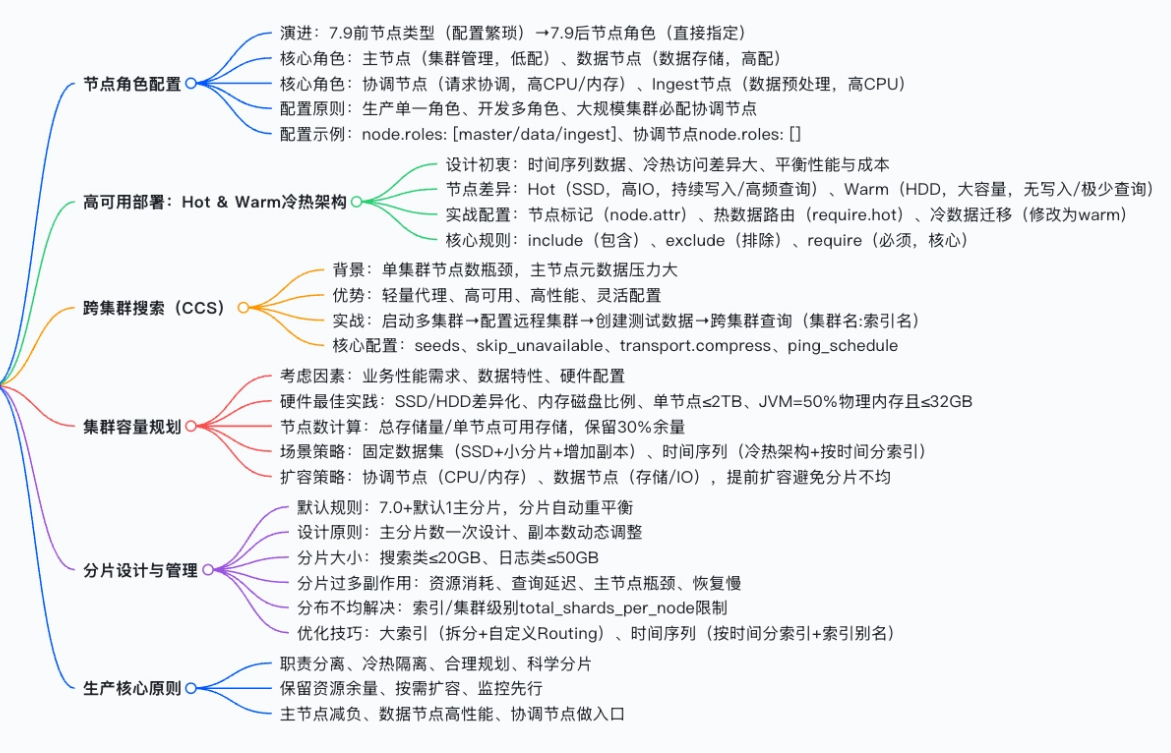
在 ElasticSearch(以下简称 ES)生产环境中,面对大规模数据存储、高并发查询及高可用的业务需求,简单的集群架构已无法胜任。ES 从 7.9 版本引入节点角色 概念,结合冷热架构 、跨集群搜索 、合理的容量与分片规划,形成了一套完整的生产级集群架构最佳实践。
本文将从节点角色配置、高可用部署、跨集群搜索、容量规划、分片设计与管理五大核心维度,为你拆解 ES 集群生产环境的落地要点。
一、节点角色配置方案:职责分离,各司其职
ES 7.9 版本前采用"节点类型"配置,需通过排除法定义节点;7.9 版本引入"节点角色"概念,通过 node.roles 直接指定职责,简化配置的同时实现了单一角色分离,是生产环境大规模集群的核心配置原则。
1. 角色演进与配置原则
- 版本差异 :7.9 前需繁琐配置
node.master/node.data;7.9+ 直接使用node.roles: [xxx]。 - 默认配置 :ES 8.X 若不手动配置,默认角色包含所有能力(
cdfhilmrstw),仅适用于开发环境。 - 生产环境铁律 :当集群节点数 > 6 个时,必须手动划分节点角色,避免职责混杂导致性能瓶颈。
2. 核心节点角色矩阵
| 节点角色 | 核心职责 | 性能配置要求 | 核心作用 |
|---|---|---|---|
| 主节点 (Master) | 集群管理、元数据维护、主分片选举 | 低配置 CPU、小内存、普通磁盘 | 保障集群基础运行,不参与数据存储/查询 |
| 数据节点 (Data) | 数据存储、检索、聚合、处理客户端数据请求 | 高配置 CPU、大内存、高速磁盘 (SSD) | 集群数据处理核心,承载所有数据读写操作 |
| 协调节点 (Coordinating Only) | 接收客户端请求、分发请求、聚合结果 | 高配置 CPU、大内存、低配置磁盘 | 充当负载均衡,避免复杂查询引发 OOM |
| 预处理节点 (Ingest) | 数据预处理(过滤、转换、清洗) | 高配置 CPU、中等内存、低配置磁盘 | 统一数据预处理逻辑,减少数据节点负担 |
3. 生产环境配置原则
- 单一角色原则:一个节点仅承担一种角色,避免资源竞争。
- 协调节点必配:大规模集群或存在复杂查询/聚合场景时,必须配置独立协调节点,作为客户端请求的唯一入口。
4. 核心配置示例 (YAML)
# 纯主节点配置node.roles:[master]
# 纯数据节点配置node.roles:[data]
# 纯协调节点配置(无任何实际业务角色)node.roles:[]
# 纯预处理节点配置node.roles:[ingest]二、高可用场景部署方案:读写分离与冷热架构
生产环境中,数据量激增与冷热数据访问频率差异大是常见痛点。Hot & Warm(冷热)架构是解决此类问题的核心方案,尤其适配日志、指标存储等时间序列数据场景。
1. 冷热架构核心设计
- 设计初衷 :时间序列数据(如日志)存在明显的访问频率差异。近期的热数据 (如近 7 天)写入/查询频率极高;历史的冷数据(如 3 个月前)几乎无写入、极少查询。
- 核心逻辑 :通过硬件隔离,热数据使用高性能硬件保障读写,冷数据使用大容量低性能硬件降低成本。
2. 冷热节点硬件配置差异
| 节点类型 | 硬件配置 | 数据特性 | 核心要求 |
|---|---|---|---|
| Hot (热节点) | SSD 磁盘、高配置 CPU、大内存 | 持续写入、高频查询 | 高 IO、高 CPU 处理能力 |
| Warm (温节点) | SATA/HDD 大容量磁盘、普通配置 | 无写入、极少查询 | 大存储容量,低成本 |
3. 架构实战:基于 Shard Filtering 实现数据迁移
核心依赖 ES 的 Shard Filtering(分片过滤)功能,分为三步:
(1) 步骤 1:标记冷热节点
通过 elasticsearch.yml 为节点添加自定义属性:
# 热节点标记node.attr.my_node_type: hot
# 温节点标记node.attr.my_node_type: warm验证命令: GET /_cat/nodeattrs?v
(2) 步骤 2:配置热数据 (分配到热节点)
创建索引时,指定索引必须分配到标记为 hot 的节点:
PUT /index-2024-05{
"settings": {
"index.routing.allocation.require.my_node_type": "hot"
}
}(3) 步骤 3:冷数据迁移 (迁移至温节点)
通过 API 动态修改旧索引的路由规则,无需重建索引:
PUT /index-2024-05/_settings{
"index.routing.allocation.require.my_node_type": "warm"
}4. 核心路由规则说明
| 路由规则 | 语法 | 说明 |
|---|---|---|
| 包含 (include) | include.${attr} |
索引分配到至少包含该属性值的节点 |
| 排除 (exclude) | exclude.${attr} |
索引不分配到包含该属性值的节点 |
| 必须 (require) | require.${attr} |
索引仅分配到包含该属性值的节点 |
三、ES 跨集群搜索 (CCS):解决单集群水平扩展瓶颈
ES 单集群的节点数无法无限增加,当集群元数据过多时,主节点会成为性能瓶颈。ES 5.3 版本引入跨集群搜索 (Cross Cluster Search, CCS,替代早期的 Tribe Node 方案。
1. CCS 核心优势
- 轻量级:无需加入其他集群,以代理方式转发请求。
- 高可用 :支持
skip_unavailable,忽略不可用远程集群。 - 高性能:支持传输压缩、自定义心跳检测。
2. 实战配置:三集群联合查询
(1) 步骤 1:配置跨集群参数
在所有集群中执行,添加远程集群信息(持久化):
PUT _cluster/settings{
"persistent": {
"cluster": {
"remote": {
"cluster0": {
"seeds": ["127.0.0.1:9300"],
"transport.ping_schedule": "30s"
},
"cluster1": {
"seeds": ["127.0.0.1:9301"],
"transport.compress": true,
"skip_unavailable": true
}
}
}
}
}(2) 步骤 2:跨集群联合查询
通过 ${集群名}:${索引名} 的语法指定跨集群索引:
GET /users,cluster1:users,cluster2:users/_search{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}(3) 核心配置参数说明
| 参数 | 作用 | 默认值 |
|---|---|---|
seeds |
远程集群的节点 IP:端口 | - |
transport.compress |
开启跨集群传输压缩 | false |
skip_unavailable |
远程集群不可用时是否忽略 | false |
max_connections_per_cluster |
单个远程集群的最大连接数 | 3 |
四、集群容量规划:从业务需求出发
容量规划是生产环境的前置核心工作,直接决定集群的稳定性与成本。核心是基于业务需求评估资源 ,并保留 30% 以上的资源余量。
1. 硬件配置最佳实践
- 磁盘选择 :
- 搜索类/高并发:SSD 磁盘。
- 日志类/低并发:SATA/HDD 磁盘。
- 内存与磁盘比例 :
- 搜索类:1:10 ~ 1:20。
- 日志类:1:48 ~ 1:96。
- 单节点数据量:建议 ≤ 2TB,最大不超过 5TB。
- JVM 配置:堆内存设置为物理内存的 50%,且不超过 32GB。
2. 不同业务场景的规划策略
- 固定大小数据集 (如电商商品):
- 策略:优先 SSD,单分片 ≤ 20GB,按业务维度拆分索引。
- 时间序列数据集 (如日志监控):
- 策略:采用 Hot & Warm 冷热架构,按时间维度创建索引,单分片 ≤ 50GB。
3. 集群扩容策略
| 扩容方向 | 解决的问题 |
|---|---|
| 增加协调/预处理节点 | CPU 和内存不足(复杂查询导致 CPU 满载、OOM) |
| 增加数据节点 | 磁盘存储容量不足、磁盘 IO 读写压力大 |
五、分片设计与管理:集群性能的核心优化点
分片是 ES 实现水平扩展和高可用的核心。不合理的分片设计是导致性能瓶颈的主要原因。
1. 分片设计核心原则
- 主分片数 (Primary :
- 一次设计,终身使用(创建后不可修改,除非 Reindex)。
- 搜索类:单分片 ≤ 20GB。
- 日志类:单分片 ≤ 50GB。
- 建议为主节点数的整数倍。
- 副本分片数 (Replica :
- 动态调整:高可用建议副本数 ≥ 1。
- 权衡:副本越多,查询吞吐越高,但写入性能越低。
2. 分片过多的副作用
- 资源消耗:CPU、内存、文件描述符消耗过高。
- 查询性能:单查询需遍历所有分片,增加延迟。
- 主节点负担:元数据管理压力大。
- 建议:集群总分片数应控制在 10W 以内。
3. 特殊场景优化技巧
- 大索引优化 :
- 拆分索引(按业务线/地区)。
- 启用自定义 Routing:
shard_num = hash(_routing) % num_primary_shards。
- 时间序列数据 :
- 按时间拆分索引 + 索引别名 (Index Alias) 管理最新索引。
六、生产最佳实践核心总结
ES 集群生产环境的搭建与优化,核心围绕 「职责分离、冷热隔离、合理规划、科学分片」 十六字原则:
- 节点角色:大规模集群必须实现单一角色分离,避免职责混杂。
- 高可用部署 :时间序列数据优先采用 Hot & Warm 冷热架构,平衡性能与成本。
- 跨集群搜索 :单集群节点数达瓶颈时,使用 CCS 替代 Tribe Node。
- 容量规划 :保留 30% 以上资源余量,按需扩容。
- 分片设计 :主分片数按未来 1~2 年业务增长设计,总分片数 ≤ 10W。
- 日常运维:监控分片分布,使用索引别名简化管理。