一、什么是Spark On Hive
Hive on Spark:Hive 为主,Spark 为辅。你用 Hive CLI/Beeline 写 HQL,Hive 解析优化,最后交给 Spark 跑任务。
Spark on Hive:Spark 为主,Hive 为辅。你用 Spark SQL/Spark 代码,Spark 自己解析优化,直接读 Hive 元数据和表数据。
目前Spark On Hive 是市场的主流
二、安装spark
1、上传spark-3.4.2-bin-hadoop3.tgz
cd /opt/modules2、解压
tar -zxf spark-3.4.2-bin-hadoop3.tgz -C /opt/installs3、重命名
cd /opt/installs
mv spark-3.4.2-bin-hadoop3/ spark5、配置环境变量:
vi /etc/profile.d/myenv.sh
export SPARK_HOME=/opt/installs/spark
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH刷新环境变量:
source /etc/profile2、测试使用
Spark Python Shell 是一个交互工具,可以启动spark中的交互工具,里面可以写代码
# 启动Python开发Spark的交互命令行
# --master:用于指定运行的模式,--master yarn
# local[2]:使用本地模式,并且只给2CoreCPU来运行程序
pyspark --master local[2]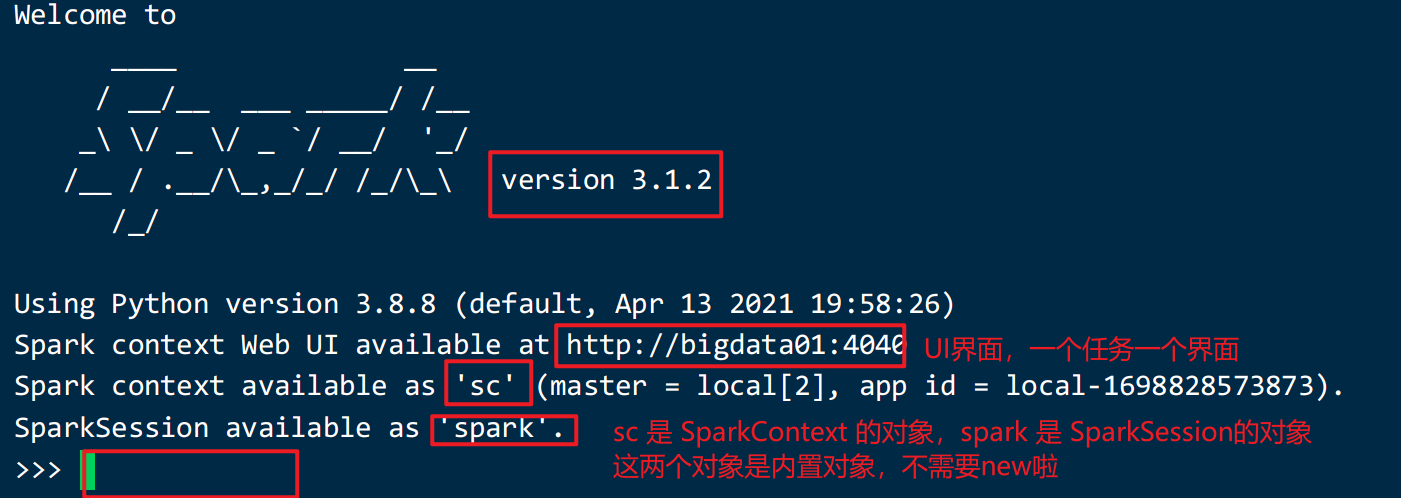
三、如何整合?
在hive 下修改hive-site.xml
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>将hive-site.xml 复制到 spark的conf 下
cp /opt/installs/hive/conf/hive-site.xml /opt/installs/spark/conf修改spark下的hive-site.xml
将之前的 10000 端口,修改为 10001 端口
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>假如报这个错误:
Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.error(SparkSubmitArguments.scala:650)
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:281)
at org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:237)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:122)
at org.apache.spark.deploy.SparkSubmit$$anon$2$$anon$3.<init>(SparkSubmit.scala:1094)
at org.apache.spark.deploy.SparkSubmit$$anon$2.parseArguments(SparkSubmit.scala:1094)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1111)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)修改配置文件,添加如下配置:
vi /etc/profile.d/myenv.sh
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile记得每次先启动 metastore 服务!!!
否则报如下错误:
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1742)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:83)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:133)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3607)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3659)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3639)
at org.apache.hadoop.hive.ql.metadata.Hive.getDatabase(Hive.java:1563)
... 30 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)thrift服务:
bash
/opt/installs/spark/sbin/stop-thriftserver.sh
bash
/opt/installs/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10001 \
--hiveconf hive.server2.thrift.bind.host=bigdata01 \
--master yarn \
--conf spark.sql.shuffle.partitions=2
假如报这个错误,是因为 spark 和 hive 的版本不兼容
org.apache.hive.service.cli.HiveSQLException: Error running query: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to fetch table ods_01_base_area. Invalid method name: 'get_table' at org.apache.spark.sql.hive.thriftserver.HiveThriftServerErrors$.runningQueryError(HiveThriftServerErrors.scala:43) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation.org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute(SparkExecuteStatementOperation.scala:261) at org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation$$anon$2$$anon$3.$anonfun$run$2(SparkExecuteStatementOperation.scala:165) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java: ...解决办法如下:
启动时指定 hive 的版本,将启动命令换成如下方式:
start-thriftserver.sh \
--conf spark.sql.hive.metastore.version=3.1.3 \
--conf spark.sql.hive.metastore.jars=maven \
--conf spark.sql.catalogImplementation=hive \
--conf spark.hadoop.hive.metastore.uris=thrift://bigdata01:9083 \
--conf spark.hadoop.hive.metastore.schema.verification=false \
--conf spark.sql.thriftServer.port=10001第一次因为要下载一些依赖的 jar 包,所以比较慢,成功后测试一下:
show tables;
select * from dog;
create table t_user1(
id int,
name string
)
row format delimited
fields terminated by ',';
load data local inpath '/home/hivedata/user.txt' into table t_user1;
select * from t_user1;四、编写一个启动脚本
接着我们编写一个 spark 远程服务启停脚本:
在/usr/local/bin 下创建一个脚本:spark-server-manager.sh
bash
#!/bin/bash
# 使用方式: spark-server-manager.sh [start|stop|]
help_info() {
echo "参数异常,请重新输入"
exit -1
}
# 获取操作命令
op=$1
# 检查参数是否正确
if [ ! $op ]; then
help_info
elif [ $op != "start" -a $op != "stop" ]; then
help_info
fi
# 开启服务
start_thrift() {
/opt/installs/spark/sbin/start-thriftserver.sh \
--conf spark.sql.hive.metastore.version=3.1.3 \
--conf spark.sql.hive.metastore.jars=maven \
--conf spark.sql.catalogImplementation=hive \
--conf spark.hadoop.hive.metastore.uris=thrift://bigdata01:9083 \
--conf spark.hadoop.hive.metastore.schema.verification=false \
--conf spark.sql.thriftServer.port=10001
}
# 停止服务
stop_thrift() {
sh /opt/installs/spark/sbin/stop-thriftserver.sh
}
# 控制操作
${op}_thriftchmod 777 spark-server-manager.sh
spark-server-manager.sh start
spark-server-manager.sh stop