 Apache Spark 4.0 正式发布了。这是 Spark 项目自诞生以来变化最大的一次版本升级------全新的 VARIANT 数据类型、原生 SQL UDF、重新设计的基础设施架构、以及对 Python 生态的全面增强。
Apache Spark 4.0 正式发布了。这是 Spark 项目自诞生以来变化最大的一次版本升级------全新的 VARIANT 数据类型、原生 SQL UDF、重新设计的基础设施架构、以及对 Python 生态的全面增强。
阿里云 EMR Serverless Spark当前已适配 Spark 4.0 ,企业用户可直接在生产环境使用这些能力,无需自建集群、无需手动升级、无需担心兼容性。
本文将介绍 Spark 4.0 带来的核心能力变革,以及 Serverless Spark 在此基础上为企业级场景做的额外增强。
一、Spark 4.0 带来了哪些核心新能力?
1. VARIANT 类型:JSON 半结构化数据处理性能提升数倍
这是 Spark 4.0 最值得关注的新特性,专门解决企业级数据平台中长期存在的半结构化数据处理痛点。
传统方案的局限性
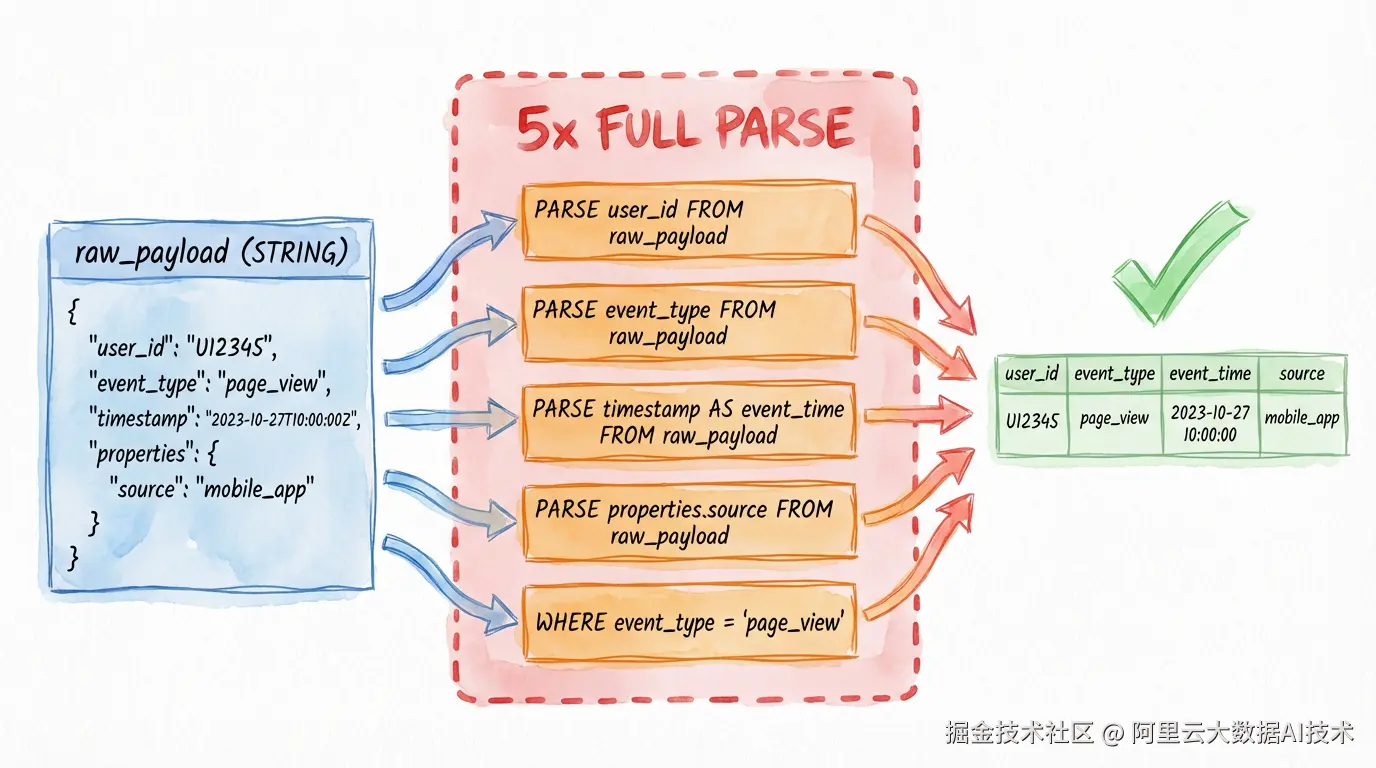
半结构化数据如 JSON 在 Spark 中常以 String 类型存储。这种方案具备开放和灵活的优点,但在查询性能方面存在明显问题,主要表现在两个方面:
-
无法应用结构化数据优化:JSON String 的数据类型无法应用到列式裁剪和谓词下推等结构化数据处理中最常用的优化手段
-
解析效率低下:在获取 JSON 中具体 key 对应数据时需要解析整个 JSON 对象(如 get_json_object)
sql
--传统方法:STRING 类型存储,查询时实时解析
CREATE TABLE user_events (
event_id BIGINT,
raw_payload STRING -- JSON 原文以字符串存储
);
-- 查询时需要反复解析
SELECT
get_json_object(raw_payload, '$.user_id') AS user_id,
get_json_object(raw_payload, '$.event_type') AS event_type,
get_json_object(raw_payload, '$.timestamp') AS event_time,
get_json_object(raw_payload, '$.properties.source') AS source
FROM user_events
WHERE get_json_object(raw_payload, '$.event_type') = 'page_view'
AND dt = '2025-03-15';该方案的核心问题:
-
性能损耗 :每次调用
get_json_object都需完整解析 JSON,取 N 个字段即解析 N 次 -
优化器无法介入:WHERE 条件中的 JSON 路径无法下推,需全量数据扫描后过滤
-
Schema 僵化 :若使用
from_json预定义结构体,上游字段变更将导致任务失败
Spark 4.0 的解决方案
Spark4 推出了 Variant 的数据类型,能够满足半结构化数据需要的开放(Open),灵活(Flexibel)和高性能(Fast)。
sql
-- Spark 4.0:VARIANT 类型存储
CREATE TABLE user_events (
event_id BIGINT,
payload VARIANT -- 二进制编码,自动索引
);
-- 数据写入时自动转换
INSERT INTO user_events
SELECT 1, parse_json('{
"user_id": "U12345",
"event_type": "purchase",
"timestamp": "2025-03-15T10:30:00",
"properties": {"source": "mobile_app", "amount": 299.99}
}');
-- 查询:路径表达式直接访问,简洁高效
SELECT
payload:user_id::STRING AS user_id,
payload:event_type::STRING AS event_type,
payload:properties.amount::DECIMAL(10,2) AS amount
FROM user_events
WHERE payload:event_type::STRING = 'purchase';
-- 单次解析,谓词可下推,无需全量扫描技术对比
| 维度 | STRING + get_json_object | VARIANT |
|---|---|---|
| 存储格式 | JSON 原文字符串 | 二进制编码 + 自动索引 |
| 查询性能 | O(N) 重复解析 | O(1) 路径定位 |
| 优化器支持 | 黑盒,无法下推 | 路径表达式参与谓词下推 |
| Schema 灵活性 | 需预定义或完全无结构 | 动态适应结构变化 |
| 语法简洁度 | 冗长的函数调用 | 直观的路径语法 |
企业级应用场景
-
用户行为埋点分析:埋点数据结构频繁变化,VARIANT 无需预定义 Schema,天然适配敏捷迭代
-
多源异构数据入湖:不同业务系统的 JSON 结构差异大,无需强行统一 Schema 即可入湖
-
API 日志存储与分析:RESTful API 的请求/响应体直接存储,按需提取字段,比预解析方案灵活数倍
2. SQL UDF:告别 Python UDF 性能瓶颈,SQL 原生函数优化
传统 UDF 的瓶颈
Spark 3.x 中封装可复用逻辑需使用 Python/Java UDF,但存在本质缺陷:
python
# Spark 3.x:Python UDF
from pyspark.sql.functions import udf
from pyspark.sql.types import DoubleType
@udf(returnType=DoubleType())
def calculate_discount(price, member_level):
rates = {1: 0.95, 2: 0.90, 3: 0.85}
return price * rates.get(member_level, 1.0)
# 优化器无法分析 UDF 内部逻辑:
# - 无法常量折叠
# - 无法谓词下推
# - 存在 JVM ↔ Python 跨进程开销
df.select(calculate_discount(col("price"), col("level")))Spark 4.0 SQL UDF
纯 SQL 定义函数体,优化器可直接内联展开并参与全局优化:
sql
-- 定义 SQL UDF
CREATE FUNCTION calculate_discount(price DECIMAL(10,2), level INT)
RETURNS DECIMAL(10,2)
RETURN CASE level
WHEN 1 THEN price * 0.95
WHEN 2 THEN price * 0.90
WHEN 3 THEN price * 0.85
ELSE price
END;
-- 支持函数组合
CREATE FUNCTION final_price(price DECIMAL(10,2), level INT, tax_rate DECIMAL(4,2))
RETURNS DECIMAL(10,2)
RETURN calculate_discount(price, level) * (1 + tax_rate);
-- 优化器将完全展开并应用所有优化规则
SELECT * FROM orders
WHERE calculate_discount(price, member_level) > 1000;表函数支持(返回多行):
sql
-- 生成日期序列
CREATE FUNCTION date_range(start_date DATE, end_date DATE)
RETURNS TABLE(dt DATE, day_of_week STRING)
RETURN SELECT day, date_format(day, 'EEEE')
FROM (SELECT sequence(start_date, end_date)) AS T(days)
LATERAL VIEW explode(days) AS day;
-- 直接使用
SELECT * FROM date_range(DATE'2025-01-01', DATE'2025-01-31');执行路径对比
plaintext
Python/Java UDF:SQL → 优化器(跳过) → 序列化 → 跨进程调用 → 反序列化
SQL UDF: SQL → 优化器(内联展开,完整优化) → 直接执行3. PySpark 增强:原生可视化、自定义数据源,Python 数据工程全面升级
Spark 4.0 针对 Python 生态进行了关键改进:
原生可视化 API
DataFrame 直接支持 .plot() 方法,服务端完成聚合后仅传输绘图所需结果:
python
# Spark 3.x:需先转 Pandas,大数据量易 OOM
df_summary = df.groupBy("region").agg(sum("revenue").alias("total")).toPandas()
df_summary.plot.bar(x="region", y="total")
# Spark 4.0:服务端聚合后直接渲染
df.groupBy("region").agg(sum("revenue").alias("total")) \
.plot.bar(x="region", y="total")Python Data Source API
Spark 4.0 新增 Python Data Source API,无需 Java/Scala,纯 Python 即可实现自定义数据源连接器,支持批量读写。以对接阿里云 OSS 上的 JSON 文件为例,只需实现三个类:
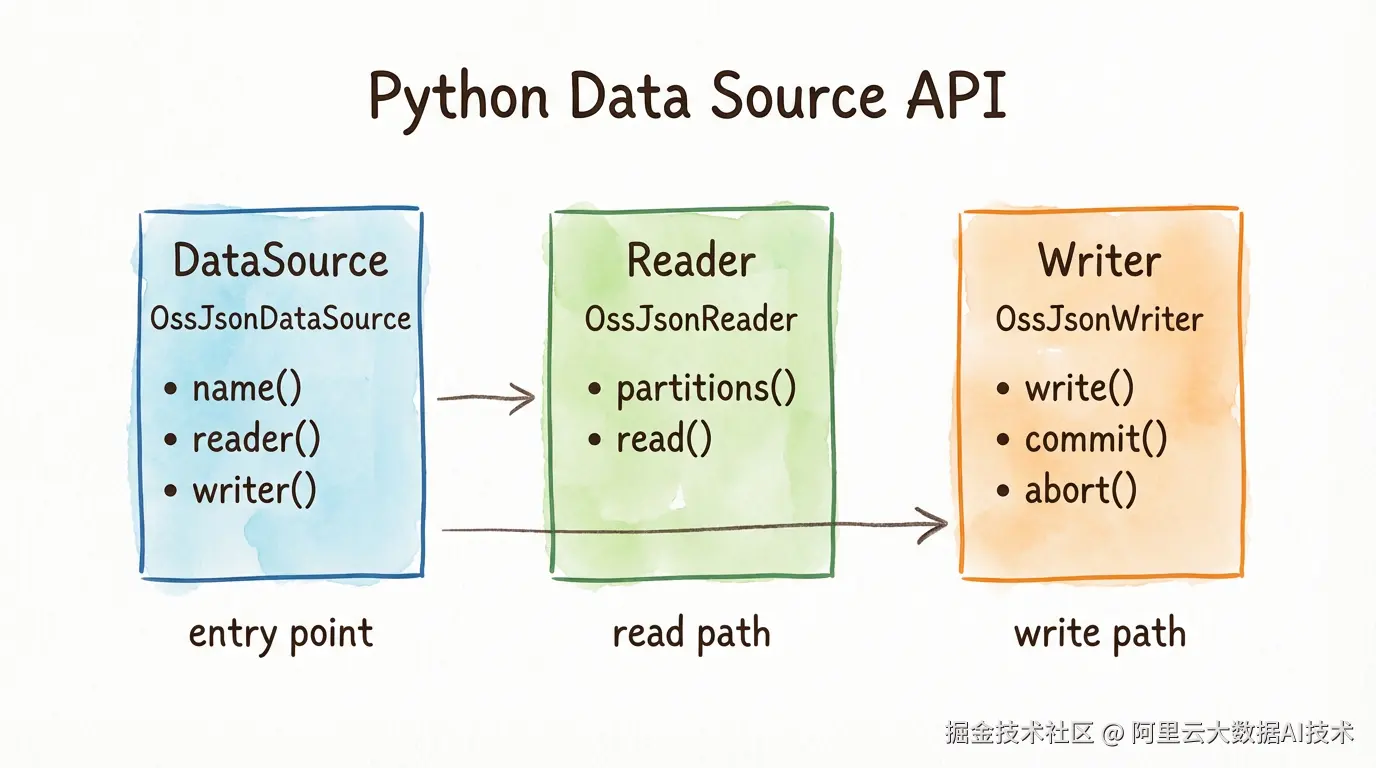
注册后,像使用 Parquet、CSV 一样使用自定义数据源:
python
spark.dataSource.register(OssJsonDataSource)
# 写入
df.write.format("oss_json").option("path", "data/events").mode("overwrite").save()
# 读取
spark.read.format("oss_json").option("path", "data/events").load().show()4. 性能提升 30%、管道语法与基础设施全面升级
整体性能提升
Spark 4.0 通过查询优化器改进、执行引擎优化和内存管理增强,在 TPC-DS 等基准测试中,相比 Spark 3.x 性能提升约 30%。
SQL 管道语法 |>
复杂查询的书写顺序与数据处理顺序一致:
sql
-- 传统写法:从内到外阅读
SELECT region, total FROM (
SELECT region, SUM(amount) AS total
FROM orders
GROUP BY region
) WHERE total > 100000
ORDER BY total DESC;
-- 管道语法:从上到下阅读
FROM orders
|> AGGREGATE SUM(amount) AS total GROUP BY region
|> WHERE total > 100000
|> ORDER BY total DESC;Structured Streaming 状态管理 v2
-
Arbitrary State API v2:单算子内管理多状态变量
-
State DataSource:直接读取和调试流状态数据
-
大幅降低有状态流处理的开发和运维复杂度
基础设施升级
| 组件 | Spark 3.x | Spark 4.0 |
|---|---|---|
| Scala | 2.12 | 2.13 |
| JDK | 8 / 11 | 17(支持 21) |
| Python | 3.8+ | 3.9+ |
二、阿里云 EMR Serverless Spark 在 Spark 4.0 上做了哪些增强?
Paimon Variant 深度适配
Serverless Spark 完成了 Spark 4.0 VARIANT 类型与 Apache Paimon 的深度集成。Paimon Variant 基于 Shredding 技术:
-
列式存储优化:高频访问字段自动提取为独立列,查询时直接列读取
-
谓词下推:过滤条件下推至存储层,显著减少 IO
-
类型安全:路径查询具备编译期类型推断
对于数据湖上的 JSON 密集型工作负载,Paimon Variant 配合 Spark 4.0 的 VARIANT 类型,提供了业界领先的存储 + 计算方案。
Fusion 向量化引擎:性能较开源 Spark 提升 3 倍
Fusion 引擎是 EMR Serverless Spark 内置的高性能向量化 SQL 执行引擎。在 TPC-DS 基准测试中,Fusion 相比开源 Spark 性能提升可达 3 倍。
我们已完成 Fusion 引擎对 Spark 4.0 的全面适配:
-
零代码改动,自动启用
-
支持 Spark SQL 和 DataFrame 任务
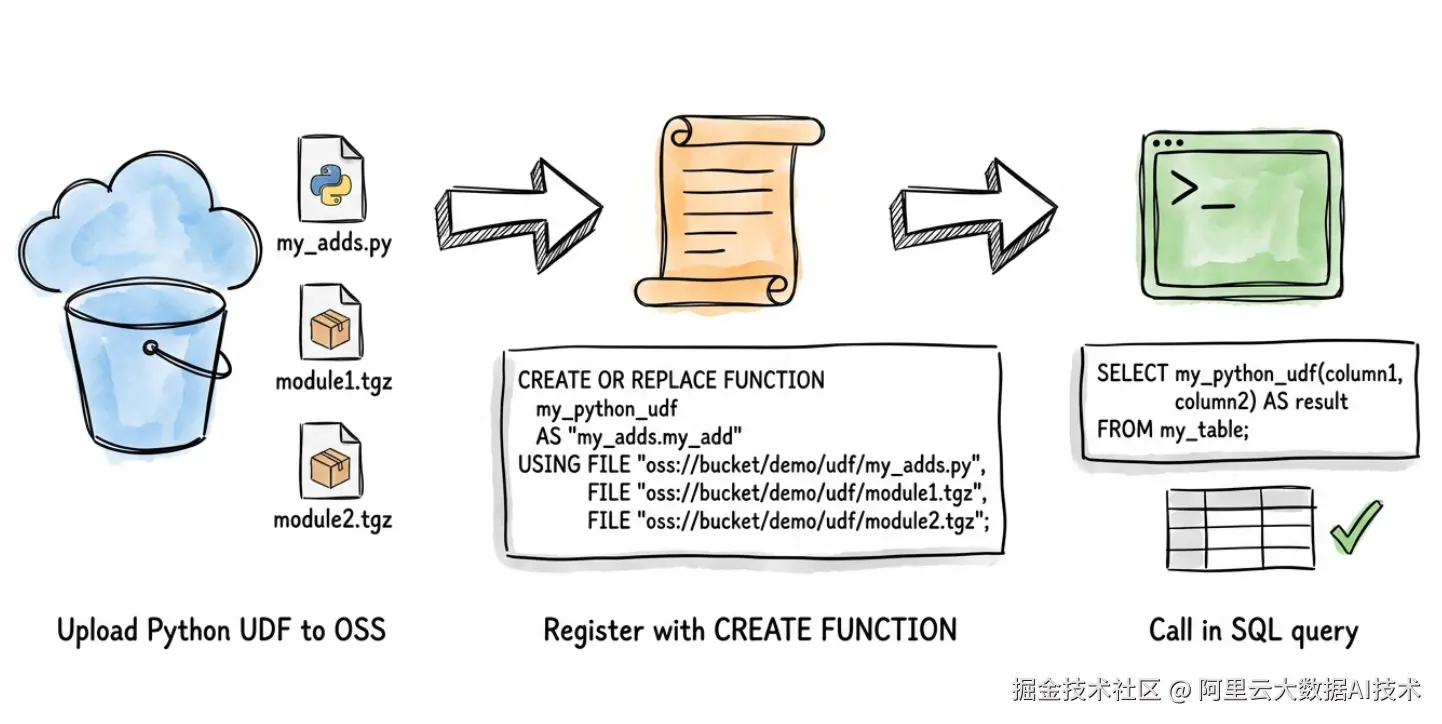
Python UDF 支持
支持通过 Python UDF 扩展 Spark SQL 功能,让企业能够使用 Python 生态灵活实现自定义业务逻辑
从 Spark 3 升级到 Spark 4:零改动平滑迁移方案
针对企业存量作业迁移痛点,阿里云 Serverless Spark 提供了平滑升级方案:
JDK 兼容性适配
Spark 4.0 弃用了 JDK 8,默认仅支持 JDK 17+。Serverless Spark 通过默认添加 JDK 参数,支持原生 JDK 8 编译的作业直接运行在 Spark 4.0 引擎上,无需重新打包:
-
自动识别作业编译时的 JDK 版本
-
运行时动态适配,无需用户干预
-
存量 JDK 8 作业零改动迁移
核心参数对齐
Spark 4.0 默认开启 ANSI SQL 模式(spark.sql.ansi.enabled=true),可能导致存量 SQL 出现兼容性问题。Serverless Spark 默认关闭 ANSI 模式:
-
保持与 Spark 3.x 一致的行为
-
存量作业无需修改即可正常运行
-
用户可根据需要手动开启 ANSI 模式享受严格类型检查