引言
在高并发编程中,我们经常需要操作共享的 Map 结构,比如缓存、计数器、分组聚合等。
一个常见的模式是:如果某个 key 不存在,就初始化一个值并放入 Map。
例如:
java
if (!map.containsKey(key)) {
map.put(key, new Value());
}这段代码在多线程环境下是线程不安全 的------两个线程可能同时检查到 key 不存在,然后都执行 put,导致后一个覆盖前一个,或者重复创建昂贵的对象。
加 synchronized 可以解决,但会降低并发度,让整个 Map 变成串行访问。有没有更好的办法?
Java 8 为 ConcurrentHashMap 引入的 computeIfAbsent 方法,正是为解决这类问题而生。
一、传统方式的痛点
先看一个典型场景:我们要实现一个缓存,从数据库加载用户信息,避免重复加载。
java
public class UserCache {
private final Map<Long, User> cache = new ConcurrentHashMap<>();
public User getUser(Long id) {
User user = cache.get(id);
if (user == null) {
user = loadFromDB(id); // 耗时操作
cache.put(id, user);
}
return user;
}
private User loadFromDB(Long id) {
// 模拟数据库查询
return new User(id, "name" + id);
}
}这段代码有什么问题?虽然使用了 ConcurrentHashMap,但 get 和 put 是两个独立的操作,不是原子的。
在高并发下,多个线程可能同时发现 cache 中没有某个 id,然后都去执行 loadFromDB,导致同一个用户被加载多次,甚至最后只有一个 put 成功,其他线程的加载结果被丢弃,造成资源浪费。
更糟糕的是,如果 loadFromDB 开销很大(比如网络请求),重复执行会严重影响系统性能。
加锁解决?
一种直观的想法是加锁:
java
public synchronized User getUser(Long id) {
User user = cache.get(id);
if (user == null) {
user = loadFromDB(id);
cache.put(id, user);
}
return user;
}但这将整个方法串行化,即使对于已经存在的 key,所有线程也必须排队等待,完全丧失了并发读的能力。显然不是好方案。
二、computeIfAbsent 登场
ConcurrentHashMap 提供了一个原子性的方法:
java
V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)- 作用:如果指定的 key 尚未与值关联(或映射为 null),则尝试使用给定的映射函数计算其值,并将其插入此映射,除非计算结果为 null。
- 原子性保证 :整个检查、计算、插入过程是原子的,由
ConcurrentHashMap内部通过细粒度锁或 CAS 机制保证,不会出现并发重复计算。
用 computeIfAbsent 改写上面的缓存:
java
public User getUser(Long id) {
return cache.computeIfAbsent(id, k -> loadFromDB(k));
}就这么简单!当多个线程同时调用 getUser(1L) 时,只有一个线程会执行 loadFromDB,其他线程会等待(或立即返回)那个计算好的值。既保证了安全,又避免了重复计算。
三、原子性保证的直观演示
为了更直观地理解 computeIfAbsent 的原子性,我们写一个小 demo:10 个线程同时向 Map 中放入同一个 key 的值,值是通过一个计数器生成的。
传统方式(不安全)
java
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
CountDownLatch latch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
Integer value = map.get("key");
if (value == null) {
value = 1; // 模拟计算
map.put("key", value);
}
latch.countDown();
}).start();
}
latch.await();
System.out.println("最终值: " + map.get("key"));多次运行,可能输出 1,也可能输出 null(由于 put 覆盖),无法保证最终结果。
使用 computeIfAbsent
java
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
CountDownLatch latch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
map.computeIfAbsent("key", k -> 1);
latch.countDown();
}).start();
}
latch.await();
System.out.println("最终值: " + map.get("key"));无论运行多少次,结果始终是 1,且只有一个线程执行了计算函数(我们可以在函数里加日志验证)。
computeIfAbsent 的工作原理
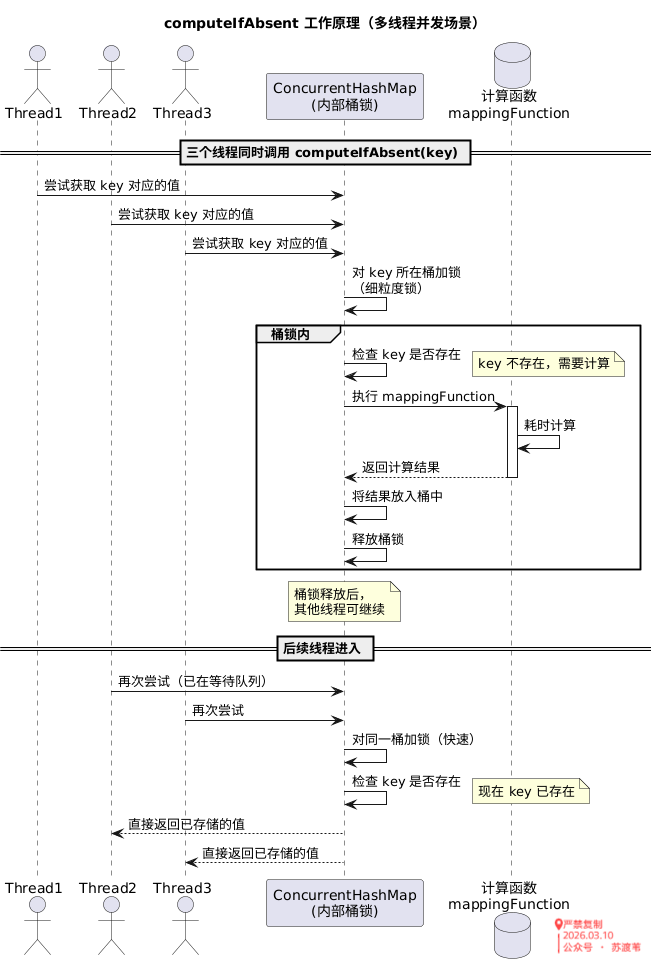
- 三个线程 同时调用
computeIfAbsent,试图获取同一个不存在的 key。 ConcurrentHashMap内部对 key 所在的桶(bucket)加细粒度锁(JDK 8 及以后采用 CAS + synchronized 对桶的首节点加锁),保证只有一个线程能进入临界区。- 成功获取锁的线程(Thread1)执行
mappingFunction进行耗时计算,在此期间,其他线程(Thread2、Thread3)会阻塞等待(或在 JDK 8 的循环中自旋等待)。 - Thread1 计算完成,将结果放入 Map,释放锁。
- 后续线程获得锁后,发现 key 已存在,直接返回已有值,不再执行计算函数。
四、注意事项(非常重要!)
虽然 computeIfAbsent 很好用,但用不对也会踩坑。
我们还是对照源码定义来说明:
java
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)1. 不要在 mappingFunction 中做耗时操作
computeIfAbsent 的内部实现会对 Map 的某个桶加锁(或使用 CAS 重试),如果 mappingFunction 执行时间过长,会阻塞其他线程对该桶的访问,导致并发性能急剧下降。
错误示例:
java
map.computeIfAbsent(key, k -> {
Thread.sleep(5000); // 模拟长任务
return loadFromDB(k);
});如果有多个线程访问同一个桶的不同 key,它们都会被阻塞,等待这个长任务完成。
正确做法 :mappingFunction 应只做轻量级计算。如果需要耗时操作(如 RPC、数据库查询),可以在函数内异步提交任务并返回 Future,或者使用其他机制(如 LoadingCache)。
2. mappingFunction 不能返回 null
如果 mappingFunction 返回 null,computeIfAbsent 会抛出 NullPointerException。因为 ConcurrentHashMap 不允许 null 作为 key 或 value。
解决方案 :如果确实不想存储值,可以返回一个占位符(如 Optional 或自定义的 NULL 对象),或者使用 compute 方法(允许返回 null 来删除条目)。
3. 小心递归调用
在 mappingFunction 内部再次调用同一个 Map 的 computeIfAbsent 可能导致死循环或 StackOverflowError。例如:
java
map.computeIfAbsent("key", k -> map.computeIfAbsent("anotherKey", k2 -> 1));这种行为是未定义的,应该避免。
4. mappingFunction 应保证幂等性
虽然 computeIfAbsent 保证函数最多执行一次,但如果因为异常等原因执行失败,不会留下映射。因此函数应该是幂等的,不会因为多次执行而产生副作用。
五、应用场景举例
1. 缓存懒加载
这是最经典的应用。例如从数据库加载用户信息:
java
public class UserService {
private final ConcurrentHashMap<Long, User> cache = new ConcurrentHashMap<>();
public User getUser(Long id) {
return cache.computeIfAbsent(id, this::loadFromDB);
}
private User loadFromDB(Long id) {
// 实际查询数据库
return userRepository.findById(id);
}
}这样,每个用户只会被加载一次,后续请求直接从缓存获取。
2. 分组计数(累加器)
假设需要统计每个分类下有多少个商品,多个线程并发上报商品分类:
java
ConcurrentHashMap<String, AtomicInteger> countMap = new ConcurrentHashMap<>();
public void increment(String category) {
countMap.computeIfAbsent(category, k -> new AtomicInteger(0))
.incrementAndGet();
}注意:这里 computeIfAbsent 返回的是 AtomicInteger,然后对其做原子递增。
如果使用 compute 直接操作 Integer 会更新整个映射,但 computeIfAbsent + 可变对象更高效。
3. 限流计数器(基于 key 的滑动窗口)
例如对每个 IP 进行访问频率限制,可以使用 computeIfAbsent 初始化计数器窗口:
java
ConcurrentHashMap<String, Deque<Long>> accessRecords = new ConcurrentHashMap<>();
public boolean tryAcquire(String ip) {
Deque<Long> records = accessRecords.computeIfAbsent(ip, k -> new ArrayDeque<>());
synchronized (records) { // 需要对 Deque 加锁
long now = System.currentTimeMillis();
// 移除超过时间窗口的记录
records.removeIf(time -> now - time > 1000);
if (records.size() < 10) {
records.addLast(now);
return true;
}
return false;
}
}虽然需要对 Deque 单独加锁,但 computeIfAbsent 保证了每个 IP 对应的队列只被创建一次,且线程安全地放入 Map。
4. 缓存计算结果
例如计算斐波那契数列,避免重复递归:
java
ConcurrentHashMap<Integer, Integer> fibCache = new ConcurrentHashMap<>();
public int fib(int n) {
if (n < 2) return n;
return fibCache.computeIfAbsent(n, k -> fib(k-1) + fib(k-2));
}但这里递归调用需要注意死循环,不过对于斐波那契是安全的。
六、总结
computeIfAbsent是 ConcurrentHashMap 提供的高并发初始化利器,它原子性地完成了"检查-计算-插入"三步,避免了并发下的重复计算和覆盖。- 相比外部同步,它只在必要时加锁,粒度更细,性能更高。
- 使用时要牢记注意事项:mappingFunction 应轻量、幂等、不返回 null,并避免递归。
七、代码在哪?
本篇涉及到的代码已上传至 GitHub:
https://github.com/iweidujiang/java-tricks-lab
欢迎 star & fork!