一、前言
在前面的卷积相关内容中,我们已经逐步弄明白了:
-
为什么图像任务要用卷积
-
卷积核如何在图像上滑动
-
卷积层为什么是可学习的
-
padding 和 stride 如何控制输出尺寸
不过前面为了方便理解,我们大多数例子都做了一个简化假设:
输入只有一个通道,输出也只有一个通道。
这在入门阶段很自然,因为这样公式和代码都更简单。
但真实世界里的图像往往不是单通道的。
比如一张 RGB 彩色图像通常有三个通道:
-
Red
-
Green
-
Blue
而在卷积神经网络中,一层卷积输出后,往往也不止一张特征图,而是很多张。
这些特征图叠在一起,就形成了新的"多通道表示"。
所以这一节"多输入多输出通道"的核心,就是要回答两个非常重要的问题:
1. 多输入通道怎么卷积?
2. 多输出通道又是怎么来的?
这一节是理解 CNN 真正结构的关键一步。
二、先回顾:什么叫通道(Channel)
在图像和卷积网络中,"通道"这个词特别常见。
最直观的理解是:
通道就是同一空间位置上的不同特征平面。
例如:
1. 灰度图
只有一个通道。
每个像素位置只有一个数值,表示亮度。
2. RGB 彩色图
有三个通道。
每个像素位置有三个值,分别表示:
-
红色强度
-
绿色强度
-
蓝色强度
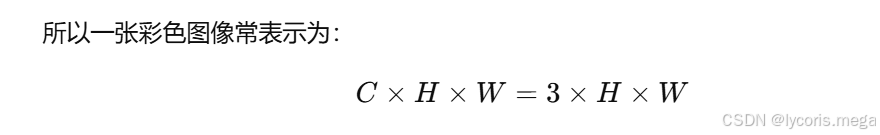
也就是:
-
3 个通道
-
每个通道都是一个二维矩阵
三、为什么卷积网络里也会有通道
这点特别重要。
输入图像有通道很好理解,
但卷积层输出为什么也会有通道?
因为卷积层并不是只学一个卷积核,而通常会学很多个卷积核。
而:
每一个卷积核都会生成一张输出特征图。
所以如果一层卷积有 16 个卷积核,那么它就会输出 16 张特征图,也就是:
16 \\text{ 个输出通道}
这说明:
-
输入通道数表示输入里有多少个特征平面
-
输出通道数表示这一层想提取多少种不同特征
所以通道可以理解成:
特征的"种类维度"
四、先讲多输入通道:彩色图像怎么卷积
假设现在输入不是单通道,而是一张 RGB 图像。
它有 3 个通道:
X_1, X_2, X_3
如果卷积层还是只输出 1 个通道,那应该怎么做?
答案是:
卷积核也必须有 3 个对应通道。
也就是说,这时候一个卷积核不再是单纯的二维矩阵,而是变成了一个三维张量:
K_1, K_2, K_3
其中:
-
(K_1) 作用在输入第 1 个通道上
-
(K_2) 作用在输入第 2 个通道上
-
(K_3) 作用在输入第 3 个通道上
五、多输入通道卷积到底怎么计算
如果输入有多个通道,那么卷积的计算方式是:
第一步
每个输入通道分别和自己对应的卷积核通道做卷积。
也就是:
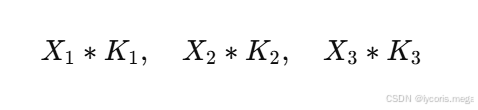
第二步
把这些结果逐元素相加。
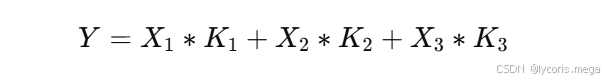
第三步
再加偏置(如果有)。
所以最终仍然只输出 一张特征图。
也就是说:
多输入通道卷积 = 各通道分别卷积,再把结果加起来。
这一点一定要记牢。
六、为什么要把多个通道卷积结果加起来
因为我们这一组卷积核的目标是:
共同提取一种跨通道特征。
举个直观例子:
如果输入是彩色图像,那么某种目标模式可能既依赖红色通道,也依赖绿色通道,还依赖蓝色通道。
所以不能只看某一个通道,而应该让同一个卷积核:
-
同时观察所有输入通道
-
再把信息融合起来
所以一个"输出通道"实际上表示:
一种综合了所有输入通道信息的特征检测结果
七、一个关键结论:卷积核输入通道数必须等于输入通道数
这是卷积网络里非常重要的规则。
如果输入有 (c_i) 个通道,那么每个卷积核也必须有 (c_i) 个通道,才能一一对应完成卷积。
所以:
-
输入 1 通道 → 卷积核也要 1 通道
-
输入 3 通道 → 卷积核也要 3 通道
-
输入 64 通道 → 卷积核也要 64 通道
这也是为什么随着网络变深,卷积层参数形状会越来越"厚"。
八、再讲多输出通道:为什么一层卷积可以输出很多张特征图
前面我们讲的是:
-
多输入通道
-
单输出通道
现在继续往前走一步:
如果我们希望输出不止 1 个通道,而是输出很多通道怎么办?
答案很简单:
那就用很多组卷积核。
例如:
-
第一组卷积核提取边缘
-
第二组卷积核提取纹理
-
第三组卷积核提取某种形状
-
第四组卷积核提取另一种局部模式
每一组卷积核都会输出一张特征图。
所以如果有 (c_o) 组卷积核,最后就会得到 (c_o) 个输出通道。
九、多输出通道本质上是什么意思
多输出通道的本质是:
一层卷积同时学习多种不同的特征提取器。
例如在图像早期层中,不同输出通道可能分别关注:
-
水平边缘
-
垂直边缘
-
某种颜色变化
-
某种简单纹理
再往深层走,不同通道可能关注:
-
轮廓片段
-
物体局部结构
-
更复杂的抽象模式
所以输出通道数越多,通常意味着:
这一层有能力提取更多种不同类型的特征
十、把多输入和多输出放在一起看

十一、一个直观例子帮助理解

十二、为什么说卷积层会让特征越来越"厚"
随着网络加深,卷积层通常会让:
-
空间尺寸逐渐变小
-
通道数逐渐变多
也就是说,特征图会从:
- "高宽大、通道少"
逐渐变成:
- "高宽小、通道多"
这其实很好理解。
因为浅层时,网络看到的是原始图像,空间细节很多;
而越往后,网络越希望把这些局部信息组合成更多高层语义特征。
所以:
-
空间维度减少
-
通道维度增加
可以理解成一种"压缩空间、扩展语义"的过程。
十三、1×1 卷积为什么和通道有关
这一节顺便也能理解一个很有名的东西:
1×1 卷积
很多人一开始会疑惑:
1×1 的卷积核空间上不就只有一个点吗?它还有什么用?
如果只有单通道输入,1×1 卷积确实没什么空间意义。
但在多通道情况下,1×1 卷积非常有用,因为它主要不是在空间上做局部提取,而是在:
通道维度上做线性组合。
也就是说,它可以用来:
-
混合不同输入通道的信息
-
改变输出通道数
-
控制参数量
所以 1×1 卷积本质上更像一种:
通道变换器
这也是多通道卷积思想延伸出来的重要应用。
十四、PyTorch 中多输入多输出通道怎么体现
在 PyTorch 里,二维卷积层是:
nn.Conv2d(in_channels, out_channels, kernel_size)例如:
from torch import nn
conv2d = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1)这表示:
-
输入通道数是 3(例如 RGB 图)
-
输出通道数是 16(这一层要学 16 种特征)
-
卷积核大小是 3×3
-
padding=1 保持空间尺寸不变
这个卷积层的权重形状通常就是:
print(conv2d.weight.shape)输出类似:
(16,\\ 3,\\ 3,\\ 3)
也就是:
-
16 个输出通道
-
每个输出通道对应 3 个输入通道
-
每个小核大小是 3×3
十五、手写多输入通道卷积的思路
为了理解原理,我们也可以先写单输出通道的多输入通道卷积。
思路就是:
-
输入的每个通道分别和卷积核对应通道做二维卷积
-
把所有结果加起来
代码思路如下:
import torch
def corr2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum()
return Y
def corr2d_multi_in(X, K):
return sum(corr2d(x, k) for x, k in zip(X, K))这里:
-
X是多个输入通道 -
K是对应多个卷积核通道 -
zip(X, K)表示一一配对 -
最后结果求和
这就是多输入通道卷积最本质的实现方式。
十六、多输出通道怎么手写
如果想进一步写多输出通道,其实也不难:
对每个输出通道都单独做一次"多输入通道卷积",最后把结果堆起来即可。
思路如下:
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)这里:
-
K中包含很多组卷积核 -
每一组
k负责生成一个输出通道 -
最后用
torch.stack(..., 0)把多个输出通道叠起来
这就得到了完整的多输入多输出通道卷积。
十七、一个基础代码示例
下面给你一版比较适合直接放博客里的示例:
import torch
# 单通道二维卷积
def corr2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum()
return Y
# 多输入通道卷积
def corr2d_multi_in(X, K):
return sum(corr2d(x, k) for x, k in zip(X, K))
# 多输入多输出通道卷积
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
# 输入:2个通道
X = torch.tensor([[[0.0, 1.0, 2.0],
[3.0, 4.0, 5.0],
[6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
[7.0, 8.0, 9.0]]])
# 卷积核:3个输出通道,每个输出通道都对应2个输入通道
K = torch.tensor([[[[0.0, 1.0],
[2.0, 3.0]],
[[1.0, 2.0],
[3.0, 4.0]]],
[[[1.0, 0.0],
[0.0, 1.0]],
[[2.0, 1.0],
[1.0, 2.0]]],
[[[1.0, 1.0],
[1.0, 1.0]],
[[-1.0, -1.0],
[-1.0, -1.0]]]])
Y = corr2d_multi_in_out(X, K)
print(Y.shape)
print(Y)这段代码比较适合你在博客里讲:
-
输入通道怎么参与
-
输出通道怎么生成
-
最终输出张量维度是什么样
十八、为什么这一节特别重要
因为很多同学前面一学卷积,只记住了:
-
卷积核在图像上滑动
-
有个特征图输出
但一进入真实 CNN,立刻就会看到:
-
输入通道数不是 1
-
输出通道数也不是 1
-
网络里动不动就是 64、128、256 通道
如果没有"多输入多输出通道"这节,很多人会直接懵掉。
而一旦这一节弄明白了,你就会发现:
CNN 并没有变本质,只是把"单通道卷积"扩展成了"跨通道信息融合 + 多种特征并行提取"。
这就是它的本质。
十九、这一节最核心的一句话
如果让我用一句话总结这一节,我会写成:
多输入通道卷积通过"分别卷积后求和"融合所有输入特征,多输出通道卷积通过"多组卷积核"同时提取多种特征。
这句话基本把这一节最核心的两个机制都说清楚了。
二十、我对这一节的理解
学这一节之前,我对"通道"的理解其实比较表面,更多只是把它当成一个数字参数,比如 3 通道、64 通道。
但真正学完之后,我才慢慢意识到:
通道不是一个附属维度,而是卷积网络表达能力的重要来源。
输入通道表示模型能同时看多少种输入信息;
输出通道表示模型这一层想提取多少种不同特征。
也就是说,CNN 不只是"在平面上卷",它其实还在:
沿着通道维度不断融合信息、生成新的特征表示。
这一下就把我对卷积网络的理解从二维平面,提升到了真正的三维张量层面。
二十一、结语
"多输入多输出通道"是卷积神经网络中非常关键的一节。
因为从这一节开始,我们才真正进入了真实 CNN 的视角,而不是只停留在单张灰度图、单个卷积核的入门状态。
通过这一节,我们应该真正弄清楚:
-
多输入通道卷积怎么做
-
为什么要对多个通道卷积结果求和
-
多输出通道是怎么生成的
-
卷积层参数为什么是四维张量
-
通道数为什么会越来越多
把这一节学扎实,后面再去看池化层、LeNet、AlexNet 等经典网络结构时,理解会顺很多。
二十二、重点速记版
1. 什么是输入通道
输入中的不同特征平面,例如 RGB 三个颜色通道。
2. 多输入通道卷积怎么做
每个输入通道分别与对应卷积核通道卷积,再把结果相加。
3. 什么是输出通道
卷积层输出的不同特征图,每个输出通道对应一种特征提取结果。
4. 多输出通道怎么产生
使用多组卷积核,每组卷积核生成一个输出通道。
5. 卷积层权重张量形状通常是什么
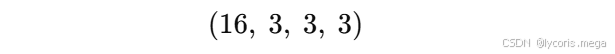
6. 为什么通道数在深层网络中会变多
因为网络需要提取越来越多种不同的特征。
7. 1×1 卷积主要在做什么
主要用于通道维度上的信息融合和通道数变换。
以上就是我对《动手学深度学习》中 多输入多输出通道 这一节的学习整理。
这一节让我真正从"单个卷积核处理一张图"的入门理解,走向了"真实卷积网络是如何在多个通道之间融合信息、并并行提取多种特征"的更完整视角。
我觉得这一节最重要的收获,不只是记住一个权重张量形状,而是要真正理解:卷积网络不仅在空间上滑动提取特征,也在通道维度上不断组织和重构信息。把这一点理解透,后面学习更复杂 CNN 结构时会顺很多。