在医学研究中,随机对照试验(RCT)一直是验证疗效和安全性的"金标准"。但在现实世界中,受限于伦理、成本或可行性,我们往往无法开展完美的RCT。基于"目标试验模拟"(Target Trial Emulation)框架的大数据分析法。简单来说,就是先在脑海中设计一个完美的理想试验,然后利用现有数据去尽可能"复刻"它。如果模拟成功,我们就能从观察性数据中得到接近RCT的因果效应估计值。简单来说,模拟RCT研究目的就是在回顾性的数据中,创造能用于分析的rct队列。
既往咱们已经对模拟RCT研究进行了初步介绍,今天咱们使用TrialEmulation包来对具体数据进行模拟RCT研究(真实世界研究)分析,这个R包进行模拟RCT研究(真实世界研究)分析非常简单,咱们先导入数据和R包
r
setwd("E:/公众号文章2026年/模拟目标实验")
library(TrialEmulation)
library("splines")
load("simdata.Rdata")
working_dir <- getwd()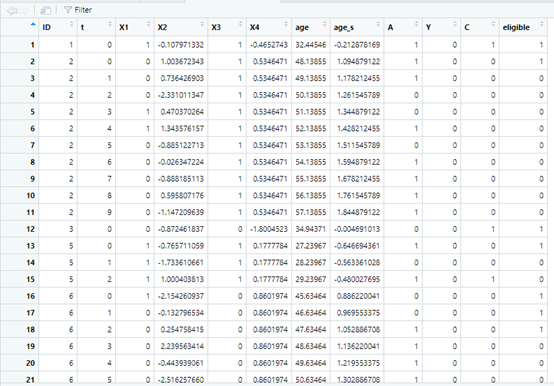
这是一个比较简单的数据,id是个体的标识编码, t 是随访/时期编号,A是咱们的研究变量,是否接受治疗,X1-X4属于协变量,age 是对应于 t 的个体年龄,age_s 是标准化年龄,Y 是对应于 t 的结局事件二元指标。C 是对应于 t 的删失指标。eligible 是对应于 t 的目标试验资格指标。glm_function是加权模型,glm这里用于二分类结局的加权
TrialEmulation包进行模拟RCT只需要两步,第一步就是整理数据,data这里是数据,period放入时间,treatment是咱们的研究变量,outcome是结局变量,estimand_type指数据处理方式,有"ITT", "PP", "As-Treated"三个方式,cense_d_cov和cense_n_cov用于构造逆概率加权,
r
prep_ITT_data <- data_preparation(
data = simdata_censored,
id = "ID", period = "t", treatment = "A",
outcome = "Y",
estimand_type = "ITT",
outcome_cov = ~ X1 + X2 + X3 + X4 + age_s, #RHS公式,其中基线协变量将在模拟试验的边缘结构模型中进行调整
use_censor_weights = TRUE, cense = "C",
cense_d_cov = ~ X1 + X2 + X3 + X4 + age_s,#逆概率分母
cense_n_cov = ~ X3 + X4, #逆概率分子
pool_cense = "numerator",
data_dir = working_dir, save_weight_models = F,
glm_function = "glm")提取生成的数据
r
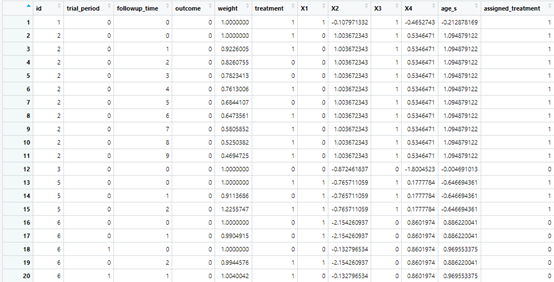
dt<-prep_ITT_data[["data"]]生成数据如下
整理一下数据
r
prep_ITT_data$data<-prep_ITT_data$data[order(prep_ITT_data$data$id,
+ prep_ITT_data$data$trial_period,prep_ITT_data$data$followup_time),]在新的数据里面,已经多出了权重,咱们就可以继续分析了,prep_ITT_data$data是加权整理后的数据,outcome_cov这里定义边缘架构模型,include_followup_time这里对时间进行了一个样条化处理,应对非直线关系,
r
ITT_result <- trial_msm(prep_ITT_data$data,
estimand_type = "ITT",
outcome_cov = ~ X1 + X2 + X3 + X4 + age_s,
model_var = "assigned_treatment",
include_followup_time = ~ ns(followup_time, df = 3),
glm_function = "glm",
use_sample_weights = FALSE,
quiet = TRUE)在这里数据中,加权后的模型系数经过稳健标准误进行了修正(一般方法有:稳健标准误,重抽样,三明治),
r
summary(ITT_result, digits = 1)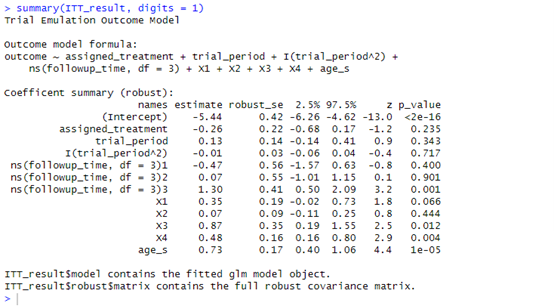
接下来我们选择trial_period == 0中的个体作为目标人群
r
new_data <- prep_ITT_data$data[prep_ITT_data$data$trial_period == 0,]
new_data <- rbind(data.table::as.data.table(prep_ITT_data$data_template),new_data)获取累积发生率
r
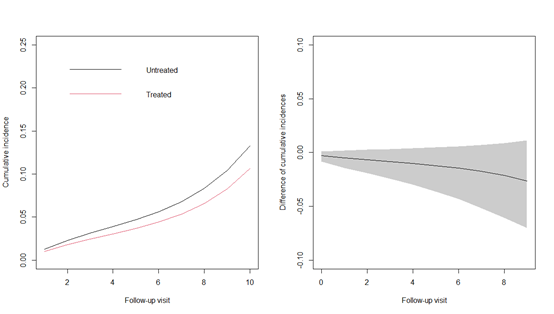
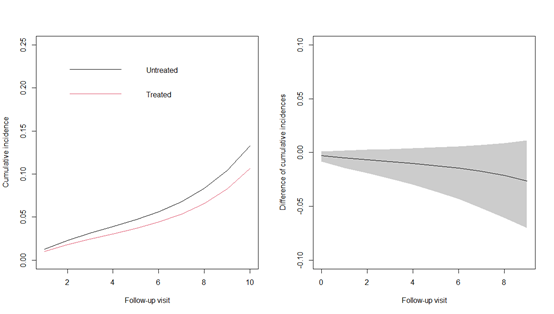
set.seed(20222022)
ITT_cuminc <- predict(ITT_result, new_data, predict_times = c(0:9))绘图,图片表示治疗组和未治疗组随着时间推移的疾病累积发生率,治疗组明显低于为治疗组。