Flink on Kubernetes部署详细教程
- 一、概念
- 二、准备工作
- 三、在K8s集群上搭建Flink集群
-
- [3.1 准备配置文件](#3.1 准备配置文件)
- [3.2 通过配置文件在 Kubernetes 上部署 Flink 集群](#3.2 通过配置文件在 Kubernetes 上部署 Flink 集群)
- [3.3 haproxy配置flink集群负载均衡](#3.3 haproxy配置flink集群负载均衡)
- [3.4 K8s验证](#3.4 K8s验证)
一、概念
Flink on Kubernetes将Flink的流处理能力与K8s的资源管理能力深度融合,实现"按需分配、自动运维、弹性伸缩"的生产级流处理系统。Flink与K8s的核心对应关系:

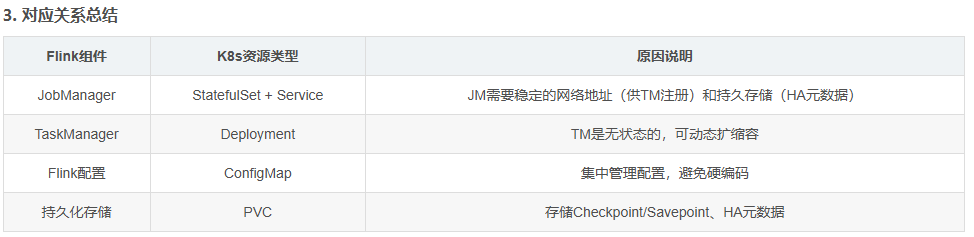
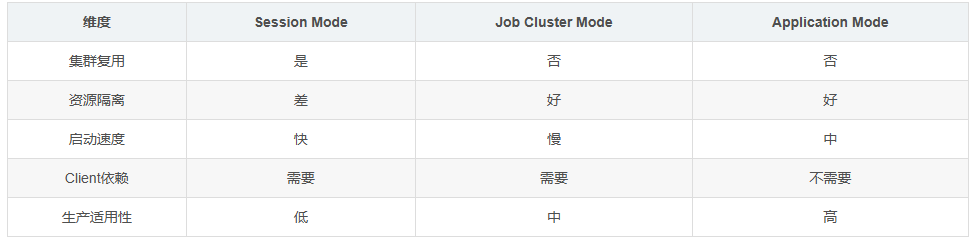
Flink官方提供三种K8s部署模式,分别对应不同的业务场景。我们需要根据作业类型、资源需求、运维复杂度选择合适的模式。
- Session Mode是共享集群模式:先启动一个长期运行的Flink集群(包含JM和一组TM),然后通过Client向集群提交多个作业。所有作业共享集群的资源(Task Slot)。
- Job Cluster Mode是专属集群模式:为每个作业启动一个独立的Flink集群(JM + 专属TM)。作业完成后,集群自动销毁。
- Application Mode是云原生最优模式:将应用代码与Flink集群打包成一个Docker镜像 ,直接在K8s上运行。作业的生命周期与集群一致(启动集群→运行作业→销毁集群)。
- 对比如下:
回到目录
二、准备工作
参考链接:从0到1搭建Flink on K8s集群
- 安装依赖工具
- Kind:本地K8s集群搭建工具(替代Minikube,启动更快);
- Docker:镜像构建与运行工具;
- kubectl:K8s命令行工具;
- Flink CLI:Flink命令行客户端(用于提交作业)。
- 搭建本地K8s集群
三、在K8s集群上搭建Flink集群
3.1 准备配置文件
1.K8s集群主节点操作
注意:必须是主节点,从节点不行
-
在K8s集群其中一个主节点上,进入主节点,查看集群状态:
kubectl version

集群状态正常,进入下一步 -
进入主节点目录,创建文件夹,并创建yaml配置文件:
#创建文件夹
mkdir /home/flink进入文件夹
cd /home/flink
创建pv.yaml文件
touch pv.yaml
创建flink.yaml文件
touch flink.yaml
- pv.yaml文件说明:为Flink 集群持久化存储,创建两个Kubernetes 存储资源对象,分别为:PersistentVolume (PV)(名称为 flink-data-pv)和PersistentVolumeClaim (PVC)(名称为 flink-data-pvc)
- flink.yaml文件说明:一个用于在 Kubernetes 上部署 Flink 集群的完整配置文件,定义了 5 个 Kubernetes 资源:
- Deployment: flink-jobmanager (Flink JobManager 部署),负责作业调度和协调
- Service: flink-jobmanager (JobManager 服务)
- Deployment: flink-taskmanager (Flink TaskManager 部署),负责实际的数据处理
- Service: flink-jobmanager-rest (JobManager REST API 服务)
- Service: flink-taskmanager-http (TaskManager HTTP 服务)
--- 根据实际情况修改下面2个 yaml 文件中 namespace 的值
-
编辑pv.yaml文件,将下面内容复制到文件中:
vi pv.yamlapiVersion: v1
kind: PersistentVolume
metadata:
name: flink-data-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
hostPath:
path: "/mnt/data/flink-data"
type: DirectoryOrCreateapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-data-pvc
namespace: test # 添加命名空间,根据实际命名修改
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
volumeName: flink-data-pv
-
编辑flink.yaml文件,将下面内容复制到文件中:
vi flink.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
namespace: test # 添加命名空间
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: jobmanager
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/flink:1.19.1-java8
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob
- containerPort: 8081
name: ui
env:
- name: JOB_MANAGER_RPC_ADDRESS
value: flink-jobmanager
- name: FLINK_PROPERTIES
value: |
jobmanager.memory.process.size: 1g
jobmanager.memory.jvm-overhead.max: 256m
state.backend: filesystem
state.checkpoints.dir: file:///mnt/data/flink-data
cluster.evenly-spread-out-slots: true
volumeMounts:
- name: flink-storage
mountPath: /mnt/data/flink-data
volumes:
- name: flink-storage
persistentVolumeClaim:
claimName: flink-data-pvcapiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
namespace: test # 添加命名空间
spec:
ports:
- name: rpc
port: 6123
- name: blob
port: 6124
- name: ui
port: 8081
selector:
app: flink
component: jobmanager
type: ClusterIPapiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
namespace: test # 添加命名空间
spec:
replicas: 3
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: taskmanager
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/flink:1.19.1-java8
args: ["taskmanager"]
ports:
- containerPort: 6121
name: data
- containerPort: 6122
name: rpc
- containerPort: 6666
name: http1
- containerPort: 6667
name: http2
- containerPort: 6668
name: http3
- containerPort: 6669
name: http4
- containerPort: 6670
name: http5
- containerPort: 6671
name: http6
- containerPort: 6672
name: http7
env:
- name: JOB_MANAGER_RPC_ADDRESS
value: flink-jobmanager
- name: FLINK_PROPERTIES
value: |
taskmanager.bind-host: 0.0.0.0
taskmanager.numberOfTaskSlots: 16
taskmanager.memory.process.size: 1024m
taskmanager.memory.heap.size: 512m
taskmanager.memory.off-heap.size: 256m
taskmanager.memory.managed.size: 256m
taskmanager.memory.jvm-metaspace.size: 128m
taskmanager.memory.jvm-overhead.min: 64m
taskmanager.memory.jvm-overhead.max: 128m
cluster.evenly-spread-out-slots: true
volumeMounts:
- name: flink-storage
mountPath: /mnt/data/flink-data
volumes:
- name: flink-storage
persistentVolumeClaim:
claimName: flink-data-pvcapiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
namespace: test # 添加命名空间
spec:
ports:
- name: ui
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
type: NodePortapiVersion: v1
kind: Service
metadata:
name: flink-taskmanager-http
namespace: test # 添加命名空间
spec:
type: NodePort
selector:
app: flink
component: taskmanager
ports:
- name: http1
port: 6666
targetPort: 6666
nodePort: 31001
- name: http2
port: 6667
targetPort: 6667
nodePort: 31002
- name: http3
port: 6668
targetPort: 6668
nodePort: 31003
- name: http4
port: 6669
targetPort: 6669
nodePort: 31004
- name: http5
port: 6670
targetPort: 6670
nodePort: 31005
- name: http6
port: 6671
targetPort: 6671
nodePort: 31006
- name: http7
port: 6672
targetPort: 6672
nodePort: 31007
3.2 通过配置文件在 Kubernetes 上部署 Flink 集群
-
通过配置文件,创建资源,执行命令:
kubectl apply -f pv.yaml
执行后,通过下面命令,判断是否成功创建资源:kubectl get pv -n 命名空间名称
kubectl get pvc -n 命名空间名称

- 通过配置文件,创建应用,执行命令:
kubectl apply -f flink.yaml
执行后,获取集群中核心资源的信息,执行命令:kubectl get all -n 命名空间名称
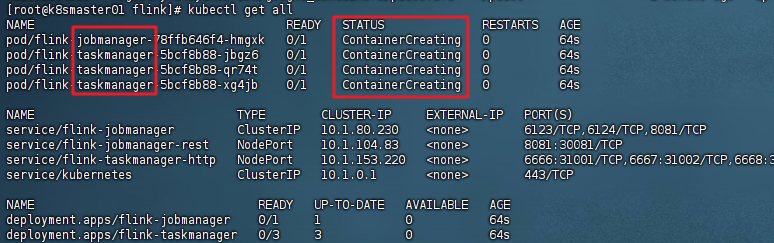
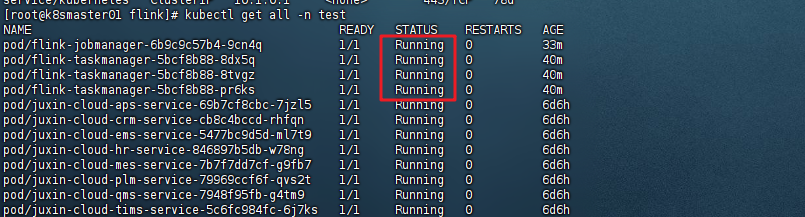
如果此时STATUS是Creating,请稍等一会,等待几分钟后重新执行,直至看到STATUS变成Running说明资源运行成功,flink集群创建成功。
回到目录
3.3 haproxy配置flink集群负载均衡
在haproxy集群的所有节点服务器中,找到 /etc/haproxy/haproxy.cfg配置文件,在文件末尾加上如下内容:vi /etc/haproxy/haproxy.cfg
#------- FLink服务 -------
listen Flink
bind *:30081 #映射端口
mode tcp #均衡模式
balance roundrobin #均衡算法
option httpclose # 此选项表在客户端和服务器端完成次连接请求后,haproxy将主动关闭此TCP连接
option abortonclose # 在服务器负载很⾼的情况下,⾃动结束掉当前队列中处理时间⽐较长的链接
server k8smaster01 10.30.2.52:30081 check
server k8smaster02 10.30.2.13:30081 check
server k8sworker01 10.30.2.25:30081 check
server k8sworker02 10.30.2.56:30081 check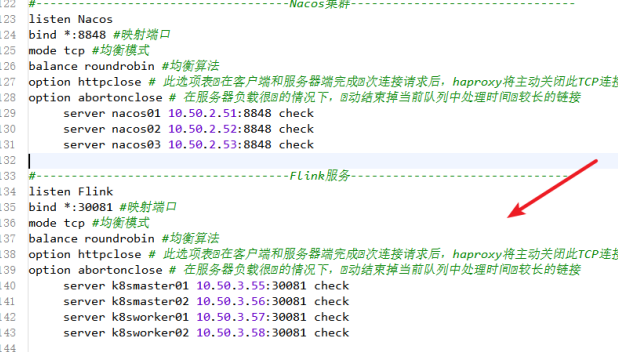
保存退出,然后重启haproxy服务,执行命令:sudo systemctl restart haproxy
查看haproxy状态,确认成功运行:sudo systemctl status haproxy
注意:
- option abortonclose 下的
server 节点名称 节点IP:30081根据flink集群实际情况配置 - 所有haproxy集群下的节点服务器都需要按照上面的步骤修改 /etc/haproxy/haproxy.cfg配置文件后,重启haproxy服务。
所有服务配置结束后,查看flink集群是否成功启动,浏览器进入Apache Flink Dashboard(Apache Flink 仪表盘),链接地址:http://10.30.2.150:30081/#/overview
这里的IP地址指的是haproxy配置的对外前端地址。
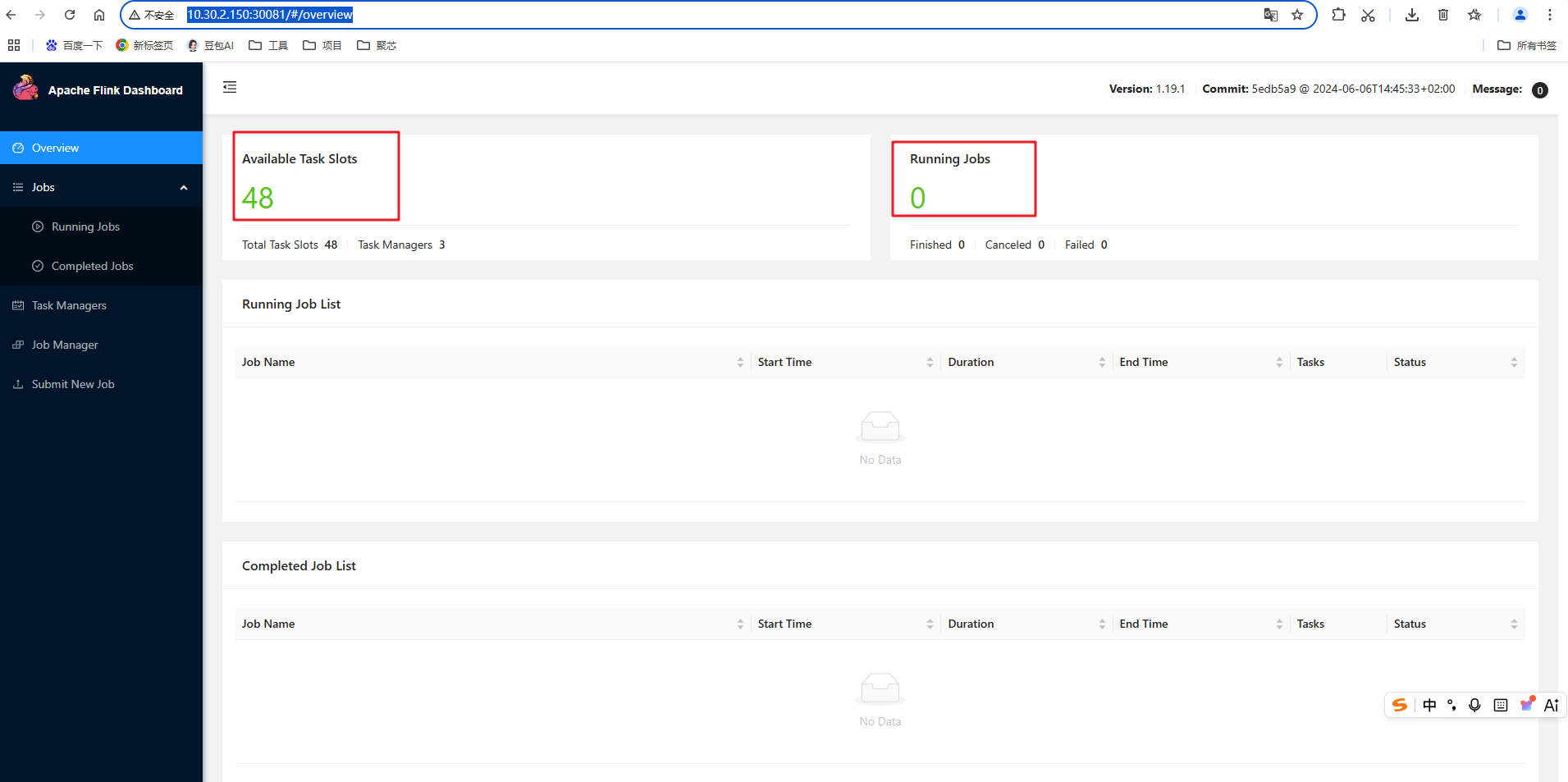
出现如下画面,说明flink集群负载均衡配置成功。
3.4 K8s验证
打开K8s的仪表板(Dashboard)访问界面,查看flink集群服务是否正常启动:
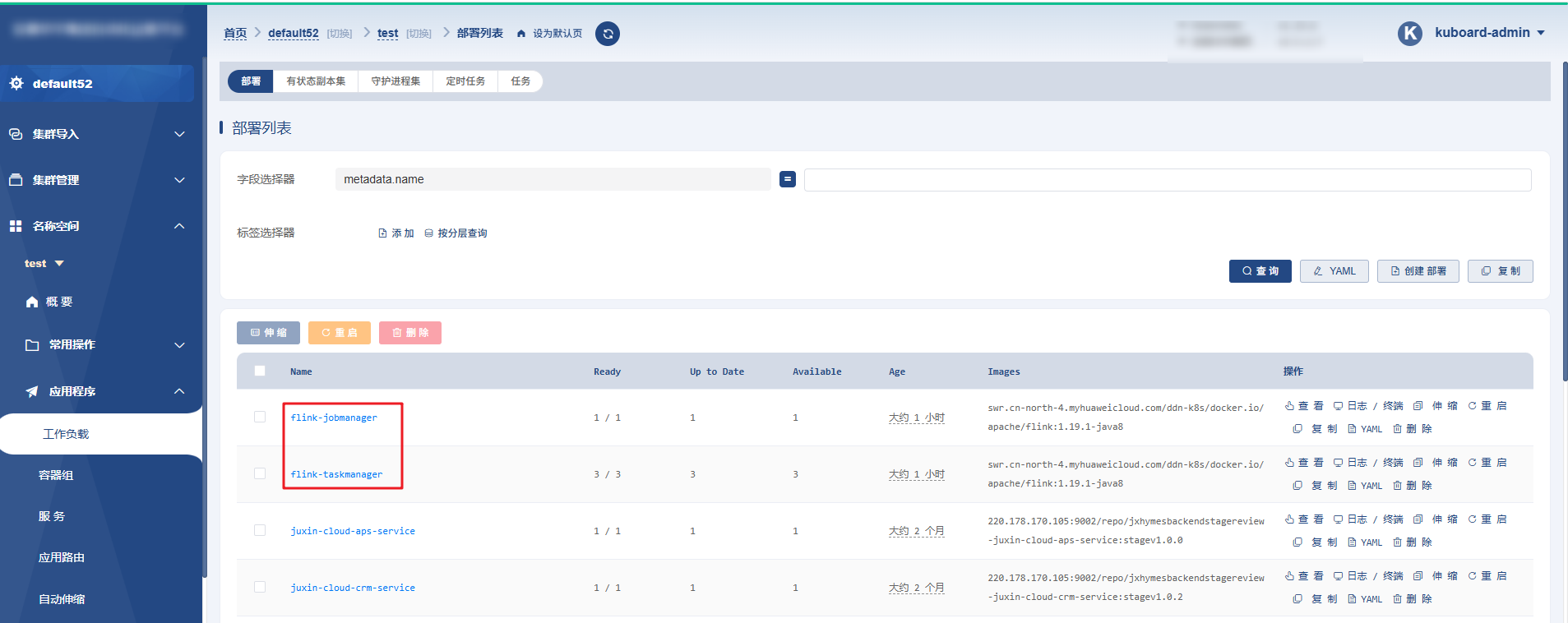
回到目录