在云原生时代,监控是每个后端开发和运维工程师的必备技能。提到 Kubernetes 监控,Prometheus + Grafana 这对"黄金搭档"几乎是绕不开的。Prometheus 负责数据的采集、存储和告警,Grafana 则负责酷炫的可视化。搞懂它们,基本就搞定了 K8s 监控的大半壁江山。
最近在项目中把这套监控体系又过了一遍,踩了不少坑,也总结了一些心得。这篇笔记把 Prometheus 和 Grafana 的核心知识点系统整理了一下。
目录
-
核心定位与架构总览
-
Prometheus 核心基础概念
-
PromQL 核心语法与常用函数
-
Prometheus 核心配置详解
-
告警体系:Prometheus Rule + Alertmanager
-
Grafana 核心知识点与可视化实践
-
进阶场景与高可用方案
-
最佳实践与避坑指南
1. 核心定位与架构总览
Prometheus 和 Grafana 分工明确,能力互补:
-
Prometheus :一个带时序数据库(TSDB)的监控告警系统。核心是采集 、存储 、查询 、告警。
-
Grafana :一个开源的可视化平台。核心是展示 、分析 、统一管理多数据源。
Prometheus 核心架构
Prometheus 采用Pull(拉)为主、Push(推)为辅 的架构。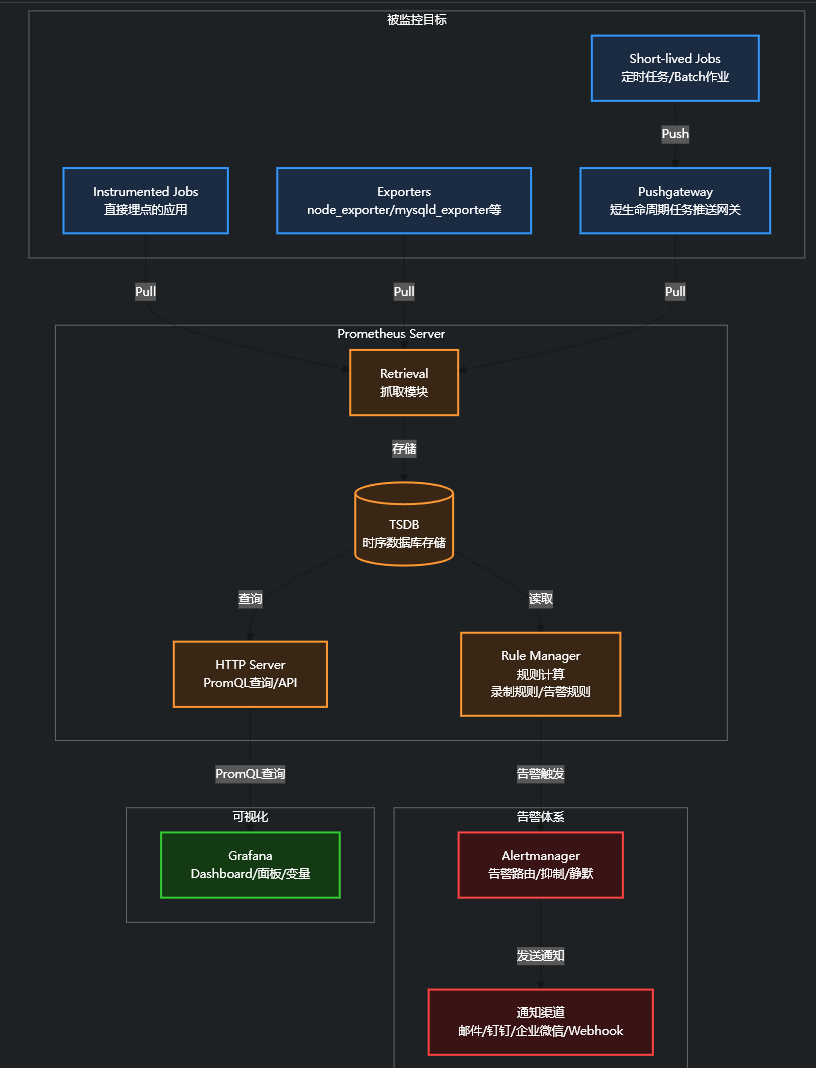
核心组件:
-
Prometheus Server:主服务,负责抓取、存储、查询。
-
Exporter :指标暴露器,把各种中间件的指标转成 Prometheus 格式。比如
node_exporter暴露主机指标,mysqld_exporter暴露 MySQL 指标。 -
Pushgateway:推送网关,给短生命周期任务(如批处理脚本)用,让它们把指标推过来,再由 Prometheus 来拉。
-
Alertmanager:告警管理器,负责告警的分组、路由、抑制、静默和通知。
-
Service Discovery:服务发现,自动发现 K8s、ECS 等环境里的监控目标。
2. Prometheus 核心基础概念
时序数据模型
Prometheus 里所有数据都是时序数据,格式如下:
指标名{标签1="值1", 标签2="值2"} [时间戳] [样本值]
-
指标名 (metric name) :比如
http_requests_total。 -
标签 (labels):定义维度,是多维查询的核心。
-
样本值 (sample value):一个 float64 的数值。
四大核心指标类型
| 指标类型 | 特性 | 适用场景 | 示例 |
|---|---|---|---|
| Counter | 只增不减的计数器 | 请求总数、错误总数、流量累计 | http_requests_total |
| Gauge | 可增可减的仪表盘 | CPU 使用率、内存占用、在线人数 | node_memory_MemAvailable_bytes |
| Histogram | 分桶统计,服务端计算 | 请求延迟、响应大小分布(算P99) | http_request_duration_seconds_bucket |
| Summary | 客户端预计算分位数 | 低基数场景分位数统计 | rpc_duration_seconds{quantile="0.95"} |
踩坑经验:分位数统计优先用 Histogram,它支持服务端聚合,更灵活。Summary 在聚合时会丢失分位数信息。
3. PromQL 核心语法与常用函数
PromQL 是 Prometheus 的灵魂,用来查询和聚合数据。
PromQL 四大数据类型
-
瞬时向量 (Instant Vector):最常用的,某个时间点的一组时序。
-
区间向量 (Range Vector) :某个时间段内的一组时序,必须配合
rate()等函数用。 -
标量 (Scalar):单个数字。
-
字符串 (String):基本不用。
高频核心函数
| 函数 | 作用 | 适用场景 | 避坑提示 |
|---|---|---|---|
rate(v range-vector) |
计算 Counter 每秒平均增长率 | QPS、CPU 使用率等长期趋势 | 必须用于 Counter,区间至少 2 倍抓取间隔 |
irate(v range-vector) |
计算 Counter 瞬时增长率 | 实时峰值监控,避免平均化 | 易抖动,不适合告警 |
increase(v range-vector) |
计算 Counter 总增量 | 统计一段时间内累计值 | 本质是 rate() * 区间秒数 |
sum() |
求和,配合 by() 分组 |
按实例/集群聚合指标 | 必须 rate() -> sum(),顺序反了结果就错了 |
histogram_quantile(φ, b) |
基于 Histogram 计算分位数 | 请求延迟 P95/P99 | 必须作用于 _bucket 指标 |
topk(k, v) |
返回值最大的前 k 个时序 | 监控 TOP N 异常指标 | - |
生产高频查询示例
-
节点 CPU 使用率
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) -
节点内存使用率
100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100) -
HTTP 接口 QPS
sum by (instance, path) (rate(http_requests_total[5m])) -
HTTP 请求延迟 P95
histogram_quantile(0.95, sum by (le, path) (rate(http_request_duration_seconds_bucket[5m]))) -
节点存活状态
up{job="node_exporter"} == 0
4. Prometheus 核心配置详解
核心配置文件 prometheus.yml:
global:
scrape_interval: 15s # 全局默认抓取间隔
evaluation_interval: 15s # 规则计算间隔
rule_files:
- "rules/*.yml"
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
static_configs:
- targets: ["node1:9100", "node2:9100"]关键配置:
-
relabel_configs:抓取前重写标签,用于服务发现。 -
metric_relabel_configs:抓取后、存储前重写,用于过滤指标、降低基数。 -
录制规则 (Recording Rule):预计算复杂 PromQL,存为新指标,加速查询。
5. 告警体系:Prometheus Rule + Alertmanager
告警规则编写
groups:
- name: node_alerts
rules:
- alert: NodeDown
expr: up{job="node_exporter"} == 0
for: 2m # 持续触发 2 分钟才告警,防抖动
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.instance }} 宕机"
description: "节点 {{ $labels.instance }} 已超过 2 分钟无法抓取。"Alertmanager 核心能力
-
路由 (Route):按标签分发告警到不同渠道。
-
分组 (Group):合并相同标签的告警,防告警风暴。
-
抑制 (Inhibit):高优先级告警抑制低优先级告警。
-
静默 (Silence):临时屏蔽告警,适合变更窗口。
6. Grafana 核心知识点与可视化实践
与 Prometheus 对接
-
添加数据源:在 Grafana 里添加 Prometheus 数据源,填上地址就行。
-
导入 Dashboard :从社区(grafana.com/grafana/dashboards)导入成熟的 Dashboard,如
8919(节点监控)、7362(MySQL)、1860(K8s)。
核心概念
-
Dashboard:面板集合。
-
Panel:可视化最小单元,对应一个或多个查询。
-
Variable :变量,实现 Dashboard 动态化。比如用
$instance变量切换节点。
最佳实践
-
分层设计:总览层 → 集群层 → 节点层 → 服务层,逐级下钻。
-
变量复用:核心维度(实例、集群)统一变量。
-
用
$__interval自动适配时间范围,防查询超时。
7. 进阶场景与高可用方案
Prometheus 单机有瓶颈,生产环境需要高可用方案:
-
主备集群:两套 Prometheus 并行抓取,解决单点故障。
-
联邦集群:分层部署,全局 Prometheus 从边缘 Prometheus 抓取聚合数据。
-
Thanos:开源高可用方案,对接对象存储实现长期存储、全局视图、降采样。
-
Cortex:云原生分布式方案,支持多租户、水平扩展。
8. 最佳实践与避坑指南
-
控制标签基数 :千万别用 user_id、trace_id 等高基数标签,会撑爆内存。
-
指标类型正确使用:累计值必须用 Counter。
-
PromQL 顺序 :必须先
rate()后sum(),顺序反了结果全错。 -
滥用 Pushgateway:别把长生命周期服务的指标推到 Pushgateway。
-
告警防抖 :告警规则一定加
for字段。 -
大范围查询:Grafana 大时间范围查询要设置步长,或用录制规则。
写在最后
Prometheus + Grafana 这套体系非常强大,但也很容易踩坑。核心就是理解数据模型、熟悉 PromQL、规范告警规则。多在实验环境搭搭、多看社区 Dashboard 的写法、多踩几次坑,慢慢就熟练了。
如果大家在用这套监控时有什么心得或者踩过什么奇葩的坑,欢迎评论区交流!
(完)