目录
[1. 环境准备(Maven依赖)](#1. 环境准备(Maven依赖))
[2. 完整代码实现](#2. 完整代码实现)
[3. 关键说明(主流用法补充,避免踩坑)](#3. 关键说明(主流用法补充,避免踩坑))
Java作为企业级开发主流语言,稳定性强、生态完善,非常适合实现爬虫开发,尤其适合大规模、分布式爬取场景,在企业级数据采集、竞品监测、数据分析等场景中应用广泛。
一、核心工具选型
Java爬虫入门及企业级基础开发中,最主流、最常用的工具组合的是**「Jsoup + OkHttp」**,二者搭配可搞定90%以上的静态网页爬取需求,生态成熟、资料丰富,遇到问题易排查,是新手入门和开发者日常开发的首选组合:
-
Jsoup :Java爬虫领域最主流的HTML解析工具,没有之一,语法类似jQuery,上手难度低,可快速定位并提取网页中的指定元素(如标题、内容、链接等),无需手动解析HTML源码,支持DOM遍历、CSS选择器和XPath,兼容性强,几乎适配所有静态网页的解析需求,是企业级爬虫中解析静态页面的首选工具。
-
OkHttp:目前Java领域最主流、最常用的HTTP请求客户端,替代了Java原生的HttpClient,广泛应用于各类Java项目,代码简洁、性能优异,支持连接池、超时设置、请求头自定义、HTTPS访问等,能轻松应对基础反爬拦截,适配多数静态网站的访问需求,与Jsoup搭配是Java爬虫的"黄金组合"。
进阶可学习WebMagic (国内成熟的Java爬虫框架,开箱即用,支持分布式、断点续爬,企业级场景常用)、Selenium(控制真实浏览器,解决动态页面爬取问题,如JS渲染的页面)
二、实践示例:爬取简单静态网页(提取文章标题)
以爬取某静态博客页面的文章标题为例,采用「Jsoup + OkHttp」这组最主流工具,全程极简,代码注释详细,复制到IDE中配置依赖后可直接运行,新手可跟着实操,快速感受Java爬虫的实现流程,同时规避基础踩坑点,贴合主流开发习惯。
1. 环境准备(Maven依赖)
本文基于Maven项目开发
针对爬虫项目,推荐使用
maven-archetype-quickstart,这是最通用、最干净的入门项目骨架,不会引入不必要的依赖。
引入「Jsoup + OkHttp」的主流稳定版本,避免版本兼容问题,这也是企业开发中最常用的版本组合:
XML
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.17.2</version> <!-- 主流稳定版,企业常用 -->
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.11.0</version> <!-- 主流稳定版,兼容多数Java项目 -->
</dependency>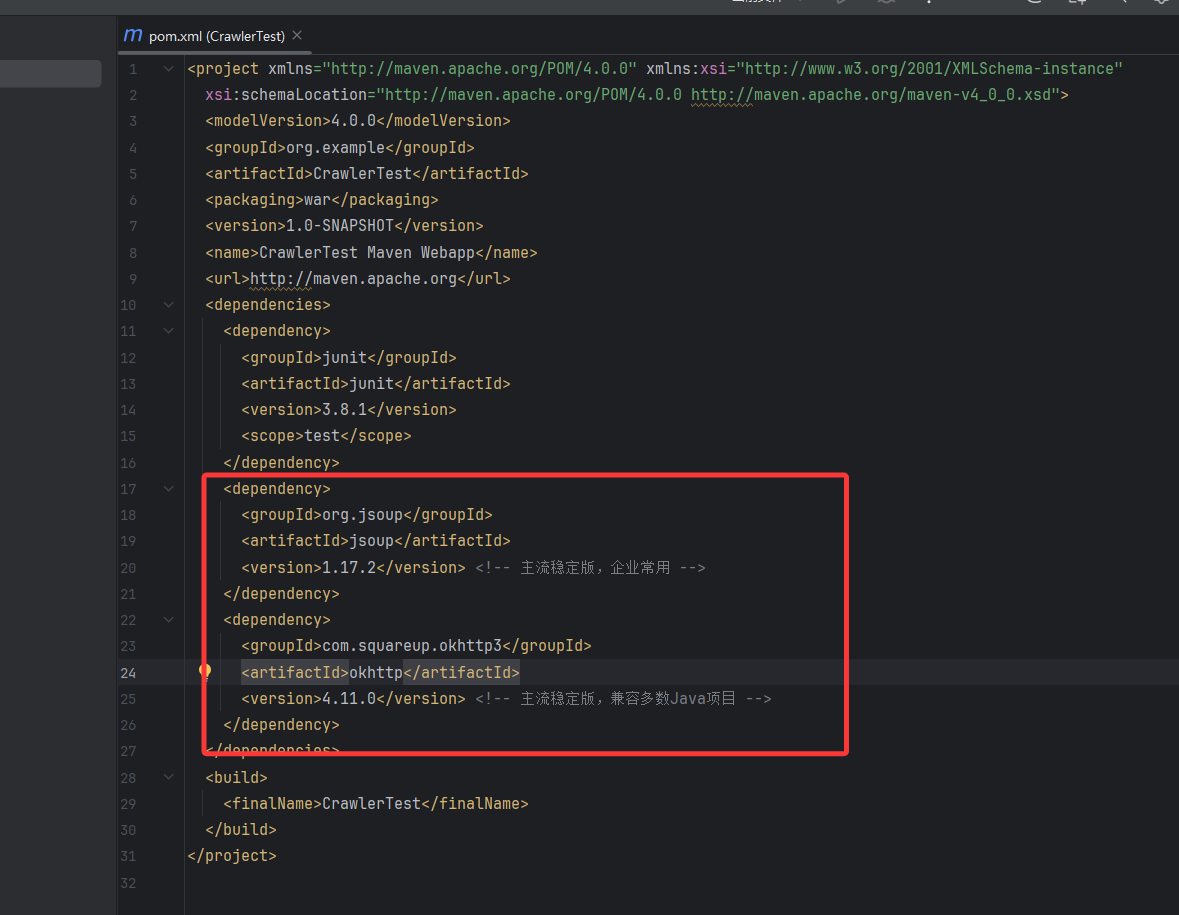
补充说明:若未使用Maven,可直接下载对应jar包导入项目(Jsoup官网、Maven仓库均可下载),确保jar包版本与代码中依赖版本一致,避免出现类找不到的异常;这两个工具的版本无需追求最新,主流稳定版即可,兼顾兼容性和稳定性。
2. 完整代码实现
采用「Jsoup + OkHttp」主流组合,发送HTTP请求获取目标静态网页的源码,通过Jsoup解析源码、提取所有文章标题,打印输出到控制台;同时添加请求头、异常处理,规避基础反爬和程序崩溃问题,代码逻辑贴合企业基础爬虫开发规范(注:爬取前务必确认目标网站允许爬取,遵守网站robots协议,避免违规)。
java
package org.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import java.io.IOException;
public class JavaCrawlerDemo {
// 目标爬取地址(示例:静态博客页面,可替换为自己需要爬取的静态网页地址)
private static final String TARGET_URL = "https://blog.csdn.net/2301_78566776/article/details/159692711?spm=1001.2014.3001.5501";
public static void main(String[] args) {
// 1. 创建OkHttp客户端(主流用法,配置超时时间,避免因网络卡顿导致程序卡死)
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(10, java.util.concurrent.TimeUnit.SECONDS) // 连接超时10秒(主流配置)
.readTimeout(10, java.util.concurrent.TimeUnit.SECONDS) // 读取超时10秒(主流配置)
.build();
// 2. 构建HTTP请求,添加请求头,模拟浏览器访问,规避基础反爬(主流反爬规避手段)
Request request = new Request.Builder()
.url(TARGET_URL)
// User-Agent:模拟浏览器身份,必须添加,否则部分网站会拒绝请求(主流配置)
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36")
// 可选:添加Referer,模拟从某个页面跳转过来,进一步规避反爬(主流优化手段)
.header("Referer", "https://example.com")
.build();
try (Response response = client.newCall(request).execute()) {
// 3. 获取网页源码(确认请求成功,响应码为200左右才代表请求成功,主流校验逻辑)
if (response.isSuccessful() && response.body() != null) {
String html = response.body().string();
// 4. Jsoup解析HTML源码,生成Document对象,便于提取元素(主流解析方式)
Document doc = Jsoup.parse(html);
// 5. 提取文章标题:根据目标页面的实际标签调整selector(F12查看网页元素即可获取)
// 示例:假设文章标题标签为 <h3 class="article-title">,若标签不同,替换引号内的内容即可(主流selector用法)
Elements titles = doc.select("h1.title-article");
// 6. 遍历输出所有标题,判断是否爬取到内容,避免空输出(主流异常兜底逻辑)
if (titles.size() == 0) {
System.out.println("未爬取到任何文章标题,请检查selector语法或目标网页是否正确");
} else {
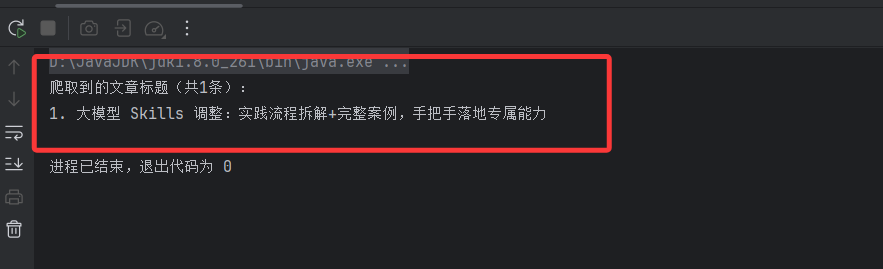
System.out.println("爬取到的文章标题(共" + titles.size() + "条):");
for (int i = 0; i < titles.size(); i++) {
System.out.println((i+1) + ". " + titles.get(i).text());
// 可选:提取文章标题对应的链接,补充功能(主流拓展逻辑)
String titleUrl = titles.get(i).select("a").attr("href");
if (!titleUrl.isEmpty()) {
System.out.println(" 文章链接:" + titleUrl);
}
}
}
} else {
System.out.println("请求失败,响应码:" + response.code());
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("爬取失败,原因:" + e.getMessage() + "(可能是网络问题、目标网站无法访问或被拦截)");
}
}
}在这里我爬取了我的上一篇文章大模型 Skills 调整:实践流程拆解+完整案例,手把手落地专属能力
在这个页面中,我们要抓取其标题
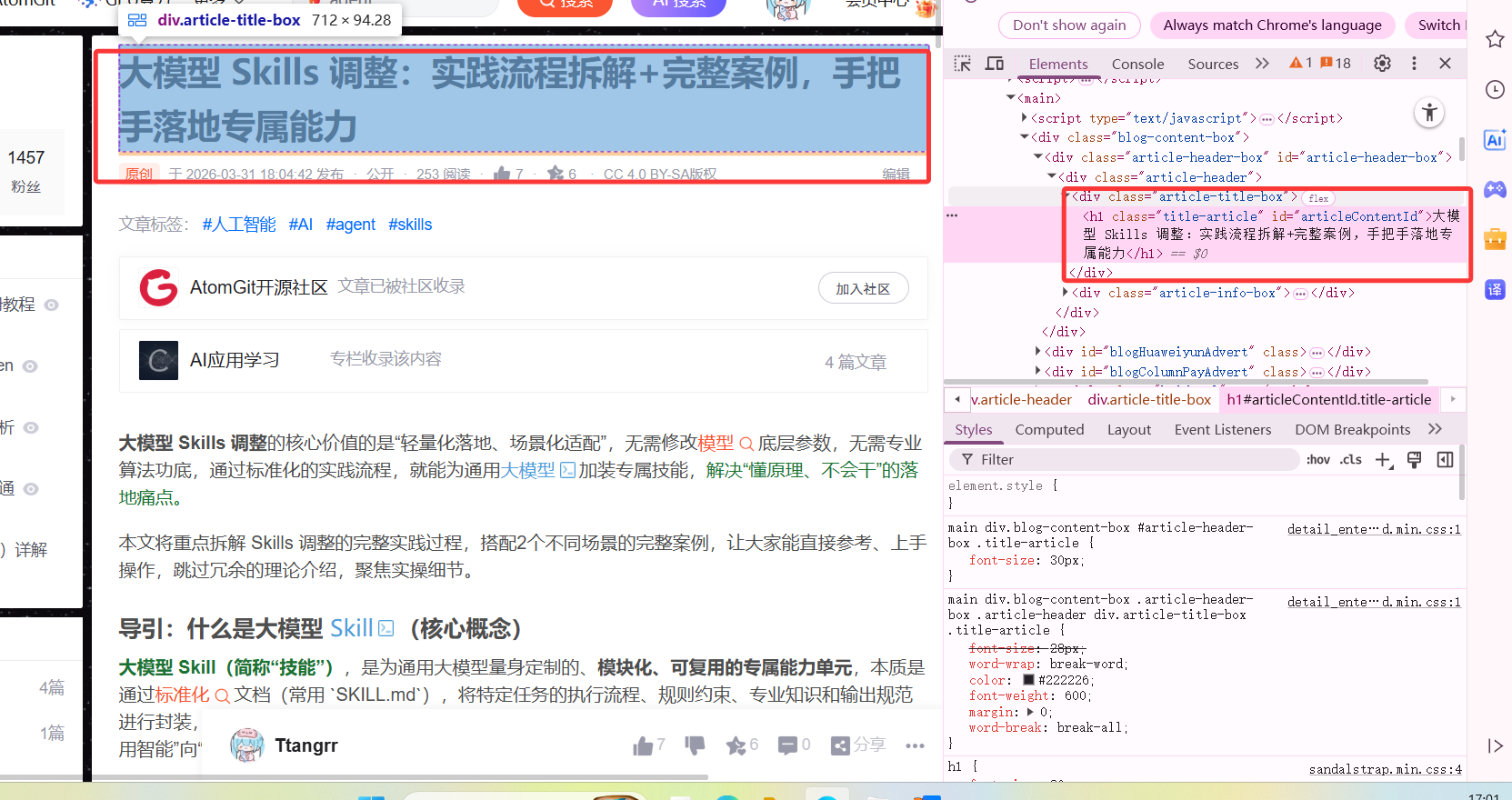
执行结果如下:
常见问题解决方案
(1)无需读取指定标签内容(如Elements titles = doc.select("h1.title-article"))的方法
核心逻辑:指定标签读取(如标题)是"提取特定数据"的操作,若无需读取,直接跳过该步骤即可,无需额外编写标签选择代码,具体分两种场景:
**场景1:**仅获取网页源码,不做任何解析 → 直接删除Jsoup解析相关代码,仅保留OkHttp发送请求、获取HTML源码的逻辑,示例片段:
java
// 仅获取网页源码,不读取任何标签
if (response.isSuccessful() && response.body() != null) {
String html = response.body().string();
System.out.println("网页完整源码:" + html); // 直接打印源码,无需解析标签
}场景2:需要解析网页,但不读取某一个特定标签(如不读取h1.title-article) → 不编写该标签的select语句即可,例如只提取链接、不提取标题,就删除Elements titles = doc.select("h1.title-article")及相关遍历代码,保留其他需要的解析逻辑。
(2)获取完整页面内容的操作方法
完整页面内容分两种理解,对应两种主流实现方式,按需选择,均贴合「Jsoup + OkHttp」组合用法:
- 获取网页完整HTML源码(最常用):直接通过OkHttp获取response.body().string(),即可得到整个页面的源码(包含所有标签、文本、样式等),示例代码同上面"场景1",无需Jsoup解析,直接打印或保存源码即可。
- 获取网页所有可见文本(去除标签,仅保留文字):通过Jsoup解析后,调用Document对象的text()方法,自动去除所有HTML标签,提取页面所有可见文本,示例片段:
java
String html = response.body().string();
Document doc = Jsoup.parse(html);
String fullText = doc.text(); // 提取页面所有可见文本,无任何标签
System.out.println("页面完整可见文本:" + fullText);(3)获取多个页面的操作方法
核心逻辑:多个页面爬取本质是"循环发送请求",针对不同页面地址,重复执行"发送请求-解析数据"的流程,主流两种实现方式,新手优先掌握第一种:
固定多个页面地址(适合页面地址已知):将所有目标页面地址存入集合,循环遍历集合,逐个发送请求,示例片段(整合到原有代码):
java
public static void main(String[] args) {
OkHttpClient client = new OkHttpClient.Builder()
.connectTimeout(10, java.util.concurrent.TimeUnit.SECONDS)
.readTimeout(10, java.util.concurrent.TimeUnit.SECONDS)
.build();
// 1. 存储多个目标页面地址(可自定义添加)
List<String> urlList = Arrays.asList(
"https://example.com/blog/page1",
"https://example.com/blog/page2",
"https://example.com/blog/page3"
);
// 2. 循环遍历,逐个爬取每个页面
for (String url : urlList) {
Request request = new Request.Builder()
.url(url)
.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36")
.build();
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful() && response.body() != null) {
String html = response.body().string();
Document doc = Jsoup.parse(html);
Elements titles = doc.select("h3.article-title"); // 按需求提取标签
System.out.println("===== 爬取页面:" + url + " =====");
// 遍历输出当前页面的标题(可替换为其他需要提取的数据)
for (int i = 0; i < titles.size(); i++) {
System.out.println((i+1) + ". " + titles.get(i).text());
}
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("爬取页面 " + url + " 失败:" + e.getMessage());
}
}
}爬取结果如下:
关键提醒:多页面爬取时,建议添加适当延迟(如Thread.sleep(1000)),避免高频访问目标网站触发反爬,延迟代码可添加在循环内部,每次请求后暂停1-2秒
3. 关键说明(主流用法补充,避免踩坑)
-
工具组合优势:「Jsoup + OkHttp」是Java爬虫最主流的组合,二者分工明确------OkHttp负责"发请求、拿源码",Jsoup负责"解析源码、提数据",搭配使用简洁高效,且资料丰富,遇到问题可快速找到解决方案,是企业基础爬虫的首选组合。
-
User-Agent必须添加:多数网站会拦截没有User-Agent的请求,认为是非法爬虫,代码中提供的User-Agent可直接使用,也可替换为自己浏览器的User-Agent(F12打开开发者工具,在Network中查看请求头即可获取),这是主流的反爬规避手段。
-
selector语法:doc.select("h1.title-article")中的语法和CSS选择器完全一致,是Jsoup的主流用法,若爬取不到内容,大概率是selector写错,可通过F12查看目标元素的标签和class、id,调整selector(例如id选择器用#,class选择器用.)。
-
异常处理:代码中捕获了IOException,同时添加了请求失败、无爬取结果的判断,避免因网络问题、页面无法访问、selector错误导致程序崩溃,这是主流的爬虫编码规范,新手可重点关注这部分逻辑,养成良好的编码习惯。
-
超时设置:OkHttpClient添加了超时时间(10秒是主流配置),避免因网络卡顿导致程序一直阻塞,可根据实际情况调整超时时间(单位可改为TimeUnit.MINUTES)。
三、入门注意事项(补充细节,规避风险)
-
合规爬取:这是爬虫开发的首要原则,仅爬取公开可访问的数据,不爬取隐私信息、版权受保护的内容;爬取前查看目标网站的robots协议(在网站域名后加/robots.txt即可查看),遵守网站的爬取规则;避免高频、批量访问同一网站,以免给网站服务器造成压力,甚至触发反爬、承担法律责任。
-
动态页面处理:若目标页面是JS渲染的(如Vue、React项目,打开F12查看源码,看不到页面实际内容),Jsoup无法解析渲染后的内容,此时需搭配Selenium(主流动态页面爬取工具),控制Chrome、Firefox等真实浏览器,模拟人工操作(如点击、滚动),获取渲染后的页面源码,后续可单独学习Selenium的基础使用。
-
进阶方向:入门后可逐步学习反爬应对技巧,如IP代理(解决IP被封禁问题,主流反爬手段)、Cookie维持(模拟登录后爬取需要登录的内容,企业级爬虫常用)、分布式爬取(应对大规模数据采集);同时可学习WebMagic框架(主流Java爬虫框架),简化爬虫开发流程,提高开发效率。
-
调试技巧:爬取过程中若出现问题,可通过打印HTML源码、响应码,排查请求是否成功;通过System.out.println()打印中间结果,排查selector是否正确;若被网站拦截,可尝试更换User-Agent、添加更多请求头,或降低访问频率,这些都是主流的调试方法