什么是布隆过滤器
布隆过滤器(Bloom Filter)是一种空间高效的概率数据结构,它用于快速判断一个元素是否属于一个集合,特点是:
- 时间高效:插入和查询时间复杂度均为 O(k)(k 为哈希函数个数,通常很小);
- 空间高效:只需一个位数组,远小于传统哈希表或集合;
- 允许假阳性:可能把不在集合中的元素误判为"可能存在",但绝无假阴性:如果判断"一定不存在",则绝对正确。
布隆过滤器解决了什么问题
在处理海量数据时,传统数据结构(如 HashSet、HashMap)会占用大量内存。例如:
- 爬虫需要对已访问的 URL 去重(数亿 URL);
- 缓存系统防止"缓存穿透"(先查 Redis 不存在再查 DB);
- 垃圾邮件过滤、黑名单查询、字典拼写检查、大数据去重等场景。
这些场景下,如果用完整存储所有元素,内存消耗巨大(每个元素至少几十字节)。布隆过滤器用极少的内存(每个元素只需几比特)近似表示集合,以极小的误判率换取空间和速度。误判率可通过增大位数组长度 m 或调整哈希函数个数 k 来控制,通常控制在 1% 以内即可满足实际需求。
布隆过滤器实现原理
1.数据结构:
布隆过滤器由「初始值都为 0 的位图数组」和「 k 个哈希函数」两部分组成:
- 一个长度为 m 的位数组(bit array),初始全部为 0;
- k 个相互独立的哈希函数 h₁, h₂, ..., hₖ,每个哈希函数能将任意元素映射到 0, m-1 范围内。
2.操作:
插入元素 x:
计算 k 个哈希值:h₁(x), h₂(x), ..., hₖ(x)
将对应位置的 bit 全部置为 1。
查询元素 x:
计算同样的 k 个哈希值。
若所有 k 个位置的 bit 均为 1 -> 可能存在(可能假阳性);
若任意一个 位置的 bit 为 0 -> 一定不存在。
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
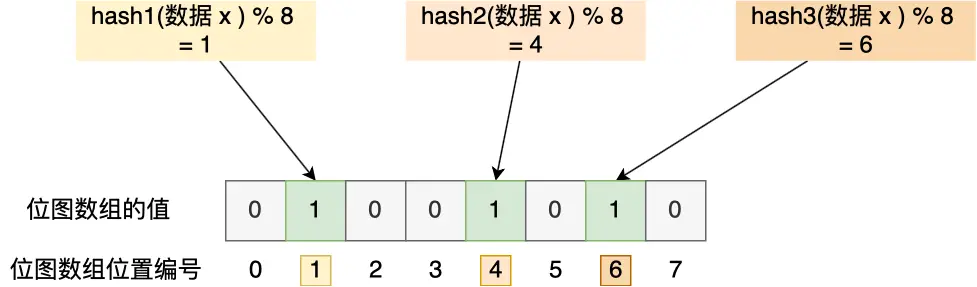
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。