提升计算能力
集群通过将多个计算节点连接在一起,能够显著提升整体计算能力。单个服务器的性能有限,而集群可以并行处理任务,适合大规模计算需求,如科学模拟、大数据分析等。
高可用性与容错性
集群设计通常包含冗余机制,即使某个节点发生故障,其他节点仍可继续运行,确保系统的高可用性。这在关键业务场景(如金融交易、在线服务)中尤为重要。
横向扩展能力
集群支持动态扩展,可根据需求增加或减少节点,灵活应对业务增长或负载波动。相较于单台高性能服务器,集群扩展成本更低,且能避免硬件瓶颈。
负载均衡
集群能够将任务合理分配到不同节点,避免单一节点过载,提高资源利用率。例如,Web服务器集群可通过负载均衡器分发用户请求,提升响应速度。
适用于分布式计算
现代技术如Hadoop、Kubernetes等依赖集群架构,支持分布式存储与计算。学习集群有助于掌握这些关键技术,适应云计算、AI训练等领域的职业需求。
1.redis-cluster架构图
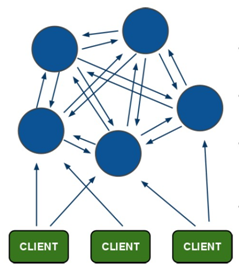
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),节点的fail是通过集群中超过半数的节点检测失效时才生效.
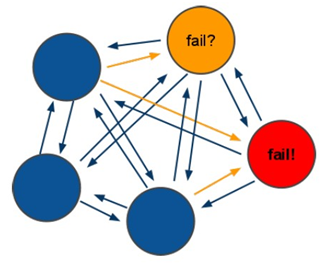
(2)存取数据时连接任一节点都可以,但集群中有一个节点fail整个集群都会fail
Redis 集群中内置了 16384 个哈希槽,当需要在Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
1、为什么节点之间相互ping-pong?
投票找出挂掉的节点
2、为什么要找出挂掉的节点?
集群中有一个节点挂了整个群都挂了
3、集群中有一个节点挂了整个集群都会挂了?为什么客户端连哪一台都行?
redis集群中有16384个槽,分给了3个节点,
存取数据时:crc16(key)%16384=0~16383
4、redis集群是多少台?
投票找出挂掉的节点超过半数:3台 高可用:3台
2.redis集群的搭建
Redis集群中至少应该有三个节点。要保证集群的高可用,需要每个节点有一个备份机。
Redis集群至少需要6台服务器。
搭建伪分布式。可以使用一台虚拟机运行6个redis实例。需要修改redis的端口号7001-7006
首先创建/redis-cluster文件夹放置
3、搭建步骤
①删除redis中的持久化文件
cd /usr/local/redis/bin
rm -f dump.rdb
rm -f appendonly.aof
②开启集群
vim /usr/local/redis/bin/redis.conf
cluster-enable yes
③拷贝6个节点
cd /usr/local
cp -r /usr/local/redis /usr/local/redis-cluster/redis-7001
..........
④修改端口号
vim /usr/local/redis-cluster/redis-7001/bin/redis.conf
port 7001
⑤编写启动脚本
cd /usr/local/redis-cluster
vim start-all.sh:
cd /usr/local/redis-cluster/redis-7001/bin
./redis-server redis.conf
更改权限
chmod 755 start-all.sh
./start-all.sh //启动脚本
ps -ef | grep redis //查看进程
⑥安装ruby环境
cd /usr/upload
yum install ruby
yum install rubygems
gem install redis-3.0.0.gem
cd /usr/upload/redis-3.0.0/src
ll *.rb
⑦使用ruby脚本搭建redis集群
cd /usr/upload/redis-3.0.0/src
./redis-trib.rb create --replicas 1 (1 有几个从者)
192.168.61.131:7001
192.168.61.131:7002
192.168.61.131:7003
192.168.61.131:7004
192.168.61.131:7005
192.168.61.131:7006
(本机ip 和端口号)
⑧测试
1)存取数据 //链接集群
./redis-cli -c -p 7001
2)测试是否高可用
cluster nodes
关闭7001
cluster nodes
4 ,redis 的基本数据类型
String(字符串)
| 操作 | 命令 | 说明 |
|---|---|---|
| 增 / 改 | set k v |
设置 key 为 k,值为 v,已存在则覆盖 |
| 查 | get k |
获取 key 为 k 的值 |
| 删 | del k |
删除 key 为 k 的键值对 |
Hash(哈希)
| 操作 | 命令 | 说明 |
|---|---|---|
| 增 / 改 | hset k field value |
给 key 为 k 的哈希表,设置字段 field 的值为 value |
| 查 | hget k field |
获取 key 为 k 的哈希表中,field 字段的值 |
| 删 | hdel k field |
删除 key 为 k 的哈希表中的 field 字段 |
List(列表)
| 操作 | 命令 | 说明 |
|---|---|---|
| 增 | lpush/rpush k v... |
lpush从列表左侧 插入元素,rpush从右侧插入 |
| 查 | lrange k start end |
获取列表指定范围的元素,0 -1代表查询全部 |
| 删 | lrem k count v |
删除列表中 count 个值为 v 的元素 |
Set(集合)
| 操作 | 命令 | 说明 |
|---|---|---|
| 增 | sadd k v... |
给 key 为 k 的集合添加元素,自动去重 |
| 查 | smembers k |
获取集合中所有元素 |
| 删 | srem k v |
删除集合中值为 v 的元素 |
ZSet(有序集合)
| 操作 | 命令 | 说明 |
|---|---|---|
| 增 | zadd k score v... |
给 key 为 k 的有序集合添加元素,同时指定分数 score(用于排序) |
| 查 | zrange k 0 -1 withscores |
按分数升序获取集合所有元素,withscores同时显示分数 |
| 删 | zrem k v |
删除有序集合中值为 v 的元素 |
核心记忆技巧
| 数据类型 | 增 | 查 | 删 |
|---|---|---|---|
| String | set |
get |
del |
| Hash | hset |
hget |
hdel |
| List | lpush/rpush |
lrange |
lrem |
| Set | sadd |
smembers |
srem |
| ZSet | zadd |
zrange |
zrem |
5,哨兵
1.哨兵核心定位
哨兵不存数据,仅负责「监控、故障判断、自动切换」,是主从架构的"守护者"。
核心目标:主节点挂了,自动把从节点升为新主,让业务无缝衔接。
2、核心工作流程
-
监控:哨兵持续PING主、从节点,判断节点是否存活;
-
主观下线:单个哨兵检测到主节点无响应,标记为主观下线;
-
客观下线:超过半数哨兵确认主节点下线,标记为客观下线(真正故障);
-
故障转移:自动选举新主,让其他从节点同步新主,旧主恢复后变为从节点。
3、最简架构
哨兵集群(至少3个,奇数,用于投票) + 1主N从
示例:3个哨兵 → 监控1个主节点 → 2个从节点
4,哨兵缺点
依赖主从架构,本身不能独立工作,需先搭建主从集群才能部署哨兵;
哨兵集群需至少 3 个节点(奇数),部署和维护成本高于单主从架构;
无数据分片能力,性能瓶颈受单节点配置限制,无法通过横向扩展节点提升存储和并发能力