作者:范中豪(炽凡)
客户诉求
1.1 多云日志统一分析
多云场景下的常见形态是:海外边缘安全与访问能力由 Cloudflare 承担(WAF/CDN/Access),详细日志通过 Logpush 统一落在 AWS S3 做低成本归档与合规留存;与此同时,总部的核心业务与可观测体系往往已经在阿里云侧运行(例如应用/网关/业务日志进入 SLS,告警与值班/工单体系也围绕阿里云侧建设)。结果就是同一条用户请求/同一次攻击/同一次发布变更的"证据链"分布在 AWS 与阿里云两侧,难以在一个平台里完成统一检索、关联分析与闭环处置。
对平台工程团队而言,这一现状带来的核心矛盾不是"日志存哪里",而是"分析与运营动作在哪里闭环":
- 日志在 S3,但排障/安全分析/运营分析往往分散在多套系统里(Cloudflare 控制台、Athena/Glue/EMR、CloudWatch、BI、自建告警)。
- 口径无法沉淀:同一个指标(例如 5xx、延迟 P99、WAF block 比例)在不同系统里各算各的,变更难审计、复用难、迁移难。
- 事件响应链路长:需要"先查日志 -> 再手工汇总 -> 再通知 -> 再派单/回滚",MTTD/MTTR 被人为拉长。

1.2 降本与简化运维
把 S3 作为日志存储,要把数据"用起来"(查询分析、可视化、告警联动),通常还需要额外的查询/ETL/指标与告警组件配合,链路变长、配置与排障跨多个系统,运维复杂度会明显上升。
如果要把数据直接接入 CloudWatch:用 CloudWatch Logs 采集与存储,用 Logs Insights 做查询分析,用 Dashboards/Alarms 做仪表盘与告警闭环,整体成本通常很高。
SLS 解决方案
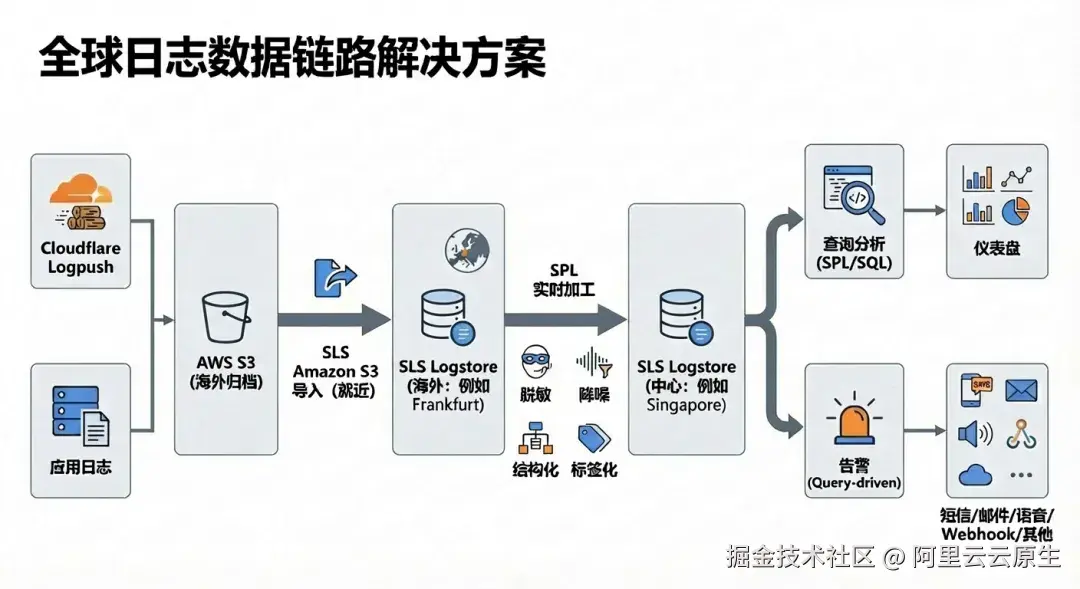
接下来将逐步分解介绍这一套 SLS 解决方案中的数据导入/加工/查询分析/仪表盘展示以及告警等功能。
2.1 从 S3 将数据导入 SLS
在很多人看来,数据导入不就是"读取-传输-写入"三板斧吗?但当你面对的是:
- 每分钟产生上千个文件的日志。
- 攻防流量瞬间从 1GB 暴涨到 10GB。
- gzip、snappy、JSON、CSV 混杂的各类数据格式。
你会发现,这绝非一个简单的"复制粘贴"操作。
接下来会先把实际导入过程中遇到的难点讲清楚,再把对应的落地做法进行说明:
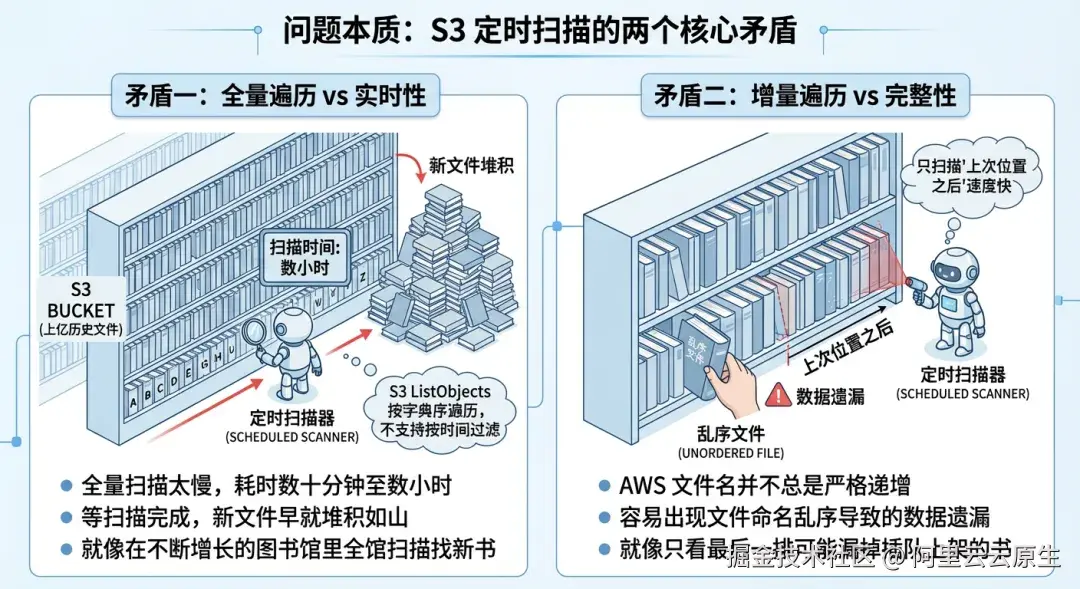
挑战一:海量小文件的"实时发现"并不简单(全量遍历 vs 实时性、增量遍历 vs 完整性)
S3 的 ListObjects 只支持按字典序遍历,不支持"按时间过滤"。当 bucket/目录历史文件量巨大时,全量扫描一轮可能需要很久;但只做增量扫描又可能因文件名乱序而漏文件。
后果:新文件发现不及时(延迟升高),或者极端情况下遗漏(完整性风险)。
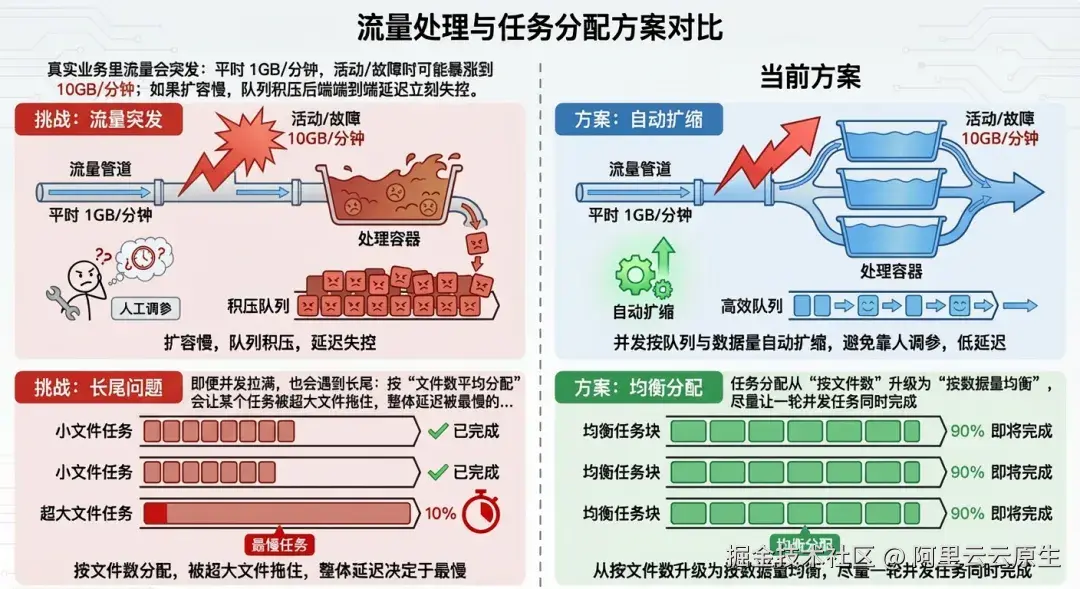
挑战二:吞吐要能跟上峰值,但不能靠"人工调参"(流量突发 + 长尾拖累)
- 真实业务里流量会突发:平时 1GB/分钟,活动/故障时可能暴涨到 10GB/分钟;如果扩容慢,队列积压后端到端延迟立刻失控。
- 即便并发拉满,也会遇到长尾:按"文件数平均分配"会让某个任务被超大文件拖住,整体延迟被最慢的那一个决定。
挑战三:格式是"混合大礼包"(压缩格式可识别,但数据格式不可自动猜)
- 同一个 bucket 往往可能混着 JSON/CSV/文本,甚至同为 JSON 也可能是"逐行 JSON / JSON 数组 / 特定服务格式(如 CloudTrail)";压缩又可能是 .gz/.snappy/.lz4/.zstd 等。
- 如果试图自动探测数据格式,会引入采样误判与额外读取开销,反而拖慢传输链路。
挑战四:正确性要可交付(不丢数据、可补偿、可定位到"哪个文件出了问题")
- 导入链路天然存在重试/重放:网络抖动、消费超时、任务重启、事件与扫描同时命中同一对象等都可能导致重复拉取。
- 更关键的是"丢失"往往更隐蔽:事件漏发、权限变更、扫描点位漂移、解析异常等都可能让某段时间的数据悄悄缺口。
针对这些难点我们的设计方案:
- 设计点一:文件发现"双机制",既追时效也保完整
- SQS 事件驱动:S3 事件 → SQS → 导入任务消费(适合文件名不规则/低延迟诉求)。
- 双模式遍历:增量追赶最新点位 + 周期全量兜底(防漏发现)。
| 对比维度 | 双模式遍历 | SQS 事件驱动 |
|---|---|---|
| 新文件发现实时性 | 分钟级 | 秒级 |
| 配置复杂度 | 简单,无需额外配置 | 需配置 S3 事件通知和 SQS |
| 可靠性 | 高(全量兜底) | 依赖 SQS 可靠性 |
| 成本 | 仅 S3 API 调用 | 额外 SQS 费用 |
| 适用场景 | 标准日志导入 | 高实时性、文件名不规则 |
- 设计点二:弹性扩缩 + 按数据量均衡分配,扛峰值、治长尾
- 并发按队列与数据量自动扩缩,避免"靠人调参"。
- 任务分配从"按文件数"升级为"按数据量均衡",尽量让一轮并发任务同时完成。
-
设计点三:压缩自动识别,数据格式显式配置(不靠猜)
- 压缩格式按后缀自动识别并解压(.gz/.snappy/.lz4/.zstd 等)。
- 数据格式由导入任务明确指定(JSON/CSV/单行/多行/CloudTrail/JSON 数组等),并补齐编码设置(默认 UTF-8,必要时指定)。
-
设计点四:点位/状态管理 + 重试/隔离 + 文件级追踪,让"补数"可落地
- 发现侧"事件 + 扫描兜底"形成补偿闭环,降低漏发现概率。
- 拉取侧维护点位与处理状态,失败文件进入重试/隔离队列,支持按对象 key 回放补数。
- 去重与幂等按对象标识(key + etag/version + offset 等)控制重复影响,让重复可控、缺口可见。
2.2 一站式数据分析
数据导入只是第一步,完整的可观测闭环还需要数据治理、交互式查询、可视化展示与智能告警。SLS 将这些能力整合在统一平台,以下介绍各环节的核心原理。
数据加工:全托管流式 ETL
SLS 数据加工基于托管的实时消费任务,使用 SPL 语法对日志进行流式处理。全托管免运维、弹性伸缩、数据秒级可见,支持按行调试与代码提示。
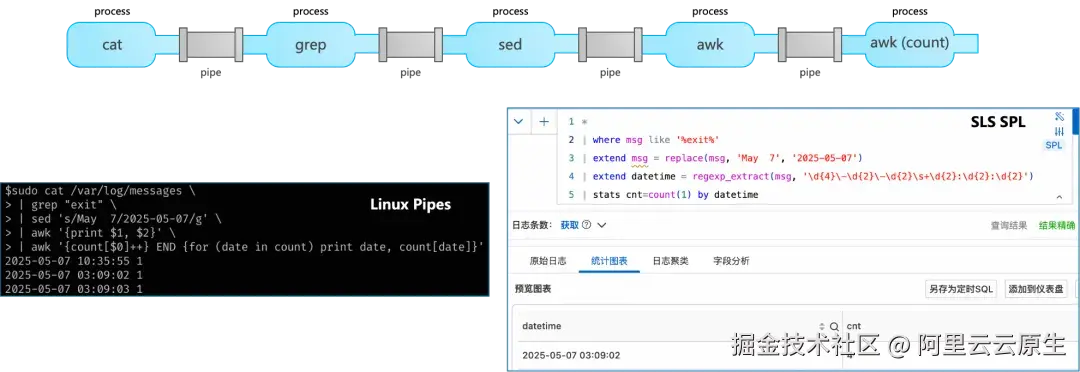
SLS 在日志 Pipeline 上以 SPL 引擎作为内核,包括列式计算、SIMD 加速、C++ 语言实现这些优势。基于 SPL 引擎进行分布式架构,我们重新设计了弹性的机制,不只是通常意义上按实例(K8s Pod 或是服务 CU)粒度的伸缩,可以按照 DataBlock 粒度(MB 级别)快速弹性。
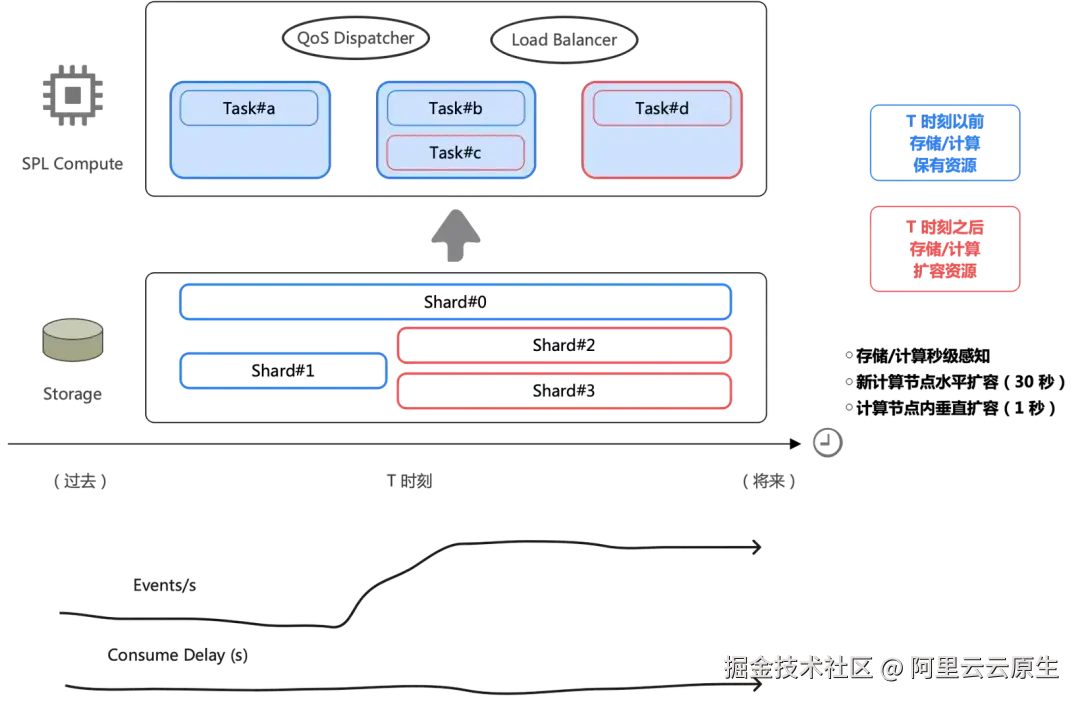
场景能力:
- 合规前置:在海外侧完成 IP → Geo 转换与脱敏,跨境后只保留合规字段,满足 GDPR/数据出境要求。
- 数据过滤:剔除无效数据,减少下游索引与存储开销。
- 结构化抽取:把原始字段加工为可分析的指标,解析嵌套 JSON 等,避免查询时重复计算。
- 字段投影:只投递黄金字段,可将跨境流量与索引成本降低 50%--80%。
- 字段富化:对日志(例如订单日志)和维表(例如用户信息表)进行字段连接(JOIN),为日志添加更多维度的信息,用于数据分析。
- 数据流转:将日志库数据的转发、汇总到目标库,也可以按字段内容进行任意转发,十分灵活。
查询分析:高性能引擎,秒级响应
SLS 提供高性能查询引擎,支持索引模式 (秒级响应百亿级数据)与扫描模式 (轻量级分析)。查询直接作用于索引,无需预建数据集或刷新延迟。针对超大规模数据分析场景,SLS 提供 SQL 独享版 ** **1 ,包括 SQL 增强 和 SQL 完全精确两种模式。

查询引擎与能力:
- 近百种分析函数:内置统计、聚合、字符串、时间、地理等函数,开箱即用。
- 跨库联合查询:通过 StoreView 支持跨 Project、跨 Logstore 的数据关联查询。
- SQL 独享版:大数据量场景下提供高精度分析能力,避免采样误差。
- 定时 SQL:支持定时执行 SQL 查询,用于报表生成与指标预计算。
仪表盘:丰富可视化,开箱即用
SLS 仪表盘是日志服务提供的数据可视化工具,将查询分析结果以图形化界面展示。仪表盘通常包含多个统计图表,汇总并呈现关键性能指标、重要数据和分析结果。
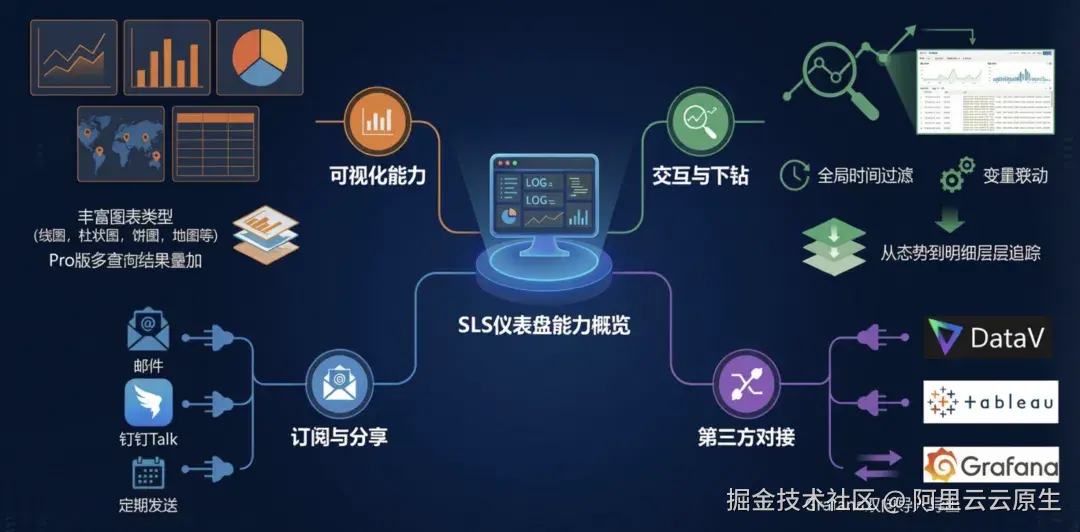
可视化能力:
- 丰富图表类型:支持表格、线图、柱状图、饼图、地图等多种统计图表,Pro 版本支持多查询结果叠加展示。
- 交互与下钻:支持全局时间过滤、变量联动、图表下钻,从态势到明细层层追踪。
- 订阅与分享:支持定期将仪表盘渲染为图片,通过邮件或钉钉群发送;支持控制台内嵌到第三方系统。
- 第三方对接:可与 DataV、Grafana、Tableau 等可视化工具对接,支持双向导入导出 Grafana 仪表盘。
告警:一站式智能运维平台
SLS 告警是一站式的告警监控、降噪、事务管理、通知分派的智能运维平台,由告警监控、告警管理、通知(行动)管理等子系统组成。接入日志或时序数据后,数分钟内即可创建监控任务、通知渠道和告警策略。
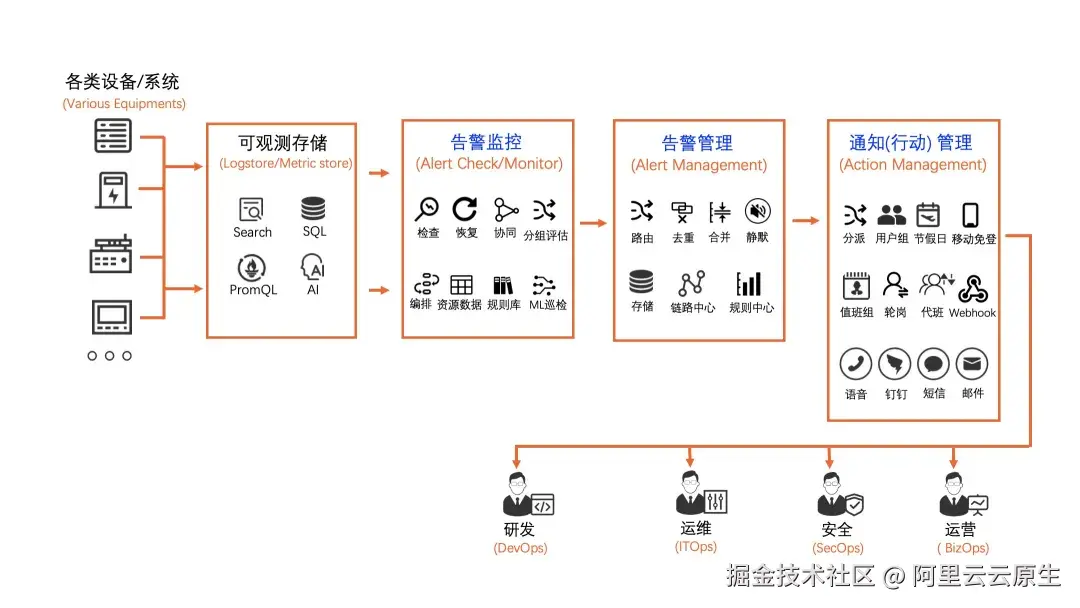
功能优势:
- 低成本免运维:SaaS 形态,除短信/语音通知外,告警监控、事务管理等不额外收费。
- 降噪与分派:支持分组、去重、抑制、升级,避免告警风暴;支持按规则自动分派到不同团队。
- 通知渠道丰富:原生集成钉钉/企微/飞书/Slack、短信/语音、Webhook。
2.3 运维简化(用一体化替代多产品组合)
2.3.1 AWS 多产品组合:为了实现同样闭环通常要哪些组件
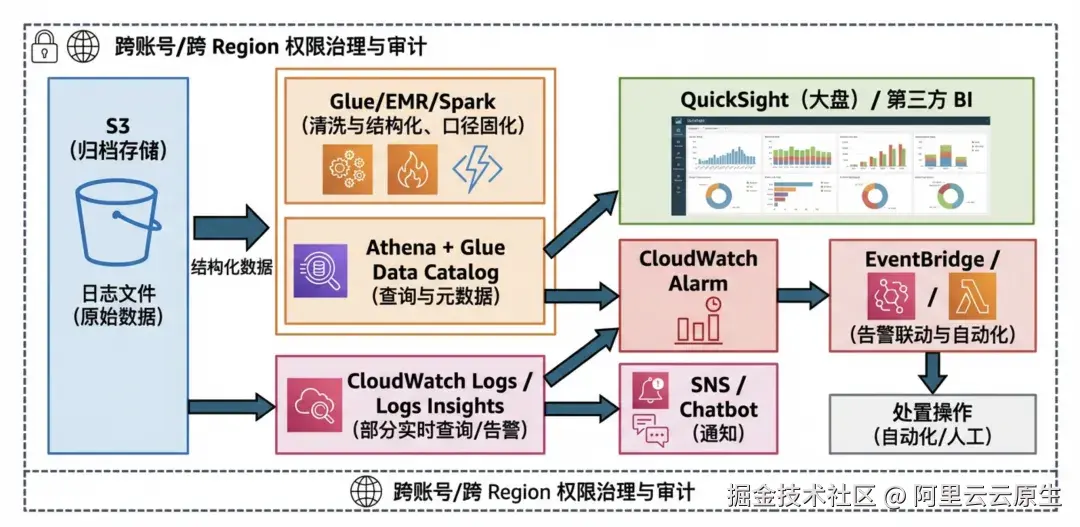
组件多并不一定不好,但当你的诉求是"统一口径、分钟级闭环、低成本可控",多组件意味着:
- 链路更长:数据要搬更多次(ETL、落中间表、刷新数据集)。
- 故障面更大:任一环节抖动都会影响端到端时效。
- 计费更碎:存储/扫描/ETL/告警/可视化/网络每项都在涨。
2.3.2 SLS 一体化 vs AWS 多产品组合
在 SLS 内把"导入 + 加工 + 索引 + 查询 + 仪表盘 + 告警/事务"做成一个可复用的工程模板,用模板交付首版,用策略迭代成本与效果。
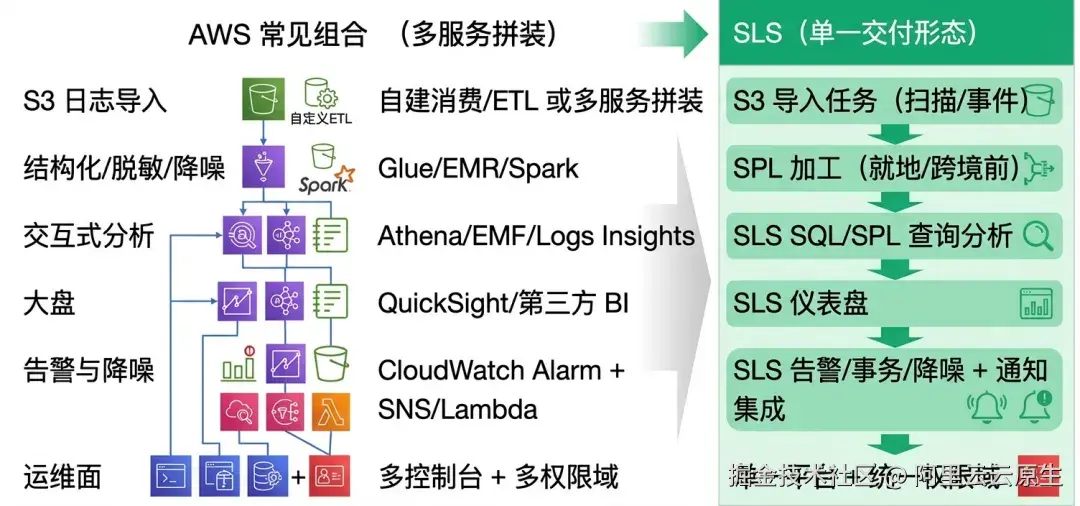
出海企业日志分析架构升级案例
背景与解决方案
某大型全球化出海企业,业务覆盖欧洲、亚太、北美等多个区域,通过主流 CDN 与安全服务实现全球访问加速及 Web 应用防护。为满足海外数据合规与审计要求,该企业将其安全与访问日志通过平台原生日志推送能力(Logpush),持续归档至公有云对象存储中,用于长期留存与后续分析。
当前在 AWS 上采用多组件组合实现海外日志的分析与监控,遇到如下问题:
- 数据分散:S3 分布在法兰克福、东京等多个 Region,数据孤岛难以统一管理与分析。
- 查询分析成本高:Athena 按扫描量计费,CloudWatch Logs Insights 查询能力受限且跨 Region 需分别查询,日常检索与告警查询成本随频次线性增长。
此外,ETL 依赖 Glue/Lambda 需自行维护,QuickSight 可视化需额外授权且存在同步延迟,CloudWatch Alarms 配置分散缺乏统一降噪能力,多产品组合带来运维复杂度高、成本不可控等问题。
基于阿里云 SLS 构建统一的可观测分析平台,实现:
- 统一数据加工:通过 SPL 在海外侧完成数据治理(字段裁剪、IP 脱敏、Geo 富化),降低跨境传输成本。
- 统一查询分析:在国内中心 Logstore 汇聚黄金数据,提供亿级数据秒级交互式查询。
- 统一可视化:一站式仪表盘,无需额外 BI 工具。
- 统一告警闭环:基于 SLS 查询分析的智能告警,支持降噪、分派与多渠道通知。
3.1 数据链路
数据从 Cloudflare Logpush 推送至 AWS S3 海外各 Region 归档,SLS 通过事件驱动或定时扫描导入同地域 Logstore,经 SPL 加工后汇聚至国内中心 Logstore,支撑统一的查询分析、仪表盘与告警。
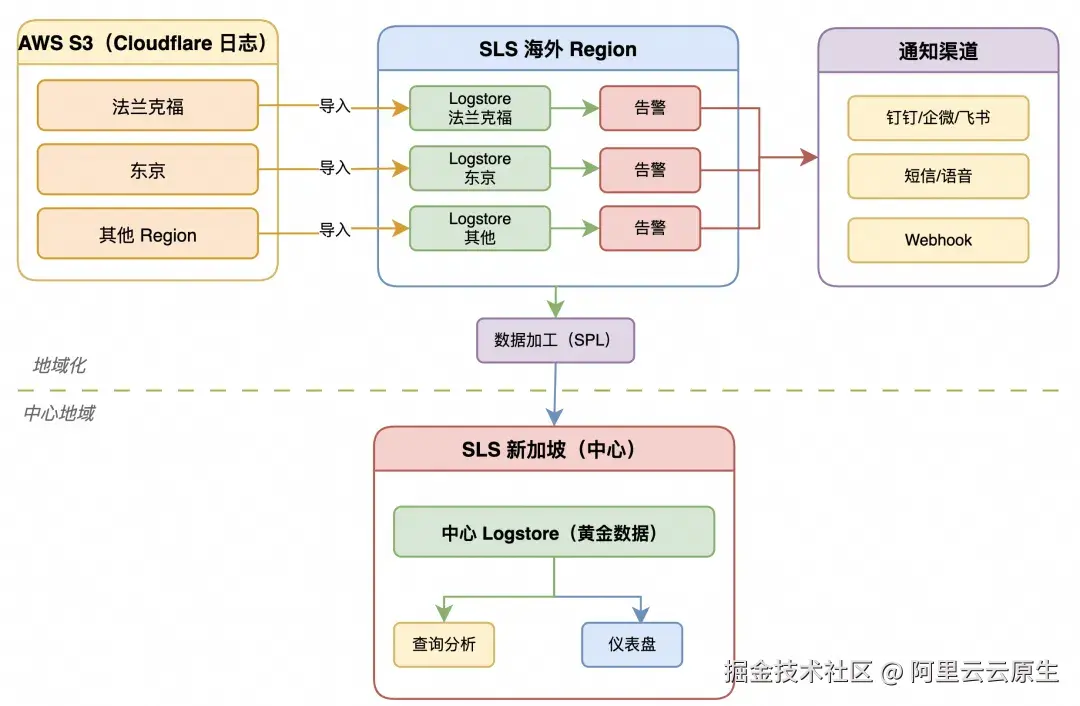
3.1.1 SPL 数据加工示例
示例原始日志(Cloudflare WAF 日志)
Cloudflare WAF 原始日志示例,包含 ClientIP、SecurityAction、SecuritySources 等敏感及安全字段,覆盖 block/allow/challenge 三种安全动作场景。这些日志可直接用于测试 SPL 加工语句。
swift
{
"EdgeStartTimestamp": "2024-12-25T10:30:00Z",
"RayID": "abc123def456",
"ClientIP": "203.0.113.50",
"OriginIP": "10.0.0.100",
"ClientRequestURI": "/api/v1/users?id=123",
"ClientRequestMethod": "POST",
"ClientRequestReferer": null,
"SecurityAction": "block",
"SecurityRuleID": "rule_001",
"SecuritySources": "[{\"source\":\"waf\",\"action\":\"block\"}]",
"OriginResponseStatus": 200,
"OriginResponseTime": 150,
"ResponseHeaders": "{\"x-cache\":\"MISS\"}"
}以下 SPL 脚本在海外侧完成数据治理:时间标准化、IP 转 Geo 地理信息、IP 脱敏为匿名指纹、安全元数据解析与风险标签化。最终通过 project-away 移除 ClientIP、OriginIP 等敏感字段,仅保留黄金字段跨境传输。
ini
-- 核心追踪与时间标准化
*
| extend __time__ = cast(to_unixtime(date_parse(EdgeStartTimestamp, '%Y-%m-%dT%H:%i:%SZ')) as bigint)
| extend RequestId = RayID
| extend RequestPath = url_extract_path(ClientRequestURI)
-- IP -> Geo(在海外完成)
| extend
GeoCountry = ip_to_country(ClientIP),
GeoRegion = ip_to_province(ClientIP),
GeoCity = ip_to_city(ClientIP)
-- IP 脱敏:保留匿名指纹(可选),不跨境携带原始 IP
| extend ClientFingerprint = to_base64(sha256(to_utf8(ClientIP)))
-- 安全元数据解析/标签化
| expand-values -keep SecuritySources
| parse-json -prefix='Security' SecuritySources
| extend IsHighRisk = if(ClientRequestMethod = 'POST' and (ClientRequestReferer is null or SecurityAction = 'block'), 1, 0)
-- 最终降噪与字段投影
| project-away ClientIP, OriginIP, ResponseHeaders, RayID加工后示例数据
加工后的数据已完成 Geo 富化、IP 脱敏、风险标签化,敏感字段已移除,可直接用于下游查询分析与告警:
json
{
"RequestPath": "/api/v1/users",
"__time__": "1735122600",
"RequestId": "abc123def456",
"ClientFingerprint": "O1zTaFfLyH1ZqEHS03UiLSNMzwMX+4ZW7OsIVsDGgEg=",
"OriginResponseTime": "150",
"GeoCity": "理查森",
"ClientRequestURI": "/api/v1/users?id=123",
"IsHighRisk": "1",
"EdgeStartTimestamp": "2024-12-25T10:30:00Z",
"SecurityAction": "block",
"SecurityRuleID": "rule_001",
"Securityaction": "block",
"GeoCountry": "美国",
"GeoRegion": "德克萨斯州",
"OriginResponseStatus": "200",
"Securitysource": "waf",
"ClientRequestMethod": "POST"
}3.1.2 查询分析示例
示例 1:WAF 规则命中统计 ------ 按规则聚合命中次数、高风险占比与独立攻击者数
vbnet
* | SELECT
SecurityRuleID,
count(*) AS TotalHits,
count_if(IsHighRisk = 1) AS HighRiskHits,
approx_distinct(ClientFingerprint) AS UniqueClients
FROM log
WHERE SecurityRuleID IS NOT NULL AND SecurityRuleID <> ''
GROUP BY SecurityRuleID
ORDER BY TotalHits DESC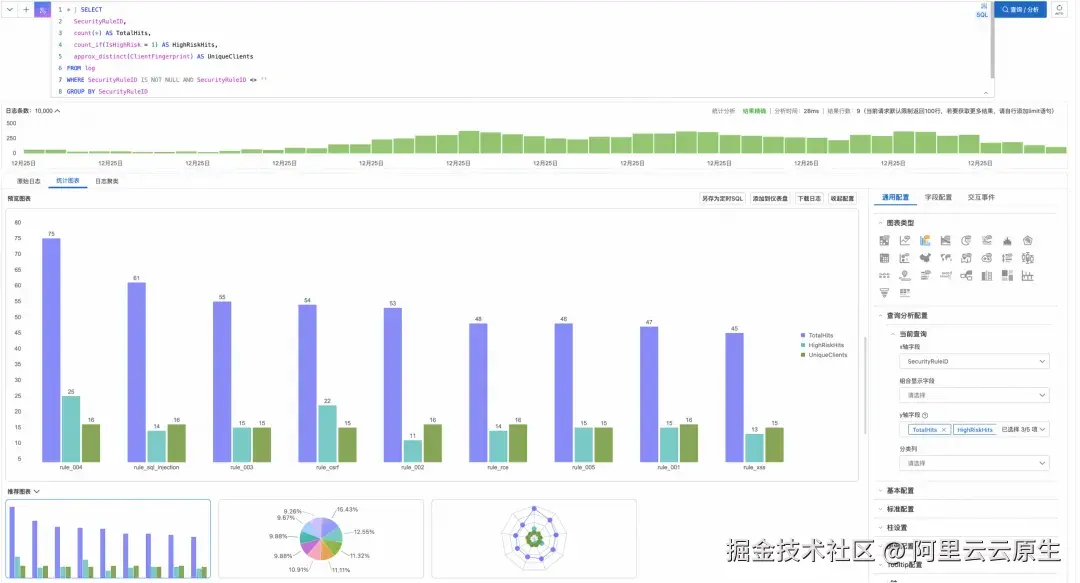
示例 2:攻击源地域 Top 10 ------ 按国家/城市聚合拦截次数与独立攻击者数
vbnet
* | SELECT
GeoCountry,
GeoCity,
count(*) AS AttackCount,
approx_distinct(ClientFingerprint) AS UniqueAttackers
FROM log
WHERE SecurityAction = 'block'
GROUP BY GeoCountry, GeoCity
ORDER BY AttackCount DESC
LIMIT 10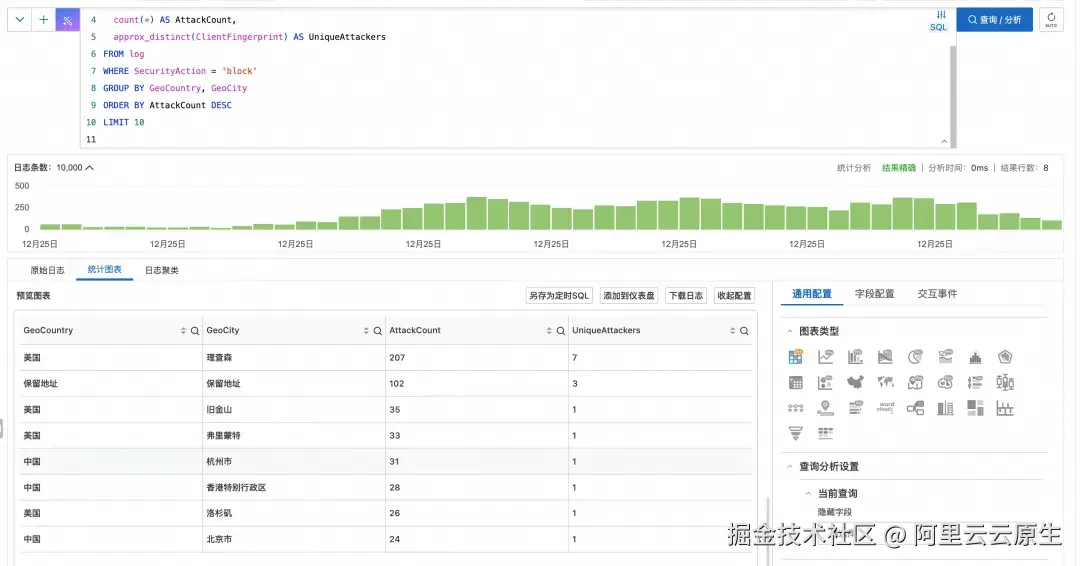
示例 3:源站 5xx 错误趋势 ------ 按分钟聚合错误次数、错误率与总请求量
scss
* | SELECT
time_series(__time__, '1m', '%Y-%m-%d %H:%i:%s', '0') AS TimeBucket,
count_if(OriginResponseStatus >= 500) AS Origin5xxCount,
count_if(OriginResponseStatus >= 500) * 100.0 / count(*) AS Origin5xxRate,
count(*) AS TotalRequests
FROM log
GROUP BY TimeBucket
ORDER BY TimeBucket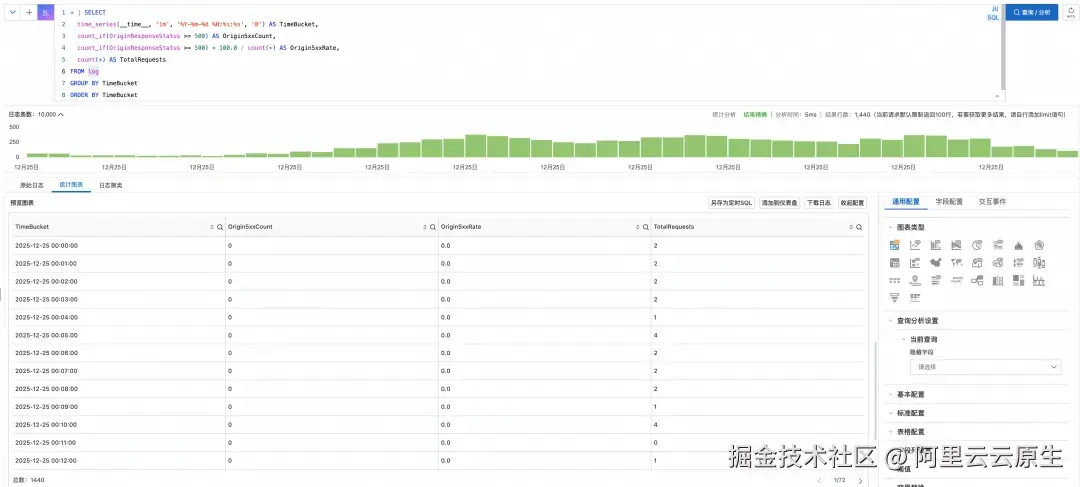
示例 4:请求延迟分位分析 ------ 按路径聚合 P50/P90/P99 延迟,定位慢接口
vbnet
* | SELECT
RequestPath,
count(*) AS RequestCount,
approx_percentile(OriginResponseTime, 0.50) AS LatencyP50,
approx_percentile(OriginResponseTime, 0.90) AS LatencyP90,
approx_percentile(OriginResponseTime, 0.99) AS LatencyP99
FROM log
WHERE OriginResponseTime IS NOT NULL
GROUP BY RequestPath
HAVING count(*) > 100
ORDER BY LatencyP99 DESC
LIMIT 20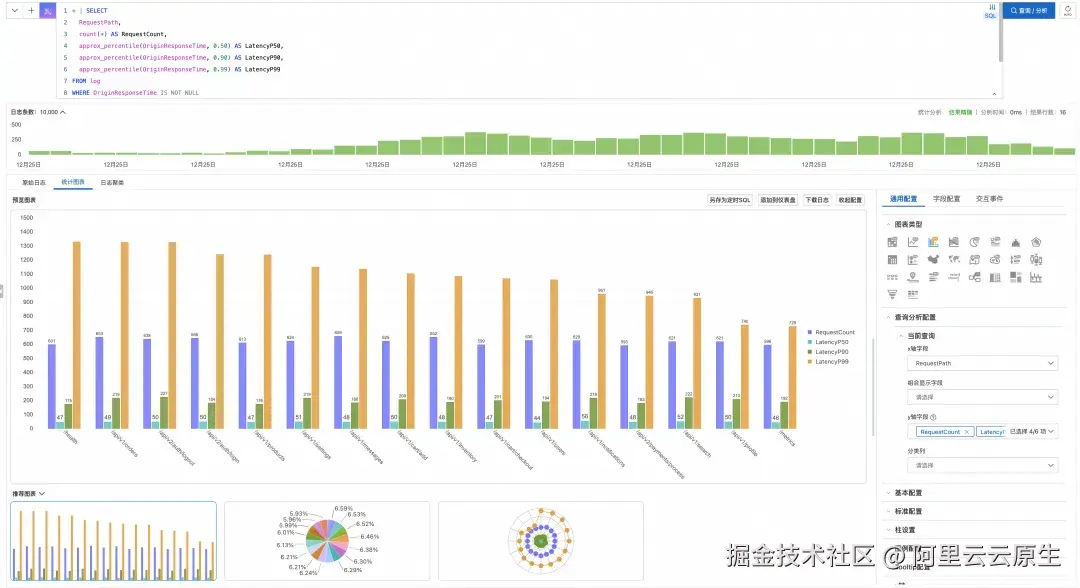
3.1.3 告警规则示例
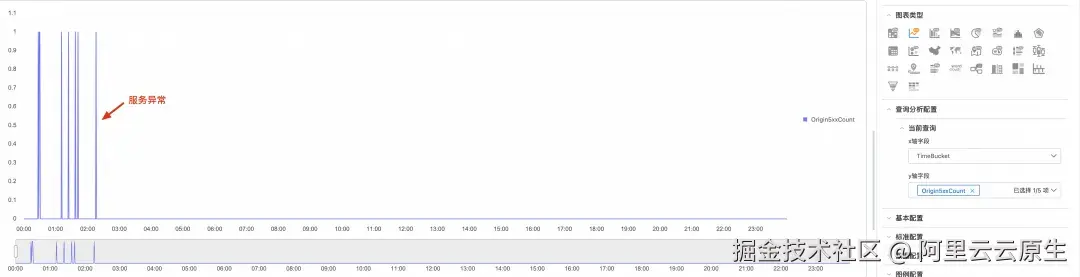
告警 1:源站 5xx 突增 ------ 错误率超过 5% 时触发,快速发现源站异常
scss
* | SELECT
count_if(OriginResponseStatus >= 500) * 100.0 / count(*) AS Origin5xxRate
FROM log
HAVING Origin5xxRate > 5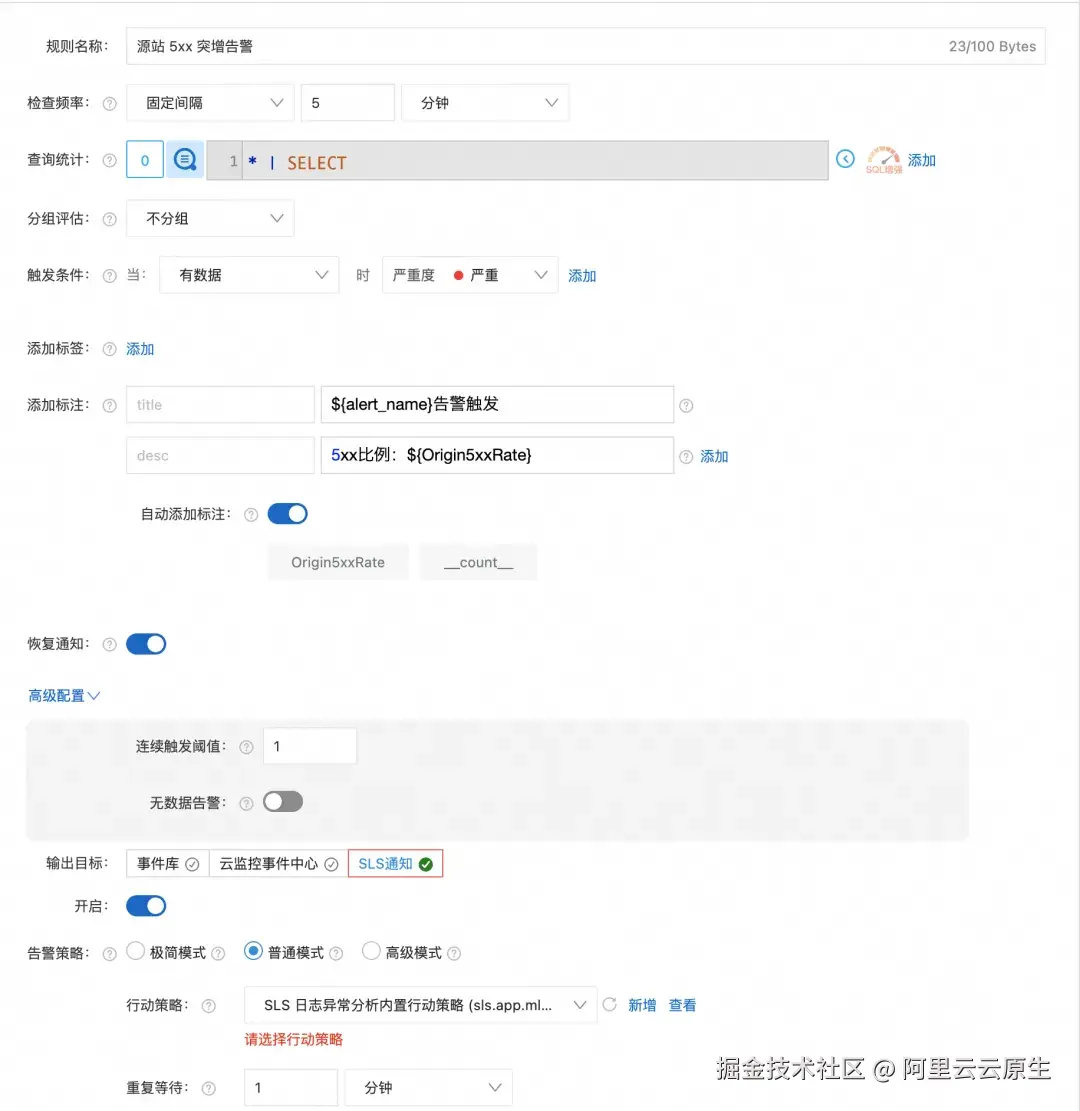
告警 2:高风险请求突增 ------ 次数超 100 或占比超 10% 时触发,识别潜在攻击
scss
* | SELECT
count_if(IsHighRisk = 1) AS HighRiskCount,
count_if(IsHighRisk = 1) * 100.0 / count(*) AS HighRiskRate
FROM log
HAVING HighRiskCount > 100 OR HighRiskRate > 10告警 3:WAF 拦截量突增 ------ 拦截超 1000 次或独立攻击者超 50 时触发,感知攻击态势
scss
* | SELECT
count_if(SecurityAction = 'block') AS BlockCount,
approx_distinct(ClientFingerprint) AS UniqueAttackers
FROM log
HAVING BlockCount > 1000 OR UniqueAttackers > 503.2 成本对比
本节以"能力对齐"的方式做端到端 TCO 对比,覆盖 SLS 在该方案中承担的完整闭环能力:数据传输(S3 导入)、数据加工(SPL)、存储与索引、查询分析、告警、可视化(约 100 个仪表盘)。为了避免"只算存储/只算查询"导致结论失真,AWS 侧选择与之最接近的 CloudWatch 一体化口径作为对标(Logs + Logs Insights + Dashboards + Alarms)。
3.2.1 口径与具体参数
- 导入写入量:20 TB/天(S3 → SLS)。
- 公网拉取流量(S3 → SLS):导入拉取的是 S3 上的压缩对象,按"压缩后约为原始 1/10"估算 → 2 TB/天(2,048 GB/天)。
- 查询负载:20,000 次/天,峰值约 24 QPS;扫描量约 100 TB/天。
- 告警负载:20 条规则,每 3 分钟执行一次(9,600 次/天),Webhook 通知。
- 可视化:约 100 个仪表盘。
- 数据加工:对所有数据进行过滤、清洗、分发。
- 存储时间:14 天。
3.2.2 单价来源说明
- 阿里云 Log Service(SLS) :单价来自阿里云国际站 Log Service Pricing 页面(按写入量计费 ),包含
Raw ingest data volume、Storage size of log data、Read traffic from the Internet,并注明data transformation / data delivery / alarms不额外计费。见:Log Service Pricing ** **2 。 - AWS CloudWatch :单价来自 AWS 官方 CloudWatch Pricing 页面(本节按
US East (N. Virginia)),覆盖CloudWatch Logs ingestion、Log storage、Logs Insights scanned、Dashboards、Standard alarm。见:CloudWatch Pricing ** **3 。 - AWS 公网出站(S3 → Internet) :单价来自 AWS 官方 Amazon S3 Pricing 页面 "Data transfer" 表格(包含"每月前 100GB 免费 + 分段单价")。本节按常见分段口径示例:First 10 TB / Month、Next 40 TB / Month、Next 100 TB / Month。见:Amazon S3 Pricing ** **4 。
3.2.3 分能力对齐与计算
1)数据传输 / 导入(把 S3 归档变为可检索数据)
SLS(按写入量计费 / Pay-by-ingested-data)
ini
1 TB = 1,024 GB
20 TB/天 = 20,480 GB/天
月费用 = 20,480 GB/天 × 0.061 USD/GB × 30 天/月
= 37,478.40 USD/月公网网络费用(S3 → SLS 拉取,计入 SLS 方案 TCO)
ini
说明:从 S3 拉取的是压缩对象,按"压缩后约为原始 1/10"估算网络出站流量
公网出站量(GB/天)= 20,480 GB/天 ÷ 10 = 2,048 GB/天
公网出站量(GB/月)= 2,048 GB/天 × 30 天/月 = 61,440 GB/月
按 AWS 口径:每月前 100 GB 公网出站免费 → 计费量 = 61,440 - 100 = 61,340 GB/月
分段计费示例(以 AWS 定价页 Data transfer 表格为准):
- First 10 TB / Month:10,240 GB × 0.09 USD/GB = 921.60 USD
- Next 40 TB / Month:40,960 GB × 0.085 USD/GB = 3,481.60 USD
- Next 100 TB / Month: (61,340 - 51,200) GB = 10,140 GB × 0.07 USD/GB = 709.80 USD
月费用合计 = 921.60 + 3,481.60 + 709.80 = 5,113.00 USD/月AWS(CloudWatch Logs ingestion)
月费用 = 20,480 GB/天 × 0.50 USD/GB × 30 天/月
= 307,200.00 USD/月2)数据加工(过滤 / 清洗 / 分发)
- SLS:按写入量计费模式下,官方说明加工/投递不额外计费。
- AWS:等价实现通常依赖 Glue/EMR/Lambda/Firehose Transform 等,费用取决于作业类型与运行时长(本节先不计入)。
3)存储(14 天保留)
- SLS "30 天免费" → 0 USD/月
- AWS(CloudWatch Log storage)
scss
稳态存储量(14 天保留)= 20,480 GB/天 × 14 天 = 286,720 GB
月费用 = 286,720 GB × 0.03 USD/(GB×month)
= 8,601.60 USD/月4)查询分析
- SLS:按写入量计费模式下,不单独按扫描量计费。
- AWS(Logs Insights scanned)。
ini
100 TB/天 × 1,024 GB/TB = 102,400 GB/天
月费用 = 102,400 GB/天 × 0.005 USD/GB × 30 天/月
= 15,360.00 USD/月5)告警
-
SLS:按写入量计费模式下告警不额外计费。
-
AWS(CloudWatch Alarms,Standard)。
月费用 = 20 个告警 × 0.10 USD/个/月
= 2.00 USD/月
6)仪表盘可视化(约 100 个 Dashboard)
-
SLS:不按"Dashboard 个数"单独计费。
-
AWS(CloudWatch Dashboards)。
月费用 = 100 个 Dashboard × 3.00 USD/个/月
= 300.00 USD/月
3.2.4 费用汇总
SLS(月度)≈ 37,478.40(写入)+ 5,113.00(S3 公网出站)= 42,591.40 USD/月
AWS(月度)= 307,200.00(ingestion)
+ 8,601.60(storage)
+ 15,360.00(Logs Insights scanned)
+ 2.00(Alarms)
+ 300.00(Dashboards)
= 331,463.60 USD/月因此,在本节口径与参数下:
ini
月度节省金额 = 331,463.60 - 42,591.40
= 288,872.20 USD/月
成本降低 = 1 - (SLS / AWS)
= 1 - (42,591.40 / 331,463.60)
≈ 87.15%3.2.5 结论
日志文件通常经过压缩归档,本文按压缩比 10:1(即压缩后约为原始大小的 1/10)进行估算。在此假设下,SLS 方案端到端 TCO 相比 AWS(CloudWatch 一体化)降低 87.15% ;同时由于 SLS 按写入量计费 30 天存储免费,本节按照 14 天计算,相当于额外获得 16 天的免费存储。
此外,SLS 的数据加工/投递与告警等能力在该计费模式下不额外计费,Dashboard 也不按"个数"单独收费;而在 AWS 侧往往需要为 Dashboards/Alarms 以及配套的 ETL/投递组件分别计费,意味着用户可以免费获得更多的额外能力。
总结展望
在数据迁移过程中,跨云/跨境传输的网络质量与费用均不可忽视,因此我们实现了通过 CloudFront 来降低跨云/跨境传输开销的能力以供用户选择。
同时,后续我们也扩展了 GCP/Azure 的数据导入,以支持多云数据统一观测。
参考:
-
SLS 从 Amazon S3 导入
Alibaba Cloud: Import data from Amazon S3
-
AWS CloudWatch 定价
Amazon CloudWatch Pricing
-
AWS Athena 定价
Amazon Athena Pricing
-
AWS Glue 定价
AWS Glue Pricing
-
AWS S3 定价
Amazon S3 Pricing
-
SLS 按写入量定价
Log Service Pricing
相关链接:
1 SQL 独享版
help.aliyun.com/zh/sls/dedi...
2 Log Service Pricing
www.alibabacloud.com/zh/product/...
3 CloudWatch Pricing
4 Amazon S3 Pricing