|----------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
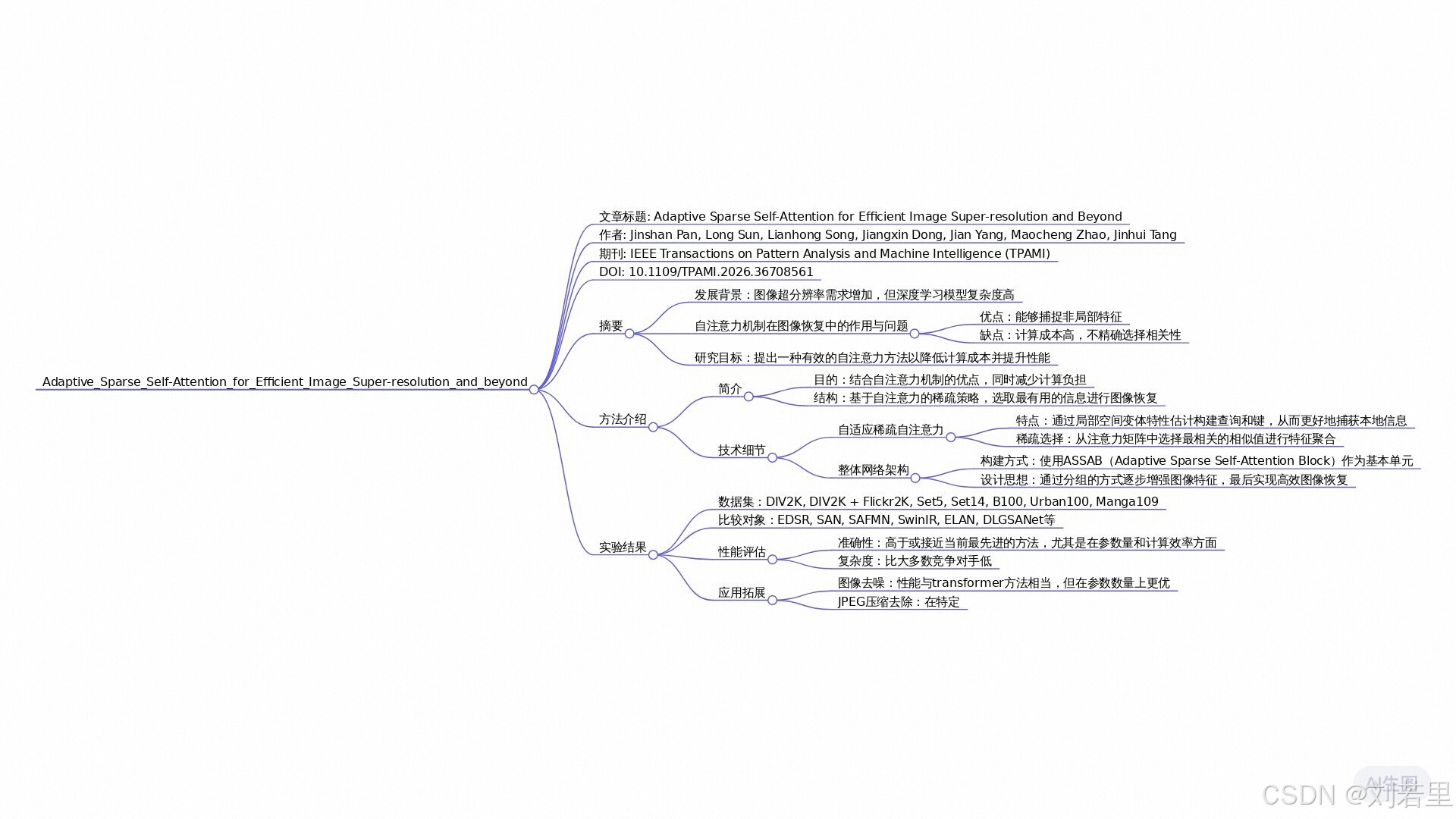
| 论文标题 | Adaptive Sparse Self-Attention for Efficient Image Super-resolution and Beyond 自适应稀疏自注意力在高效图像超分辨率及更广泛应用中的研究 |
| 论文作者 | Pan, Jinshan; Sun, Long; Song, Lianhong; Dong, Jiangxin; Yang, Jian; |
| 发表日期 | 2026年 |
| GB引用 | Pan J, Sun L, Song L, et al. Adaptive Sparse Self-Attention for Efficient Image Super-resolution and beyondJ. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. |
| DOI | https://doi.org/10.1109/TPAMI.2026.3670856 |
代码与原文可在资源库中下载
全文概述
本文提出了一种自适应稀疏自注意力机制,旨在解决图像超分辨率任务中传统自注意力机制存在的计算效率低、局部细节恢复能力不足的问题。现有基于Transformer的方法通过全局上下文建模提升图像重建质量,但其计算复杂度高且依赖所有token间的相似度计算,导致无关token干扰特征聚合,同时缺乏对局部高频信息的有效建模。
针对这些问题,作者设计了两阶段解决方案:首先通过局部空间变分特征估计模块,利用动态卷积网络提取局部空间变异特征,替代传统线性投影操作,增强局部细节建模能力;其次提出稀疏自注意力机制,通过ReLU等选择性函数筛选关键token的相似度值,减少无关token干扰,实现高效特征聚合。
实验表明,该方法在Urban100等基准数据集上以更少参数量和计算量达到SOTA性能,且在图像去噪、JPEG伪影去除等任务中表现出色。理论分析证明该方法同时建模局部与非局部特征,通过稀疏选择机制提升结构细节恢复能力,为Transformer在图像修复任务中的应用提供了新思路。
术语解释
- 自适应稀疏自注意力(Adaptive Sparse Self-Attention): 一种改进的自注意力机制,通过选择性函数动态筛选关键token的相似度值,减少无关token干扰,实现高效特征聚合。该方法在保持全局上下文建模能力的同时,显著降低计算复杂度。
- 局部空间变分特征估计(Local Spatial-Variant Feature Estimation): 基于动态卷积网络的特征提取模块,通过为每个像素生成K×K动态卷积核,捕捉自然图像的局部空间变异细节,替代传统线性投影操作,增强局部纹理建模能力。
- 稀疏自注意力(Sparse Self-Attention): 采用ReLU等选择性函数对自注意力矩阵进行稀疏化处理,仅保留高相似度token的特征贡献,抑制低相关token干扰。该机制将计算复杂度从O(N²)降至O(N),同时提升结构细节恢复质量。
Adaptive Sparse Self-Attention Block 框架
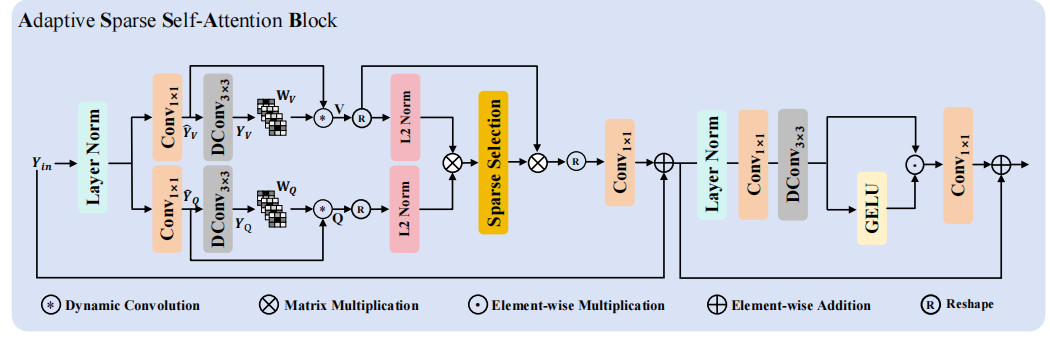
Adaptive Sparse Self-Attention Block 代码实现
ASSA Block 代码
python
'''自适应稀疏自注意力模块(Adaptive Sparse Self-Attention, ASSA)
核心设计:整合"动态深度卷积 + 自适应稀疏策略 + 训练-测试双模式",通过"特征投影→动态增强→稀疏注意力计算→特征还原"的流程,
自适应控制注意力稀疏度,在训练时探索全局依赖,测试时通过局部窗口(TLC)提升推理效率,平衡模型性能与部署效率
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from idynamic_dwconv import IDynamicDWConv
class MaskedSoftmax(nn.Module):
def __init__(self):
super(MaskedSoftmax, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
mask = x > 0
x = self.softmax(x)
x = torch.where(mask > 0, x, torch.zeros_like(x))
return x
class TopK(nn.Module):
def __init__(self):
super(TopK, self).__init__()
def forward(self, x):
b, h, C, _ = x.shape
mask = torch.zeros(b, h, C, C, device=x.device, requires_grad=False)
index = torch.topk(x, k=int(C/4), dim=-1, largest=True)[1]
mask.scatter_(-1, index, 1.)
result = torch.where(mask > 0, x, torch.zeros_like(x))
return result
# Sparse Self-Attention
class SparseSelfAttention(nn.Module):
"""
自适应稀疏自注意力模块(Adaptive Sparse Self-Attention, ASSA)
功能:动态特征增强+自适应稀疏注意力,平衡全局依赖捕捉与计算效率
核心设计:
- 动态深度卷积:IDynamicDWConv增强QV特征,提升局部依赖捕捉
- 多稀疏策略适配:支持ReLU/Softmax/MaskedSoftmax/TopK/GELU/Sigmoid多种激活,灵活控制稀疏度
- 训练-测试双模式:训练时全局稀疏注意力,测试时TLC局部窗口注意力,兼顾性能与推理速度
- 可学习温度因子:自适应调整注意力分布锐度,优化稀疏关联
Args:
dim: 输入/输出通道数
num_heads: 注意力头数
bias: 输出投影是否带偏置(默认False)
tlc_flag: 是否启用TLC测试模式(默认True)
tlc_kernel: 测试时局部窗口尺寸(默认48)
activation: 稀疏策略激活函数(默认'relu')
"""
def __init__(self, dim, num_heads, bias, tlc_flag=True, tlc_kernel=48, activation='relu'):
super(SparseSelfAttention, self).__init__()
self.tlc_flag = tlc_flag # TLC flag for validation and test
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.project_in = nn.Conv2d(dim, dim * 2, 1, bias=False)
self.dynamic_conv = IDynamicDWConv(dim * 2, kernel_size=3, bias=False)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
self.act = nn.Identity()
if activation == 'relu':
self.act = nn.ReLU()
elif activation == 'softmax':
self.act = nn.Softmax(dim=-1)
elif activation == 'maskedsoftmax':
self.act = MaskedSoftmax()
elif activation == 'topk':
self.act = TopK()
elif activation == 'gelu':
self.act = nn.GELU()
elif activation == 'sigmoid':
self.act = nn.Sigmoid()
# [x2, x3, x4] -> [96, 72, 48]
self.kernel_size = [tlc_kernel, tlc_kernel]
def _forward(self, qv):
q, v = qv.chunk(2, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = F.normalize(q, dim=-1)
k = F.normalize(v, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = self.act(attn)
out = (attn @ v)
return out
def forward(self, x):
b, c, h, w = x.shape
qv = self.dynamic_conv(self.project_in(x))
if self.training or not self.tlc_flag:
out = self._forward(qv)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
# Then we use the TLC methods in test mode
qv = self.grids(qv) # convert to local windows
out = self._forward(qv)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=qv.shape[-2], w=qv.shape[-1])
out = self.grids_inverse(out) # reverse
out = self.project_out(out)
return out
# Code from [megvii-research/TLC] https://github.com/megvii-research/TLC
def grids(self, x):
b, c, h, w = x.shape
self.original_size = (b, c // 2, h, w)
assert b == 1
k1, k2 = self.kernel_size
k1 = min(h, k1)
k2 = min(w, k2)
num_row = (h - 1) // k1 + 1
num_col = (w - 1) // k2 + 1
self.nr = num_row
self.nc = num_col
import math
step_j = k2 if num_col == 1 else math.ceil((w - k2) / (num_col - 1) - 1e-8)
step_i = k1 if num_row == 1 else math.ceil((h - k1) / (num_row - 1) - 1e-8)
parts = []
idxes = []
i = 0# 0~h-1
last_i = False
while i < h and not last_i:
j = 0
if i + k1 >= h:
i = h - k1
last_i = True
last_j = False
while j < w and not last_j:
if j + k2 >= w:
j = w - k2
last_j = True
parts.append(x[:, :, i:i + k1, j:j + k2])
idxes.append({'i': i, 'j': j})
j = j + step_j
i = i + step_i
parts = torch.cat(parts, dim=0)
self.idxes = idxes
return parts
def grids_inverse(self, outs):
preds = torch.zeros(self.original_size).to(outs.device)
b, c, h, w = self.original_size
count_mt = torch.zeros((b, 1, h, w)).to(outs.device)
k1, k2 = self.kernel_size
k1 = min(h, k1)
k2 = min(w, k2)
for cnt, each_idx in enumerate(self.idxes):
i = each_idx['i']
j = each_idx['j']
preds[0, :, i:i + k1, j:j + k2] += outs[cnt, :, :, :]
count_mt[0, 0, i:i + k1, j:j + k2] += 1.
del outs
torch.cuda.empty_cache()
return preds / count_mt
if __name__ == "__main__":
device = torch.device('cuda:0'if torch.cuda.is_available() else'cpu')
x = torch.randn(1, 64, 32, 32).to(device)
model = SparseSelfAttention(64, num_heads=4, tlc_flag=True, tlc_kernel=48, activation='relu', bias=False).to(device)
y = model(x)
print("输入特征维度: ", x.shape)
print("输出特征维度: ", y.shape)
print(f"ASSA 注意力模块参数量: {sum(p.numel() for p in model.parameters())/1e6:.2f}M")Idynamic Dwconv代码
python
"""
code from github: https://github.com/Atten4Vis/DemystifyLocalViT
Thanks to the bravo job from Han, Qi and Fan, Zejia and Dai, Qi and Sun, Lei and Cheng, Ming-Ming and Liu, Jiaying and Wang, Jingdong
Paper: "On the Connection between Local Attention and Dynamic Depth-wise Convolution" ICLR 2022 Spotlight
"""
"""
@inproceedings{han2021connection,
title={On the Connection between Local Attention and Dynamic Depth-wise Convolution},
author={Han, Qi and Fan, Zejia and Dai, Qi and Sun, Lei and Cheng, Ming-Ming and Liu, Jiaying and Wang, Jingdong},
booktitle={International Conference on Learning Representations},
year={2022}
}
"""
from torch.autograd import Function
import torch
from torch.nn.modules.utils import _pair
import torch.nn as nn
from einops import rearrange
from collections import namedtuple
import cupy # idynamic implement is based on cupy-cuda
from string import Template
Stream = namedtuple('Stream', ['ptr'])
def Dtype(t):
if isinstance(t, torch.cuda.FloatTensor):
return 'float'
elif isinstance(t, torch.cuda.DoubleTensor):
return 'double'
# @cupy._util.memoize(for_each_device=True)
# def load_kernel(kernel_name, code, **kwargs):
# code = Template(code).substitute(**kwargs)
# kernel_code = cupy.cuda.compile_with_cache(code)
# return kernel_code.get_function(kernel_name)
@cupy._util.memoize(for_each_device=True)
def load_kernel(kernel_name, code, **kwargs):
code = Template(code).substitute(**kwargs)
return cupy.RawKernel(code, kernel_name)
CUDA_NUM_THREADS = 1024
# if you use in 3090 and above, please set 1024 for the fastest calculation
# CUDA_NUM_THREADS = 1024 # FIXME: cuda
kernel_loop = '''
#define CUDA_KERNEL_LOOP(i, n) \
for (int i = blockIdx.x * blockDim.x + threadIdx.x; \
i < (n); \
i += blockDim.x * gridDim.x)
'''
def GET_BLOCKS(N):
return (N + CUDA_NUM_THREADS - 1) // CUDA_NUM_THREADS
_idynamic_kernel = kernel_loop + '''
extern "C"
__global__ void idynamic_forward_kernel(
const ${Dtype}* bottom_data, const ${Dtype}* weight_data, ${Dtype}* top_data) {
CUDA_KERNEL_LOOP(index, ${nthreads}) {
const int n = index / ${channels} / ${top_height} / ${top_width};
const int c = (index / ${top_height} / ${top_width}) % ${channels};
const int h = (index / ${top_width}) % ${top_height};
const int w = index % ${top_width};
const int g = c / (${channels} / ${groups});
${Dtype} value = 0;
#pragma unroll
for (int kh = 0; kh < ${kernel_h}; ++kh) {
#pragma unroll
for (int kw = 0; kw < ${kernel_w}; ++kw) {
const int h_in = -${pad_h} + h * ${stride_h} + kh * ${dilation_h};
const int w_in = -${pad_w} + w * ${stride_w} + kw * ${dilation_w};
if ((h_in >= 0) && (h_in < ${bottom_height})
&& (w_in >= 0) && (w_in < ${bottom_width})) {
const int offset = ((n * ${channels} + c) * ${bottom_height} + h_in)
* ${bottom_width} + w_in;
const int offset_weight = ((((n * ${groups} + g) * ${kernel_h} + kh) * ${kernel_w} + kw) * ${top_height} + h)
* ${top_width} + w;
value += weight_data[offset_weight] * bottom_data[offset];
}
}
}
top_data[index] = value;
}
}
'''
_idynamic_kernel_backward_grad_input = kernel_loop + '''
extern "C"
__global__ void idynamic_backward_grad_input_kernel(
const ${Dtype}* const top_diff, const ${Dtype}* const weight_data, ${Dtype}* const bottom_diff) {
CUDA_KERNEL_LOOP(index, ${nthreads}) {
const int n = index / ${channels} / ${bottom_height} / ${bottom_width};
const int c = (index / ${bottom_height} / ${bottom_width}) % ${channels};
const int h = (index / ${bottom_width}) % ${bottom_height};
const int w = index % ${bottom_width};
const int g = c / (${channels} / ${groups});
${Dtype} value = 0;
#pragma unroll
for (int kh = 0; kh < ${kernel_h}; ++kh) {
#pragma unroll
for (int kw = 0; kw < ${kernel_w}; ++kw) {
const int h_out_s = h + ${pad_h} - kh * ${dilation_h};
const int w_out_s = w + ${pad_w} - kw * ${dilation_w};
if (((h_out_s % ${stride_h}) == 0) && ((w_out_s % ${stride_w}) == 0)) {
const int h_out = h_out_s / ${stride_h};
const int w_out = w_out_s / ${stride_w};
if ((h_out >= 0) && (h_out < ${top_height})
&& (w_out >= 0) && (w_out < ${top_width})) {
const int offset = ((n * ${channels} + c) * ${top_height} + h_out)
* ${top_width} + w_out;
const int offset_weight = ((((n * ${groups} + g) * ${kernel_h} + kh) * ${kernel_w} + kw) * ${top_height} + h_out)
* ${top_width} + w_out;
value += weight_data[offset_weight] * top_diff[offset];
}
}
}
}
bottom_diff[index] = value;
}
}
'''
_idynamic_kernel_backward_grad_weight = kernel_loop + '''
extern "C"
__global__ void idynamic_backward_grad_weight_kernel(
const ${Dtype}* const top_diff, const ${Dtype}* const bottom_data, ${Dtype}* const buffer_data) {
CUDA_KERNEL_LOOP(index, ${nthreads}) {
const int h = (index / ${top_width}) % ${top_height};
const int w = index % ${top_width};
const int kh = (index / ${kernel_w} / ${top_height} / ${top_width})
% ${kernel_h};
const int kw = (index / ${top_height} / ${top_width}) % ${kernel_w};
const int h_in = -${pad_h} + h * ${stride_h} + kh * ${dilation_h};
const int w_in = -${pad_w} + w * ${stride_w} + kw * ${dilation_w};
if ((h_in >= 0) && (h_in < ${bottom_height})
&& (w_in >= 0) && (w_in < ${bottom_width})) {
const int g = (index / ${kernel_h} / ${kernel_w} / ${top_height} / ${top_width}) % ${groups};
const int n = (index / ${groups} / ${kernel_h} / ${kernel_w} / ${top_height} / ${top_width}) % ${num};
${Dtype} value = 0;
#pragma unroll
for (int c = g * (${channels} / ${groups}); c < (g + 1) * (${channels} / ${groups}); ++c) {
const int top_offset = ((n * ${channels} + c) * ${top_height} + h)
* ${top_width} + w;
const int bottom_offset = ((n * ${channels} + c) * ${bottom_height} + h_in)
* ${bottom_width} + w_in;
value += top_diff[top_offset] * bottom_data[bottom_offset];
}
buffer_data[index] = value;
} else {
buffer_data[index] = 0;
}
}
}
'''
class _idynamic(Function):
@staticmethod
def forward(ctx, input, weight, stride, padding, dilation):
assert input.dim() == 4 and input.is_cuda
assert weight.dim() == 6 and weight.is_cuda
batch_size, channels, height, width = input.size()
kernel_h, kernel_w = weight.size()[2:4]
output_h = int((height + 2 * padding[0] - (dilation[0] * (kernel_h - 1) + 1)) / stride[0] + 1)
output_w = int((width + 2 * padding[1] - (dilation[1] * (kernel_w - 1) + 1)) / stride[1] + 1)
output = input.new(batch_size, channels, output_h, output_w)
n = output.numel()
with torch.cuda.device_of(input):
f = load_kernel('idynamic_forward_kernel', _idynamic_kernel, Dtype=Dtype(input), nthreads=n,
num=batch_size, channels=channels, groups=weight.size()[1],
bottom_height=height, bottom_width=width,
top_height=output_h, top_width=output_w,
kernel_h=kernel_h, kernel_w=kernel_w,
stride_h=stride[0], stride_w=stride[1],
dilation_h=dilation[0], dilation_w=dilation[1],
pad_h=padding[0], pad_w=padding[1])
f(block=(CUDA_NUM_THREADS, 1, 1),
grid=(GET_BLOCKS(n), 1, 1),
args=[input.data_ptr(), weight.data_ptr(), output.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
ctx.save_for_backward(input, weight)
ctx.stride, ctx.padding, ctx.dilation = stride, padding, dilation
return output
@staticmethod
def backward(ctx, grad_output):
assert grad_output.is_cuda
if not grad_output.is_contiguous():
grad_output.contiguous()
input, weight = ctx.saved_tensors
stride, padding, dilation = ctx.stride, ctx.padding, ctx.dilation
batch_size, channels, height, width = input.size()
kernel_h, kernel_w = weight.size()[2:4]
output_h, output_w = grad_output.size()[2:]
grad_input, grad_weight = None, None
opt = dict(Dtype=Dtype(grad_output),
num=batch_size, channels=channels, groups=weight.size()[1],
bottom_height=height, bottom_width=width,
top_height=output_h, top_width=output_w,
kernel_h=kernel_h, kernel_w=kernel_w,
stride_h=stride[0], stride_w=stride[1],
dilation_h=dilation[0], dilation_w=dilation[1],
pad_h=padding[0], pad_w=padding[1])
with torch.cuda.device_of(input):
if ctx.needs_input_grad[0]:
grad_input = input.new(input.size())
n = grad_input.numel()
opt['nthreads'] = n
f = load_kernel('idynamic_backward_grad_input_kernel',
_idynamic_kernel_backward_grad_input, **opt)
f(block=(CUDA_NUM_THREADS, 1, 1),
grid=(GET_BLOCKS(n), 1, 1),
args=[grad_output.data_ptr(), weight.data_ptr(), grad_input.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
if ctx.needs_input_grad[1]:
grad_weight = weight.new(weight.size())
n = grad_weight.numel()
opt['nthreads'] = n
f = load_kernel('idynamic_backward_grad_weight_kernel',
_idynamic_kernel_backward_grad_weight, **opt)
f(block=(CUDA_NUM_THREADS, 1, 1),
grid=(GET_BLOCKS(n), 1, 1),
args=[grad_output.data_ptr(), input.data_ptr(), grad_weight.data_ptr()],
stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))
return grad_input, grad_weight, None, None, None
def _idynamic_cuda(input, weight, bias=None, stride=1, padding=0, dilation=1):
""" idynamic kernel
"""
assert input.size(0) == weight.size(0)
assert input.size(-2) // stride == weight.size(-2)
assert input.size(-1) // stride == weight.size(-1)
if input.is_cuda:
out = _idynamic.apply(input, weight, _pair(stride), _pair(padding), _pair(dilation))
if bias is not None:
out += bias.view(1, -1, 1, 1)
else:
raise NotImplementedError
return out
class IDynamicDWConv(nn.Module):
def __init__(self, dim, kernel_size, bias):
super(IDynamicDWConv, self).__init__()
self.groups = dim
self.kernel_size = kernel_size
self.weight = nn.Conv2d(dim, dim * kernel_size ** 2, kernel_size=3, stride=1, padding=1, groups=dim, bias=bias)
def forward(self, x):
b, c, h, w = x.shape
weight = self.weight(x)
weight = weight.view(b, self.groups, self.kernel_size, self.kernel_size, h, w)
out = _idynamic_cuda(x, weight, stride=1, padding=(self.kernel_size - 1) // 2)
return outASSA Block 核心思想
为减少无关token干扰,采用转置缩放点积操作计算注意力矩阵,并用ReLU作为选择函数(S)筛选有效相似性值,保留与当前token最相关的信息。同时,通过共享参数模块估计K和V,降低模型复杂度。该机制使注意力图稀疏化,提升特征聚合效率。
ASSA Block 具体过程
1. 数据预处理与重塑
采用kv共享策略(即键K和值V通过同一模块共享参数估计),将输入特征重塑为查询()和值(
),形状均为HW×C(其中HW为图像空间维度乘积,C为通道数)。【对应于原文公式5和公式6】
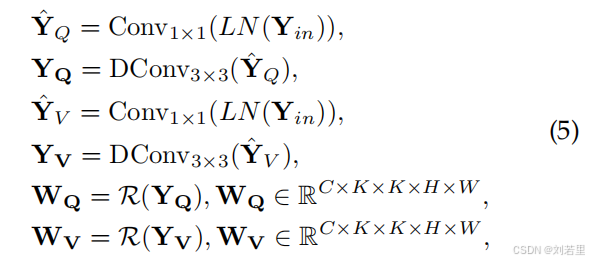
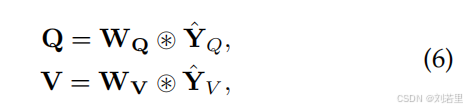

2. 稀疏注意力矩阵计算
通过转置缩放点积操作计算注意力矩阵,具体为的乘积,再经过选择函数(S)处理。文中选用ReLU作为选择函数,通过非线性激活筛选出有效相似性值,生成稀疏注意力矩阵A(形状为C×C),保留与当前token最相关的信息,减少无关token干扰 。【对应于原文公式7】
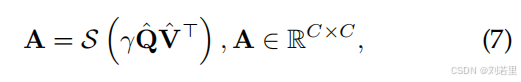
3. 特征聚合与残差连接
利用稀疏注意力矩阵A对值特征进行聚合,通过重塑函数(T)将结果恢复为H×W×C的空间维度,再经1×1卷积调整通道,并与输入特征(
)进行残差连接,得到聚合特征
。【对应于原文公式8】
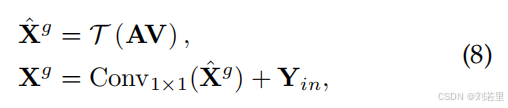
4. 门控前馈网络增强
对应用层归一化(LN)和1×1卷积,生成中间特征
(通道数扩展为4C),经3×3深度卷积后按通道分割为
和
。通过GELU激活
,并与
逐元素相乘,最终经1×1卷积输出增强后的特征,进一步提升表示能力。【对应于原文公式9】
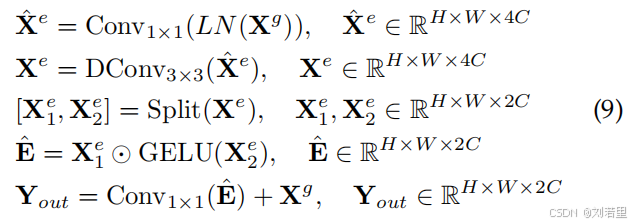
ASSA Block 创新点
-
自适应稀疏策略机制:多稀疏模式适配,支持 6 种激活函数对应不同稀疏策略(Top-K 硬性稀疏、MaskedSoftmax 掩码稀疏、GELU 柔性稀疏等,稀疏选择函数最优为ReLU),可根据任务需求灵活选择,比单一稀疏模式更具泛化性。可学习温度因子,动态调整注意力分布锐度,让稀疏筛选更精准,避免无效关联干扰。
-
动态深度卷积增强:引入 IDynamicDWConv 动态深度卷积,在 QV 投影后增强局部特征依赖,解决传统自注意力局部细节捕捉不足的问题,提升注意力特征质量。深度卷积轻量化设计,不显著增加计算成本,平衡局部增强与全局依赖捕捉。
-
极简架构与强兼容性:Q=V 简化设计,减少一次特征投影,降低参数量;输入输出维度一致,支持任意通道数与空间尺寸,可直接嵌入 CNN、Transformer 等各类视觉模型,集成成本低。